Data-Driven Efficient Production of Cartoon Character Animation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Reallusion Premieres Iclone 1.52 - New Technology for Independent Machinima
For Immediate Release Reallusion Premieres iClone 1.52 - New Technology for Independent Machinima New York City - November 1st, 2006 – Reallusion, official Academy of Machinima Arts and Sciences’ Machinima Festival partner hits the red carpet with the iClone powered Best Visual Design nominee, “Reich and Roll”, an iClone film festival feature created by Scintilla Films, Italy. iClone™ is the 3D real-time filmmaking engine featuring complete tools for character animation, scene building, and movie directing. Leap from brainstorm to screen with advanced animation and visual effects for 3D characters, animated short-films, Machinima, or simulated training. The technology of storytelling evolves with iClone. Real-time visual effects, character interaction, and cameras all animate in with vivid quality providing storytellers instant visualization into their world. Stefano Di Carli, Director of ‘Reich and Roll’ says, “Each day I find new tricks in iClone. It's really an incredible new way of filmmaking. So Reallusion is not just hypin' a product. What you promise on the site is true. You can do movies!” Machinima is a rising genre in independent filmmaking providing storytellers with technology to bring their films to screen excluding high production costs or additional studio staff. iClone launches independent filmmakers and studios alike into a production power pack of animation tools designed to simplify character creation, facial animation, and scene production for 3D films. “iClone Independent filmmakers can commercially produce Machinima guaranteeing that the movies you make are the movies you own and may distribute or sell,” said John Martin II, Director of Product Marketing of Reallusion. “iClone’s freedom for filmmakers who desire to own and market their films supports the new real-time independent filmmaking spirit and the rise of directors who seek new technologies for the future of film.” iClone Studio 1.52 sets the stage delivering accessible directing tools to develop and debut films with speed. -

Facial Animation: Overview and Some Recent Papers
Facial animation: overview and some recent papers Benjamin Schroeder January 25, 2008 Outline Iʼll start with an overview of facial animation and its history; along the way Iʼll discuss some common approaches. After that Iʼll talk about some notable recent papers and finally offer a few thoughts about the future. 1 Defining the problem 2 Historical highlights 3 Some recent papers 4 Thoughts on the future Defining the problem Weʼll take facial animation to be the process of turning a characterʼs speech and emotional state into facial poses and motion. (This might extend to motion of the whole head.) Included here is the problem of modeling the form and articulation of an expressive head. There are some related topics that we wonʼt consider today. Autonomous characters require behavioral models to determine what they might feel or say. Hand and body gestures are often used alongside facial animation. Faithful animation of hair and rendering of skin can greatly enhance the animation of a face. Defining the problem This is a tightly defined problem, but solving it is difficult. We are intimately aware of how human faces should look, and sensitive to subtleties in the form and motion. Lip and mouth shapes donʼt correspond to individual sounds, but are context-dependent. These are further affected by the emotions of the speaker and by the language being spoken. Many different parts of the face and head work together to convey meaning. Facial anatomy is both structurally and physically complex: there are many layers of different kinds of material (skin, fat, muscle, bones). Defining the problem Here are some sub-questions to consider. -

Ipi Soft Motion Capture Software Inspires Feature Length Machinima
iPi Soft Motion Capture Software Inspires Feature Length Machinima Horror Movie Ticket Zer0 Director Ian Chisholm Uses End-to-End Markerless Performance Capture Pipeline For Character Animation; Film Now Airing on YouTube _____ MOSCOW, RUSSIA – September 25, 2018 – For his most ambitious project to date, the feature length horror film Ticket Zer0, motion capture director/writer Ian Chisholm once again leaned heavily on iPi Motion Capture, the advanced markerless motion capture technology from iPi Soft. The 66-minute animated machinima cinematic production is currently available for streaming on YouTube or Blu-Ray here. Ticket Zer0 is a follow-up to Chisholm’s Clear Skies trilogy series (viewed by hundreds of thousands on YouTube), which also used iPi Mocap throughout for performance capture. Ticket Zer0 tells the story of the night shift at a deserted industrial facility. When a troubleshooter is sent in to fix a mysterious problem, something far more sinister emerges than any of them could have imagined. Chisholm notes production for Ticket Zer0 took almost five years to complete and used iPi Motion Capture for recording movement in every single frame for all the characters in the film. “iPi Soft technology has proven to be an invaluable creative resource for me as a filmmaker during motion capture sessions,” he says. “There wasn't anything on screen that wasn't recorded by iPi Mocap. The ability to perform the motion capture was exactly what I needed to expand and improve the immersive quality of my film.” Workflow Details: For motion capture production, Chisholm used iPi Mocap in conjunction with six Sony PS3 Eye cameras along with two PlayStation Move controllers to track hand movements. -

Application of Performance Motion Capture Technology in Film and Television Performance Animation
Proceedings of the 2nd International Symposium on Computer, Communication, Control and Automation (ISCCCA-13) Application of Performance Motion Capture Technology in Film and Television Performance Animation ZHANG Manyu Dept. Animation of Art, Tianjin Academy of Fine Arts Tianjin , CHINA E-mail: [email protected] Abstract—In today’s animation films, virtual character tissue simulation technique” for the first time, so that acting animation is a research field developing rapidly in computer skills of actors can be delivered to viewers maximally. graphics, and motion capture is the most significant What’s more, people realize that “motion capture component, which has brought about revolutionary change for technology” shall be called as “performance capture 3D animation production technology. It makes that animation technology” increasingly. Orangutan Caesar presented in producers are able to drive animation image models directly with the use of actors’ performance actions and expressions, Rise of the Apes through “motion capture” technology is which has simplified animation manufacturing operation very classical. Various complicated and subtle expressions greatly and enhanced quality for animation production. and body languages of Caesar’s not vanished bestiality and initially emerged human nature have been presented Keywords- film and television films, motion capture, naturally and freshly in the film, which has achieved the technology excellent realm of mixing the false with the genuine. When Caesar stands in front of Doctor Will in equal gesture, its I. INTRODUCTION independence and arbitrariness in its expression with dignity With the development of modern computer technology, of orangutan has undoubtedly let viewers understand computer animation technology has developed rapidly. -
Motion Capture Assisted Animation: Texturing and Synthesis
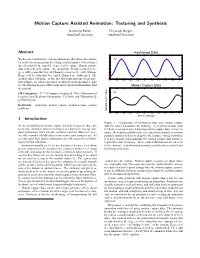
Motion Capture Assisted Animation: Texturing and Synthesis Katherine Pullen Christoph Bregler Stanford University Stanford University Abstract Keyframed Data 2 We discuss a method for creating animations that allows the anima- 0 (a) tor to sketch an animation by setting a small number of keyframes −2 on a fraction of the possible degrees of freedom. Motion capture −4 data is then used to enhance the animation. Detail is added to de- −6 grees of freedom that were keyframed, a process we call texturing. −8 Degrees of freedom that were not keyframed are synthesized. The −10 method takes advantage of the fact that joint motions of an artic- −12 ulated figure are often correlated, so that given an incomplete data 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 set, the missing degrees of freedom can be predicted from those that Motion Capture Data are present. 1 CR Categories: I.3.7 [Computer Graphics]: Three-Dimensional 0 (b) Graphics and Realism—Animation; J.5 [Arts and Humantities]: −1 performing arts −2 Keywords: animation, motion capture, motion texture, motion −3 synthesis −4 translation in inches −5 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 time in seconds 1 Introduction Figure 1: Comparison of keyframed data and motion capture As the availability of motion capture data has increased, there has data for root y translation for walking. (a) keyframed data, with been more and more interest in using it as a basis for creating com- keyframes indicated by red dots (b) motion capture data. -

First Words: the Birth of Sound Cinema
First Words The Birth of Sound Cinema, 1895 – 1929 Wednesday, September 23, 2010 Northwest Film Forum Co-Presented by The Sprocket Society Seattle, WA www.sprocketsociety.org Origins “In the year 1887, the idea occurred to me that it was possible to devise an instrument which should do for the eye what the phonograph does for the ear, and that by a combination of the two all motion and sound could be recorded and reproduced simultaneously. …I believe that in coming years by my own work and that of…others who will doubtlessly enter the field that grand opera can be given at the Metropolitan Opera House at New York [and then shown] without any material change from the original, and with artists and musicians long since dead.” Thomas Edison Foreword to History of the Kinetograph, Kinetoscope and Kineto-Phonograph (1894) by WK.L. Dickson and Antonia Dickson. “My intention is to have such a happy combination of electricity and photography that a man can sit in his own parlor and see reproduced on a screen the forms of the players in an opera produced on a distant stage, and, as he sees their movements, he will hear the sound of their voices as they talk or sing or laugh... [B]efore long it will be possible to apply this system to prize fights and boxing exhibitions. The whole scene with the comments of the spectators, the talk of the seconds, the noise of the blows, and so on will be faithfully transferred.” Thomas Edison Remarks at the private demonstration of the (silent) Kinetoscope prototype The Federation of Women’s Clubs, May 20, 1891 This Evening’s Film Selections All films in this program were originally shot on 35mm, but are shown tonight from 16mm duplicate prints. -

Creating 3DCG Animation with a Network of 3D Depth Sensors Ning
2016 International Conference on Sustainable Energy, Environment and Information Engineering (SEEIE 2016) ISBN: 978-1-60595-337-3 Creating 3DCG Animation with a Network of 3D Depth Sensors Ning-ping SUN1,*, Yohei YAMASHITA2 and Ryosuke OKUMURA1 1Dept. of Human-Oriented Information System Engineering 2Advanced Electronics and Information Systems Engineering Course, National Institute of Technology, Kumamoto College, 2659-2 Suya, Koshi, Kumamoto 861-1102, Japan *Corresponding author Keywords: Depth sensor, Network, 3D computer graphics, Animation production. Abstract. The motion capture is a useful technique for creating animations instead of manual labor, but the expensive camera based devices restrict its practical application. The emerging of inexpensive small size of depth-sensing devices provides us opportunities to reconstitute motion capture system. We introduced a network of 3D depth sensors into the production of real time 3DCG animation. Different to the existing system, the new system works well for data communication and anime rendering. We discuss below server how communicate with a group of sensors, and how we operate a group of sensors in the rendering of animation. Some results of verification experiments are provided as well. Introduction The presentation of character’s movement is very important for animation productions. In general, there are two kinds of technique to present movement in an anime. First one is a traditional method, in which animators draw a series of frames of character’s movements individually, and show these frames continuously in a short time interval. Fps, i.e., frames per second is involved the quality of an animation. The more the fps is, the better the quality becomes. -

Video Rewrite: Driving Visual Speech with Audio Christoph Bregler, Michele Covell, Malcolm Slaney Interval Research Corporation
ACM SIGGRAPH 97 Video Rewrite: Driving Visual Speech with Audio Christoph Bregler, Michele Covell, Malcolm Slaney Interval Research Corporation ABSTRACT Video Rewrite automatically pieces together from old footage a new video that shows an actor mouthing a new utterance. The Video Rewrite uses existing footage to create automatically new results are similar to labor-intensive special effects in Forest video of a person mouthing words that she did not speak in the Gump. These effects are successful because they start from actual original footage. This technique is useful in movie dubbing, for film footage and modify it to match the new speech. Modifying example, where the movie sequence can be modified to sync the and reassembling such footage in a smart way and synchronizing it actors’ lip motions to the new soundtrack. to the new sound track leads to final footage of realistic quality. Video Rewrite automatically labels the phonemes in the train- Video Rewrite uses a similar approach but does not require labor- ing data and in the new audio track. Video Rewrite reorders the intensive interaction. mouth images in the training footage to match the phoneme Our approach allows Video Rewrite to learn from example sequence of the new audio track. When particular phonemes are footage how a person’s face changes during speech. We learn what unavailable in the training footage, Video Rewrite selects the clos- a person’s mouth looks like from a video of that person speaking est approximations. The resulting sequence of mouth images is normally. We capture the dynamics and idiosyncrasies of her artic- stitched into the background footage. -

384 Cinemacraft: Immersive Live Machinima As an Empathetic
Cinemacraft: Immersive Live Machinima as an Empathetic Musical Storytelling Platform Siddharth Narayanan Ivica Ico Bukvic Electrical and Computer Engineering Institue for Creativity, Arts & Technology Virginia Tech Virginia Tech [email protected] [email protected] ABSTRACT or joystick manipulation for various body motions, rang- ing from simple actions such as walking or jumping to In the following paper we present Cinemacraft, a technology- more elaborate tasks like opening doors or pulling levers. mediated immersive machinima platform for collaborative Such an approach can often result in non-natural and po- performance and musical human-computer interaction. To tentially limiting interactions. Such interactions also lead achieve this, Cinemacraft innovates upon a reverse-engineered to profoundly different bodily experiences for the user and version of Minecraft, offering a unique collection of live may detract from the sense of immersion [10]. Modern day machinima production tools and a newly introduced Kinect game avatars are also loaded with body, posture, and ani- HD module that allows for embodied interaction, includ- mation details in an unending quest for realism and com- ing posture, arm movement, facial expressions, and a lip pelling human representations that are often stylized and syncing based on captured voice input. The result is a mal- limited due to the aforesaid limited forms of interaction. leable and accessible sensory fusion platform capable of These challenges lead to the uncanny valley problem that delivering compelling live immersive and empathetic mu- has been explored through the human likeness of digitally sical storytelling that through the use of low fidelity avatars created faces [11], and the effects of varying degrees of re- also successfully sidesteps the uncanny valley. -

FILM-GOING in the SILENT ERA Elizabeth Ezra in The
THE CINEMISING PROCESS: FILM-GOING IN THE SILENT ERA Elizabeth Ezra In the Surrealist text Nadja, published in 1928, André Breton reminisces about going to the cinema in the days ‘when, with Jacques Vaché we would settle down to dinner in the orchestra of [the cinema in] the former Théâtre des Folies- Dramatiques, opening cans, slicing bread, uncorking bottles, and talking in ordinary tones, as if around a table, to the great amazement of the spectators, who dared not say a word’ (Breton 1960 [1928]: 37). When Breton recalled these youthful antics, which had probably taken place in the late teens or early twenties, he characterized them as ‘a question of going beyond the bounds of what is “allowed,” which, in the cinema as nowhere else, prepared me to invite in the “forbidden” (Breton 1951; original emphasis). Breton’s remarks beg the following questions. How did such behaviour in a cinema come to be considered transgressive? How did the structures emerge that made it a transgressive act to speak or eat a meal in the cinema, to reject, in other words, the narrative absorption that had become a standard feature of the filmgoing experience? The conventions that gave meaning to such forms of transgression emerged over the course of the silent era in what may be called, to adapt Norbert Elias’s term, ‘the cinemizing process’ (1994). The earliest historians of cinema already relied heavily on a rhetoric of lost innocence (witness the multiple accounts of the first cinema-goers cowering under their seats in front of the Lumière brothers’ film of a train pulling into a station); the cinemizing process thus presupposes a ‘golden age’ of naive, uninitiated spectatorship followed by 2 an evolution of audiences into worldy-wise creatures of habit. -

A Software Pipeline for 3D Animation Generation Using Mocap Data and Commercial Shape Models
A Software Pipeline for 3D Animation Generation using Mocap Data and Commercial Shape Models Xin Zhang, David S. Biswas and Guoliang Fan School of Electrical and Computer Engineering Oklahoma State University Stillwater, Oklahoma, United States {xin.zhang, david.s.bisaws, guoliang.fan}@okstate.edu ABSTRACT Additionally, high-quality motion capture (mocap) data We propose a software pipeline to generate 3D animations by and realistic human shape models are two important compo- using the motion capture (mocap) data and human shape nents for animation generation, each of which involves a spe- models. The proposed pipeline integrates two animation cific skeleton definition including the number of joints, the software tools, Maya and MotionBuilder in one flow. Specif- naming convention, hierarchical relationship and underlying ically, we address the issue of skeleton incompatibility among physical meaning of each joint. Ideally, animation software the mocap data, shape models, and animation software. Our can drive a human shape model to move and articulate ac- objective is to generate both realistic and accurate motion- cording to the given mocap data and optimize the deforma- specific animation sequences. Our method is tested by three tion of the body surface with natural smoothness, as shown mocap data sets of various motion types and five commer- in Fig. 1. With the development of computer graphics and cial human shape models, and it demonstrates better visual the mocap technology, there are plenty of mocap data and realisticness and kinematic accuracy when compared with 3D human models available for various research activities. three other animation generation methods. However, due to their different sources, there is a major gap between the mocap data, shape models and animation soft- ware, which often makes animation generation a challenging Categories and Subject Descriptors task. -

Keyframe Or Motion Capture? Reflections on Education of Character Animation
EURASIA Journal of Mathematics, Science and Technology Education, 2018, 14(12), em1649 ISSN:1305-8223 (online) OPEN ACCESS Research Paper https://doi.org/10.29333/ejmste/99174 Keyframe or Motion Capture? Reflections on Education of Character Animation Tsai-Yun Mou 1* 1 National Pingtung University, TAIWAN Received 20 April 2018 ▪ Revised 12 August 2018 ▪ Accepted 13 September 2018 ABSTRACT In character animation education, the training process needs diverse domain knowledge to be covered in order to develop students with good animation ability. However, design of motion also requires digital ability, creativity and motion knowledge. Moreover, there are gaps between animation education and industry production which motion capture is widely applied. Here we try to incorporate motion capture into education and investigate whether motion capture is supportive in character animation, especially in creativity element. By comparing two kinds of motion design method, traditional keyframe and motion capture, we investigated students’ creativity in motion design. The results showed that in originality factor, keyframe method had slightly higher performance support for designing unusual motions. Nevertheless, motion capture had shown more support in creating valid actions in quantity which implied fluency factor of creativity was achieved. However, in flexibility factor, although motion capture created more emotions in amount, keyframe method actually offered higher proportion of sentiment design. Participants indicated that keyframe was helpful to design extreme poses. While motion capture provided intuitive design tool for exploring possibilities. Therefore, we propose to combine motion capture technology with keyframe method in character animation education to increase digital ability, stimulate creativity, and establish solid motion knowledge. Keywords: animation education, character animation, creativity, motion capture, virtual character INTRODUCTION The education of animation is a long-standing and multidisciplinary training.