Exploration of the Key Proteins in the Normal-Adenoma-Carcinoma Sequence of Colorectal Cancer Evolution Using In-Depth Quantitative Proteomics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Analysis of Gene Expression Data for Gene Ontology
ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION A Thesis Presented to The Graduate Faculty of The University of Akron In Partial Fulfillment of the Requirements for the Degree Master of Science Robert Daniel Macholan May 2011 ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION Robert Daniel Macholan Thesis Approved: Accepted: _______________________________ _______________________________ Advisor Department Chair Dr. Zhong-Hui Duan Dr. Chien-Chung Chan _______________________________ _______________________________ Committee Member Dean of the College Dr. Chien-Chung Chan Dr. Chand K. Midha _______________________________ _______________________________ Committee Member Dean of the Graduate School Dr. Yingcai Xiao Dr. George R. Newkome _______________________________ Date ii ABSTRACT A tremendous increase in genomic data has encouraged biologists to turn to bioinformatics in order to assist in its interpretation and processing. One of the present challenges that need to be overcome in order to understand this data more completely is the development of a reliable method to accurately predict the function of a protein from its genomic information. This study focuses on developing an effective algorithm for protein function prediction. The algorithm is based on proteins that have similar expression patterns. The similarity of the expression data is determined using a novel measure, the slope matrix. The slope matrix introduces a normalized method for the comparison of expression levels throughout a proteome. The algorithm is tested using real microarray gene expression data. Their functions are characterized using gene ontology annotations. The results of the case study indicate the protein function prediction algorithm developed is comparable to the prediction algorithms that are based on the annotations of homologous proteins. -

Small Nucleolar Rnas Determine Resistance to Doxorubicin in Human Osteosarcoma
International Journal of Molecular Sciences Article Small Nucleolar RNAs Determine Resistance to Doxorubicin in Human Osteosarcoma Martina Godel 1, Deborah Morena 1, Preeta Ananthanarayanan 1, Ilaria Buondonno 1, Giulio Ferrero 2,3 , Claudia M. Hattinger 4, Federica Di Nicolantonio 1,5 , Massimo Serra 4 , 1 2 1, , 1, , Riccardo Taulli , Francesca Cordero , Chiara Riganti * y and Joanna Kopecka * y 1 Department of Oncology, University of Torino, 1026 Torino, Italy; [email protected] (M.G.); [email protected] (D.M.); [email protected] (P.A.); [email protected] (I.B.); [email protected] (F.D.N.); [email protected] (R.T.) 2 Department of Computer Science, University of Torino, 10149 Torino, Italy; [email protected] (G.F.); [email protected] (F.C.) 3 Department of Clinical and Biological Sciences, University of Torino, 10043 Orbassano, Italy 4 Laboratory of Experimental Oncology, Pharmacogenomics and Pharmacogenetics Research Unit, IRCCS Istituto Ortopedico Rizzoli, 40136 Bologna, Italy; [email protected] (C.M.H.); [email protected] (M.S.) 5 Candiolo Cancer Institute, FPO–IRCCS, 10060 Candiolo, Italy * Correspondence: [email protected] (C.R.); [email protected] (J.K.); Tel.: +39-0116705857 (C.R.); +39-0116705849 (J.K.) These authors equally contributed to this work. y Received: 31 May 2020; Accepted: 21 June 2020; Published: 24 June 2020 Abstract: Doxorubicin (Dox) is one of the most important first-line drugs used in osteosarcoma therapy. Multiple and not fully clarified mechanisms, however, determine resistance to Dox. With the aim of identifying new markers associated with Dox-resistance, we found a global up-regulation of small nucleolar RNAs (snoRNAs) in human Dox-resistant osteosarcoma cells. -

Investigation of the Underlying Hub Genes and Molexular Pathogensis in Gastric Cancer by Integrated Bioinformatic Analyses
bioRxiv preprint doi: https://doi.org/10.1101/2020.12.20.423656; this version posted December 22, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Investigation of the underlying hub genes and molexular pathogensis in gastric cancer by integrated bioinformatic analyses Basavaraj Vastrad1, Chanabasayya Vastrad*2 1. Department of Biochemistry, Basaveshwar College of Pharmacy, Gadag, Karnataka 582103, India. 2. Biostatistics and Bioinformatics, Chanabasava Nilaya, Bharthinagar, Dharwad 580001, Karanataka, India. * Chanabasayya Vastrad [email protected] Ph: +919480073398 Chanabasava Nilaya, Bharthinagar, Dharwad 580001 , Karanataka, India bioRxiv preprint doi: https://doi.org/10.1101/2020.12.20.423656; this version posted December 22, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Abstract The high mortality rate of gastric cancer (GC) is in part due to the absence of initial disclosure of its biomarkers. The recognition of important genes associated in GC is therefore recommended to advance clinical prognosis, diagnosis and and treatment outcomes. The current investigation used the microarray dataset GSE113255 RNA seq data from the Gene Expression Omnibus database to diagnose differentially expressed genes (DEGs). Pathway and gene ontology enrichment analyses were performed, and a proteinprotein interaction network, modules, target genes - miRNA regulatory network and target genes - TF regulatory network were constructed and analyzed. Finally, validation of hub genes was performed. The 1008 DEGs identified consisted of 505 up regulated genes and 503 down regulated genes. -

Molecular Effects of Isoflavone Supplementation Human Intervention Studies and Quantitative Models for Risk Assessment
Molecular effects of isoflavone supplementation Human intervention studies and quantitative models for risk assessment Vera van der Velpen Thesis committee Promotors Prof. Dr Pieter van ‘t Veer Professor of Nutritional Epidemiology Wageningen University Prof. Dr Evert G. Schouten Emeritus Professor of Epidemiology and Prevention Wageningen University Co-promotors Dr Anouk Geelen Assistant professor, Division of Human Nutrition Wageningen University Dr Lydia A. Afman Assistant professor, Division of Human Nutrition Wageningen University Other members Prof. Dr Jaap Keijer, Wageningen University Dr Hubert P.J.M. Noteborn, Netherlands Food en Consumer Product Safety Authority Prof. Dr Yvonne T. van der Schouw, UMC Utrecht Dr Wendy L. Hall, King’s College London This research was conducted under the auspices of the Graduate School VLAG (Advanced studies in Food Technology, Agrobiotechnology, Nutrition and Health Sciences). Molecular effects of isoflavone supplementation Human intervention studies and quantitative models for risk assessment Vera van der Velpen Thesis submitted in fulfilment of the requirements for the degree of doctor at Wageningen University by the authority of the Rector Magnificus Prof. Dr M.J. Kropff, in the presence of the Thesis Committee appointed by the Academic Board to be defended in public on Friday 20 June 2014 at 13.30 p.m. in the Aula. Vera van der Velpen Molecular effects of isoflavone supplementation: Human intervention studies and quantitative models for risk assessment 154 pages PhD thesis, Wageningen University, Wageningen, NL (2014) With references, with summaries in Dutch and English ISBN: 978-94-6173-952-0 ABSTRact Background: Risk assessment can potentially be improved by closely linked experiments in the disciplines of epidemiology and toxicology. -

Candidate Gene Resequencing to Identify Rare, Pedigree-Specific Variants Influencing Healthy Aging Phenotypes in the Long Life Family Study Todd E
Druley et al. BMC Geriatrics (2016) 16:80 DOI 10.1186/s12877-016-0253-y RESEARCH ARTICLE Open Access Candidate gene resequencing to identify rare, pedigree-specific variants influencing healthy aging phenotypes in the long life family study Todd E. Druley1,2, Lihua Wang1,3, Shiow J. Lin1,3, Joseph H. Lee4,5,6, Qunyuan Zhang1,3, E. Warwick Daw1,3, Haley J. Abel1,3, Sara E. Chasnoff1,2, Enrique I. Ramos1,2, Benjamin T. Levinson1,2, Bharat Thyagarajan7, Anne B. Newman8, Kaare Christensen9, Richard Mayeux10 and Michael A. Province1,3* Abstract Background: The Long Life Family Study (LLFS) is an international study to identify the genetic components of various healthy aging phenotypes. We hypothesized that pedigree-specific rare variants at longevity-associated genes could have a similar functional impact on healthy phenotypes. Methods: We performed custom hybridization capture sequencing to identify the functional variants in 464 candidate genes for longevity or the major diseases of aging in 615 pedigrees (4,953 individuals) from the LLFS, using a multiplexed, custom hybridization capture. Variants were analyzed individually or as a group across an entire gene for association to aging phenotypes using family based tests. Results: We found significant associations to three genes and nine single variants. Most notably, we found a novel variant significantly associated with exceptional survival in the 3’ UTR OBFC1 in 13 individuals from six pedigrees. OBFC1 (chromosome 10) is involved in telomere maintenance, and falls within a linkage peak recently reported from an analysis of telomere length in LLFS families. Two different algorithms for single gene associations identified three genes with an enrichment of variation that was significantly associated with three phenotypes (GSK3B with the Healthy Aging Index, NOTCH1 with diastolic blood pressure and TP53 with serum HDL). -

Open Data for Differential Network Analysis in Glioma
International Journal of Molecular Sciences Article Open Data for Differential Network Analysis in Glioma , Claire Jean-Quartier * y , Fleur Jeanquartier y and Andreas Holzinger Holzinger Group HCI-KDD, Institute for Medical Informatics, Statistics and Documentation, Medical University Graz, Auenbruggerplatz 2/V, 8036 Graz, Austria; [email protected] (F.J.); [email protected] (A.H.) * Correspondence: [email protected] These authors contributed equally to this work. y Received: 27 October 2019; Accepted: 3 January 2020; Published: 15 January 2020 Abstract: The complexity of cancer diseases demands bioinformatic techniques and translational research based on big data and personalized medicine. Open data enables researchers to accelerate cancer studies, save resources and foster collaboration. Several tools and programming approaches are available for analyzing data, including annotation, clustering, comparison and extrapolation, merging, enrichment, functional association and statistics. We exploit openly available data via cancer gene expression analysis, we apply refinement as well as enrichment analysis via gene ontology and conclude with graph-based visualization of involved protein interaction networks as a basis for signaling. The different databases allowed for the construction of huge networks or specified ones consisting of high-confidence interactions only. Several genes associated to glioma were isolated via a network analysis from top hub nodes as well as from an outlier analysis. The latter approach highlights a mitogen-activated protein kinase next to a member of histondeacetylases and a protein phosphatase as genes uncommonly associated with glioma. Cluster analysis from top hub nodes lists several identified glioma-associated gene products to function within protein complexes, including epidermal growth factors as well as cell cycle proteins or RAS proto-oncogenes. -

Widespread Signals of Convergent Adaptation to High Altitude in Asia and America
bioRxiv preprint doi: https://doi.org/10.1101/002816; this version posted September 26, 2014. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Widespread signals of convergent adaptation to high altitude in Asia and America Matthieu Foll 1,2,3,*, Oscar E. Gaggiotti 4,5, Josephine T. Daub 1,2, Alexandra Vatsiou 5 and Laurent Excoffier 1,2 1 CMPG, Institute oF Ecology and Evolution, University oF Berne, Berne, 3012, Switzerland 2 Swiss Institute oF BioinFormatics, Lausanne, 1015, Switzerland 3 Present address: School oF LiFe Sciences, École Polytechnique Fédérale de Lausanne (EPFL), Lausanne, 1015, Switzerland 4 School oF Biology, Scottish Oceans Institute, University oF St Andrews, St Andrews, FiFe, KY16 8LB, UK 5 Laboratoire d'Ecologie Alpine (LECA), UMR 5553 CNRS-Université de Grenoble, Grenoble, France * Corresponding author: [email protected] 1 bioRxiv preprint doi: https://doi.org/10.1101/002816; this version posted September 26, 2014. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Abstract Living at high-altitude is one oF the most diFFicult challenges that humans had to cope with during their evolution. Whereas several genomic studies have revealed some oF the genetic bases oF adaptations in Tibetan, Andean and Ethiopian populations, relatively little evidence oF convergent evolution to altitude in diFFerent continents has accumulated. -

A High-Throughput Approach to Uncover Novel Roles of APOBEC2, a Functional Orphan of the AID/APOBEC Family
Rockefeller University Digital Commons @ RU Student Theses and Dissertations 2018 A High-Throughput Approach to Uncover Novel Roles of APOBEC2, a Functional Orphan of the AID/APOBEC Family Linda Molla Follow this and additional works at: https://digitalcommons.rockefeller.edu/ student_theses_and_dissertations Part of the Life Sciences Commons A HIGH-THROUGHPUT APPROACH TO UNCOVER NOVEL ROLES OF APOBEC2, A FUNCTIONAL ORPHAN OF THE AID/APOBEC FAMILY A Thesis Presented to the Faculty of The Rockefeller University in Partial Fulfillment of the Requirements for the degree of Doctor of Philosophy by Linda Molla June 2018 © Copyright by Linda Molla 2018 A HIGH-THROUGHPUT APPROACH TO UNCOVER NOVEL ROLES OF APOBEC2, A FUNCTIONAL ORPHAN OF THE AID/APOBEC FAMILY Linda Molla, Ph.D. The Rockefeller University 2018 APOBEC2 is a member of the AID/APOBEC cytidine deaminase family of proteins. Unlike most of AID/APOBEC, however, APOBEC2’s function remains elusive. Previous research has implicated APOBEC2 in diverse organisms and cellular processes such as muscle biology (in Mus musculus), regeneration (in Danio rerio), and development (in Xenopus laevis). APOBEC2 has also been implicated in cancer. However the enzymatic activity, substrate or physiological target(s) of APOBEC2 are unknown. For this thesis, I have combined Next Generation Sequencing (NGS) techniques with state-of-the-art molecular biology to determine the physiological targets of APOBEC2. Using a cell culture muscle differentiation system, and RNA sequencing (RNA-Seq) by polyA capture, I demonstrated that unlike the AID/APOBEC family member APOBEC1, APOBEC2 is not an RNA editor. Using the same system combined with enhanced Reduced Representation Bisulfite Sequencing (eRRBS) analyses I showed that, unlike the AID/APOBEC family member AID, APOBEC2 does not act as a 5-methyl-C deaminase. -

The RNA-Protein Interactome of Differentiated Kidney Tubular Epithelial Cells
BASIC RESEARCH www.jasn.org The RNA-Protein Interactome of Differentiated Kidney Tubular Epithelial Cells Michael Ignarski,1 Constantin Rill,1 Rainer W.J. Kaiser,1 Madlen Kaldirim,1 René Neuhaus,1 Reza Esmaillie,1 Xinping Li,2 Corinna Klein,3 Katrin Bohl,1 Maike Petersen,1 Christian K. Frese,3 Martin Höhne ,1 Ilian Atanassov,2 Markus M. Rinschen,1 Katja Höpker,1 Bernhard Schermer,1,4,5 Thomas Benzing,1,4,5 Christoph Dieterich,6,7 Francesca Fabretti,1 and Roman-Ulrich Müller 1,4,5 1Department II of Internal Medicine and Center for Molecular Medicine Cologne, University of Cologne, Faculty of Medicine and University Hospital of Cologne, Cologne, Germany; 2Proteomics Core Facility, Max Planck Institute for Biology of Ageing, Cologne, Germany; 3Proteomics Facility, Cologne Excellence Cluster on Cellular Stress Responses in Aging-associated Diseases, 4Nephrolab, Cologne Excellence Cluster on Cellular Stress Responses in Aging- associated Diseases, Faculty of Medicine and University Hospital Cologne, and 5Systems Biology of Ageing Cologne, University of Cologne, Cologne, Germany; 6Department of Internal Medicine III, Klaus Tschira Institute for Integrative Computational Cardiology, University Hospital Heidelberg, Heidelberg, Germany; and 7German Center for Cardiovascular Research (DZHK)–Partner site, Heidelberg/Mannheim, Germany ABSTRACT Background RNA-binding proteins (RBPs) are fundamental regulators of cellular biology that affect all steps in the generation and processing of RNA molecules. Recent evidence suggests that regulation of RBPs that modulate both RNA stability and translation may have a profound effect on the proteome. However, regulation of RBPs in clinically relevant experimental conditions has not been studied systematically. Methods We used RNA interactome capture, a method for the global identification of RBPs to characterize the global RNA‐binding proteome (RBPome) associated with polyA-tailed RNA species in murine ciliated epithelial cells of the inner medullary collecting duct. -

The Neurodegenerative Diseases ALS and SMA Are Linked at The
Nucleic Acids Research, 2019 1 doi: 10.1093/nar/gky1093 The neurodegenerative diseases ALS and SMA are linked at the molecular level via the ASC-1 complex Downloaded from https://academic.oup.com/nar/advance-article-abstract/doi/10.1093/nar/gky1093/5162471 by [email protected] on 06 November 2018 Binkai Chi, Jeremy D. O’Connell, Alexander D. Iocolano, Jordan A. Coady, Yong Yu, Jaya Gangopadhyay, Steven P. Gygi and Robin Reed* Department of Cell Biology, Harvard Medical School, 240 Longwood Ave. Boston MA 02115, USA Received July 17, 2018; Revised October 16, 2018; Editorial Decision October 18, 2018; Accepted October 19, 2018 ABSTRACT Fused in Sarcoma (FUS) and TAR DNA Binding Protein (TARDBP) (9–13). FUS is one of the three members of Understanding the molecular pathways disrupted in the structurally related FET (FUS, EWSR1 and TAF15) motor neuron diseases is urgently needed. Here, we family of RNA/DNA binding proteins (14). In addition to employed CRISPR knockout (KO) to investigate the the RNA/DNA binding domains, the FET proteins also functions of four ALS-causative RNA/DNA binding contain low-complexity domains, and these domains are proteins (FUS, EWSR1, TAF15 and MATR3) within the thought to be involved in ALS pathogenesis (5,15). In light RNAP II/U1 snRNP machinery. We found that each of of the discovery that mutations in FUS are ALS-causative, these structurally related proteins has distinct roles several groups carried out studies to determine whether the with FUS KO resulting in loss of U1 snRNP and the other two members of the FET family, TATA-Box Bind- SMN complex, EWSR1 KO causing dissociation of ing Protein Associated Factor 15 (TAF15) and EWS RNA the tRNA ligase complex, and TAF15 KO resulting in Binding Protein 1 (EWSR1), have a role in ALS. -
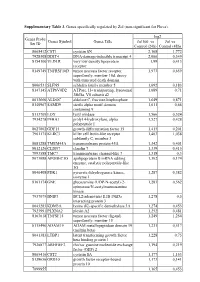
Supplementary Table 3. Genes Specifically Regulated by Zol (Non-Significant for Fluva)
Supplementary Table 3. Genes specifically regulated by Zol (non-significant for Fluva). log2 Genes Probe Genes Symbol Genes Title Zol100 vs Zol vs Set ID Control (24h) Control (48h) 8065412 CST1 cystatin SN 2,168 1,772 7928308 DDIT4 DNA-damage-inducible transcript 4 2,066 0,349 8154100 VLDLR very low density lipoprotein 1,99 0,413 receptor 8149749 TNFRSF10D tumor necrosis factor receptor 1,973 0,659 superfamily, member 10d, decoy with truncated death domain 8006531 SLFN5 schlafen family member 5 1,692 0,183 8147145 ATP6V0D2 ATPase, H+ transporting, lysosomal 1,689 0,71 38kDa, V0 subunit d2 8013660 ALDOC aldolase C, fructose-bisphosphate 1,649 0,871 8140967 SAMD9 sterile alpha motif domain 1,611 0,66 containing 9 8113709 LOX lysyl oxidase 1,566 0,524 7934278 P4HA1 prolyl 4-hydroxylase, alpha 1,527 0,428 polypeptide I 8027002 GDF15 growth differentiation factor 15 1,415 0,201 7961175 KLRC3 killer cell lectin-like receptor 1,403 1,038 subfamily C, member 3 8081288 TMEM45A transmembrane protein 45A 1,342 0,401 8012126 CLDN7 claudin 7 1,339 0,415 7993588 TMC7 transmembrane channel-like 7 1,318 0,3 8073088 APOBEC3G apolipoprotein B mRNA editing 1,302 0,174 enzyme, catalytic polypeptide-like 3G 8046408 PDK1 pyruvate dehydrogenase kinase, 1,287 0,382 isozyme 1 8161174 GNE glucosamine (UDP-N-acetyl)-2- 1,283 0,562 epimerase/N-acetylmannosamine kinase 7937079 BNIP3 BCL2/adenovirus E1B 19kDa 1,278 0,5 interacting protein 3 8043283 KDM3A lysine (K)-specific demethylase 3A 1,274 0,453 7923991 PLXNA2 plexin A2 1,252 0,481 8163618 TNFSF15 tumor necrosis -

Transcriptomic Insights Into the Morphological Variation Present in Bromeliaceae Victoria A
Western Kentucky University TopSCHOLAR® Masters Theses & Specialist Projects Graduate School 5-2015 Transcriptomic Insights into the Morphological Variation Present in Bromeliaceae Victoria A. Gilkison Western Kentucky University, [email protected] Follow this and additional works at: http://digitalcommons.wku.edu/theses Part of the Botany Commons Recommended Citation Gilkison, Victoria A., "Transcriptomic Insights into the Morphological Variation Present in Bromeliaceae" (2015). Masters Theses & Specialist Projects. Paper 1495. http://digitalcommons.wku.edu/theses/1495 This Thesis is brought to you for free and open access by TopSCHOLAR®. It has been accepted for inclusion in Masters Theses & Specialist Projects by an authorized administrator of TopSCHOLAR®. For more information, please contact [email protected]. TRANSCRIPTOMIC INSIGHTS INTO THE MORPHOLOGICAL VARIATION PRESENT IN BROMELIACEAE A Thesis Presented to The Faculty of the Department of Biology Western Kentucky University Bowling Green, Kentucky In Partial Fulfillment Of the Requirements for the Degree Masters of Science By Victoria Gilkison April 2015 ACKNOWLEDGMENTS First, I would like to thank my advisor, Dr. Rob Wyatt for helping me to design such a fun project! I enjoyed experimenting with and learning new techniques such as sequencing and bioinformatics. I learned a lot and truly enjoyed every step of the process (even the ones that included me banging my head on the desk and yelling at computers). Thank you for helping me become a more independent researcher and for allowing me to share your office. I will greatly miss our random yet educational conversations. I would also like to thank my other council members for helping me stay on track even when I was faced with “too much” data.