Competitive Bridge Bidding with Deep Neural Networks∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Transfers Responses to NT Opening Bids
Auckland Bridge Club Improvers Sessions Transfers Responses to NT Opening Bids Basic responses 2. Stayman, asking partner to bid a 4 card major or 2♦ without one. 2 Promises at least five hearts and orders partner to bid 2. 2 Promises at least five spades and orders partner to bid 2. The use of 2 There are several different meanings that players use for 2 and 2NT in and 2NT response to partner’s 1NT opening. In Modern Acol the meanings are as follows: 2 Either a raise to 2NT without a 4-card major, usually 11-12 points. Or a strong hand with at least game forcing values, looking for the best game or slam, say 18 or more points. Usually the hand will have no 5-card suit. It asks opener a question. Are you a minimum? If so bid 2NT. Or are you a maximum, in which case bid your lowest 4-card suit. 2NT Since hands that would have bid 2NT now bid 2, we now have a bid without a meaning. So we use it as a transfer to a minor. You need a weak 6-card minor suit (either clubs or diamonds). It tells Opener to bid 3. which you pass if clubs is your suit or you bid 3 if you have diamonds. Then he will pass. Responder’s second bid after making a transfer response Bid Auction goes 1NT - 2 - 2 Typical hand Pass My 2 transfer was a weak take-out in spades. K 9 7 6 4 2 Opener is declarer in 2. -

Introducion to Duplicate
INTRODUCTION to DUPLICATE INTRODUCTION TO DUPLICATE BRIDGE This book is not about how to bid, declare or defend a hand of bridge. It assumes you know how to do that or are learning how to do those things elsewhere. It is your guide to playing Duplicate Bridge, which is how organized, competitive bridge is played all over the World. It explains all the Laws of Duplicate and the process of entering into Club games or Tournaments, the Convention Card, the protocols and rules of player conduct; the paraphernalia and terminology of duplicate. In short, it’s about the context in which duplicate bridge is played. To become an accomplished duplicate player, you will need to know everything in this book. But you can start playing duplicate immediately after you read Chapter I and skim through the other Chapters. © ACBL Unit 533, Palm Springs, Ca © ACBL Unit 533, 2018 Pg 1 INTRODUCTION to DUPLICATE This book belongs to Phone Email I joined the ACBL on ____/____ /____ by going to www.ACBL.com and signing up. My ACBL number is __________________ © ACBL Unit 533, 2018 Pg 2 INTRODUCTION to DUPLICATE Not a word of this book is about how to bid, play or defend a bridge hand. It assumes you have some bridge skills and an interest in enlarging your bridge experience by joining the world of organized bridge competition. It’s called Duplicate Bridge. It’s the difference between a casual Saturday morning round of golf or set of tennis and playing in your Club or State championships. As in golf or tennis, your skills will be tested in competition with others more or less skilled than you; this book is about the settings in which duplicate happens. -

Acol Bidding Notes
SECTION 1 - INTRODUCTION The following notes are designed to help your understanding of the Acol system of bidding and should be used in conjunction with Crib Sheets 1 to 5 and the Glossary of Terms The crib sheets summarise the bidding in tabular form, whereas these notes provide a fuller explanation of the reasons for making particular bids and bidding strategy. These notes consist of a number of short chapters that have been structured in a logical order to build on the things learnt in the earlier chapters. However, each chapter can be viewed as a mini-lesson on a specific area which can be read in isolation rather than trying to absorb too much information in one go. It should be noted that there is not a single set of definitive Acol ‘rules’. The modern Acol bidding style has developed over the years and different bridge experts recommend slightly different variations based on their personal preferences and playing experience. These notes are based on the methods described in the book The Right Way to Play Bridge by Paul Mendelson, which is available at all good bookshops (and some rubbish ones as well). They feature a ‘Weak No Trump’ throughout and ‘Strong Two’ openings. +++++++++++++++++++++++++++++++++++++ INDEX Section 1 Introduction Chapter 1 Bidding objectives & scoring Chapter 2 Evaluating the strength of your hand Chapter 3 Evaluating the shape of your hand . Section 2 Balanced Hands Chapter 21 1NT opening bid & No Trumps responses Chapter 22 1NT opening bid & suit responses Chapter 23 Opening bids with stronger balanced hands Chapter 24 Supporting responder’s major suit Chapter 25 2NT opening bid & responses Chapter 26 2 Clubs opening bid & responses Chapter 27 No Trumps responses after an opening suit bid Chapter 28 Summary of bidding with Balanced Hands . -
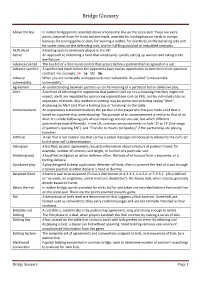
Bridge Glossary
Bridge Glossary Above the line In rubber bridge points recorded above a horizontal line on the score-pad. These are extra points, beyond those for tricks bid and made, awarded for holding honour cards in trumps, bonuses for scoring game or slam, for winning a rubber, for overtricks on the declaring side and for under-tricks on the defending side, and for fulfilling doubled or redoubled contracts. ACOL/Acol A bidding system commonly played in the UK. Active An approach to defending a hand that emphasizes quickly setting up winners and taking tricks. See Passive Advance cue bid The cue bid of a first round control that occurs before a partnership has agreed on a suit. Advance sacrifice A sacrifice bid made before the opponents have had an opportunity to determine their optimum contract. For example: 1♦ - 1♠ - Dbl - 5♠. Adverse When you are vulnerable and opponents non-vulnerable. Also called "unfavourable vulnerability vulnerability." Agreement An understanding between partners as to the meaning of a particular bid or defensive play. Alert A method of informing the opponents that partner's bid carries a meaning that they might not expect; alerts are regulated by sponsoring organizations such as EBU, and by individual clubs or organisers of events. Any method of alerting may be authorised including saying "Alert", displaying an Alert card from a bidding box or 'knocking' on the table. Announcement An explanatory statement made by the partner of the player who has just made a bid that is based on a partnership understanding. The purpose of an announcement is similar to that of an Alert. -

Learning to Communicate Implicitly by Actions
The Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-20) Learning to Communicate Implicitly by Actions Zheng Tian,1 Shihao Zou,1 Ian Davies,1 Tim Warr,1 Lisheng Wu,1 Haitham Bou Ammar,1,2 Jun Wang1 1University College London, 2Huawei R&DUK {zheng.tian.11, shihao.zou.17, ian.davies.12, tim.warr.17, lisheng.wu.17}@ucl.ac.uk [email protected] [email protected] Abstract for facilitating collaboration in MARL, explicit communica- tion channels come at additional computational and memory In situations where explicit communication is limited, human costs, making them difficult to deploy in decentralized con- collaborators act by learning to: (i) infer meaning behind their trol (Roth, Simmons, and Veloso 2006). partner’s actions, and (ii) convey private information about the state to their partner implicitly through actions. The first Environments where explicit communication is difficult component of this learning process has been well-studied in or prohibited are common. These settings can be synthetic multi-agent systems, whereas the second — which is equally such as those in games, e.g., bridge and Hanabi, but also crucial for successful collaboration — has not. To mimic both frequently appear in real-world tasks such as autonomous components mentioned above, thereby completing the learn- driving and autonomous fleet control. In these situations, ing process, we introduce a novel algorithm: Policy Belief humans rely upon implicit communication as a means of in- Learning (PBL). PBL uses a belief module to model the other formation exchange (Rasouli, Kotseruba, and Tsotsos 2017) agent’s private information and a policy module to form a and are effective in learning to infer the implicit meaning be- distribution over actions informed by the belief module. -

The Rubensohl Convention
Review sheet 61UZ-2 10/01/2021 The Rubensohl convention You will use the Rubensohl convention in response to your partner's 1 NT opening, but after an overcall. Here is the simplified theory of this convention. After a natural overcall 2 ♦, 2 ♥ or 2 ♠ Any level 2 bid is natural Above 2 NT any bid is a Jacoby transfer. 2 NT is artificial (Jacoby for ♣) An impossible Jacoby becomes a Stayman A double is a take-out double : it could be a Stayman with 8 HCP, or show a balanced hand with 8 HCP or more. S W N E 1NT 2 ♦ 2 ♥ 5 4 3 A Q 7 6 5 6 5 4 8 7 ♠ ♠ ♠ ♥ ♥ ♥ ♥ ♥ ♣ ♣ ♣ ♦ ♦ Exercise E5867 2 ♥ showing 5 ♥ cards and a maximum of 7 HCP. S W N E 1NT 2 ♥ 3 ♦ K J 5 4 4 A J 5 4 Q 10 9 2 ♠ ♠ ♠ ♠ ♥ ♣ ♣ ♣ ♣ ♦ ♦ ♦ ♦ Exercise E5871 3 ♦ Impossible Jacoby (the opponent's overcall is ♥, therefore the responder can't be willing to play ♥ !) : this is a Stayman with 4 ♠ cards and short ♥ : game forcing Page 1 Nous retrouver sur www.ibridge.fr vous permet de parfaire votre bridge. En jouant des donnes, en accédant aux leçons de votre niveau et au recueil des fiches techniques. Review sheet 61UZ-2 10/01/2021 The Rubensohl convention After a natural level 2 overcall Bidding a suit at level 2 is natural and non forcing : the responder holds a maximum of 7 HCP Doubling is not punitive : A double requires a minimum of 7-8 HCP and most of the time shows a hand with which the responder would have bid 2 NT (with no overcall). -

2000 Bridge Bulletin Index
2000 Bridge Bulletin Index ACBL BRIDGE HALL OF FAME. George Rosenkranz named Blackwood Award winner, Meyer Schleifer receives the von Zedtwitz Award C February. Hall of Fame inducts Lou Bluhm, Harry Fishbein, Charles Solomon, George Rosenkranz, Sidney Lazard, Meyer Schleifer and Ira Rubin C October. ACBL BOARD OF DIRECTORS. Highlights from the Boston Board meeting --- February. Election notice C March C May . Highlights of Cincinnati Board meeting C May. Highlights from the Anaheim meeting C October. Election results for 2000 Board C November. ACBL CHARITY FOUNDATION. 2000 Charity Committee appointees named --- February. ACBL CHARITY GAME. Winners C August. ACBL GOODWILL COMMITTEE. 2000 Appointees named --- February. ACBL HALL OF FAME. Rosenkranz wins Blackwood award; Meyer Schleifer is von Zedtwitz award winner C February. ACBL HONORARY MEMBER OF THE YEAR. Chip Martel named for 2000 --- February. ACBL INSTANT MATCHPOINT GAME. Promo C August, September. Results C December. ACBL INTERNATIONAL FUND GAME. Winners C July, November. ACBL PATRON MEMBER LIST. December. ACBL SENIOR GAME. Winners C May. ACE OF CLUBS. Winners of the 1999 contest --- April. AMERICAN BRIDGE ASSOCIATION. Schedule of upcoming national events --- monthly. ANAHEIM NABC. Promos C April --- July. Meltzer squad wins Spingold; Wei-Sender team takes Wagar; District 9 repeats win in GNT-A; District 19 wins GNT-B title; District 13 victorious in GNT-C contest; Zia, Rosenberg top LM Pairs field; Ping, Leung win Red Ribbon; Nugit squad wins Senior Swiss teams C October. Willenken, Silverstein win Fast Open Pairs; Bach and Burgess take IMP Pairs title; Mixed B-A-M winners; 199er Pairs winners; Five-way tie fir Fishbein Trophy; other NABC highlights C November. -

C.C.Tatham & Associates Ltd
C.C.Tatham & Associates Ltd. Consulting Engineers STEPHENSON ROAD I BRIDGE Town of Bracebridge ond Town of H u ntsville Municipol Closs Environmentol Assessment Proiect File prepared by: prepared for C.C. Tatham & Associates Ltd. The Town of Bracebridge and the Town of Huntsville I Banon Drive Bracebridge, ON P1L 0A1 November 17,2014 Tel: (705) 645-7756 Fax: (705)645-8'159 [email protected] CCTA File 212529-1 Toble of Contents 1 lntroduction and Background 1 1.1 I nhoduction/Backg rou nd I 1.2 Class Environmental Assessment Process 2 1.2.1 Class EA Schedules 2 1.2.2 Class EA Terminology 4 1.2.3 SelectedSchedule 4 2 Need & Justification 6 2.1 Existing Conditions and Background 6 2.1.1 StructuralCondition 7 2.1.2 TrafficConditions 10 2.1.3 Utilities 10 2.1.4 HydraulicAssessment 10 2.1.5 Geometry 11 21.6 BarrierProtection 11 2.2 Problem/Opportun ity Statement 11 3 Gonsultation - Study Commencement 12 3,1 Notification 12 3.2 Public Comments 12 3.3 Agency Comments 13 4 Alternative Solutions '14 4.1 Alternative 1 - Do Nothing 14 4.2 Alternative 2 - Rehabilitate the Bridge 4,3 Alternative 3 - Replace the Bridge 5 Environment lnventory 5.1 Natural Environment 5.2 Social Environment 5.2.1 Archaeological lnvestigation 5.2.2 Cultural Heritage Evaluation Report 5.2.3 Property Acquisition 5.3 Physical Environment 5.3.1 Existing Bridge Structure 5.3.2 Existing Approaches 5,3,3 Traffic Operations 5,3,4 Utilities 5.3.5 Hydraulics 5.3.6 Barriers 5.3.7 Geotechnical Considerations 5.4 Economic Environment 6 Evaluation of Alternative Solutions 6.1 Evaluation -

Bolish Club Contents
Bolish Club A system that has evolved from EHAA+ (my version of EHAA, Every Hand An Adventure), and is now more similar to Polish Club. Other sources of inspiration are Keri by Ron Klinger, Ambra by Benito Garozzo, and Einari Club (a local Blue-team-like system, something of a standard in Turku). BC includes natural or strong 1|, 5-card majors, 2-over-1 game forcing, and responders 2| as relay in most situations. By Jari BÄoling,some based on ideas and discussions with Kurt-Erik HÄaggblom,Jyrki Lahtonen, and Ensio Lehtinen, last updated January 5, 2007 Contents 1 The 1| opening 2 1.1 Interference over 1| ......................................... 8 2 The 1} opening 10 3 Major openings 10 3.1 Choosing response in borderline cases . 12 3.2 The semi-forcing 1NT response . 12 3.3 The 1M-2| relay . 14 3.3.1 After interference . 15 3.3.2 A natural alternative . 15 4 The weak twos 16 4.1 New suit bids ask for stoppers and length . 16 4.2 Jump shifts are control asking bids . 17 4.3 2NT is an invitational or better raise . 17 4.4 The weak 2| opening . 18 4.5 Competition . 18 4.5.1 The McCabe convention . 19 5 The 2| opening as 17{18 balanced 19 6 2} Wilkosz 20 7 2| Multi-Wilkosz 20 8 Semi-balanced 2M 21 9 2} multi 22 10 The 2NT opening 22 BC Opening Bids Opening strength description conventional response frequency 1| a) 11{17 2+ clubs 2|, 2}, 2NT, 3} 8.5(9.7)% b) 18+ any shape (excluding 23-24 bal.) 1}=0{5 hcpts 3.2% 1} 11{17 4+ diamonds 2|, 2}, 2NT, 3| 8.6(9.5)% 1~ 11{17¤ 5+ hearts 2|, 2}, 2NT 6.7% 1Ä 11{17¤ 5+ spades 2|, 2~, 2NT 6.9% 1NT a) -

Bridge for Dummies‰
01_924261 ffirs.qxp 8/17/06 2:49 PM Page i Bridge FOR DUMmIES‰ 2ND EDITION by Eddie Kantar 01_924261 ffirs.qxp 8/17/06 2:49 PM Page iv 01_924261 ffirs.qxp 8/17/06 2:49 PM Page i Bridge FOR DUMmIES‰ 2ND EDITION by Eddie Kantar 01_924261 ffirs.qxp 8/17/06 2:49 PM Page ii Bridge For Dummies®, 2nd Edition Published by Wiley Publishing, Inc. 111 River St. Hoboken, NJ 07030-5774 www.wiley.com Copyright © 2006 by Wiley Publishing, Inc., Indianapolis, Indiana Published simultaneously in Canada No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning, or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without either the prior written permis- sion of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, 978-750-8400, fax 978-646-8600. Requests to the Publisher for permission should be addressed to the Legal Department, Wiley Publishing, Inc., 10475 Crosspoint Blvd., Indianapolis, IN 46256, 317-572-3447, fax 317-572-4355, or online at http://www. wiley.com/go/permissions. Trademarks: Wiley, the Wiley Publishing logo, For Dummies, the Dummies Man logo, A Reference for the Rest of Us!, The Dummies Way, Dummies Daily, The Fun and Easy Way, Dummies.com and related trade dress are trademarks or registered trademarks of John Wiley & Sons, Inc. and/or its affiliates in the United States and other countries, and may not be used without written permission. -

Beat Them at the One Level Eastbourne Epic
National Poetry Day Tablet scoring - the rhyme and reason Rosen - beat them at the one level Byrne - Ode to two- suited overcalls Gold - time to jump shift? Eastbourne Epic – winners and pictures English Bridge INSIDE GUIDE © All rights reserved From the Chairman 5 n ENGLISH BRIDGE Major Jump Shifts – David Gold 6 is published every two months by the n Heather’s Hints – Heather Dhondy 8 ENGLISH BRIDGE UNION n Bridge Fiction – David Bird 10 n Broadfields, Bicester Road, Double, Bid or Pass? – Andrew Robson 12 Aylesbury HP19 8AZ n Prize Leads Quiz – Mould’s questions 14 n ( 01296 317200 Fax: 01296 317220 Add one thing – Neil Rosen N 16 [email protected] EW n Web site: www.ebu.co.uk Basic Card Play – Paul Bowyer 18 n ________________ Two-suit overcalls – Michael Byrne 20 n World Bridge Games – David Burn 22 Editor: Lou Hobhouse n Raggett House, Bowdens, Somerset, TA10 0DD Ask Frances – Frances Hinden 24 n Beat Today’s Experts – Bird’s questions 25 ( 07884 946870 n [email protected] Sleuth’s Quiz – Ron Klinger’s questions 27 n ________________ Bridge with a Twist – Simon Cochemé 28 n Editorial Board Pairs vs Teams – Simon Cope 30 n Jeremy Dhondy (Chairman), Bridge Ha Ha & Caption Competition 32 n Barry Capal, Lou Hobhouse, Peter Stockdale Poetry special – Various 34 n ________________ Electronic scoring review – Barry Morrison 36 n Advertising Manager Eastbourne results and pictures 38 n Chris Danby at Danby Advertising EBU News, Eastbourne & Calendar 40 n Fir Trees, Hall Road, Hainford, Ask Gordon – Gordon Rainsford 42 n Norwich NR10 3LX -

Transferring Into a Minor Suit Over Partner’S Opening NT Call
Transferring Into a Minor Suit Over Partner’s Opening NT Call Assuming a 15-17 HCP opening of 1-NT by Partner, it is almost universally accepted that Responder should transfer when holding a 5-card or longer Major suit (Hearts or Spades). When Responder holds a long Minor suit (Clubs or Diamonds), however, the situation is markedly different. This is due to the fact that when transferring to a Major suit the Partnership can always play, minimally, at the 2-level; but when transferring to a Minor suit the Partnership is forced to the 3-level. For this reason, Minor suit transfers require a 6-card or longer suit, unlike Major suit transfers which require 5-cards or longer. Transfers for either Minor Suit should not be utilized after an opening of 2-NT, since the level of bidding becomes too high except when Responder’s intent is to use “Minor Suit Stayman” in order to seek a possible Minor suit Slam. Having the circumstance and Partnership agreement as to the means by which one transfers into either Minor suit, however, does not necessarily mean that a Responder should always take the occasion to do so, even when Responder holds a long Minor suit. (See Examples 1-3) Opener Responder 1-NT ???? Example 1: 872 98 974 AJ962 “Pass” (The Minor suit held, here, by Responder, is not 6-pieces or longer.) Example 2: Q42 J8 Q76532 Q6 “Pass” (A 1-NT contract, when Responder holds 6-8 HCP’s is likely to produce a higher match-point score than three of a Minor suit, which might not even be makeable.) Example 3: Q7 Q4 KQJ954 K63 3-NT (Why announce your 6-card Minor suit to the Opponents when a final 3-NT contract is likely to be the optimal contract.