Collecting a Motion-Capture Corpus of American Sign Language for Data-Driven Generation Research
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ipi Soft Motion Capture Software Inspires Feature Length Machinima
iPi Soft Motion Capture Software Inspires Feature Length Machinima Horror Movie Ticket Zer0 Director Ian Chisholm Uses End-to-End Markerless Performance Capture Pipeline For Character Animation; Film Now Airing on YouTube _____ MOSCOW, RUSSIA – September 25, 2018 – For his most ambitious project to date, the feature length horror film Ticket Zer0, motion capture director/writer Ian Chisholm once again leaned heavily on iPi Motion Capture, the advanced markerless motion capture technology from iPi Soft. The 66-minute animated machinima cinematic production is currently available for streaming on YouTube or Blu-Ray here. Ticket Zer0 is a follow-up to Chisholm’s Clear Skies trilogy series (viewed by hundreds of thousands on YouTube), which also used iPi Mocap throughout for performance capture. Ticket Zer0 tells the story of the night shift at a deserted industrial facility. When a troubleshooter is sent in to fix a mysterious problem, something far more sinister emerges than any of them could have imagined. Chisholm notes production for Ticket Zer0 took almost five years to complete and used iPi Motion Capture for recording movement in every single frame for all the characters in the film. “iPi Soft technology has proven to be an invaluable creative resource for me as a filmmaker during motion capture sessions,” he says. “There wasn't anything on screen that wasn't recorded by iPi Mocap. The ability to perform the motion capture was exactly what I needed to expand and improve the immersive quality of my film.” Workflow Details: For motion capture production, Chisholm used iPi Mocap in conjunction with six Sony PS3 Eye cameras along with two PlayStation Move controllers to track hand movements. -

Application of Performance Motion Capture Technology in Film and Television Performance Animation
Proceedings of the 2nd International Symposium on Computer, Communication, Control and Automation (ISCCCA-13) Application of Performance Motion Capture Technology in Film and Television Performance Animation ZHANG Manyu Dept. Animation of Art, Tianjin Academy of Fine Arts Tianjin , CHINA E-mail: [email protected] Abstract—In today’s animation films, virtual character tissue simulation technique” for the first time, so that acting animation is a research field developing rapidly in computer skills of actors can be delivered to viewers maximally. graphics, and motion capture is the most significant What’s more, people realize that “motion capture component, which has brought about revolutionary change for technology” shall be called as “performance capture 3D animation production technology. It makes that animation technology” increasingly. Orangutan Caesar presented in producers are able to drive animation image models directly with the use of actors’ performance actions and expressions, Rise of the Apes through “motion capture” technology is which has simplified animation manufacturing operation very classical. Various complicated and subtle expressions greatly and enhanced quality for animation production. and body languages of Caesar’s not vanished bestiality and initially emerged human nature have been presented Keywords- film and television films, motion capture, naturally and freshly in the film, which has achieved the technology excellent realm of mixing the false with the genuine. When Caesar stands in front of Doctor Will in equal gesture, its I. INTRODUCTION independence and arbitrariness in its expression with dignity With the development of modern computer technology, of orangutan has undoubtedly let viewers understand computer animation technology has developed rapidly. -
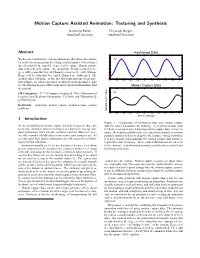
Motion Capture Assisted Animation: Texturing and Synthesis
Motion Capture Assisted Animation: Texturing and Synthesis Katherine Pullen Christoph Bregler Stanford University Stanford University Abstract Keyframed Data 2 We discuss a method for creating animations that allows the anima- 0 (a) tor to sketch an animation by setting a small number of keyframes −2 on a fraction of the possible degrees of freedom. Motion capture −4 data is then used to enhance the animation. Detail is added to de- −6 grees of freedom that were keyframed, a process we call texturing. −8 Degrees of freedom that were not keyframed are synthesized. The −10 method takes advantage of the fact that joint motions of an artic- −12 ulated figure are often correlated, so that given an incomplete data 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 set, the missing degrees of freedom can be predicted from those that Motion Capture Data are present. 1 CR Categories: I.3.7 [Computer Graphics]: Three-Dimensional 0 (b) Graphics and Realism—Animation; J.5 [Arts and Humantities]: −1 performing arts −2 Keywords: animation, motion capture, motion texture, motion −3 synthesis −4 translation in inches −5 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 time in seconds 1 Introduction Figure 1: Comparison of keyframed data and motion capture As the availability of motion capture data has increased, there has data for root y translation for walking. (a) keyframed data, with been more and more interest in using it as a basis for creating com- keyframes indicated by red dots (b) motion capture data. -

Creating 3DCG Animation with a Network of 3D Depth Sensors Ning
2016 International Conference on Sustainable Energy, Environment and Information Engineering (SEEIE 2016) ISBN: 978-1-60595-337-3 Creating 3DCG Animation with a Network of 3D Depth Sensors Ning-ping SUN1,*, Yohei YAMASHITA2 and Ryosuke OKUMURA1 1Dept. of Human-Oriented Information System Engineering 2Advanced Electronics and Information Systems Engineering Course, National Institute of Technology, Kumamoto College, 2659-2 Suya, Koshi, Kumamoto 861-1102, Japan *Corresponding author Keywords: Depth sensor, Network, 3D computer graphics, Animation production. Abstract. The motion capture is a useful technique for creating animations instead of manual labor, but the expensive camera based devices restrict its practical application. The emerging of inexpensive small size of depth-sensing devices provides us opportunities to reconstitute motion capture system. We introduced a network of 3D depth sensors into the production of real time 3DCG animation. Different to the existing system, the new system works well for data communication and anime rendering. We discuss below server how communicate with a group of sensors, and how we operate a group of sensors in the rendering of animation. Some results of verification experiments are provided as well. Introduction The presentation of character’s movement is very important for animation productions. In general, there are two kinds of technique to present movement in an anime. First one is a traditional method, in which animators draw a series of frames of character’s movements individually, and show these frames continuously in a short time interval. Fps, i.e., frames per second is involved the quality of an animation. The more the fps is, the better the quality becomes. -

384 Cinemacraft: Immersive Live Machinima As an Empathetic
Cinemacraft: Immersive Live Machinima as an Empathetic Musical Storytelling Platform Siddharth Narayanan Ivica Ico Bukvic Electrical and Computer Engineering Institue for Creativity, Arts & Technology Virginia Tech Virginia Tech [email protected] [email protected] ABSTRACT or joystick manipulation for various body motions, rang- ing from simple actions such as walking or jumping to In the following paper we present Cinemacraft, a technology- more elaborate tasks like opening doors or pulling levers. mediated immersive machinima platform for collaborative Such an approach can often result in non-natural and po- performance and musical human-computer interaction. To tentially limiting interactions. Such interactions also lead achieve this, Cinemacraft innovates upon a reverse-engineered to profoundly different bodily experiences for the user and version of Minecraft, offering a unique collection of live may detract from the sense of immersion [10]. Modern day machinima production tools and a newly introduced Kinect game avatars are also loaded with body, posture, and ani- HD module that allows for embodied interaction, includ- mation details in an unending quest for realism and com- ing posture, arm movement, facial expressions, and a lip pelling human representations that are often stylized and syncing based on captured voice input. The result is a mal- limited due to the aforesaid limited forms of interaction. leable and accessible sensory fusion platform capable of These challenges lead to the uncanny valley problem that delivering compelling live immersive and empathetic mu- has been explored through the human likeness of digitally sical storytelling that through the use of low fidelity avatars created faces [11], and the effects of varying degrees of re- also successfully sidesteps the uncanny valley. -

A Software Pipeline for 3D Animation Generation Using Mocap Data and Commercial Shape Models
A Software Pipeline for 3D Animation Generation using Mocap Data and Commercial Shape Models Xin Zhang, David S. Biswas and Guoliang Fan School of Electrical and Computer Engineering Oklahoma State University Stillwater, Oklahoma, United States {xin.zhang, david.s.bisaws, guoliang.fan}@okstate.edu ABSTRACT Additionally, high-quality motion capture (mocap) data We propose a software pipeline to generate 3D animations by and realistic human shape models are two important compo- using the motion capture (mocap) data and human shape nents for animation generation, each of which involves a spe- models. The proposed pipeline integrates two animation cific skeleton definition including the number of joints, the software tools, Maya and MotionBuilder in one flow. Specif- naming convention, hierarchical relationship and underlying ically, we address the issue of skeleton incompatibility among physical meaning of each joint. Ideally, animation software the mocap data, shape models, and animation software. Our can drive a human shape model to move and articulate ac- objective is to generate both realistic and accurate motion- cording to the given mocap data and optimize the deforma- specific animation sequences. Our method is tested by three tion of the body surface with natural smoothness, as shown mocap data sets of various motion types and five commer- in Fig. 1. With the development of computer graphics and cial human shape models, and it demonstrates better visual the mocap technology, there are plenty of mocap data and realisticness and kinematic accuracy when compared with 3D human models available for various research activities. three other animation generation methods. However, due to their different sources, there is a major gap between the mocap data, shape models and animation soft- ware, which often makes animation generation a challenging Categories and Subject Descriptors task. -

Keyframe Or Motion Capture? Reflections on Education of Character Animation
EURASIA Journal of Mathematics, Science and Technology Education, 2018, 14(12), em1649 ISSN:1305-8223 (online) OPEN ACCESS Research Paper https://doi.org/10.29333/ejmste/99174 Keyframe or Motion Capture? Reflections on Education of Character Animation Tsai-Yun Mou 1* 1 National Pingtung University, TAIWAN Received 20 April 2018 ▪ Revised 12 August 2018 ▪ Accepted 13 September 2018 ABSTRACT In character animation education, the training process needs diverse domain knowledge to be covered in order to develop students with good animation ability. However, design of motion also requires digital ability, creativity and motion knowledge. Moreover, there are gaps between animation education and industry production which motion capture is widely applied. Here we try to incorporate motion capture into education and investigate whether motion capture is supportive in character animation, especially in creativity element. By comparing two kinds of motion design method, traditional keyframe and motion capture, we investigated students’ creativity in motion design. The results showed that in originality factor, keyframe method had slightly higher performance support for designing unusual motions. Nevertheless, motion capture had shown more support in creating valid actions in quantity which implied fluency factor of creativity was achieved. However, in flexibility factor, although motion capture created more emotions in amount, keyframe method actually offered higher proportion of sentiment design. Participants indicated that keyframe was helpful to design extreme poses. While motion capture provided intuitive design tool for exploring possibilities. Therefore, we propose to combine motion capture technology with keyframe method in character animation education to increase digital ability, stimulate creativity, and establish solid motion knowledge. Keywords: animation education, character animation, creativity, motion capture, virtual character INTRODUCTION The education of animation is a long-standing and multidisciplinary training. -

Motion Capture Technology for Entertainment
[in the SPOTLIGHT] Chris Bregler Motion Capture Technology for Entertainment he year 2007 started with this momentous goal. One of the considered “cheating” in the anima- two big bangs for Lucas- secret ingredients that will get us tion world, where it was thought that Film’s Industrial Light and there may be motion capture (MoCap), everything should be conjured up by Magic (ILM), the motion defined as a technology that allows us the imagination. “Good animation” picture visual effects compa- to record human motion with sensors was considered to be a rare and hard- Tny started by George Lucas in 1975, in and to digitally map the motion to to-acquire art form that followed the two eagerly awaited Hollywood events. In computer-generated creatures. MoCap famous drawing and animation princi- January, ILM won the “Scientific and has been both hyped and criticized ples of cartoon physics invented by Engineering Award” of the Academy of since people started experimenting Disney. Rotoscoping was thought to be Motion Picture Arts and Sciences for with computerized motion-recording “cheap animation” that lacked expres- their image-based modeling work applied devices in the 1970s. Whether reviled siveness. If one of animation’s main to visual effects in the film industry. In by animation purists as a shortcut or principles is exaggeration—everything February, ILM took home the Oscar needs to be bigger than life, not for “Best Visual Effects” for Pirates just a copy of life—rotoscoping, as of the Caribbean: Dead Man’s Chest, THE ILM AWARDS ARE precursor of MoCap, was consid- a milestone achievement for ILM IN LINE WITH ONE SPECIFIC ered even less than life because after their last Oscar for Forrest GOAL—THE CREATION OF many important subtleties got lost Gump in 1994 and many previous ARTIFICIAL HUMANS in the process. -

Chapter 2: Motion Capture Process and Systems to Appear in Jung, Fisher, Gleicher, Thingvold
Chapter 2: Motion Capture Process and Systems To appear in Jung, Fisher, Gleicher, Thingvold. "Motion Capture and Motion Editing." AK Peters, summer 2000. By Ron Fischer, The Digital Actors Company This chapter gives an overview of Motion Capture and various technologies used to do it. Motion capture is a complex technology that deeply affects the aesthetics of the CG art form. Because of its complexity and the speed at which profitable production proceeds, it is a challenging process to keep under control. Stories of the failure of this work are readily available, ranging in cause from technological difficulties to the more common “operator error.” Rather than build up a museum of horror stories we'll teach good procedures and specific problems to avoid. Fear-mongering does not serve anyone well. We distinguish “motion capture process” (the topic of this chapter) from “motion application process” (the topic of later chapters). The “capture process” obtains motion data from the performer, and the “application process” retargets that motion data onto an animated character. The connection between the processes are the two skeletal models in the computer. One model, the performer model, is some representation of the human performer in the capture volume. The second one, the target model, might be a computer-animated figure onto which the motion is applied. In the next section, we'll discuss planning and executing a motion capture production job. Most aspects are covered, from breaking down the work, to casting talent, to delivering the results to a client. The following section introduces a practical model of motion capture technology. -

Introduction and Animation Basics
Lecture 1: introduction PhD in Computer Science, MIRALab, University of Geneva, 2006-2011 Second post-doc, Institute for Media First post-doc, HCI Group, Innovation, Nanyang Technological EPFL, Lausanne, 2012-2013 University, 2013-2015 (Expressive) Character animation Facial animation Body gestures/emotions Gaze behavior Motion synthesis Multi-character interactions Virtual humans in VR and (Serious) Games Social robots and AI Florian Gaeremynck (GMT Student) [email protected] Ask questions for practical assignments Introduction to basic techniques in Computer Animation ▪ Motion synthesis, facial & body animation, … Introduction to research topics ▪ Giving presentations ▪ Reading and evaluating research papers ▪ Writing an essay about an animation topic Hands-on experience ▪ Short animation movie production or programming exercise Grading: ▪ Research papers (R) ▪ Project (P) ▪ Essay (E) ▪ Final grade = 0.3*R + 0.3*P + 0.4*E ▪ Condition: E >= 5 *Pay attention that R is based on your presentations but also involves paper summaries. You will not a get a separate grade for the summaries but it is part of the overall grade R. Attendance is overall not mandatory, but.. ▪ You are required to attend the lectures with student presentations you wrote a review for. You will send a one A4 page review for each paper. In total, you should have 6 reviews . ▪ Similar to peer-review process of conferences and journals Deadline for submitting these reviews is one day before the lecture until 23:59 You are not limited to 6 papers though, read as much as you can, participate the presentations and ask questions! Note: In all your emails to the teacher or the TA, you must include [INFOMCANIM 2021] in the subject line of your email. -

Motion Capture History, Technologies and Applications
Motion Capture History, Technologies and Applications Advanced Computing Center for the Arts and Design Ohio State University Vita Berezina-Blackburn ©2003- 2016, The Ohio State University Motion Capture • motion capture (mocap) is sampling and recording motion of humans, animals and inanimate objects as 3d data for analysis, playback and remapping • performance capture is acting with motion capture in film and games • motion tracking is real-time processing of motion capture data ©2003- 2016, The Ohio State University History of Motion Capture • Eadweard Muybridge (1830-1904) • Etienne-Jules Marey (1830-1904) • Nikolai Bernstein (1896-1966) • Harold Edgerton (1903-1990) • Gunnar Johansson (1911- 1998) ©2003- 2016, The Ohio State University Eadward Muybridge • the flying horse • 20,000 photos of animal and human locomotion • UK-USA, 1872 © Kingston Museum ©2003- 2016, The Ohio State University Eadward Muybridge • zoopraxiscope © Kingston Museum ©2003- 2016, The Ohio State University Etienne-Jules Marey • first person to analyze human and animal motion with film • created chronophotographic gun and fixed plate camera • France, 1880s ©2003- 2016, The Ohio State University Modern Art • Futurism (Boccionni, Balla and others) • Marcel Duchamp ©2003- 2016, The Ohio State University Rotoscoping • allowed animators to trace cartoon characters over photographed frames of live performances. • invented in 1915 by Max Fleischer • Koko the Clown • Snow White © Walt Disney ©2003- 2016, The Ohio State University Nikolai Bernstein • General Biomechanics – 1924, Central Institute of Labor, Moscow • physiology of sport and labor activities, foundations of ergonomics • cyclography • concepts of degrees of freedom and hierarchical structure of motion control ©2003- 2016, The Ohio State University Harold Edgerton • electronic stroboscope and flash • exposures of 1/1000th to 1/1000000 sec • MIT, 1930s-1960 © Palm Press Inc. -

MAKING MACHINIMA: Animation, Games and Multimodal Participation in the Media Arts Andrew Burn ABSTRACT in the Project Discussed
MAKING MACHINIMA: animation, games and multimodal participation in the media arts Andrew Burn ABSTRACT In the project discussed in this article, 30 11-year-olds made an animated film in the machinima style, influenced by both film and game culture, and using a 3-D animation software tool, Moviestorm. The processes and products of the project will be analysed using a social semiotic/multimodal approach, exploring the social interests behind the integration of visual design, music, voice acting, story-writing and animation which characterise the project. The outcomes suggest a need to move beyond established thinking and practice in media literacy practice and research in three ways. First, we need to develop moving image education to recognise new genres and cultures. Second, we need to recognise that such productions are intensely multimodal, involving music, drama, story-writing and visual design. Third, such projects demand connected pedagogy across media, literacy, music, drama, computer science and art. INTRODUCTION Media literacy is a contested notion, in Europe, in the US, and globally. In my own context, it is closely allied with a model of media education built around a conceptual framework of media institutions, texts and audiences, a model best-known in David Buckingham’s version (2003). My own conception, while close to Buckingham’s (and indebted to his) is a little different. For one thing, it incorporates an emphasis on the poetics of the media as well as the rhetorics. For another, it incorporates a social semiotic-multimodal notion of media texts. It is elaborated fully in Burn and Durran (2007), along with a series of case studies exemplifying its various features.