The Segment in Phonetics and Phonology the Segment in Phonetics and Phonology
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Technical Report, Vol
CRL Technical Report, Vol. 19 No. 1, March 2007 CENTER FOR RESEARCH IN LANGUAGE March 2007 Vol. 19, No. 1 CRL Technical Reports, University of California, San Diego, La Jolla CA 92093-0526 Tel: (858) 534-2536 • E-mail: [email protected] • WWW: http://crl.ucsd.edu/newsletter/current/TechReports/articles.html TECHNICAL REPORT Arab Sign Languages: A Lexical Comparison Kinda Al-Fityani Department of Communication, University of California, San Diego EDITOR’S NOTE The CRL Technical Report replaces the feature article previously published with every issue of the CRL Newsletter. The Newsletter is now limited to announcements and news concerning the CENTER FOR RESEARCH IN LANGUAGE. CRL is a research center at the University of California, San Diego that unites the efforts of fields such as Cognitive Science, Linguistics, Psychology, Computer Science, Sociology, and Philosophy, all who share an interest in language. The Newsletter can be found at http://crl.ucsd.edu/newsletter/current/TechReports/articles.html. The Technical Reports are also produced and published by CRL and feature papers related to language and cognition (distributed via the World Wide Web). We welcome response from friends and colleagues at UCSD as well as other institutions. Please visit our web site at http://crl.ucsd.edu. SUBSCRIPTION INFORMATION If you know of others who would be interested in receiving the Newsletter and the Technical Reports, you may add them to our email subscription list by sending an email to [email protected] with the line "subscribe newsletter <email-address>" in the body of the message (e.g., subscribe newsletter [email protected]). -

Effects of Phonetic and Inventory Constraints in the Spirantization of Intervocalic Voiced Stops: Comparing Two Different Measurements of Energy Change
Effects of Phonetic and Inventory Constraints in the Spirantization of Intervocalic Voiced Stops: Comparing two Different Measurements of Energy Change. Marta Ortega-LLebaria University of Northern Colorado E-mail: [email protected] This paper extends the same hypothesis to the phenomenon ABSTRACT of spirantization by investigating the interaction of phonetic factors with inventory constraints. First, it This paper examines the effect of inventory constraints and examines whether the phonetic factors of stress and vowel the phonetic factors of stress and vowel context in the context, which had an effect in the lenition of Spanish lenition of English and Spanish intervocalic voiced stops. intervocalic /g/ [3], had also an effect in English Five native speakers of American English and five native intervocalic /g/ and in Spanish and English intervocalic /b/. speakers of Caribbean Spanish were recorded saying Secondly, this paper studies the interaction of inventory bi-syllabic words containing intervocalic /b/ and /g/. The constraints with phonetic factors. Inventory constraints intervocalic consonants were evaluated according to two were aimed to preserve the system of sound contrasts of a measures of energy, i.e. RMS ratio, and speed of consonant language while phonetic factors provided contexts that release. Repeated Measures ANOVAS in each measure favored consonant lenition. Hypothetically, a consonant indicated that for both languages, /b/ and /g/ were most will become lenited in a favorable context only if the lenited in trochee words, and that /g/ was most spirantized resulting sound will not impair a contrast of the language. when flanked by /i/ and /u/ vowels. Inventory constraints For example, in English, /b/ contrasts with the voiced moderated the degree of consonant lenition displayed in the fricative /v/ while in Spanish, it does not. -

Department of English and American Studies
Masaryk University Faculty of Arts Department of English and American Studies English Language and Literature Petra Jureková The Pronunciation of English in Czech, Slovak and Russian Speakers Bachelor‟s Diploma Thesis Supervisor: PhDr. Kateřina Tomková, Ph.D. 2015 I declare that I have worked on this thesis independently, using only the primary and secondary sources listed in the bibliography. …………………………………………… Author‟s signature 2 I would like to express gratitude to my supervisor, PhDr. Kateřina Tomková, Ph.D., and thank her for her advice, patience, kindness and help. I would also like to thank all the volunteers that participated in the research project. 3 Table of contents List of tables ...................................................................................................................... 5 1. Introduction ............................................................................................................... 7 1.1. English as an important language for international communication .................. 7 1.2. Acquisition of a foreign language ...................................................................... 8 1.2.1. English as a foreign language ..................................................................... 8 1.2.2. Pronunciation .............................................................................................. 8 1.3. About the thesis .................................................................................................. 9 2. English phonetic system ........................................................................................ -

The Phonetics of Contrastive Phonation in Gujarati$
Journal of Phonetics ] (]]]]) ]]]–]]] Contents lists available at SciVerse ScienceDirect Journal of Phonetics journal homepage: www.elsevier.com/locate/phonetics The phonetics of contrastive phonation in Gujarati$ Sameer ud Dowla Khan n Department of Linguistics, Reed College, 3203 SE Woodstock Boulevard, Portland, OR 97202-8199, USA article info abstract Article history: The current study examines (near-)minimal pairs of breathy and modal phonation produced by ten Received 20 December 2011 native speakers of Gujarati in connected speech, across different vowel qualities and separated by nine Received in revised form equal timepoints of vowel duration. The results identify five spectral measures (i.e. H1–H2, H2–H4, 3 July 2012 H1–A1, H1–A2, H1–A3), four noise measures (i.e. cepstral peak prominence and three measures of Accepted 9 July 2012 harmonics-to-noise ratio), and one electroglottographic measure (i.e. CQ) as reliable indicators of breathy phonation, revealing a considerably larger inventory of cues to breathy phonation than what had previously been reported for the language. Furthermore, while the spectral measures are consistently distinct for breathy and modal vowels when averaging across timepoints, the efficacy of the four noise measures in distinguishing phonation categories is localized to the midpoint of the vowel’s duration. This indicates that the magnitude of breathiness, especially in terms of aperiodicity, changes as a function of time. The current study supports that breathy voice in Gujarati is a dynamic, multidimensional -

Using 'North Wind and the Sun' Texts to Sample Phoneme Inventories
Blowing in the wind: Using ‘North Wind and the Sun’ texts to sample phoneme inventories Louise Baird ARC Centre of Excellence for the Dynamics of Language, The Australian National University [email protected] Nicholas Evans ARC Centre of Excellence for the Dynamics of Language, The Australian National University [email protected] Simon J. Greenhill ARC Centre of Excellence for the Dynamics of Language, The Australian National University & Department of Linguistic and Cultural Evolution, Max Planck Institute for the Science of Human History [email protected] Language documentation faces a persistent and pervasive problem: How much material is enough to represent a language fully? How much text would we need to sample the full phoneme inventory of a language? In the phonetic/phonemic domain, what proportion of the phoneme inventory can we expect to sample in a text of a given length? Answering these questions in a quantifiable way is tricky, but asking them is necessary. The cumulative col- lection of Illustrative Texts published in the Illustration series in this journal over more than four decades (mostly renditions of the ‘North Wind and the Sun’) gives us an ideal dataset for pursuing these questions. Here we investigate a tractable subset of the above questions, namely: What proportion of a language’s phoneme inventory do these texts enable us to recover, in the minimal sense of having at least one allophone of each phoneme? We find that, even with this low bar, only three languages (Modern Greek, Shipibo and the Treger dialect of Breton) attest all phonemes in these texts. -

3-On-3 Restrictions and PCC Typology Syntax
November 28, 2020 3-on-3 restrictions and PCC typology: a reply to Pancheva and Zubizaretta (2018)∗ Amy Rose Deal UC Berkeley Abstract Restrictions on clitic combinations are generally in place when a ditransitive is expressed with both direct object and indirect object clitics. The best-studied such restrictions involve local per- sons, as in classic person-case constraint (PCC) effects—e.g., in French, banning combinations of local person DO clitics with IO clitics (strong PCC). Many languages also impose restrictions on combinations of 3rd person clitics (*3-on-3). Spanish, for instance, bans combinations of 3rd dative + 3rd accusative, requiring the dative to be replaced by the so-called “spurious se” (Perlmut- ter 1971). These two types of restrictions have typically been attributed to separate grammatical rules, if not entirely separate components of the grammar. However, in recent work, Pancheva and Zubizarreta (2018) have proposed a partial unification of *3-on-3 and classic PCC, treating both as grounded in syntactic licensing principles. This theory predicts a typological interaction: 3-on- 3 restrictions will be found only in certain languages that also constrain combinations including local persons. In this paper, I argue that this prediction is false. In Ubykh (NW Caucasian), no re- striction is imposed on clitic combinations involving local persons—there is no PCC effect of any type—but 3-on-3 combinations show clitic opacity effects reminiscent of spurious se. Capturing this pattern requires grammatical rules for the 3-on-3 context that are not grounded in PCC syntax, thus making a case for the independence of the two types of ditransitive person restrictions more generally. -

Grapheme-To-Phoneme Transcription in Hungarian
International Journal of Computational Linguistics and Applications vol. 7, no. 1, 2016, pp. 161–173 Received 08/02/2016, accepted 07/03/2016, final 20/06/2016 ISSN 0976-0962, http://ijcla.bahripublications.com Grapheme-to-Phoneme Transcription in Hungarian ATTILA NOVÁK1 AND BORBÁLA SIKLÓSI2 1 MTA-PPKE Hungarian Language Technology Research Group, Hungary 2 Pázmány Péter Catholic University, Hungary ABSTRACT A crucial component of text-to-speech systems is the one respon- sible for the transcription of the written text to its phonemic rep- resentation. although the complexity of the relation between the written and spoken form of languages varies, most languages have their regular and irregular phonological set of rules. In this paper, we present a system for the phonemic transcription of Hungarian. Beside the implementation of rules describing default letter-to-phoneme correspondences and morphophonological al- ternations, the tool incorporates the knowledge of a Hungarian morphological analyzer in order to be able to detect compound and other morpheme boundaries, and it contains a rich lexicon of entries with irregular pronunciation. It is shown that the system performs well even on texts containing a high number of foreign names. 1 INTRODUCTION In the research reported about in this study, our goal was to imple- ment a system that can automatically transform written Hungarian to its phonemic representation. The original intent of the system This is a pre-print version of the paper, before proper formatting and copyediting by the editorial staff. 162 ATTILA NOVÁK AND BORBÁLA SIKLÓSI was to transcribe a database of Hungarian geographic terms. How- ever, due to certain design decisions, our system proved to perform well also on texts containing a high ratio of foreign names and suf- fixed forms. -
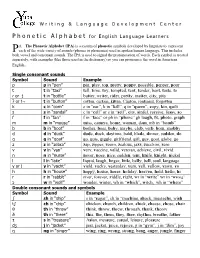
Writing & Language Development Center Phonetic Alphabet for English Language Learners Pin, Play, Top, Pretty, Poppy, Possibl
Writing & Language Development Center Phonetic Alphabet f o r English Language Learners A—The Phonetic Alphabet (IPA) is a system of phonetic symbols developed by linguists to represent P each of the wide variety of sounds (phones or phonemes) used in spoken human language. This includes both vowel and consonant sounds. The IPA is used to signal the pronunciation of words. Each symbol is treated separately, with examples (like those used in the dictionary) so you can pronounce the word in American English. Single consonant sounds Symbol Sound Example p p in “pen” pin, play, top, pretty, poppy, possible, pepper, pour t t in “taxi” tell, time, toy, tempted, tent, tender, bent, taste, to ɾ or ţ t in “bottle” butter, writer, rider, pretty, matter, city, pity ʔ or t¬ t in “button” cotton, curtain, kitten, Clinton, continent, forgotten k c in “corn” c in “car”, k in “kill”, q in “queen”, copy, kin, quilt s s in “sandal” c in “cell” or s in “sell”, city, sinful, receive, fussy, so f f in “fan” f in “face” or ph in “phone” gh laugh, fit, photo, graph m m in “mouse” miss, camera, home, woman, dam, mb in “bomb” b b in “boot” bother, boss, baby, maybe, club, verb, born, snobby d d in “duck” dude, duck, daytime, bald, blade, dinner, sudden, do g g in “goat” go, guts, giggle, girlfriend, gift, guy, goat, globe, go z z in “zebra” zap, zipper, zoom, zealous, jazz, zucchini, zero v v in “van” very, vaccine, valid, veteran, achieve, civil, vivid n n in “nurse” never, nose, nice, sudden, tent, knife, knight, nickel l l in “lake” liquid, laugh, linger, -

The Phonemic − Syllabic Comparisons of Standard Malay and Palembang Malay Using a Historical Linguistic Perspective
Passage2013, 1(2), 35-44 The Phonemic − Syllabic Comparisons of Standard Malay and Palembang Malay Using a Historical Linguistic Perspective By: Novita Arsillah English Language and Literature Program (E-mail: [email protected] / mobile: +6281312203723) ABSTRACT This study is a historical linguistic investigation entitled The Phonemic − Syllabic Comparisons of Standard Malay and Palembang Malay Using a Historical Linguistic Perspective which aims to explore the types of sound changes found in Palembang Malay. The investigation uses a historical linguistic comparative method to compare the phonemic and syllabic changes between an ancestral language Standard Malay and its decent language Palembang Malay. Standard Malay refers to the Wilkinson dictionary in 1904. The participants of this study are seven native speakers of Palembang Malay whose ages range from 20 to 40 years old. The data were collected from the voices of the participants that were recorded along group conversations and interviews. This study applies the theoretical framework of sound changes which proposed by Terry Crowley in 1997 and Lily Campbell in 1999. The findings show that there are nine types of sound changes that were found as the results, namely assimilation (42.35%), lenition (20%), sound addition (3.53%), metathesis (1.18%), dissimilation (1.76%), abnormal sound changes (3.53%), split (13.53%), vowel rising (10.59%), and monophthongisation (3.53%). Keywords: Historical linguistics, standard Malay, Palembang Malay, comparative method, sound change, phoneme, syllable. 35 Novita Arsillah The Phonemic − Syllabic Comparisons of Standard Malay and Palembang Malay Using a Historical Linguistic Perspective INTRODUCTION spelling system in this study since it is considered to be the first Malay spelling This study classifies into the system that is used widely in Malaya, field of historical linguistics that Singapore, and Brunei (Omar, 1989). -

Universals in Phonology This Article A
UC Berkeley Phonology Lab Annual Report (2007) (Commissioned for special issue of The Linguistic Review, 2008, Harry van der Hulst, ed.) Universals in Phonology ABSTRACT This article asks what is universal about phonological systems. Beginning with universals of segment inventories, a distinction is drawn between descriptive universals (where the effect of different theoretical frameworks is minimized) vs. analytic universals (which are specific-theory- dependent). Since there are few absolute universals such as “all languages have stops” and “all languages have at least two degrees of vowel height”, theory-driven or “architectural” universals concerning distinctive features and syllable structure are also considered. Although several near- universals are also mentioned, the existence of conflicting “universal tendencies” and contradictory resolutions naturally leads into questions concerning the status of markedness and synchronic explanation in phonology. While diachrony is best at accounting for typologically unusual and language-specific phonological properties, the absolute universals discussed in this study are clearly grounded in synchrony. 1. Introduction My colleague John Ohala likes to tell the following mythical story about a lecture that the legendary Roman Jakobson gives upon arrival at Harvard University some time in the 1940s. The topic is child language and phonological universals, a subject which Prof. Jakobson addresses in his Kindersprache, Aphasie und allgemeine Lautgesetze (1941). In his also legendary strong Russian accent, Jakobson makes the pronouncement, “In all languages, first utterance of child, [pa]!” 1 He goes on to explain that it is a matter of maximal opposition: “[p] is the consonant most consonant, and [a] is the vowel most vowel.” As the joke continues, a very concerned person in the audience raises his hand and is called on: “But, professor, my child’s first utterance was [tSik].” Prof. -

Part 1: Introduction to The
PREVIEW OF THE IPA HANDBOOK Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet PARTI Introduction to the IPA 1. What is the International Phonetic Alphabet? The aim of the International Phonetic Association is to promote the scientific study of phonetics and the various practical applications of that science. For both these it is necessary to have a consistent way of representing the sounds of language in written form. From its foundation in 1886 the Association has been concerned to develop a system of notation which would be convenient to use, but comprehensive enough to cope with the wide variety of sounds found in the languages of the world; and to encourage the use of thjs notation as widely as possible among those concerned with language. The system is generally known as the International Phonetic Alphabet. Both the Association and its Alphabet are widely referred to by the abbreviation IPA, but here 'IPA' will be used only for the Alphabet. The IPA is based on the Roman alphabet, which has the advantage of being widely familiar, but also includes letters and additional symbols from a variety of other sources. These additions are necessary because the variety of sounds in languages is much greater than the number of letters in the Roman alphabet. The use of sequences of phonetic symbols to represent speech is known as transcription. The IPA can be used for many different purposes. For instance, it can be used as a way to show pronunciation in a dictionary, to record a language in linguistic fieldwork, to form the basis of a writing system for a language, or to annotate acoustic and other displays in the analysis of speech. -

Issues in the Distribution of the Glottal Stop
Theoretical Issues in the Representation of the Glottal Stop in Blackfoot* Tyler Peterson University of British Columbia 1.0 Introduction This working paper examines the phonemic and phonetic status and distribution of the glottal stop in Blackfoot.1 Observe the phonemic distribution (1), four phonological operations (2), and three surface realizations (3) of the glottal stop: (1) a. otsi ‘to swim’ c. otsi/ ‘to splash with water’ b. o/tsi ‘to take’ (2) a. Metathesis: V/VC ® VV/C nitáó/mai/takiwa nit-á/-omai/takiwa 1-INCHOAT-believe ‘now I believe’ b. Metathesis ® Deletion: V/VùC ® VVù/C ® VVùC kátaookaawaatsi káta/-ookaa-waatsi INTERROG-sponsor.sundance-3s.NONAFFIRM ‘Did she sponsor a sundance?’ (Frantz, 1997: 154) c. Metathesis ® Degemination: V/V/C ® VV//C ® VV/C áó/tooyiniki á/-o/too-yiniki INCHOAT-arrive(AI)-1s/2s ‘when I/you arrive’ d. Metathesis ® Deletion ® V-lengthening: V/VC ® VV/C ® VVùC kátaoottakiwaatsi káta/-ottaki-waatsi INTEROG-bartender-3s.NONAFFIRM ‘Is he a bartender?’ (Frantz, 1997) (3) Surface realizations: [V/C] ~ [VV0C] ~ [VùC] aikai/ni ‘He dies’ a. [aIkaI/ni] b. [aIkaII0ni] c. [aIkajni] The glottal stop appears to have a unique status within the Blackfoot consonant inventory. The examples in (1) (and §2.1 below) suggest that it appears as a fully contrastive phoneme in the language. However, the glottal stop is put through variety of phonological processes (metathesis, syncope and degemination) that no other consonant in the language is subject to. Also, it has a variety of surfaces realizations in the form of glottalization on an adjacent vowel (cf.