Deep Reinforcement Learning: a Brief Introduction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Artificial Intelligence in Health Care: the Hope, the Hype, the Promise, the Peril
Artificial Intelligence in Health Care: The Hope, the Hype, the Promise, the Peril Michael Matheny, Sonoo Thadaney Israni, Mahnoor Ahmed, and Danielle Whicher, Editors WASHINGTON, DC NAM.EDU PREPUBLICATION COPY - Uncorrected Proofs NATIONAL ACADEMY OF MEDICINE • 500 Fifth Street, NW • WASHINGTON, DC 20001 NOTICE: This publication has undergone peer review according to procedures established by the National Academy of Medicine (NAM). Publication by the NAM worthy of public attention, but does not constitute endorsement of conclusions and recommendationssignifies that it is the by productthe NAM. of The a carefully views presented considered in processthis publication and is a contributionare those of individual contributors and do not represent formal consensus positions of the authors’ organizations; the NAM; or the National Academies of Sciences, Engineering, and Medicine. Library of Congress Cataloging-in-Publication Data to Come Copyright 2019 by the National Academy of Sciences. All rights reserved. Printed in the United States of America. Suggested citation: Matheny, M., S. Thadaney Israni, M. Ahmed, and D. Whicher, Editors. 2019. Artificial Intelligence in Health Care: The Hope, the Hype, the Promise, the Peril. NAM Special Publication. Washington, DC: National Academy of Medicine. PREPUBLICATION COPY - Uncorrected Proofs “Knowing is not enough; we must apply. Willing is not enough; we must do.” --GOETHE PREPUBLICATION COPY - Uncorrected Proofs ABOUT THE NATIONAL ACADEMY OF MEDICINE The National Academy of Medicine is one of three Academies constituting the Nation- al Academies of Sciences, Engineering, and Medicine (the National Academies). The Na- tional Academies provide independent, objective analysis and advice to the nation and conduct other activities to solve complex problems and inform public policy decisions. -

Artificial Intelligence: with Great Power Comes Great Responsibility
ARTIFICIAL INTELLIGENCE: WITH GREAT POWER COMES GREAT RESPONSIBILITY JOINT HEARING BEFORE THE SUBCOMMITTEE ON RESEARCH AND TECHNOLOGY & SUBCOMMITTEE ON ENERGY COMMITTEE ON SCIENCE, SPACE, AND TECHNOLOGY HOUSE OF REPRESENTATIVES ONE HUNDRED FIFTEENTH CONGRESS SECOND SESSION JUNE 26, 2018 Serial No. 115–67 Printed for the use of the Committee on Science, Space, and Technology ( Available via the World Wide Web: http://science.house.gov U.S. GOVERNMENT PUBLISHING OFFICE 30–877PDF WASHINGTON : 2018 COMMITTEE ON SCIENCE, SPACE, AND TECHNOLOGY HON. LAMAR S. SMITH, Texas, Chair FRANK D. LUCAS, Oklahoma EDDIE BERNICE JOHNSON, Texas DANA ROHRABACHER, California ZOE LOFGREN, California MO BROOKS, Alabama DANIEL LIPINSKI, Illinois RANDY HULTGREN, Illinois SUZANNE BONAMICI, Oregon BILL POSEY, Florida AMI BERA, California THOMAS MASSIE, Kentucky ELIZABETH H. ESTY, Connecticut RANDY K. WEBER, Texas MARC A. VEASEY, Texas STEPHEN KNIGHT, California DONALD S. BEYER, JR., Virginia BRIAN BABIN, Texas JACKY ROSEN, Nevada BARBARA COMSTOCK, Virginia CONOR LAMB, Pennsylvania BARRY LOUDERMILK, Georgia JERRY MCNERNEY, California RALPH LEE ABRAHAM, Louisiana ED PERLMUTTER, Colorado GARY PALMER, Alabama PAUL TONKO, New York DANIEL WEBSTER, Florida BILL FOSTER, Illinois ANDY BIGGS, Arizona MARK TAKANO, California ROGER W. MARSHALL, Kansas COLLEEN HANABUSA, Hawaii NEAL P. DUNN, Florida CHARLIE CRIST, Florida CLAY HIGGINS, Louisiana RALPH NORMAN, South Carolina DEBBIE LESKO, Arizona SUBCOMMITTEE ON RESEARCH AND TECHNOLOGY HON. BARBARA COMSTOCK, Virginia, Chair FRANK D. LUCAS, Oklahoma DANIEL LIPINSKI, Illinois RANDY HULTGREN, Illinois ELIZABETH H. ESTY, Connecticut STEPHEN KNIGHT, California JACKY ROSEN, Nevada BARRY LOUDERMILK, Georgia SUZANNE BONAMICI, Oregon DANIEL WEBSTER, Florida AMI BERA, California ROGER W. MARSHALL, Kansas DONALD S. BEYER, JR., Virginia DEBBIE LESKO, Arizona EDDIE BERNICE JOHNSON, Texas LAMAR S. -

AI Computer Wraps up 4-1 Victory Against Human Champion Nature Reports from Alphago's Victory in Seoul
The Go Files: AI computer wraps up 4-1 victory against human champion Nature reports from AlphaGo's victory in Seoul. Tanguy Chouard 15 March 2016 SEOUL, SOUTH KOREA Google DeepMind Lee Sedol, who has lost 4-1 to AlphaGo. Tanguy Chouard, an editor with Nature, saw Google-DeepMind’s AI system AlphaGo defeat a human professional for the first time last year at the ancient board game Go. This week, he is watching top professional Lee Sedol take on AlphaGo, in Seoul, for a $1 million prize. It’s all over at the Four Seasons Hotel in Seoul, where this morning AlphaGo wrapped up a 4-1 victory over Lee Sedol — incidentally, earning itself and its creators an honorary '9-dan professional' degree from the Korean Baduk Association. After winning the first three games, Google-DeepMind's computer looked impregnable. But the last two games may have revealed some weaknesses in its makeup. Game four totally changed the Go world’s view on AlphaGo’s dominance because it made it clear that the computer can 'bug' — or at least play very poor moves when on the losing side. It was obvious that Lee felt under much less pressure than in game three. And he adopted a different style, one based on taking large amounts of territory early on rather than immediately going for ‘street fighting’ such as making threats to capture stones. This style – called ‘amashi’ – seems to have paid off, because on move 78, Lee produced a play that somehow slipped under AlphaGo’s radar. David Silver, a scientist at DeepMind who's been leading the development of AlphaGo, said the program estimated its probability as 1 in 10,000. -

AI, Robots, and Swarms: Issues, Questions, and Recommended Studies
AI, Robots, and Swarms Issues, Questions, and Recommended Studies Andrew Ilachinski January 2017 Approved for Public Release; Distribution Unlimited. This document contains the best opinion of CNA at the time of issue. It does not necessarily represent the opinion of the sponsor. Distribution Approved for Public Release; Distribution Unlimited. Specific authority: N00014-11-D-0323. Copies of this document can be obtained through the Defense Technical Information Center at www.dtic.mil or contact CNA Document Control and Distribution Section at 703-824-2123. Photography Credits: http://www.darpa.mil/DDM_Gallery/Small_Gremlins_Web.jpg; http://4810-presscdn-0-38.pagely.netdna-cdn.com/wp-content/uploads/2015/01/ Robotics.jpg; http://i.kinja-img.com/gawker-edia/image/upload/18kxb5jw3e01ujpg.jpg Approved by: January 2017 Dr. David A. Broyles Special Activities and Innovation Operations Evaluation Group Copyright © 2017 CNA Abstract The military is on the cusp of a major technological revolution, in which warfare is conducted by unmanned and increasingly autonomous weapon systems. However, unlike the last “sea change,” during the Cold War, when advanced technologies were developed primarily by the Department of Defense (DoD), the key technology enablers today are being developed mostly in the commercial world. This study looks at the state-of-the-art of AI, machine-learning, and robot technologies, and their potential future military implications for autonomous (and semi-autonomous) weapon systems. While no one can predict how AI will evolve or predict its impact on the development of military autonomous systems, it is possible to anticipate many of the conceptual, technical, and operational challenges that DoD will face as it increasingly turns to AI-based technologies. -

The Discovery of Chinese Logic Modern Chinese Philosophy
The Discovery of Chinese Logic Modern Chinese Philosophy Edited by John Makeham, Australian National University VOLUME 1 The titles published in this series are listed at brill.nl/mcp. The Discovery of Chinese Logic By Joachim Kurtz LEIDEN • BOSTON 2011 This book is printed on acid-free paper. Library of Congress Cataloging-in-Publication Data Kurtz, Joachim. The discovery of Chinese logic / by Joachim Kurtz. p. cm. — (Modern Chinese philosophy, ISSN 1875-9386 ; v. 1) Includes bibliographical references and index. ISBN 978-90-04-17338-5 (hardback : alk. paper) 1. Logic—China—History. I. Title. II. Series. BC39.5.C47K87 2011 160.951—dc23 2011018902 ISSN 1875-9386 ISBN 978 90 04 17338 5 Copyright 2011 by Koninklijke Brill NV, Leiden, The Netherlands. Koninklijke Brill NV incorporates the imprints Brill, Global Oriental, Hotei Publishing, IDC Publishers, Martinus Nijhoff Publishers and VSP. All rights reserved. No part of this publication may be reproduced, translated, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without prior written permission from the publisher. Authorization to photocopy items for internal or personal use is granted by Koninklijke Brill NV provided that the appropriate fees are paid directly to The Copyright Clearance Center, 222 Rosewood Drive, Suite 910, Danvers, MA 01923, USA. Fees are subject to change. CONTENTS List of Illustrations ...................................................................... vii List of Tables ............................................................................. -

The AGA Song Book up to Date
3rd Edition Songs, Poems, Stories and More! Edited by Bob Felice Published by The American Go Association P.O. Box 397, Old Chelsea Station New York, N.Y., 10113-0397 Copyright 1998, 2002, 2006 in the U.S.A. by the American Go Association, except where noted. Cover illustration by Jim Rodgers. No part of this book may be used or reproduced in any form or by any means, or stored in a database or retrieval system, without prior written permission of the copyright holder, except for brief quotations used as part of a critical review. Introductions Introduction to the 1st Edition When I attended my first Go Congress three years ago I was astounded by the sheer number of silly Go songs everyone knew. At the next Congress, I wondered if all these musical treasures had ever been printed. Some research revealed that the late Bob High had put together three collections of Go songs, but the last of these appeared in 1990. Very few people had these song books, and some, like me, weren’t even aware that they existed. While new songs had been printed in the American Go Journal, there was clearly a need for a new collection of Go songs. Last year I decided to do whatever I could to bring the AGA Song Book up to date. I wanted to collect as many of the old songs as I could find, as well as the new songs that had been written since Bob High’s last song book. You are holding in your hands the book I was looking for two years ago. -

In-Datacenter Performance Analysis of a Tensor Processing Unit
In-Datacenter Performance Analysis of a Tensor Processing Unit Presented by Josh Fried Background: Machine Learning Neural Networks: ● Multi Layer Perceptrons ● Recurrent Neural Networks (mostly LSTMs) ● Convolutional Neural Networks Synapse - each edge, has a weight Neuron - each node, sums weights and uses non-linear activation function over sum Propagating inputs through a layer of the NN is a matrix multiplication followed by an activation Background: Machine Learning Two phases: ● Training (offline) ○ relaxed deadlines ○ large batches to amortize costs of loading weights from DRAM ○ well suited to GPUs ○ Usually uses floating points ● Inference (online) ○ strict deadlines: 7-10ms at Google for some workloads ■ limited possibility for batching because of deadlines ○ Facebook uses CPUs for inference (last class) ○ Can use lower precision integers (faster/smaller/more efficient) ML Workloads @ Google 90% of ML workload time at Google spent on MLPs and LSTMs, despite broader focus on CNNs RankBrain (search) Inception (image classification), Google Translate AlphaGo (and others) Background: Hardware Trends End of Moore’s Law & Dennard Scaling ● Moore - transistor density is doubling every two years ● Dennard - power stays proportional to chip area as transistors shrink Machine Learning causing a huge growth in demand for compute ● 2006: Excess CPU capacity in datacenters is enough ● 2013: Projected 3 minutes per-day per-user of speech recognition ○ will require doubling datacenter compute capacity! Google’s Answer: Custom ASIC Goal: Build a chip that improves cost-performance for NN inference What are the main costs? Capital Costs Operational Costs (power bill!) TPU (V1) Design Goals Short design-deployment cycle: ~15 months! Plugs in to PCIe slot on existing servers Accelerates matrix multiplication operations Uses 8-bit integer operations instead of floating point How does the TPU work? CISC instructions, issued by host. -

Artificial Intelligence and Big Data – Innovation Landscape Brief
ARTIFICIAL INTELLIGENCE AND BIG DATA INNOVATION LANDSCAPE BRIEF © IRENA 2019 Unless otherwise stated, material in this publication may be freely used, shared, copied, reproduced, printed and/or stored, provided that appropriate acknowledgement is given of IRENA as the source and copyright holder. Material in this publication that is attributed to third parties may be subject to separate terms of use and restrictions, and appropriate permissions from these third parties may need to be secured before any use of such material. ISBN 978-92-9260-143-0 Citation: IRENA (2019), Innovation landscape brief: Artificial intelligence and big data, International Renewable Energy Agency, Abu Dhabi. ACKNOWLEDGEMENTS This report was prepared by the Innovation team at IRENA’s Innovation and Technology Centre (IITC) with text authored by Sean Ratka, Arina Anisie, Francisco Boshell and Elena Ocenic. This report benefited from the input and review of experts: Marc Peters (IBM), Neil Hughes (EPRI), Stephen Marland (National Grid), Stephen Woodhouse (Pöyry), Luiz Barroso (PSR) and Dongxia Zhang (SGCC), along with Emanuele Taibi, Nadeem Goussous, Javier Sesma and Paul Komor (IRENA). Report available online: www.irena.org/publications For questions or to provide feedback: [email protected] DISCLAIMER This publication and the material herein are provided “as is”. All reasonable precautions have been taken by IRENA to verify the reliability of the material in this publication. However, neither IRENA nor any of its officials, agents, data or other third- party content providers provides a warranty of any kind, either expressed or implied, and they accept no responsibility or liability for any consequence of use of the publication or material herein. -
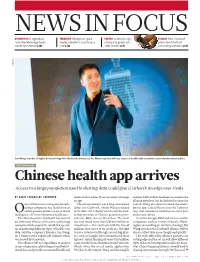
Chinese Health App Arrives Access to a Large Population Used to Sharing Data Could Give Icarbonx an Edge Over Rivals
NEWS IN FOCUS ASTROPHYSICS Legendary CHEMISTRY Deceptive spice POLITICS Scientists spy ECOLOGY New Zealand Arecibo telescope faces molecule offers cautionary chance to green UK plans to kill off all uncertain future p.143 tale p.144 after Brexit p.145 invasive predators p.148 ICARBONX Jun Wang, founder of digital biotechnology firm iCarbonX, showcases the Meum app that will use reams of health data to provide customized medical advice. BIOTECHNOLOGY Chinese health app arrives Access to a large population used to sharing data could give iCarbonX an edge over rivals. BY DAVID CYRANOSKI, SHENZHEN medical advice directly to consumers through another $400 million had been invested in the an app. alliance members, but he declined to name the ne of China’s most intriguing biotech- The announcement was a long-anticipated source. Wang also demonstrated the smart- nology companies has fleshed out an debut for iCarbonX, which Wang founded phone app, called Meum after the Latin for earlier quixotic promise to use artificial in October 2015 shortly after he left his lead- ‘my’, that customers would use to enter data Ointelligence (AI) to revolutionize health care. ership position at China’s genomics pow- and receive advice. The Shenzhen firm iCarbonX has formed erhouse, BGI, also in Shenzhen. The firm As well as Google, IBM and various smaller an ambitious alliance with seven technology has now raised more than US$600 million in companies, such as Arivale of Seattle, Wash- companies from around the world that special- investment — this contrasts with the tens of ington, are working on similar technology. But ize in gathering different types of health-care millions that most of its rivals are thought Wang says that the iCarbonX alliance will be data, said the company’s founder, Jun Wang, to have invested (although several big play- able to collect data more cheaply and quickly. -

Fml-Based Dynamic Assessment Agent for Human-Machine Cooperative System on Game of Go
Accepted for publication in International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems in July, 2017 FML-BASED DYNAMIC ASSESSMENT AGENT FOR HUMAN-MACHINE COOPERATIVE SYSTEM ON GAME OF GO CHANG-SHING LEE* MEI-HUI WANG, SHENG-CHI YANG Department of Computer Science and Information Engineering, National University of Tainan, Tainan, Taiwan *[email protected], [email protected], [email protected] PI-HSIA HUNG, SU-WEI LIN Department of Education, National University of Tainan, Tainan, Taiwan [email protected], [email protected] NAN SHUO, NAOYUKI KUBOTA Dept. of System Design, Tokyo Metropolitan University, Japan [email protected], [email protected] CHUN-HSUN CHOU, PING-CHIANG CHOU Haifong Weiqi Academy, Taiwan [email protected], [email protected] CHIA-HSIU KAO Department of Computer Science and Information Engineering, National University of Tainan, Tainan, Taiwan [email protected] Received (received date) Revised (revised date) Accepted (accepted date) In this paper, we demonstrate the application of Fuzzy Markup Language (FML) to construct an FML- based Dynamic Assessment Agent (FDAA), and we present an FML-based Human–Machine Cooperative System (FHMCS) for the game of Go. The proposed FDAA comprises an intelligent decision-making and learning mechanism, an intelligent game bot, a proximal development agent, and an intelligent agent. The intelligent game bot is based on the open-source code of Facebook’s Darkforest, and it features a representational state transfer application programming interface mechanism. The proximal development agent contains a dynamic assessment mechanism, a GoSocket mechanism, and an FML engine with a fuzzy knowledge base and rule base. -

Deepfakes & Disinformation
DEEPFAKES & DISINFORMATION DEEPFAKES & DISINFORMATION Agnieszka M. Walorska ANALYSISANALYSE 2 DEEPFAKES & DISINFORMATION IMPRINT Publisher Friedrich Naumann Foundation for Freedom Karl-Marx-Straße 2 14482 Potsdam Germany /freiheit.org /FriedrichNaumannStiftungFreiheit /FNFreiheit Author Agnieszka M. Walorska Editors International Department Global Themes Unit Friedrich Naumann Foundation for Freedom Concept and layout TroNa GmbH Contact Phone: +49 (0)30 2201 2634 Fax: +49 (0)30 6908 8102 Email: [email protected] As of May 2020 Photo Credits Photomontages © Unsplash.de, © freepik.de, P. 30 © AdobeStock Screenshots P. 16 © https://youtu.be/mSaIrz8lM1U P. 18 © deepnude.to / Agnieszka M. Walorska P. 19 © thispersondoesnotexist.com P. 19 © linkedin.com P. 19 © talktotransformer.com P. 25 © gltr.io P. 26 © twitter.com All other photos © Friedrich Naumann Foundation for Freedom (Germany) P. 31 © Agnieszka M. Walorska Notes on using this publication This publication is an information service of the Friedrich Naumann Foundation for Freedom. The publication is available free of charge and not for sale. It may not be used by parties or election workers during the purpose of election campaigning (Bundestags-, regional and local elections and elections to the European Parliament). Licence Creative Commons (CC BY-NC-ND 4.0) https://creativecommons.org/licenses/by-nc-nd/4.0 DEEPFAKES & DISINFORMATION DEEPFAKES & DISINFORMATION 3 4 DEEPFAKES & DISINFORMATION CONTENTS Table of contents EXECUTIVE SUMMARY 6 GLOSSARY 8 1.0 STATE OF DEVELOPMENT ARTIFICIAL -

Machine Theory of Mind
Machine Theory of Mind Neil C. Rabinowitz∗ Frank Perbet H. Francis Song DeepMind DeepMind DeepMind [email protected] [email protected] [email protected] Chiyuan Zhang S. M. Ali Eslami Matthew Botvinick Google Brain DeepMind DeepMind [email protected] [email protected] [email protected] Abstract 1. Introduction Theory of mind (ToM; Premack & Woodruff, For all the excitement surrounding deep learning and deep 1978) broadly refers to humans’ ability to rep- reinforcement learning at present, there is a concern from resent the mental states of others, including their some quarters that our understanding of these systems is desires, beliefs, and intentions. We propose to lagging behind. Neural networks are regularly described train a machine to build such models too. We de- as opaque, uninterpretable black-boxes. Even if we have sign a Theory of Mind neural network – a ToM- a complete description of their weights, it’s hard to get a net – which uses meta-learning to build models handle on what patterns they’re exploiting, and where they of the agents it encounters, from observations might go wrong. As artificial agents enter the human world, of their behaviour alone. Through this process, the demand that we be able to understand them is growing it acquires a strong prior model for agents’ be- louder. haviour, as well as the ability to bootstrap to Let us stop and ask: what does it actually mean to “un- richer predictions about agents’ characteristics derstand” another agent? As humans, we face this chal- and mental states using only a small number of lenge every day, as we engage with other humans whose behavioural observations.