What Is Bayesianism? a Guide for the Perplexed David H
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Descriptive Statistics (Part 2): Interpreting Study Results
Statistical Notes II Descriptive statistics (Part 2): Interpreting study results A Cook and A Sheikh he previous paper in this series looked at ‘baseline’. Investigations of treatment effects can be descriptive statistics, showing how to use and made in similar fashion by comparisons of disease T interpret fundamental measures such as the probability in treated and untreated patients. mean and standard deviation. Here we continue with descriptive statistics, looking at measures more The relative risk (RR), also sometimes known as specific to medical research. We start by defining the risk ratio, compares the risk of exposed and risk and odds, the two basic measures of disease unexposed subjects, while the odds ratio (OR) probability. Then we show how the effect of a disease compares odds. A relative risk or odds ratio greater risk factor, or a treatment, can be measured using the than one indicates an exposure to be harmful, while relative risk or the odds ratio. Finally we discuss the a value less than one indicates a protective effect. ‘number needed to treat’, a measure derived from the RR = 1.2 means exposed people are 20% more likely relative risk, which has gained popularity because of to be diseased, RR = 1.4 means 40% more likely. its clinical usefulness. Examples from the literature OR = 1.2 means that the odds of disease is 20% higher are used to illustrate important concepts. in exposed people. RISK AND ODDS Among workers at factory two (‘exposed’ workers) The probability of an individual becoming diseased the risk is 13 / 116 = 0.11, compared to an ‘unexposed’ is the risk. -

Teacher Guide 12.1 Gambling Page 1
TEACHER GUIDE 12.1 GAMBLING PAGE 1 Standard 12: The student will explain and evaluate the financial impact and consequences of gambling. Risky Business Priority Academic Student Skills Personal Financial Literacy Objective 12.1: Analyze the probabilities involved in winning at games of chance. Objective 12.2: Evaluate costs and benefits of gambling to Simone, Paula, and individuals and society (e.g., family budget; addictive behaviors; Randy meet in the library and the local and state economy). every afternoon to work on their homework. Here is what is going on. Ryan is flipping a coin, and he is not cheating. He has just flipped seven heads in a row. Is Ryan’s next flip more likely to be: Heads; Tails; or Heads and tails are equally likely. Paula says heads because the first seven were heads, so the next one will probably be heads too. Randy says tails. The first seven were heads, so the next one must be tails. Lesson Objectives Simone says that it could be either heads or tails Recognize gambling as a form of risk. because both are equally Calculate the probabilities of winning in games of chance. likely. Who is correct? Explore the potential benefits of gambling for society. Explore the potential costs of gambling for society. Evaluate the personal costs and benefits of gambling. © 2008. Oklahoma State Department of Education. All rights reserved. Teacher Guide 12.1 2 Personal Financial Literacy Vocabulary Dependent event: The outcome of one event affects the outcome of another, changing the TEACHING TIP probability of the second event. This lesson is based on risk. -

Odds: Gambling, Law and Strategy in the European Union Anastasios Kaburakis* and Ryan M Rodenberg†
63 Odds: Gambling, Law and Strategy in the European Union Anastasios Kaburakis* and Ryan M Rodenberg† Contemporary business law contributions argue that legal knowledge or ‘legal astuteness’ can lead to a sustainable competitive advantage.1 Past theses and treatises have led more academic research to endeavour the confluence between law and strategy.2 European scholars have engaged in the Proactive Law Movement, recently adopted and incorporated into policy by the European Commission.3 As such, the ‘many futures of legal strategy’ provide * Dr Anastasios Kaburakis is an assistant professor at the John Cook School of Business, Saint Louis University, teaching courses in strategic management, sports business and international comparative gaming law. He holds MS and PhD degrees from Indiana University-Bloomington and a law degree from Aristotle University in Thessaloniki, Greece. Prior to academia, he practised law in Greece and coached basketball at the professional club and national team level. He currently consults international sport federations, as well as gaming operators on regulatory matters and policy compliance strategies. † Dr Ryan Rodenberg is an assistant professor at Florida State University where he teaches sports law analytics. He earned his JD from the University of Washington-Seattle and PhD from Indiana University-Bloomington. Prior to academia, he worked at Octagon, Nike and the ATP World Tour. 1 See C Bagley, ‘What’s Law Got to Do With It?: Integrating Law and Strategy’ (2010) 47 American Business Law Journal 587; C -
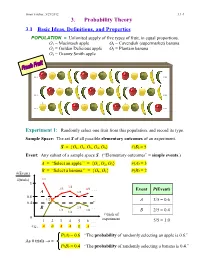
3. Probability Theory
Ismor Fischer, 5/29/2012 3.1-1 3. Probability Theory 3.1 Basic Ideas, Definitions, and Properties POPULATION = Unlimited supply of five types of fruit, in equal proportions. O1 = Macintosh apple O4 = Cavendish (supermarket) banana O2 = Golden Delicious apple O5 = Plantain banana O3 = Granny Smith apple … … … … … … Experiment 1: Randomly select one fruit from this population, and record its type. Sample Space: The set S of all possible elementary outcomes of an experiment. S = {O1, O2, O3, O4, O5} #(S) = 5 Event: Any subset of a sample space S. (“Elementary outcomes” = simple events.) A = “Select an apple.” = {O1, O2, O3} #(A) = 3 B = “Select a banana.” = {O , O } #(B) = 2 #(Event) 4 5 #(trials) 1/1 1 3/4 2/3 4/6 . Event P(Event) A 3/5 0.6 1/2 A 3/5 = 0.6 0.4 B 2/5 . 1/3 2/6 1/4 B 2/5 = 0.4 # trials of 0 experiment 1 2 3 4 5 6 . 5/5 = 1.0 e.g., A B A A B A . P(A) = 0.6 “The probability of randomly selecting an apple is 0.6.” As # trials → ∞ P(B) = 0.4 “The probability of randomly selecting a banana is 0.4.” Ismor Fischer, 5/29/2012 3.1-2 General formulation may be facilitated with the use of a Venn diagram: Experiment ⇒ Sample Space: S = {O1, O2, …, Ok} #(S) = k A Om+1 Om+2 O2 O1 O3 Om+3 O 4 . Om . Ok Event A = {O1, O2, …, Om} ⊆ S #(A) = m ≤ k Definition: The probability of event A, denoted P(A), is the long-run relative frequency with which A is expected to occur, as the experiment is repeated indefinitely. -

Probability Cheatsheet V2.0 Thinking Conditionally Law of Total Probability (LOTP)
Probability Cheatsheet v2.0 Thinking Conditionally Law of Total Probability (LOTP) Let B1;B2;B3; :::Bn be a partition of the sample space (i.e., they are Compiled by William Chen (http://wzchen.com) and Joe Blitzstein, Independence disjoint and their union is the entire sample space). with contributions from Sebastian Chiu, Yuan Jiang, Yuqi Hou, and Independent Events A and B are independent if knowing whether P (A) = P (AjB )P (B ) + P (AjB )P (B ) + ··· + P (AjB )P (B ) Jessy Hwang. Material based on Joe Blitzstein's (@stat110) lectures 1 1 2 2 n n A occurred gives no information about whether B occurred. More (http://stat110.net) and Blitzstein/Hwang's Introduction to P (A) = P (A \ B1) + P (A \ B2) + ··· + P (A \ Bn) formally, A and B (which have nonzero probability) are independent if Probability textbook (http://bit.ly/introprobability). Licensed and only if one of the following equivalent statements holds: For LOTP with extra conditioning, just add in another event C! under CC BY-NC-SA 4.0. Please share comments, suggestions, and errors at http://github.com/wzchen/probability_cheatsheet. P (A \ B) = P (A)P (B) P (AjC) = P (AjB1;C)P (B1jC) + ··· + P (AjBn;C)P (BnjC) P (AjB) = P (A) P (AjC) = P (A \ B1jC) + P (A \ B2jC) + ··· + P (A \ BnjC) P (BjA) = P (B) Last Updated September 4, 2015 Special case of LOTP with B and Bc as partition: Conditional Independence A and B are conditionally independent P (A) = P (AjB)P (B) + P (AjBc)P (Bc) given C if P (A \ BjC) = P (AjC)P (BjC). -

Naïve Bayes Classifier
CS 60050 Machine Learning Naïve Bayes Classifier Some slides taken from course materials of Tan, Steinbach, Kumar Bayes Classifier ● A probabilistic framework for solving classification problems ● Approach for modeling probabilistic relationships between the attribute set and the class variable – May not be possible to certainly predict class label of a test record even if it has identical attributes to some training records – Reason: noisy data or presence of certain factors that are not included in the analysis Probability Basics ● P(A = a, C = c): joint probability that random variables A and C will take values a and c respectively ● P(A = a | C = c): conditional probability that A will take the value a, given that C has taken value c P(A,C) P(C | A) = P(A) P(A,C) P(A | C) = P(C) Bayes Theorem ● Bayes theorem: P(A | C)P(C) P(C | A) = P(A) ● P(C) known as the prior probability ● P(C | A) known as the posterior probability Example of Bayes Theorem ● Given: – A doctor knows that meningitis causes stiff neck 50% of the time – Prior probability of any patient having meningitis is 1/50,000 – Prior probability of any patient having stiff neck is 1/20 ● If a patient has stiff neck, what’s the probability he/she has meningitis? P(S | M )P(M ) 0.5×1/50000 P(M | S) = = = 0.0002 P(S) 1/ 20 Bayesian Classifiers ● Consider each attribute and class label as random variables ● Given a record with attributes (A1, A2,…,An) – Goal is to predict class C – Specifically, we want to find the value of C that maximizes P(C| A1, A2,…,An ) ● Can we estimate -

The Bayesian Approach to Statistics
THE BAYESIAN APPROACH TO STATISTICS ANTHONY O’HAGAN INTRODUCTION the true nature of scientific reasoning. The fi- nal section addresses various features of modern By far the most widely taught and used statisti- Bayesian methods that provide some explanation for the rapid increase in their adoption since the cal methods in practice are those of the frequen- 1980s. tist school. The ideas of frequentist inference, as set out in Chapter 5 of this book, rest on the frequency definition of probability (Chapter 2), BAYESIAN INFERENCE and were developed in the first half of the 20th century. This chapter concerns a radically differ- We first present the basic procedures of Bayesian ent approach to statistics, the Bayesian approach, inference. which depends instead on the subjective defini- tion of probability (Chapter 3). In some respects, Bayesian methods are older than frequentist ones, Bayes’s Theorem and the Nature of Learning having been the basis of very early statistical rea- Bayesian inference is a process of learning soning as far back as the 18th century. Bayesian from data. To give substance to this statement, statistics as it is now understood, however, dates we need to identify who is doing the learning and back to the 1950s, with subsequent development what they are learning about. in the second half of the 20th century. Over that time, the Bayesian approach has steadily gained Terms and Notation ground, and is now recognized as a legitimate al- ternative to the frequentist approach. The person doing the learning is an individual This chapter is organized into three sections. -

Scalable and Robust Bayesian Inference Via the Median Posterior
Scalable and Robust Bayesian Inference via the Median Posterior CS 584: Big Data Analytics Material adapted from David Dunson’s talk (http://bayesian.org/sites/default/files/Dunson.pdf) & Lizhen Lin’s ICML talk (http://techtalks.tv/talks/scalable-and-robust-bayesian-inference-via-the-median-posterior/61140/) Big Data Analytics • Large (big N) and complex (big P with interactions) data are collected routinely • Both speed & generality of data analysis methods are important • Bayesian approaches offer an attractive general approach for modeling the complexity of big data • Computational intractability of posterior sampling is a major impediment to application of flexible Bayesian methods CS 584 [Spring 2016] - Ho Existing Frequentist Approaches: The Positives • Optimization-based approaches, such as ADMM or glmnet, are currently most popular for analyzing big data • General and computationally efficient • Used orders of magnitude more than Bayes methods • Can exploit distributed & cloud computing platforms • Can borrow some advantages of Bayes methods through penalties and regularization CS 584 [Spring 2016] - Ho Existing Frequentist Approaches: The Drawbacks • Such optimization-based methods do not provide measure of uncertainty • Uncertainty quantification is crucial for most applications • Scalable penalization methods focus primarily on convex optimization — greatly limits scope and puts ceiling on performance • For non-convex problems and data with complex structure, existing optimization algorithms can fail badly CS 584 [Spring 2016] - -

Using Epidemiological Evidence in Tort Law: a Practical Guide Aleksandra Kobyasheva
Using epidemiological evidence in tort law: a practical guide Aleksandra Kobyasheva Introduction Epidemiology is the study of disease patterns in populations which seeks to identify and understand causes of disease. By using this data to predict how and when diseases are likely to arise, it aims to prevent the disease and its consequences through public health regulation or the development of medication. But can this data also be used to tell us something about an event that has already occurred? To illustrate, consider a case where a claimant is exposed to a substance due to the defendant’s negligence and subsequently contracts a disease. There is not enough evidence available to satisfy the traditional ‘but-for’ test of causation.1 However, an epidemiological study shows that there is a potential causal link between the substance and the disease. What is, or what should be, the significance of this study? In Sienkiewicz v Greif members of the Supreme Court were sceptical that epidemiological evidence can have a useful role to play in determining questions of causation.2 The issue in that case was a narrow one that did not present the full range of concerns raised by epidemiological evidence, but the court’s general attitude was not unusual. Few English courts have thought seriously about the ways in which epidemiological evidence should be approached or interpreted; in particular, the factors which should be taken into account when applying the ‘balance of probability’ test, or the weight which should be attached to such factors. As a result, this article aims to explore this question from a practical perspective. -

LINEAR REGRESSION MODELS Likelihood and Reference Bayesian
{ LINEAR REGRESSION MODELS { Likeliho o d and Reference Bayesian Analysis Mike West May 3, 1999 1 Straight Line Regression Mo dels We b egin with the simple straight line regression mo del y = + x + i i i where the design p oints x are xed in advance, and the measurement/sampling i 2 errors are indep endent and normally distributed, N 0; for each i = i i 1;::: ;n: In this context, wehavelooked at general mo delling questions, data and the tting of least squares estimates of and : Now we turn to more formal likeliho o d and Bayesian inference. 1.1 Likeliho o d and MLEs The formal parametric inference problem is a multi-parameter problem: we 2 require inferences on the three parameters ; ; : The likeliho o d function has a simple enough form, as wenow show. Throughout, we do not indicate the design p oints in conditioning statements, though they are implicitly conditioned up on. Write Y = fy ;::: ;y g and X = fx ;::: ;x g: Given X and the mo del 1 n 1 n parameters, each y is the corresp onding zero-mean normal random quantity i plus the term + x ; so that y is normal with this term as its mean and i i i 2 variance : Also, since the are indep endent, so are the y : Thus i i 2 2 y j ; ; N + x ; i i with conditional density function 2 2 2 2 1=2 py j ; ; = expfy x =2 g=2 i i i for each i: Also, by indep endence, the joint density function is n Y 2 2 : py j ; ; = pY j ; ; i i=1 1 Given the observed resp onse values Y this provides the likeliho o d function for the three parameters: the joint density ab ove evaluated at the observed and 2 hence now xed values of Y; now viewed as a function of ; ; as they vary across p ossible parameter values. -

1 Estimation and Beyond in the Bayes Universe
ISyE8843A, Brani Vidakovic Handout 7 1 Estimation and Beyond in the Bayes Universe. 1.1 Estimation No Bayes estimate can be unbiased but Bayesians are not upset! No Bayes estimate with respect to the squared error loss can be unbiased, except in a trivial case when its Bayes’ risk is 0. Suppose that for a proper prior ¼ the Bayes estimator ±¼(X) is unbiased, Xjθ (8θ)E ±¼(X) = θ: This implies that the Bayes risk is 0. The Bayes risk of ±¼(X) can be calculated as repeated expectation in two ways, θ Xjθ 2 X θjX 2 r(¼; ±¼) = E E (θ ¡ ±¼(X)) = E E (θ ¡ ±¼(X)) : Thus, conveniently choosing either EθEXjθ or EX EθjX and using the properties of conditional expectation we have, θ Xjθ 2 θ Xjθ X θjX X θjX 2 r(¼; ±¼) = E E θ ¡ E E θ±¼(X) ¡ E E θ±¼(X) + E E ±¼(X) θ Xjθ 2 θ Xjθ X θjX X θjX 2 = E E θ ¡ E θ[E ±¼(X)] ¡ E ±¼(X)E θ + E E ±¼(X) θ Xjθ 2 θ X X θjX 2 = E E θ ¡ E θ ¢ θ ¡ E ±¼(X)±¼(X) + E E ±¼(X) = 0: Bayesians are not upset. To check for its unbiasedness, the Bayes estimator is averaged with respect to the model measure (Xjθ), and one of the Bayesian commandments is: Thou shall not average with respect to sample space, unless you have Bayesian design in mind. Even frequentist agree that insisting on unbiasedness can lead to bad estimators, and that in their quest to minimize the risk by trading off between variance and bias-squared a small dosage of bias can help. -

Analysis of Scientific Research on Eyewitness Identification
ANALYSIS OF SCIENTIFIC RESEARCH ON EYEWITNESS IDENTIFICATION January 2018 Patricia A. Riley U.S. Attorney’s Office, DC Table of Contents RESEARCH DOES NOT PROVIDE A FIRM FOUNDATION FOR JURY INSTRUCTIONS OF THE TYPE ADOPTED BY SOME COURTS OR, IN SOME INSTANCES, FOR EXPERT TESTIMONY ...................................................... 6 RESEARCH DOES NOT PROVIDE A FIRM FOUNDATION FOR JURY INSTRUCTIONS OF THE TYPE ADOPTED BY SOME COURTS AND, IN SOME INSTANCES, FOR EXPERT TESTIMONY .................................................... 8 Introduction ............................................................................................................................................. 8 Courts should not comment on the evidence or take judicial notice of contested facts ................... 11 Jury Instructions based on flawed or outdated research should not be given .................................. 12 AN OVERVIEW OF THE RESEARCH ON EYEWITNESS IDENTIFICATION OF STRANGERS, NEW AND OLD .... 16 Important Points .................................................................................................................................... 16 System Variables .................................................................................................................................... 16 Simultaneous versus sequential presentation ................................................................................... 16 Double blind, blind, blinded administration (unless impracticable ...................................................