TWAG: a Topic-Guided Wikipedia Abstract Generator
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Examresult-Karnataka-High-Court
List of candidates who attended Prl. Examination conducted for the post of Civil Judges held on 08/12/2012, with Category and Marks obtained. Min Marks RegNo SlNo Name of the Applicant Category Marks Obtained BNG1200001 1 MANJU.S SC 30 51 BNG1200002 2 CHANDRAKALA B Cat-II(A) 40 70 BNG1200003 3 S. RAJESHWARI Cat-III(B) 40 38 BNG1200004 4 NETHRAVATHI.K.P. SC 30 38 BNG1200005 6 VEERESH KUMAR JAVALI M.C. GM 40 27 BNG1200006 9 NARASIMHA MURTHY.V.L. Cat-II(A) 40 46 BNG1200007 10 JYOTHI.N SC 30 60 BNG1200008 11 UMAJYOTHI CHINIWAL GM 40 56 BNG1200009 12 PRAVEEN G.ADAGATTI GM 40 ABSENT BNG1200010 13 RAVI.M.R. SC 30 63 BNG1200011 14 MANJUNATHA.N.G. Cat-II(A) 40 46 BNG1200012 16 D.SHIVU SC 30 54 BNG1200013 17 MANJUNATHA.S GM 40 43 BNG1200014 18 B.G.KAVITHA GM 40 56 BNG1200015 19 ERANNA.D.M. Cat-I 40 51 BNG1200016 20 PURUSHOTHAM.G SC 30 48 BNG1200017 21 HEMANTHA Cat-II(A) 40 50 BNG1200018 22 BHAVYA.N SC 30 54 BNG1200019 23 RAVISHANKAR Cat-III(B) 40 55 BNG1200020 26 RAJESH MAHADEVA GM 40 55 BNG1200021 27 GANGADHARA.C.M. Cat-III(A) 40 77 BNG1200022 28 WAHEEDA.M.M. Cat-II(B) 40 42 BNG1200023 29 HANUMANTAGOUDA SORATUR Cat-III(B) 40 50 BNG1200024 30 ANJALI.R. Cat-II(A) 40 42 BNG1200025 31 SHRIKANTH RAVINDRA GM 40 85 BNG1200026 35 SOWJANYA.A.B. GM 40 45 BNG1200027 36 CHETAN ANNADANI MANJUNATHA GM 40 82 BNG1200028 37 DUSHYANTH KUMAR.R. -

Inoperative Sb
INOPERATIVE SB ACCOUNTS SL NO ACCOUNT NUMBER CUSTOMER NAME 1 100200000032 SURESH T R 2 100200000133 NAVEEN H N * 3 100200000189 BALACHARI N M * 4 100200000202 JAYASIMHA B K 5 100200000220 SRIVIDHYA R 6 100200000225 GURURAJ C S * 7 100200000236 VASUDHA Y AITHAL * 8 100200000262 MUNICHANDRA M * 9 100200000269 VENKOBA RAO K R 10 100200000272 VIMALA H S 11 100200000564 PARASHURAMA SHARMA V * 12 100200000682 RAMDAS B S * 13 100200000715 SHANKARANARAYANA RAO T S 14 100200000752 M/S.VIDHYANIDHI - K.S.C.B.G.O. * 15 100200000768 SESHAPPA R N 16 100200000777 SHIVAKUMAR N * 17 100200000786 RAMYA VIJAY 18 100200000876 GIRIRAJ G R 19 100200000900 LEELAVATHI C S 20 100200000926 SARASWATHI A S * 21 100200001019 NAGENDRA PRASAD S 22 100200001037 BHANUPRAKASHA H V * 23 100200001086 GURU MURTHY K R * 24 100200001109 VANISHREE V S * 25 100200001183 VEENA SURESH * 26 100200001207 KRISHNA MURTHY Y N 27 100200001223 M/S.VACHAN ENTERPRISES * 28 100200001250 DESHPANDE M R 29 100200001272 ARJUN DESHPANDE * 30 100200001305 PRASANNA KUMAR S 31 100200001333 CHANDRASHEKARA H R 32 100200001401 KUMAR ARAGAM 33 100200001472 JAYALAKSMAMMA N * 34 100200001499 MOHAN RAO K * 35 100200001517 LEELA S JAIN 36 100200001523 MANJUNATH S BHAT 37 100200001557 SATYANARAYANA A * 1 38 100200001559 SHARADAMMA S * 39 100200001588 RAGHOTHAMA R * 40 100200001589 SRIDHARA RAO B S * 41 100200001597 SUBRAMANYA K N * 42 100200001635 SIMHA V N * 43 100200001656 SUMA PRAKASH 44 100200001679 INDIRESHA T V * 45 100200001691 AJAY H A 46 100200001718 VISHWANATH K N 47 100200001733 SREEKANTA MURTHY -
Himachal Futuristic Communications Limited
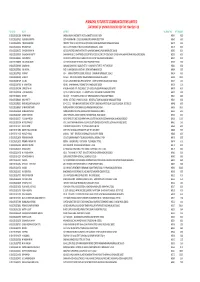
HIMACHAL FUTURISTIC COMMUNICATIONS LIMITED STATEMENT OF UNPAID DIVIDEND FOR THE YEAR 2017‐18 FOLIO NO NAME ADDRESS WARRANT NO NET AMOUNT IN30113526032896 PAVAN NAYAK SHOBHA NILAYA CHEGRIBETTU POST BAIDABETTU UDUPI 576234 66363 6.00 IN30113526037023 K SACHIEN ACHARYA 3875 ANUGRAHA M C C B BLOCK DAVANGERE DAVANAGERE 577004 66365 0.60 IN30113526046561 Y BHAGYALAKSHMI 'AMRUTH NIVAS' NO 14/2 1ST FLOOR 4TH MODEL HOUSE BASAVANGUDI BANGALORE 560004 66375 0.48 IN30113526050366 N RAJASHEKAR NO 671 11TH B MAIN 5TH BLOCK JAYANAGAR BANGALORE 560047 66379 0.60 IN30113526060752 CHANDRASHEKAR N NO 5163 PRESTIGE SHANTINIKETAN ITPL MAIN ROAD MAHADEVPURA BANGALORE 560048 66392 0.30 IN30113526063675 SHASHIDHARA SHETTY SHASHIDHARA & CO. CHARTERED ACCOUNTANTS NO 5/19 FLOOR 11TH CROSS WCR II STAGE MAHALAKSHMIPURAM BANGALORE 560086 66395 6.00 IN30113526065513 K RAVINDRAN NO 100 SRI VANAYAKA NILAYA BABUSABPALYA KALYAN NAGAR BANGALORE 560043 66397 0.30 IN30113526068085 K N UMA SHANKAR C/O Y D PUTTANAIAH 7TH ROAD K R NAGAR MYSORE 571602 66398 3.00 IN30113526069166 JAYARAM M SANNAMPADY HOUSE P.O.GOLITHOTTU VIA NELYADI PUTTUR TQ. PUTTUR 574229 66401 0.60 IN30113526070963 K N ANITHA W/O K S NAGESH BILWA KUNTA N R EXTN CHINTAMANI 563125 66404 3.00 IN30113526077692 K S BHAT NO 4 NANDA THEATRE BUILDING 3RD BLOCK JAYANAGAR BANGALORE 560011 66414 0.60 IN30113526082292 G SURESH NO 1676 2ND CROSS PRAKASH NAGAR BANGALORE BANGALORE 560021 66420 30.00 IN30113526087729 K SUMA C/O A N AMARA NARAYANA PHOTOGRAPHER DOOR NO 939 BIG BAZZAR KOLAR 563101 66427 1.20 IN30113526087995 -

6Th Entrance Examination -2020 Allotted List
6TH ENTRANCE EXAMINATION -2020 ALLOTTED LIST - 3rd ROUND 14/07/21 District:BAGALKOT School: 0266- SC/ST(T)( GEN) BAGALKOTE(PRATIBANVITA), BAGALKOTE Sl CET NO Candidate Name CET Rank ALLOT CATEG 1 FB339 PARWATI PATIL 131 GMF 2 FA149 PARVIN WATHARAD WATHARAD 13497 2BF 3 FM010 LAVANYA CHANDRAPPA CHALAVADI 17722 SCF 4 FP011 ISHWARI JALIHAL 3240 GMF 5 FM033 SANJANA DUNDAPPA BALLUR 3329 GMF 6 FK014 SHRUSTI KUMBAR 3510 GMF 7 FU200 BANDAVVA SHANKAR IRAPPANNAVAR 3646 GMF 8 FV062 SAHANA SHRISHAIL PATIL 3834 GMF 9 FM336 BIBIPATHIMA THASILDHAR THASILDHAR 4802 2BF 10 FD100 SUNITA LAMANI 53563 SCF 11 FH140 LAXMI PARASAPPA BISANAL 53809 STF 12 FL414 VARSHA VENKATESH GOUDAR 5510 3AF 13 FE285 RUKMINI CHENNADASAR 67399 SCF School: 0267- MDRS(H)( BC) KAVIRANNA, MUDHOL Sl CET NO Candidate Name CET Rank ALLOT CATEG 1 FM298 PRAJWALAGOUDA HALAGATTI 1039 GMM 2 FS510 VISHWAPRASAD VENKAPPA LAKSHANATTI 1109 GMM 3 FM328 LALBI WALIKAR 16027 2BF 4 FF038 SWATI BASAVARAJ PATIL 1743 GMF 5 FX194 RAHUL BAVALATTI 22527 STM 6 FL443 SHREELAKSHMI B KULAKARNI 2894 GMF 7 FR225 GEETAA SHIVAPPA KADAPATTI 3292 2AF 8 FU054 KAVYA DODDAVVA MERTI 53654 SCF 9 FT283 PUJA KOTTALAGI 64514 STF 10 FX248 SAMARTH SHIVANAND HALAGANI 883 GMM School: 0268- MDRS(U)( SC) MUCHAKHANDI, BAGALKOTE Sl CET NO Candidate Name CET Rank ALLOT CATEG 1 FE505 SHREEYAS SIDDAPPA GADDI 19156 STM 2 FP158 CHETAN LAMANI 33481 SCM 3 FB165 LOKESH V LAMANI 34878 SCM 4 FH101 PREM GANGARAM LAMANI 35697 SCM 5 FC321 SHRIKANTH BASAVARAJ LAMANI 35928 SCM 6 FD200 BHAGYASHREE SEETARAM LAMANI 54723 SCF 7 FE525 VAISHALI DHAKAPPA -

National Conference On
REPORT NATIONAL CONFERENCE CHILDREN IN DISASTERS & EMERGENCIES: UNDERSTANDING VULNERABILITY, DEVELOPING CAPACITIES & PROMOTING RESILIENCE March 08-10, 2021 Organized By CHILD CENTRIC DISASTER RISK REDUCTION CENTRE (CCDRR), NIDM & SAVE THE CHILDREN Knowledge Partners 1 CHILDREN IN DISASTERS & EMERGENCIES: UNDERSTANDING VULNERABILITY, DEVELOPING CAPACITIES & PROMOTING RESILIENCE “CHILDREN CAN’T WAIT” CONTENTS S. No. Topic Pg. No 1 About the Conference 03 - 06 2 Programme & Session Schedule 07 - 10 3 Inaugural Session 11 - 13 4 Context Setting Session 13 - 15 5 Day 1 - Theme: Understanding Vulnerabilities – Protecting 15 - 16 Children in All Context of Disasters & Emergencies 6 Day 2 - Theme: Developing Capacities – All Children are 17 - 26 Safe, Learn and Thrive 7 Day 3 – Theme: Promoting Resilience – Commitment to 27 - 36 Reaching the Most Marginalised and Vulnerable Children 8 Valedictory Session 36 - 38 9 Summary of Recommendations 39 - 41 10 Profile of Speakers and Domain Experts 42 - 51 11 Profile of Programme Convenor & Coordinators 52 - 53 12 Annexure 1: List of Participants 54 - 151 2 1. About the Conference 1.1 BACKGROUND India is vulnerable to a large number of hazards which is compounded by increasing vulnerabilities related to changing demographics and socio-economic conditions, unplanned urbanization, development within high-risk zones, environmental degradation, climate change, geological hazards, epidemics and pandemics. This poses a serious threat to India’s overall economy, its population and sustainable development. Vulnerability from disasters varies from one community to the other and in space. Community’s preparedness always plays an important role in reducing disasters and emergency risk and vulnerability. India’s total Child population is (164.5 million1) as compared to the total 328.46 million2 US population; more than half of the total US population. -
To Download Branch Wise Placement Data in Pdf Format
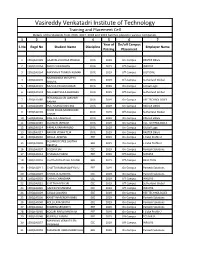
Vasireddy Venkatadri Institute of Technology Training and Placement Cell Details of the Students from 2016, 2017, 2018 and 2019 batches placed in various companies 1 2 3 4 5 6 7 Year of On/off Campus S.No Regd No Student Name Discipline Employer Name Passing Placement 1 15BQ1A0129 GAJAVALLI DURGA PRASAD CIVIL 2019 On-Campus RASTER ENGG 2 15BQ1A0154 MADA VISWANATH CIVIL 2019 Off-Campus INFOSYS 3 15BQ1A0164 MANNAVA THARUN KUMAR CIVIL 2019 Off-Campus JUST DIAL MUDIGONDA SRI SATYA 4 15BQ1A0170 CIVIL 2019 Off-Campus Sutherland Global SRAVYA 5 15BQ1A0172 MUVVA PAVAN KUMAR CIVIL 2019 On-Campus Global Logic 6 15BQ1A0174 NALLABOTHULA BHARGAV CIVIL 2019 Off-Campus Sutherland Global PERUMALLA SRI LAKSHMI 7 15BQ1A0185 CIVIL 2019 On-Campus VEE TECHNOLOGIES RAMYA 8 15BQ1A0193 PULI MURALI KRISHNA CIVIL 2019 On-Campus RASTER ENGG SHAIK KHAJA MOINUDDIN 9 15BQ1A0199 CIVIL 2019 Off-Campus Sutherland Global CHISTY 10 15BQ1A01A6 SWETHA TADEPALLI CIVIL 2019 On-Campus RASTER ENGG 11 15BQ1A01B7 VELINENI JAHNAVI CIVIL 2019 On-Campus VEE TECHNOLOGIES 12 16BQ5A0114 PARALA VARAPRASAD CIVIL 2019 On-Campus Global Logic 13 16BQ5A0117 RAVURI VISWA TEJA CIVIL 2019 On-Campus RASTER ENGG 14 15BQ1A0202 AKILLA. APARNA EEE 2019 On-Campus L Cube Profile 2 ALLAMUDI SREE LALITHA 15 15BQ1A0203 EEE 2019 On-Campus L Cube Profile 2 DEEPTHI 16 15BQ1A0207 B SESHA SAI EEE 2019 On-Campus Pantech Solutions 17 15BQ1A0214 CHAGALA HARINI EEE 2019 Off-Campus SONATA 18 15BQ1A0216 CHATHARASUPALLI.PAVANI EEE 2019 Off-Campus RSAC TECH 19 15BQ1A0217 CHATTU RAMANJANEYULU EEE 2019 On-Campus Pantech -

Banner Name Proprietor Partner BANNER LIST
BANNER LIST Banner Name Proprietor Partner 1234 Cine Creations C.R.Loknath Anand L 1895 Dec 28 the World Ist Movie Production S.Selvaraj No 2 Streams Media P Ltd., Prakash Belavadi S.Nandakumar 21st Century Lions Cinema (P) Ltd., Nagathihalli Chandrashekar No 24 Frames Pramodh B.V No 24 Frames Cine Combines Srinivasulu J Gayathri 24 Frames Movie Productions (p) Ltd K.V.Vikram Dutt K.Venkatesh Dutt 3A Cine Productions Sanjiv Kumar Gavandi No 4D Creations Gurudatta R No 7 Star Entertainment Studios Kiran Kumar.M.G No A & A Associates Aradhya V.S No A B M Productions P.S.Bhanu Prakash P.S.Anil Kumar A' Entertainers Rajani Jagannath J No A Frame To Frame Movies Venkatesh.M No A.A.Combines Praveen Arvind Gurjer N.S.Rajkumar A.B.C.Creations Anand S Nayamagowda No A.C.C.Cinema - Shahabad Cement Works. M.N.Lal T.N.Shankaran A.G.K.Creations M.Ganesh Mohamad Azeem A.J.Films R.Ashraf No A.K.Combines Akbar Basha S Dr. S.R.Kamal (Son) A.K.Films Syed Karim Anjum Syed Kalimulla A.K.K. Entertainment Ltd Ashok Kheny A.Rudragowda (Director) A.K.N.D.Enterprises - Bangalore N.K.Noorullah No A.L.Films Lokesh H.K No A.L.K.Creations C.Thummala No A.M.J.Films Janardhana A.M No A.M.M.Pictures Prakash Babu N.K No A.M.M.Pictures Prakash Babu N.K No A.M.Movies Nazir Khan No A.M.N.Film Distributor Syed Alimullah Syed Nadimullah A.M.V.Productions Ramu V No A.N.Jagadish Jagadish A.N Mamatha A.J(Wife) A.N.Pictures U.Upendra Kumar Basu No A.N.Ramesh A.N.Ramesh A.R.Chaya A.N.S.Cine Productions Sunanda M B.N.Gangadhar (Husband) A.N.S.Films Sneha B.G B.N.Gangadhar (Father) A.N.S.Productions Gangadhar B.N No A.P.Helping Creations Annopoorna H.T M.T.Ramesh A.R.Combines Ashraf Kumar K.S.Prakash A.R.J.Films Chand Pasha Sardar Khan A.R.Productions K.S.Raman No A.R.S.Enterprises H.M.Anand Raju No A.S.Films Noorjhan Mohd Asif A.S.Ganesha Films Dr.T.Krishnaveni No A.S.K.Combines Aruni Rudresh No A.S.K.Films A.S.Sheela Rudresh A.S.Rudresh A.T.R.Films Raghu A.T. -

Annexure 1B 18416
Annexure 1 B List of taxpayers allotted to State having turnover of more than or equal to 1.5 Crore Sl.No Taxpayers Name GSTIN 1 BROTHERS OF ST.GABRIEL EDUCATION SOCIETY 36AAAAB0175C1ZE 2 BALAJI BEEDI PRODUCERS PRODUCTIVE INDUSTRIAL COOPERATIVE SOCIETY LIMITED 36AAAAB7475M1ZC 3 CENTRAL POWER RESEARCH INSTITUTE 36AAAAC0268P1ZK 4 CO OPERATIVE ELECTRIC SUPPLY SOCIETY LTD 36AAAAC0346G1Z8 5 CENTRE FOR MATERIALS FOR ELECTRONIC TECHNOLOGY 36AAAAC0801E1ZK 6 CYBER SPAZIO OWNERS WELFARE ASSOCIATION 36AAAAC5706G1Z2 7 DHANALAXMI DHANYA VITHANA RAITHU PARASPARA SAHAKARA PARIMITHA SANGHAM 36AAAAD2220N1ZZ 8 DSRB ASSOCIATES 36AAAAD7272Q1Z7 9 D S R EDUCATIONAL SOCIETY 36AAAAD7497D1ZN 10 DIRECTOR SAINIK WELFARE 36AAAAD9115E1Z2 11 GIRIJAN PRIMARY COOPE MARKETING SOCIETY LIMITED ADILABAD 36AAAAG4299E1ZO 12 GIRIJAN PRIMARY CO OP MARKETING SOCIETY LTD UTNOOR 36AAAAG4426D1Z5 13 GIRIJANA PRIMARY CO-OPERATIVE MARKETING SOCIETY LIMITED VENKATAPURAM 36AAAAG5461E1ZY 14 GANGA HITECH CITY 2 SOCIETY 36AAAAG6290R1Z2 15 GSK - VISHWA (JV) 36AAAAG8669E1ZI 16 HASSAN CO OPERATIVE MILK PRODUCERS SOCIETIES UNION LTD 36AAAAH0229B1ZF 17 HCC SEW MEIL JOINT VENTURE 36AAAAH3286Q1Z5 18 INDIAN FARMERS FERTILISER COOPERATIVE LIMITED 36AAAAI0050M1ZW 19 INDU FORTUNE FIELDS GARDENIA APARTMENT OWNERS ASSOCIATION 36AAAAI4338L1ZJ 20 INDUR INTIDEEPAM MUTUAL AIDED CO-OP THRIFT/CREDIT SOC FEDERATION LIMITED 36AAAAI5080P1ZA 21 INSURANCE INFORMATION BUREAU OF INDIA 36AAAAI6771M1Z8 22 INSTITUTE OF DEFENCE SCIENTISTS AND TECHNOLOGISTS 36AAAAI7233A1Z6 23 KARNATAKA CO-OPERATIVE MILK PRODUCER\S FEDERATION -

TAMIL CINEMA Tamil Cinema
TAMIL CINEMA Tamil cinema (also known as Cinema of Tamil Nadu, the Tamil film industry or the Chennai film industry) is the film industry based in Chennai, Tamil Nadu, India, dedicated to the production of films in the Tamil language. It is based in Chennai's Kodambakkam district, where several South Indian film production companies are headquartered. Tamil cinema is known for being India's second largest film industry in terms of films produced, revenue and worldwide distribution,[1] with audiences mainly including people from the four southern Indian states of Tamil Nadu, Kerala, Andra Pradesh, and Karnataka. Silent films were produced in Chennai since 1917 and the era of talkies dawned in 1931 with the film Kalidas.[2] By the end of the 1930s, the legislature of the State of Madras passed the Entertainment Tax Act of 1939.[3] Tamil cinema later had a profound effect on other filmmaking industries of India, establishing Chennai as a secondary hub for Telugu cinema, Malayalam cinema, Kannada cinema, and Hindi cinema. The industry also inspired filmmaking in Tamil diaspora populations in other countries, such as Sri Lankan Tamil cinema and Canadian Tamil cinema.[6] Film studios in Chennai are bound by legislation, such as the Cinematography Film Rules of 1948,[7] the Cinematography Act of 1952,[8] and the Copyright Act of 1957.[9] Influences Tamil cinema has been impacted by many factors, due to which it has become the second largest film industry of India. The main impacts of the early cinema were the cultural influences of the country. The Tamil language, ancient than the Sanskrit, was the medium in which many plays and stories were written since the ages as early as the Cholas. -

STUDY on the IMPACT of CREATIVE LIBERTY USED in INDIAN HISTORICAL SHOWS and MOVIES H S Harsha Kumar HOD, Department of Journalis
INTERNATIONALJOURNAL OF MULTIDISCIPLINARYEDUCATIONALRESEARCH ISSN:2277-7881; IMPACT FACTOR :6.514(2020); IC VALUE:5.16; ISI VALUE:2.286 Peer Reviewed and Refereed Journal: VOLUME:10, ISSUE:1(4), January :2021 Online Copy Available: www.ijmer.in STUDY ON THE IMPACT OF CREATIVE LIBERTY USED IN INDIAN HISTORICAL SHOWS AND MOVIES H S Harsha Kumar HOD, Department of Journalism, Government First Grade College Vijayanagar, Bangalore Introduction Historical references in movies, shows are the latest trends in the entertainment industry. In India there are more than 150 movies and 40 T.V shows approximately produced on the historical events and records. Many of these produced by the various makers to retell the tales of glory and valour of India’s great heroes do provide justice to the heroes to some extent. Authentic and accurate depictions for the sake of knowledge or even getting the glimpses of the history is not the outcome of these shows or movies. Various inconsistencies, differences and various inaccuracies regarding the script, scenes and execution, laymen are often misdirected towards concepts. The idea of creative liberty or artistic license used by the writers to make the best of the historical references provided may cause discrepancies or irregularities difficult to accept by the people or some intellectuals. But, to demand accuracy and authenticity from the Indian historical is, for its fans, to miss the point. The genre, after all, is that the descendant of Indian traditions of myth, folklore, ballads and popular history, which have combined to inform us more about an imagined past than an actual one. -

Carvaan Mini Kannada Song List
01. Aadisinodu Beelisinodu 10. Thamnnam Thamnam 19. Ninna Nanna 28. Malenaada Henna 36. Prema Preeti Nannusiru 45. Preethine Aa Dyavaru Thanda 54. Kaalavannu Thadeyoru Yaaru 63. Ninna Kanna Notadalle Album: Kasturi Nivasa Album: Eradu Kanasu Album: Bhagyavantharu Album: Bhootayyana Maga Ayyu Album: Singapoorinalli Raja Kulla Album: Doorada Betta Album: Kittu Puttu Album: Babruvahana Artiste: P.B. Sreenivas Artistes: P.B. Sreenivas, S. Janaki Artiste: Dr. Rajkumar Artistes: P.B. Sreenivas, S. Janaki Artistes: S.P. Balasubrahmanyam, Artistes: P.B. Sreenivas, P. Susheela Artistes: K.J. Yesudas, S. Janaki Artiste: P.B. Sreenivas Lyricist: Chi Udayashankar Lyricist: Chi Udayashankar Lyricist: Chi Udayashankar Lyricist: Chi Udayashankar K.J. Yesudas Lyricist: Chi Udayashankar Lyricist: Chi Udayashankar Lyricist: Chi Udayashankar Music Director: G.K. Venkatesh Music Director: Rajan-Nagendra Music Director: Rajan-Nagendra Music Director: G.K. Venkatesh Lyricist: Chi Udayashankar Music Director: G.K. Venkatesh Music Director: Rajan-Nagendra Music Director: T.G. Lingappa Music Director: Rajan-Nagendra 02. Neerabittu Nelada Mele 11. Jeeva Veene 20. Beladingalaagi Baa 29. Cheluveya Andada 46. Thai Thai Bangari 55. Olave Jeevana - Duet (Sad) 64. Nee Nadeva Haadiyalli Album: Hombisilu Album: Hombisilu Album: Huliya Haalina Mevu Album: Devara Gudi 37. Ee Samaya Album: Giri Kanye Album: Sakshatkara Album: Bangarada Hoovu Artiste: S.P. Balasubrahmanyam Artistes: S.P. Balasubrahmanyam, S. Janaki Artiste: Dr. Rajkumar Artiste: S.P. Balasubrahmanyam Album: Babruvahana Artiste: Dr. Rajkumar Artistes: P.B. Sreenivas, P. Susheela Artistes: P. Susheela, S. Janaki Lyricist: Geethapriya Lyricist: Geethapriya Lyricist: Chi Udayashankar Lyricist: Chi Udayashankar Artistes: Dr. Rajkumar, S. Janaki Lyricist: Chi Udayashankar Lyricist: K. P. Sastry Lyricist: Vijaya Narasimha Music Director: Rajan-Nagendra Music Director: Rajan-Nagendra Music Director: G.K. -

Unpaid Dividend-15-16-I4 (PDF)
Note: This sheet is applicable for uploading the particulars related to the unclaimed and unpaid amount pending with company. Make sure that the details are in accordance with the information already provided in e-form IEPF-2 CIN/BCIN L72200KA1999PLC025564 Prefill Company/Bank Name MINDTREE LIMITED Date Of AGM(DD-MON-YYYY) 17-JUL-2018 Sum of unpaid and unclaimed dividend 759188.00 Sum of interest on matured debentures 0.00 Sum of matured deposit 0.00 Sum of interest on matured deposit 0.00 Sum of matured debentures 0.00 Sum of interest on application money due for refund 0.00 Sum of application money due for refund 0.00 Redemption amount of preference shares 0.00 Sales proceed for fractional shares 0.00 Validate Clear Proposed Date of Investor First Investor Middle Investor Last Father/Husband Father/Husband Father/Husband Last DP Id-Client Id- Amount Address Country State District Pin Code Folio Number Investment Type transfer to IEPF Name Name Name First Name Middle Name Name Account Number transferred (DD-MON-YYYY) 49/2 4TH CROSS 5TH BLOCK KORAMANGALA BANGALORE MIND00000000AZ00 Amount for unclaimed and A ANAND NA KARNATAKA INDIA Karnataka 560095 2539 unpaid dividend 72.00 28-Apr-2023 69 I FLOOR SANJEEVAPPA LAYOUT MEG COLONY JAIBHARATH NAGAR MIND00000000AZ00 Amount for unclaimed and A ANTONY FELIX NA BANGALORE INDIA Karnataka 560033 2646 unpaid dividend 72.00 28-Apr-2023 NO 198 ANUGRAHA II FLOOR OLD POLICE STATION ROAD MIND00000000AZ00 Amount for unclaimed and A G SUDHINDRA NA THYAGARAJANAGAR BANGALORE INDIA Karnataka 560028 2723 unpaid