MAKING MACHINIMA: Animation, Games and Multimodal Participation in the Media Arts Andrew Burn ABSTRACT in the Project Discussed
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Animation: Types
Animation: Animation is a dynamic medium in which images or objects are manipulated to appear as moving images. In traditional animation, images are drawn or painted by hand on transparent celluloid sheets to be photographed and exhibited on film. Today most animations are made with computer generated (CGI). Commonly the effect of animation is achieved by a rapid succession of sequential images that minimally differ from each other. Apart from short films, feature films, animated gifs and other media dedicated to the display moving images, animation is also heavily used for video games, motion graphics and special effects. The history of animation started long before the development of cinematography. Humans have probably attempted to depict motion as far back as the Paleolithic period. Shadow play and the magic lantern offered popular shows with moving images as the result of manipulation by hand and/or some minor mechanics Computer animation has become popular since toy story (1995), the first feature-length animated film completely made using this technique. Types: Traditional animation (also called cel animation or hand-drawn animation) was the process used for most animated films of the 20th century. The individual frames of a traditionally animated film are photographs of drawings, first drawn on paper. To create the illusion of movement, each drawing differs slightly from the one before it. The animators' drawings are traced or photocopied onto transparent acetate sheets called cels which are filled in with paints in assigned colors or tones on the side opposite the line drawings. The completed character cels are photographed one-by-one against a painted background by rostrum camera onto motion picture film. -

Cel Animation and Define the Words That
Chapter 5-Animation Objective The students will be able to: define animation and describe how it can be used in multimedia. discuss the origins of cel animation and define the words that originate from this technique. define the capabilities of computer animation and the mathematical techniques that differ from traditional cel animation. discuss some of the general principles and factors that apply to the creation of computer animation for multimedia presentations. Overview Introduction to animation. Computer-generated animation. File formats used in animation. Making successful animations. Introduction to Animation Animation is defined as the act of making something come alive. It is concerned with the visual or aesthetic aspect of the project. Animation is an object moving across or into or out of the screen. Introduction to Animation Animation is possible because of a biological phenomenon known as persistence of vision and a psychological phenomenon called phi. In animation, a series of images are rapidly changed to create an illusion of movement. Usage of Animation Artistic purposes Storytelling Displaying data (scientific visualization) Instructional purposes 12 Basic Principles of Animation 1. Timing The basics are: more drawings between poses slow and smooth the action. Fewer drawings make the action faster and crisper. A variety of slow and fast timing within a scene adds texture and interest to the movement. 12 Basic Principles of Animation 2. Secondary Action This action adds to and enriches the main action and adds more dimension to the character animation, supplementing and/or re-enforcing the main action. 12 Basic Principles of Animation 3. Follow Through and Overlapping Action When the main body of the character stops, all other parts will continue to catch up to the main mass of the character, such as arms, long hair, clothing, coat tails or a dress, floppy ears or a long tail (these follow the path of action). -

Texture Mapping for Cel Animation
Texture Mapping for Cel Animation 1 2 1 Wagner Toledo Corrˆea1 Robert J. Jensen Craig E. Thayer Adam Finkelstein 1 Princeton University 2 Walt Disney Feature Animation (a) Flat colors (b) Complex texture Figure 1: A frame of cel animation with the foreground character painted by (a) the conventional method, and (b) our system. Abstract 1 INTRODUCTION We present a method for applying complex textures to hand-drawn In traditional cel animation, moving characters are illustrated with characters in cel animation. The method correlates features in a flat, constant colors, whereas background scenery is painted in simple, textured, 3-D model with features on a hand-drawn figure, subtle and exquisite detail (Figure 1a). This disparity in render- and then distorts the model to conform to the hand-drawn artwork. ing quality may be desirable to distinguish the animated characters The process uses two new algorithms: a silhouette detection scheme from the background; however, there are many figures for which and a depth-preserving warp. The silhouette detection algorithm is complex textures would be advantageous. Unfortunately, there are simple and efficient, and it produces continuous, smooth, visible two factors that prohibit animators from painting moving charac- contours on a 3-D model. The warp distorts the model in only two ters with detailed textures. First, moving characters are drawn dif- dimensions to match the artwork from a given camera perspective, ferently from frame to frame, requiring any complex shading to yet preserves 3-D effects such as self-occlusion and foreshortening. be replicated for every frame, adapting to the movements of the The entire process allows animators to combine complex textures characters—an extremely daunting task. -

Machinima : the Art and Practice of Virtual Filmmaking Pdf, Epub, Ebook
MACHINIMA : THE ART AND PRACTICE OF VIRTUAL FILMMAKING PDF, EPUB, EBOOK Phylis Johnson | 327 pages | 30 Mar 2012 | McFarland & Co Inc | 9780786461714 | English | Jefferson, NC, United States Machinima : The Art and Practice of Virtual Filmmaking PDF Book By now, you probably heard the news. With Oculus Rift, and a "new" Second Life, so to speak on the horizon, I am wondering what machinima will be like in the near future. Here's Witchy Woman below , a quick fun machinima capture of the aftermath, with Kara Trapdoor as the tour guide through the now city swamps of St. The film mixes narration from individuals who have been subjected to this dangerous and occasionally fatal prank with artistically glitched wireframe landscapes from the games they play. Courtesy Aino Baar. In conclusion, Understanding Machinima is a well-written and captivating book, especially for those who want to analyse machinima in connection to the universe of media. More Information. Because performance runs in an unreal virtual space, most environments are nurtured by a futuristic aesthetics that take up a feeling of disenchantment for lost utopia from science fiction. Osprey Therian is a director who develops visual storytelling without following a particular script. There are six phases of filmmaking and these phases are taught in the following order in traditional 'in-residence' film production programs. Game companies quickly followed this trend and eventually "game-based demo recording" was used to allow the players to demonstrate their skills, Nitsche, , p. Regardless, lots of people had fun doing random game machinima and commenting on the footage in real time - just not what I wanted this time around. -

The Significance of Anime As a Novel Animation Form, Referencing Selected Works by Hayao Miyazaki, Satoshi Kon and Mamoru Oshii
The significance of anime as a novel animation form, referencing selected works by Hayao Miyazaki, Satoshi Kon and Mamoru Oshii Ywain Tomos submitted for the degree of Doctor of Philosophy Aberystwyth University Department of Theatre, Film and Television Studies, September 2013 DECLARATION This work has not previously been accepted in substance for any degree and is not being concurrently submitted in candidature for any degree. Signed………………………………………………………(candidate) Date …………………………………………………. STATEMENT 1 This dissertation is the result of my own independent work/investigation, except where otherwise stated. Other sources are acknowledged explicit references. A bibliography is appended. Signed………………………………………………………(candidate) Date …………………………………………………. STATEMENT 2 I hereby give consent for my dissertation, if accepted, to be available for photocopying and for inter-library loan, and for the title and summary to be made available to outside organisations. Signed………………………………………………………(candidate) Date …………………………………………………. 2 Acknowledgements I would to take this opportunity to sincerely thank my supervisors, Elin Haf Gruffydd Jones and Dr Dafydd Sills-Jones for all their help and support during this research study. Thanks are also due to my colleagues in the Department of Theatre, Film and Television Studies, Aberystwyth University for their friendship during my time at Aberystwyth. I would also like to thank Prof Josephine Berndt and Dr Sheuo Gan, Kyoto Seiko University, Kyoto for their valuable insights during my visit in 2011. In addition, I would like to express my thanks to the Coleg Cenedlaethol for the scholarship and the opportunity to develop research skills in the Welsh language. Finally I would like to thank my wife Tomoko for her support, patience and tolerance over the last four years – diolch o’r galon Tomoko, ありがとう 智子. -

Introduction Examples of Early Animation
Sabine Fox, 21101363 Introduction Animation first started out as still drawings, such as in cave paintings, which depicted animals or humans with multiple sets of legs, giving the illusion of movement. There has also been an ancient bowl found in Iran which features sequential images of a goat leaping to a tree. When putting animation into context of portraying actual movement by using mechanisms and sequential images, the earliest known animation was created for devices of Chinese inventor Ting Huan in 180 AD. The device was an earlier version of the zoetrope, where it held a series of drawings that rotated when the device was suspended over a lamp. When rotated at the right speed, it created an illusion of movement. Examples of early animation Thaumatrope, 1826, created by English physician John Ayrton Paris. -- It consisted of a disc with two images on opposite sides that merged together when the disc was quickly spun using strings. An example is a bird on one side and a cage on the other. In 1831 Joseph Plateau created the phenakistiscope -- a wheel that had slits around the edge. Under each slit were images on a paper slip that are almost similar to one another, and when the wheel is spun facing the mirror, the images appear to move. The zoetrope, designed by William George Homer in 1834 but wasn’t widely used until 1867. The device was similar to how the phenakistiscope worked -- did not require a mirror to see the images and was moved by turning the cylinder around. It also allowed for the images to be changed, which wasn’t possible with the phenakistiscope. -

Ipi Soft Motion Capture Software Inspires Feature Length Machinima
iPi Soft Motion Capture Software Inspires Feature Length Machinima Horror Movie Ticket Zer0 Director Ian Chisholm Uses End-to-End Markerless Performance Capture Pipeline For Character Animation; Film Now Airing on YouTube _____ MOSCOW, RUSSIA – September 25, 2018 – For his most ambitious project to date, the feature length horror film Ticket Zer0, motion capture director/writer Ian Chisholm once again leaned heavily on iPi Motion Capture, the advanced markerless motion capture technology from iPi Soft. The 66-minute animated machinima cinematic production is currently available for streaming on YouTube or Blu-Ray here. Ticket Zer0 is a follow-up to Chisholm’s Clear Skies trilogy series (viewed by hundreds of thousands on YouTube), which also used iPi Mocap throughout for performance capture. Ticket Zer0 tells the story of the night shift at a deserted industrial facility. When a troubleshooter is sent in to fix a mysterious problem, something far more sinister emerges than any of them could have imagined. Chisholm notes production for Ticket Zer0 took almost five years to complete and used iPi Motion Capture for recording movement in every single frame for all the characters in the film. “iPi Soft technology has proven to be an invaluable creative resource for me as a filmmaker during motion capture sessions,” he says. “There wasn't anything on screen that wasn't recorded by iPi Mocap. The ability to perform the motion capture was exactly what I needed to expand and improve the immersive quality of my film.” Workflow Details: For motion capture production, Chisholm used iPi Mocap in conjunction with six Sony PS3 Eye cameras along with two PlayStation Move controllers to track hand movements. -

Application of Performance Motion Capture Technology in Film and Television Performance Animation
Proceedings of the 2nd International Symposium on Computer, Communication, Control and Automation (ISCCCA-13) Application of Performance Motion Capture Technology in Film and Television Performance Animation ZHANG Manyu Dept. Animation of Art, Tianjin Academy of Fine Arts Tianjin , CHINA E-mail: [email protected] Abstract—In today’s animation films, virtual character tissue simulation technique” for the first time, so that acting animation is a research field developing rapidly in computer skills of actors can be delivered to viewers maximally. graphics, and motion capture is the most significant What’s more, people realize that “motion capture component, which has brought about revolutionary change for technology” shall be called as “performance capture 3D animation production technology. It makes that animation technology” increasingly. Orangutan Caesar presented in producers are able to drive animation image models directly with the use of actors’ performance actions and expressions, Rise of the Apes through “motion capture” technology is which has simplified animation manufacturing operation very classical. Various complicated and subtle expressions greatly and enhanced quality for animation production. and body languages of Caesar’s not vanished bestiality and initially emerged human nature have been presented Keywords- film and television films, motion capture, naturally and freshly in the film, which has achieved the technology excellent realm of mixing the false with the genuine. When Caesar stands in front of Doctor Will in equal gesture, its I. INTRODUCTION independence and arbitrariness in its expression with dignity With the development of modern computer technology, of orangutan has undoubtedly let viewers understand computer animation technology has developed rapidly. -
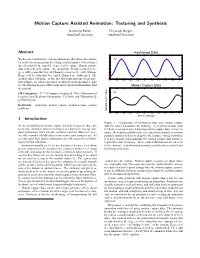
Motion Capture Assisted Animation: Texturing and Synthesis
Motion Capture Assisted Animation: Texturing and Synthesis Katherine Pullen Christoph Bregler Stanford University Stanford University Abstract Keyframed Data 2 We discuss a method for creating animations that allows the anima- 0 (a) tor to sketch an animation by setting a small number of keyframes −2 on a fraction of the possible degrees of freedom. Motion capture −4 data is then used to enhance the animation. Detail is added to de- −6 grees of freedom that were keyframed, a process we call texturing. −8 Degrees of freedom that were not keyframed are synthesized. The −10 method takes advantage of the fact that joint motions of an artic- −12 ulated figure are often correlated, so that given an incomplete data 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 set, the missing degrees of freedom can be predicted from those that Motion Capture Data are present. 1 CR Categories: I.3.7 [Computer Graphics]: Three-Dimensional 0 (b) Graphics and Realism—Animation; J.5 [Arts and Humantities]: −1 performing arts −2 Keywords: animation, motion capture, motion texture, motion −3 synthesis −4 translation in inches −5 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 time in seconds 1 Introduction Figure 1: Comparison of keyframed data and motion capture As the availability of motion capture data has increased, there has data for root y translation for walking. (a) keyframed data, with been more and more interest in using it as a basis for creating com- keyframes indicated by red dots (b) motion capture data. -

High-Performance Play: the Making of Machinima
High-Performance Play: The Making of Machinima Henry Lowood Stanford University <DRAFT. Do not cite or distribute. To appear in: Videogames and Art: Intersections and Interactions, Andy Clarke and Grethe Mitchell (eds.), Intellect Books (UK), 2005. Please contact author, [email protected], for permission.> Abstract: Machinima is the making of animated movies in real time through the use of computer game technology. The projects that launched machinima embedded gameplay in practices of performance, spectatorship, subversion, modification, and community. This article is concerned primarily with the earliest machinima projects. In this phase, DOOM and especially Quake movie makers created practices of game performance and high-performance technology that yielded a new medium for linear storytelling and artistic expression. My aim is not to answer the question, “are games art?”, but to suggest that game-based performance practices will influence work in artistic and narrative media. Biography: Henry Lowood is Curator for History of Science & Technology Collections at Stanford University and co-Principal Investigator for the How They Got Game Project in the Stanford Humanities Laboratory. A historian of science and technology, he teaches Stanford’s annual course on the history of computer game design. With the collaboration of the Internet Archive and the Academy of Machinima Arts and Sciences, he is currently working on a project to develop The Machinima Archive, a permanent repository to document the history of Machinima moviemaking. A body of research on the social and cultural impacts of interactive entertainment is gradually replacing the dismissal of computer games and videogames as mindless amusement for young boys. There are many good reasons for taking computer games1 seriously. -

From Synthespian to Convergence Character: Reframing the Digital Human in Contemporary Hollywood Cinema by Jessica L. Aldred
From Synthespian to Convergence Character: Reframing the Digital Human in Contemporary Hollywood Cinema by Jessica L. Aldred A thesis submitted to the Faculty of Graduate and Postdoctoral Affairs in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Cultural Mediations Carleton University Ottawa, Ontario © 2012 Jessica L. Aldred Library and Archives Bibliotheque et Canada Archives Canada Published Heritage Direction du 1+1 Branch Patrimoine de I'edition 395 Wellington Street 395, rue Wellington Ottawa ON K1A0N4 Ottawa ON K1A 0N4 Canada Canada Your file Votre reference ISBN: 978-0-494-94206-2 Our file Notre reference ISBN: 978-0-494-94206-2 NOTICE: AVIS: The author has granted a non L'auteur a accorde une licence non exclusive exclusive license allowing Library and permettant a la Bibliotheque et Archives Archives Canada to reproduce, Canada de reproduire, publier, archiver, publish, archive, preserve, conserve, sauvegarder, conserver, transmettre au public communicate to the public by par telecommunication ou par I'lnternet, preter, telecommunication or on the Internet, distribuer et vendre des theses partout dans le loan, distrbute and sell theses monde, a des fins commerciales ou autres, sur worldwide, for commercial or non support microforme, papier, electronique et/ou commercial purposes, in microform, autres formats. paper, electronic and/or any other formats. The author retains copyright L'auteur conserve la propriete du droit d'auteur ownership and moral rights in this et des droits moraux qui protege cette these. Ni thesis. Neither the thesis nor la these ni des extraits substantiels de celle-ci substantial extracts from it may be ne doivent etre imprimes ou autrement printed or otherwise reproduced reproduits sans son autorisation. -

Creating 3DCG Animation with a Network of 3D Depth Sensors Ning
2016 International Conference on Sustainable Energy, Environment and Information Engineering (SEEIE 2016) ISBN: 978-1-60595-337-3 Creating 3DCG Animation with a Network of 3D Depth Sensors Ning-ping SUN1,*, Yohei YAMASHITA2 and Ryosuke OKUMURA1 1Dept. of Human-Oriented Information System Engineering 2Advanced Electronics and Information Systems Engineering Course, National Institute of Technology, Kumamoto College, 2659-2 Suya, Koshi, Kumamoto 861-1102, Japan *Corresponding author Keywords: Depth sensor, Network, 3D computer graphics, Animation production. Abstract. The motion capture is a useful technique for creating animations instead of manual labor, but the expensive camera based devices restrict its practical application. The emerging of inexpensive small size of depth-sensing devices provides us opportunities to reconstitute motion capture system. We introduced a network of 3D depth sensors into the production of real time 3DCG animation. Different to the existing system, the new system works well for data communication and anime rendering. We discuss below server how communicate with a group of sensors, and how we operate a group of sensors in the rendering of animation. Some results of verification experiments are provided as well. Introduction The presentation of character’s movement is very important for animation productions. In general, there are two kinds of technique to present movement in an anime. First one is a traditional method, in which animators draw a series of frames of character’s movements individually, and show these frames continuously in a short time interval. Fps, i.e., frames per second is involved the quality of an animation. The more the fps is, the better the quality becomes.