Distribution Patterns and Networks of Relations Among Cities and Institutes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Analyze a World Map
Analyze a World Map Materials: Map of the World: Political or use link this website Map of the World Worksheet You could start the discussion by saying that the social studies part of the GED test assumes that everyone has a basic knowledge of world geography. The test will contain maps that you have to analyze and the answers are not always directly on the map. This is one area of the test where they expect you to just know the approximate locations of countries and oceans. So we thought we would use this world map to familiarize everyone with some world geography. Hand out the maps. The first thing you need to do with a map is read the title so that you know what you are looking at. Ask, “What is the title of this map?” ‘Map of the World: Political”. So this map should give us information about the location of countries. Then look to see if there is a legend or a list of symbols that explains the information shown on the map. Ask, “Is there a legend for this map/” Yes, it shows the scale of the map. You can discuss that the scale shows the relationship between distances on the map to the actual distance on the ground. Look to see if there is anything on the map showing directions, most maps have a compass that shows east, west, north, and south. Ask, “Does this map have any symbols indicating direction?” Yes, this map has a direction compass that shows points north. Ask if students know where south, east, and west are on the map. -

Countries and Continents of the World: a Visual Model
Countries and Continents of the World http://geology.com/world/world-map-clickable.gif By STF Members at The Crossroads School Africa Second largest continent on earth (30,065,000 Sq. Km) Most countries of any other continent Home to The Sahara, the largest desert in the world and The Nile, the longest river in the world The Sahara: covers 4,619,260 km2 The Nile: 6695 kilometers long There are over 1000 languages spoken in Africa http://www.ecdc-cari.org/countries/Africa_Map.gif North America Third largest continent on earth (24,256,000 Sq. Km) Composed of 23 countries Most North Americans speak French, Spanish, and English Only continent that has every kind of climate http://www.freeusandworldmaps.com/html/WorldRegions/WorldRegions.html Asia Largest continent in size and population (44,579,000 Sq. Km) Contains 47 countries Contains the world’s largest country, Russia, and the most populous country, China The Great Wall of China is the only man made structure that can be seen from space Home to Mt. Everest (on the border of Tibet and Nepal), the highest point on earth Mt. Everest is 29,028 ft. (8,848 m) tall http://craigwsmall.wordpress.com/2008/11/10/asia/ Europe Second smallest continent in the world (9,938,000 Sq. Km) Home to the smallest country (Vatican City State) There are no deserts in Europe Contains mineral resources: coal, petroleum, natural gas, copper, lead, and tin http://www.knowledgerush.com/wiki_image/b/bf/Europe-large.png Oceania/Australia Smallest continent on earth (7,687,000 Sq. -

Geography Notes.Pdf
THE GLOBE What is a globe? a small model of the Earth Parts of a globe: equator - the line on the globe halfway between the North Pole and the South Pole poles - the northern-most and southern-most points on the Earth 1. North Pole 2. South Pole hemispheres - half of the earth, divided by the equator (North & South) and the prime meridian (East and West) 1. Northern Hemisphere 2. Southern Hemisphere 3. Eastern Hemisphere 4. Western Hemisphere continents - the largest land areas on Earth 1. North America 2. South America 3. Europe 4. Asia 5. Africa 6. Australia 7. Antarctica oceans - the largest water areas on Earth 1. Atlantic Ocean 2. Pacific Ocean 3. Indian Ocean 4. Arctic Ocean 5. Antarctic Ocean WORLD MAP ** NOTE: Our textbooks call the “Southern Ocean” the “Antarctic Ocean” ** North America The three major countries of North America are: 1. Canada 2. United States 3. Mexico Where Do We Live? We live in the Western & Northern Hemispheres. We live on the continent of North America. The other 2 large countries on this continent are Canada and Mexico. The name of our country is the United States. There are 50 states in it, but when it first became a country, there were only 13 states. The name of our state is New York. Its capital city is Albany. GEOGRAPHY STUDY GUIDE You will need to know: VOCABULARY: equator globe hemisphere continent ocean compass WORLD MAP - be able to label 7 continents and 5 oceans 3 Large Countries of North America 1. United States 2. Canada 3. -

Was This World Map Made Ten Centuries Ago?
HAWAIIAN GAZETTE, FRIDAY, JANUARY n, 1907 SEMI-WEEKL- Y Was This World Map Made Ten Centuries Ago? gg "J" ISOME DETAILS OF GREAT Vf? rr9rv-vr- i 'vir)('JK.rr KXW XXXjtXXmXmKiXXXiXXX XvyXXXrXXX ffKftXr1 STORM Politically Inclined policemen nro not wanted by tho new Sheriff, who will MAUI, shortly Issue nn order to the effect that January i. The holiday sea- son 2 i I nlj employes of tho police department on Maul has not been a tlmo of quiet 5 j ft must chooso between their Jobs on tho enjoyment ns far as weather is 5 a force and their oITlces In any of tho concerned. Dame Nnturo has echoed A.- -. a. w three political party committees. This anything but the Christmas sentiment rule Is to bo strictly enforced, the em of "peace on earth and good-wi- lt ployes of tho public being supposed, bo mn." far as tho police are concernod at least, Before recovery could bo made from to give their time and energy to th tho effects of the recent north storm public and not for the advancement with Its 20 Inches of moisture In local- politically or otherwlso of any one sec- ities, on Saturday tho wind changed Ifr tion of tho public to the southucst and nn kona Tho Sheriff Is making plain storm came Into being. It contin- If It that ued to blow fiercely ho means ho says all tho night what when he tabued through, accompanied by nn Incessant i - i politics around tho police station. In piny of lightning and the heavy roll of this he has come In for moro or less thunder. -
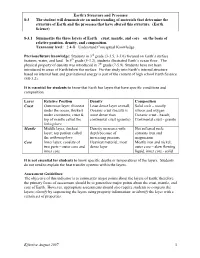
Earth's Structure and Processes 8-3 the Student Will Demonstrate An
Earth’s Structure and Processes 8-3 The student will demonstrate an understanding of materials that determine the structure of Earth and the processes that have altered this structure. (Earth Science) 8-3.1 Summarize the three layers of Earth – crust, mantle, and core – on the basis of relative position, density, and composition. Taxonomy level: 2.4-B Understand Conceptual Knowledge Previous/future knowledge: Students in 3rd grade (3-3.5, 3-3.6) focused on Earth’s surface features, water, and land. In 5th grade (5-3.2), students illustrated Earth’s ocean floor. The physical property of density was introduced in 7th grade (7-5.9). Students have not been introduced to areas of Earth below the surface. Further study into Earth’s internal structure based on internal heat and gravitational energy is part of the content of high school Earth Science (ES-3.2). It is essential for students to know that Earth has layers that have specific conditions and composition. Layer Relative Position Density Composition Crust Outermost layer; thinnest Least dense layer overall; Solid rock – mostly under the ocean, thickest Oceanic crust (basalt) is silicon and oxygen under continents; crust & more dense than Oceanic crust - basalt; top of mantle called the continental crust (granite) Continental crust - granite lithosphere Mantle Middle layer, thickest Density increases with Hot softened rock; layer; top portion called depth because of contains iron and the asthenosphere increasing pressure magnesium Core Inner layer; consists of Heaviest material; most Mostly iron and nickel; two parts – outer core and dense layer outer core – slow flowing inner core liquid, inner core - solid It is not essential for students to know specific depths or temperatures of the layers. -

World Map of Al-‘Umari #226.1
World Map of al-‘Umari #226.1 TITLE: The Mamunic World Map DATE: 1340 AUTHOR: Ahmad ibn Yahya ibn Fadlallah al-‘Umari DESCRIPTION: The geographic work Masalik al-aNar fi mainalik al-amsar [Ways of Perception Concerning the Most Populous [Civilized] Provinces] was written by Ahmad Ibn Fadlalldh al-Umari (died 1349), a distinguished administrator and author who was active in Cairo and Damascus under Mamluk rule. He claims that the map is a copy of the world map made for Caliph al-Ma’mun (reigned 813-833); also mentioned by al-Mas’udi (#212) earlier. The world map shown here is reproduced in this manuscript of the work of al- ‘Umari. The same manuscript also has maps of the first three climates. Although the climates are not divided into sections, the general impression is that the maps are derived from those of al-Idrisi (#219). However, from its appearance it seems to have been compiled from the text of the Kitab bast al-ard fi tuliha wa-al-‘ard [Exposition of the earth in length and breadth] by Ibn Sa‘id (#221). Al-‘Umari’s text does mention a map and gives a few examples of longitude and latitude, but on the whole they do not correspond with positions given on the map. Most of the Istanbul manuscripts of Ibn Fadlallah al-‘Umari’s work are undated. However, the earliest one to be dated is 1585, suggesting that this and most other copies were prepared for the libraries of the Ottoman sultans of that period. By that time the idea of a graticule was well known from European sources and could have been added to bring the map up to date. -

Comparison of Spherical Cube Map Projections Used in Planet-Sized Terrain Rendering
FACTA UNIVERSITATIS (NIS)ˇ Ser. Math. Inform. Vol. 31, No 2 (2016), 259–297 COMPARISON OF SPHERICAL CUBE MAP PROJECTIONS USED IN PLANET-SIZED TERRAIN RENDERING Aleksandar M. Dimitrijevi´c, Martin Lambers and Dejan D. Ranˇci´c Abstract. A wide variety of projections from a planet surface to a two-dimensional map are known, and the correct choice of a particular projection for a given application area depends on many factors. In the computer graphics domain, in particular in the field of planet rendering systems, the importance of that choice has been neglected so far and inadequate criteria have been used to select a projection. In this paper, we derive evaluation criteria, based on texture distortion, suitable for this application domain, and apply them to a comprehensive list of spherical cube map projections to demonstrate their properties. Keywords: Map projection, spherical cube, distortion, texturing, graphics 1. Introduction Map projections have been used for centuries to represent the curved surface of the Earth with a two-dimensional map. A wide variety of map projections have been proposed, each with different properties. Of particular interest are scale variations and angular distortions introduced by map projections – since the spheroidal surface is not developable, a projection onto a plane cannot be both conformal (angle- preserving) and equal-area (constant-scale) at the same time. These two properties are usually analyzed using Tissot’s indicatrix. An overview of map projections and an introduction to Tissot’s indicatrix are given by Snyder [24]. In computer graphics, a map projection is a central part of systems that render planets or similar celestial bodies: the surface properties (photos, digital elevation models, radar imagery, thermal measurements, etc.) are stored in a map hierarchy in different resolutions. -

From the Old Ages to Mercator
14 The World Image in Maps – From the Old Ages to Mercator Mirjanka Lechthaler Institute of Geoinformation and Cartography Vienna University of Technology, Austria Abstract Studying the Australian aborigines’ ‘dreamtime’ maps or engravings from Dutch cartographers of the 16 th century, one can lose oneself in their beauty. Casually, cartography is a kind of art. Visualization techniques, precision and compliance with reality are of main interest. The centuries of great expeditions led to today’s view and mapping of the world. This chapter gives an overview on the milestones in the history of cartography, from the old ages to Mercator’s map collections. Each map presented is a work of art, which acts as a substitute for its era, allowing us to re-live the circumstances at that time. 14.1 Introduction Long before people were able to write, maps have been used to visualise reality or fantasy. Their content in \ uenced how people saw the world. From studying maps conclusions can be drawn about how visualized regions are experienced, imagined, or meant to be perceived. Often this is in \ uenced by social and political objectives. Cartography is an essential instrument in mapping and therefore preserving cultural heritage. Map contents are expressed by means of graphical language. Only techniques changed – from cuneiform writing to modern digital techniques. From the begin- nings of cartography until now, this language remained similar: clearly perceptible graphics that represented real world objects. The chapter features the brief and concise history of the appearance and develop- ment of topographic representations from Mercator’s time (1512–1594), which was an important period for the development of cartography. -

History of Cartography by Trista L
Name Date History of Cartography By Trista L. Pollard Our view of the world has changed since 1500 years ago. The maps and globes we use today are very accurate. They show more details. You can see cities and countries. They show landforms and landmarks. Our maps now have a standard coordinate or grid system. This measurement system helps us to locate places on Earth. But what about the first maps? What are they like? How were they made? Let's take a journey into the history of cartography. Cartography is the science of making maps. Today's cartographers use computers and cameras to help make maps. This is called remote sensing. Cameras are placed or mounted on airplanes. These cameras take pictures of the Earth's surface. Satellites in space are also used for cartography. Mapmakers in the past had much less technology. They used observation and stories from sailors to make maps. Most early scientists believed the Earth was flat. Imagine sailing from your country and falling over a cliff! That's what people thought. They also thought Earth was a flat disc. The center of the disc was filled with people. The outer edges of the Earth were empty. A world map made as early as 500 B.C. showed a disc with two continents. These continents were Europe and Asia. Both were surrounded by an ocean. That makes sense! Most people only knew about their surrounding or immediate area. Geographers also found early maps of the Pacific Ocean. They were made by navigators from Polynesia or the Pacific Islands. -
How Do We Teach Geography?
How do we teach geography? If we asked our students to describe their understanding of geography, what kinds of answers do you think they might give us? But if geography is about maps, then how well do they know their maps? In late 2002, the National Geographic Society conducted an international survey of young people between the ages of 18-24 in nine countries - the U.S., Canada, France, Germany, Italy, Japan, Mexico, Sweden, and Britain. Each of the respondents was asked 56 questions about geography. None of the countries received and “A” grade. Sweden led the way with an average of 40 correct answers, followed by Germany and Italy each with 38 correct answers. Mexico was last with a “D-” for an average score of 21, just two points below the 23 score of the Americans. Some of the findings from the young Americans included the following: • 89% could locate the U.S. on a blank world map. • 89% could find both California and Texas on a map of the U.S; 51% could locate New York. • 71% could locate the Pacific Ocean. • 17% could locate Afghanistan on a blank world map. • 13% could locate Iraq on a blank world map. Many historians and geographers think that perhaps we can’t identify places on maps because we continue to rely on a traditional interpretation of geography Geography - the study of land, places, and the people in those lands. So, what might happen if we required students to think critically about maps, map making, geographical politics, and the people who live and work in various geographical regions? • We might begin to get our students to think geopolitically - to think about the influence of geography, culture, ethnicity, and religion on the politics - especially the domestic and foreign politics - of a nation. -

World, January 2015
Political Map of the World, January 2015 AUSTRALIA Independent state Bermuda Dependency or area of special sovereignty Sicily / AZORES Island / island group 150 120 90 60 30 0 30 60 90 120 150 180 Capital Alert FRANZ JOSEF ARCTIC OCEAN ARCTIC OCEAN LAND SEVERNAYA ARCTIC OCEAN ZEMLYA Ellesmere Island QUEEN ELIZABETH Qaanaaq (Thule) Longyearbyen NEW SIBERIAN ISLANDS Scale 1:35,000,000 Svalbard NOVAYA Kara Sea ISLANDS Greenland Sea ZEMLYA Laptev Sea Robinson Projection Banks (NORWAY) Barents Sea Island Resolute East Siberian Sea standard parallels 38°N and 38°S Pond Inlet Baffin Greenland Wrangel Beaufort Sea (DENMARK) Island Barrow Victoria Bay Tiksi Island Baffin Jan Mayen Norwegian Pevek Chukchi Island (NORWAY) Noril'sk Sea Murmansk Cherskiy Sea Arctic Circle (66°33') Arctic Circle (66°33') NORWAY Fairbanks Great Nuuk White Sea Anadyr' Nome (Godthåb) ICELAND Provideniya U. S. Bear Lake Iqaluit Denmark SWEDEN Arkhangel'sk Davis Strait Faroe Reykjavík Islands FINLAND Strait (DEN.) Gulf Lake Yakutsk Ladoga R U S S I A Anchorage Great Tórshavn of Lake Whitehorse Slave Lake Bothnia Helsinki Onega 60 Hudson Oslo Magadan 60 Bay Stockholm Tallinn Saint Petersburg Rockall EST. Perm' Gulf of Alaska Juneau Churchill Baltic Kuujjuaq Labrador (U.K.) Yaroslavl' Tyumen' Bering Sea Fort McMurray Sea Riga¯ Nizhniy Izhevsk North LAT. Novgorod Tomsk Sea Glasgow DENMARK Moscow Kazan' Yekaterinburg Krasnoyarsk Sea Copenhagen LITH. Chelyabinsk Novosibirsk Lake Prince Belfast UNITED RUSSIA Vilnius Ufa Omsk Sea of C A N A D A Minsk Ul'yanovsk Baikal S George Happy Valley- Leeds ND Goose Bay Dublin Isle of Hamburg Samara Barnaul Okhotsk ISLA Edmonton Man BELARUS N Lake IRELAND (U.K.) KINGDOM Amsterdam Berlin Warsaw U.S. -

Review of Web Mapping: Eras, Trends and Directions
International Journal of Geo-Information Review Review of Web Mapping: Eras, Trends and Directions Bert Veenendaal 1,*, Maria Antonia Brovelli 2 ID and Songnian Li 3 ID 1 Department of Spatial Sciences, Curtin University, GPO Box U1987, Perth 6845, Australia 2 Department of Civil and Environmental Engineering (DICA), Politecnico di Milano, P.zza Leonardo da Vinci 32, 20133 Milan, Italy; [email protected] 3 Department of Civil Engineering, Ryerson University, 350 Victoria Street, Toronto, ON M5B 2K3, Canada; [email protected] * Correspondence: [email protected]; Tel.: +618-9266-7701 Received: 28 July 2017; Accepted: 16 October 2017; Published: 21 October 2017 Abstract: Web mapping and the use of geospatial information online have evolved rapidly over the past few decades. Almost everyone in the world uses mapping information, whether or not one realizes it. Almost every mobile phone now has location services and every event and object on the earth has a location. The use of this geospatial location data has expanded rapidly, thanks to the development of the Internet. Huge volumes of geospatial data are available and daily being captured online, and are used in web applications and maps for viewing, analysis, modeling and simulation. This paper reviews the developments of web mapping from the first static online map images to the current highly interactive, multi-sourced web mapping services that have been increasingly moved to cloud computing platforms. The whole environment of web mapping captures the integration and interaction between three components found online, namely, geospatial information, people and functionality. In this paper, the trends and interactions among these components are identified and reviewed in relation to the technology developments.