Structural Segmentation of Alap in Dhrupad Vocal Concerts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
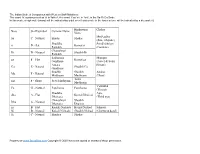
Note Staff Symbol Carnatic Name Hindustani Name Chakra Sa C
The Indian Scale & Comparison with Western Staff Notations: The vowel 'a' is pronounced as 'a' in 'father', the vowel 'i' as 'ee' in 'feet', in the Sa-Ri-Ga Scale In this scale, a high note (swara) will be indicated by a dot over it and a note in the lower octave will be indicated by a dot under it. Hindustani Chakra Note Staff Symbol Carnatic Name Name MulAadhar Sa C - Natural Shadaj Shadaj (Base of spine) Shuddha Swadhishthan ri D - flat Komal ri Rishabh (Genitals) Chatushruti Ri D - Natural Shudhh Ri Rishabh Sadharana Manipur ga E - Flat Komal ga Gandhara (Navel & Solar Antara Plexus) Ga E - Natural Shudhh Ga Gandhara Shudhh Shudhh Anahat Ma F - Natural Madhyam Madhyam (Heart) Tivra ma F - Sharp Prati Madhyam Madhyam Vishudhh Pa G - Natural Panchama Panchama (Throat) Shuddha Ajna dha A - Flat Komal Dhaivat Dhaivata (Third eye) Chatushruti Shudhh Dha A - Natural Dhaivata Dhaivat ni B - Flat Kaisiki Nishada Komal Nishad Sahsaar Ni B - Natural Kakali Nishada Shudhh Nishad (Crown of head) Så C - Natural Shadaja Shadaj Property of www.SarodSitar.com Copyright © 2010 Not to be copied or shared without permission. Short description of Few Popular Raags :: Sanskrut (Sanskrit) pronunciation is Raag and NOT Raga (Alphabetical) Aroha Timing Name of Raag (Karnataki Details Avroha Resemblance) Mood Vadi, Samvadi (Main Swaras) It is a old raag obtained by the combination of two raags, Ahiri Sa ri Ga Ma Pa Ga Ma Dha ni Så Ahir Bhairav Morning & Bhairav. It belongs to the Bhairav Thaat. Its first part (poorvang) has the Bhairav ang and the second part has kafi or Så ni Dha Pa Ma Ga ri Sa (Chakravaka) serious, devotional harpriya ang. -

Sample Quizzes
SAMPLE QUIZZES Two quizzes follow, each of them representing different topics of information to be acquired by students, who are themselves at different levels of learning. They are only a sampler of what might be developed as an assessment of student learning of the musical culture of Bulgaria. Quiz 1. Multiple Choice. Choose the best or most appropriate answer. 1. In the medieval period of Indian music (12th through 17th centuries), painters were commission to paint sets of miniature paintings of entire rag (or raga) families, called (a) rāginis, (b) rāgamālas, (c) rāgamālikas, (d) Bhairagi. 2. The old vocal music form consisting of a slow abstract beginning which gathers momentum, “restarts” with a fixed composition, and climaxes with a fast rhythmic section, and which has influenced most later North Indian classical forms, is known as (a) dhrupad, (b) khyāl, (c) jor, (d) alāap. 3. Syllables that are used by musicians to construct rhythmic patterns (such as “taka”, “takita”, and “takadimi”) are known as (a) talās, (b) lāyas, (c) chhands, and (d) jātīs. 4. Syllables for pitches in a scale are sa-re-ga-ma-pa-dha-ni-sa, known collectively as (a) sruti, (b) sārgām, (c) gintī, (d) rāga. 1. The oldest scriptures in India, dating from 1500 BCE and comprised of sacred hymns, poetic descriptions of the gods and nature, rituals, and blessings, are known as the (a) Bharatā Natyam, (b) Vedas, (c) Vikritis, (d) Mantrās. 2. Which of the following is not a general quality common to all ragas? (a) A rāga must have at least five notes and cannot omit Sa, (b) There is an ascending and descending format, (c) Some form of Re must be present, (d) Certain moods are associated with each. -

Master of Performing Arts (Vocal & Instrumental)
MASTER OF PERFORMING ARTS (VOCAL & INSTRUMENTAL) I SEMESTER Course - 101 (Applied Theory) Credits: 4 Marks: 80 Internal Assessment: 20 Total: 100 Course Objectives:- 1. To critically appreciate a music concert. 2. To understand and compare the ragas and talas prescribed for practical’s. 3. To write compositions in the prescribed notation system. 4. To introduce students to staff notation. Course Content:- I. Theoretical study of Ragas and Talas prescribed for practical and their comparative study wherever possible. II. Reading and writing of Notations of compositions Alap, Taan etc. in the Ragas and Talas with prescribed Laykraries. III. Elementary Knowledge of Staff Notation. IV. Critical appreciation of Music concert. Bibliographies:- a. Dr. Bahulkar, S. Kalashastra Visharad (Vol. 1 - 4 ). Mumbai:: Sanskar Prakashan. b. Dr. Sharma, M. Music India. A. B. H. Publishing Hoouse. c. Dr. Vasant. Sangeet Visharad. Hatras:: Sangeet Karyalaya. d. Rajopadhyay, V. Sangeet Shastra. Akhil Bhartiya Gandharva Vidhyalaya e. Rathod, B. Thumri. Jaipur:: University Book House Pvt. Ltd. f. Shivpuji, G. Lay Shastra. Bhopal: Madhya Pradesh Hindi Granth. Course - 102 (General Theory) Credits: 4 Marks: 80 Internal Assessment: 20 Total: 100 Course Objectives:- 1. To study Aesthetics in Music. 2. To appreciate the aesthetic aspects of different forms of music. Course Content:- I. Definition of Aesthetics and its Application in Music. II. Aesthetical principles of Different Haran’s. III. Aesthetical aspects of different forms of Music. a. Dhrupad, Dhamar, Khayal, Thumri, Tappa etc. IV. Merits and demerits of vocalist. Bibliographies:- a. Bosanquet, B. (2001). The concept of Aesthetics. New Delhi: Sethi Publishing Company. b. Dr. Bahulkar, S. Kalashastra Visharad (Vol. -

The Rich Heritage of Dhrupad Sangeet in Pushtimarg On
Copyright © 2006 www.vallabhkankroli.org - All Rights Reserved by Shree Vakpati Foundation - Baroda ||Shree DwaDwarrrrkeshokesho Jayati|| || Shree Vallabhadhish Vijayate || The Rich Heritage Of Dhrupad Sangeet in Pushtimarg on www.vallabhkankroli.org Reference : 8th Year Text Book of Pushtimargiya Patrachaar by Shree Vakpati Foundation - Baroda Inspiration: PPG 108 Shree Vrajeshkumar Maharajshri - Kankroli PPG 108 Shree Vagishkumar Bawashri - Kankroli Copyright © 2006 www.vallabhkankroli.org - All Rights Reserved by Shree Vakpati Foundation - Baroda Contents Meaning of Sangeet ........................................................................................................................... 4 Naad, Shruti and Swar ....................................................................................................................... 4 Definition of Raga.............................................................................................................................. 5 Rules for Defining Ragas................................................................................................................... 6 The Defining Elements in the Raga................................................................................................... 7 Vadi, Samvadi, Anuvadi, Vivadi [ Sonant, Consonant, Assonant, Dissonant] ................................ 8 Aroha, avaroha [Ascending, Descending] ......................................................................................... 8 Twelve Swaras of the Octave ........................................................................................................... -

(Estd. U/S 3 of UGC Act 1956) Coimbatore-64
Avinashilingam Institute for Home Science and Higher Education for Women University (Estd. u/s 3 of UGC Act 1956) Coimbatore-641043, Tamilnadu, India MA.MUSIC (Two year program with Practicals) Scheme of Instruction and Examination For the students admitted from 2018-2019 & onwards Part Subject Name of the Hrs of Scheme of Examination code paper/ instruction/week Duration CIA CE Component of Exam Total Credit Theory Practic al FIRST SEMESTER I Theory of 5 - 3 40 60 100 3 17MMUC01 Indian Music –I I 17MMUC02 Biography-I 4 - 3 40 60 100 3 I History of 4 - 3 40 60 100 3 17MMUC03 Indian Music-I I Concert Forms- 5 - 3 40 60 100 4 17MMUC04 Theory I Kalpitha - 5 3 40 60 100 4 17MMUC05 Sangeetha - Practical-I I Compositions of - 5 3 40 60 100 4 Tamil 17MMUC06 Composers - Practical-II II 17MSXCS1 CSS - 2 - 25 25 - SECOND SEMESTER I History of - 3 40 60 100 3 17MMUC07 Indian Music-II 4 I Research - 3 40 60 100 3 Methodology 5 17MMUC08 in Music (Theory) I 4 - 3 40 60 100 4 17MMUC09 Operas and Dance dramas I Nadopasana - 5 3 40 60 100 4 Kritis of 17MMUC10 Tyagaraja- Practical-III I Musical - 5 3 40 60 100 4 17MMUC11 Compositions - Practical- IV I 1 - - - - 100 2 17MMUC12 Mini Project II 17MMUM01 MOOC - - - - - - 2 I 17MMUI01 Inter 2 2 3 40 60 100 4 disciplinary Course II 17MSXCS1 CSS - 2 3 25 50 75 1 Part Subject code Name of the paper/ Hrs of Scheme of Examination Component instruction/week Theory Practical Duration CIA CE Total Credit of Exam Internship during summer vacation for one month THIRD SEMESTER I 17MMUC13 Musicology 4 - 3 40 60 100 3 I -

Performing Arts (91 – 95)
PERFORMING ARTS (91 – 95) One of the following five syllabuses may be offered: Western Music (93) Hindustani Music (91) Indian Dance (94) Carnatic Music (92) Drama (95) HINDUSTANI MUSIC (91) CLASS X The syllabus is divided into three sections: PRACTICAL Section A - Vocal Music 1. Bhairav, Bhopaali and Malkauns - Singing of Section B - Instrumental Music Chotakhayal song in any one raga, as mentioned above (with alaaps and taans). Lakshangeet and Section C - Tabla. Swarmalika in the other two ragas. PART 1: THEORY – 100 Marks 2. Padhant (Reciting)-Thekas of the following new taals - Rupak, Jhaptaal and Deepchandi in Dugun SECTION A: HINDUSTANI VOCAL MUSIC and Chaugun, showing Tali, Khali and Matras on 1. (a) Non-detail terms: Sound (Dhwani), Meend, hands. Kan (Sparsha swar), Gamak, Tigun, Thumri, 3. Identification of ragas - Bhairav, Bhoopali and Poorvang, Uttarang, Poorva Raga and Uttar Malkauns. Raga. SECTION B (b) Detailed topics: Nad, three qualities of Nad (volume, pitch, timbre); Shruti and placement HINDUSTANI INSTRUMENTAL MUSIC of 12 swaras; Dhrupad and Dhamar. (EXCLUDING TABLA) 2. Description of the three ragas - Bhairav, Bhoopali THEORY and Malkauns, their Thaat, Jati, Vadi-Samvadi, Swaras (Varjit and Vikrit), Aroha-Avaroha, Pakad, 1. (a) Non-detail terms: Sound (Dhwani); Kan; time of raga and similar raga. Meend, Zamzama; Gamak; Baj; Jhala; Tigun. (b) Detailed topics: Nad; three qualities of Nad 3. Writing in the Taal notation, the three Taals - Rupak, Jhaptaal and Deepchandi (Chanchar), their (volume, pitch, timbre); Shruti and placement Dugun, Tigun and Chaugun. of 12 swaras; Maseetkhani and Razakhani 4. Knowledge of musical notation system of Pt. V.N. -

The Place of Performance in a Landscape of Conquest: Raja Mansingh's Akhārā in Gwalior
South Asian History and Culture ISSN: 1947-2498 (Print) 1947-2501 (Online) Journal homepage: https://www.tandfonline.com/loi/rsac20 The place of performance in a landscape of conquest: Raja Mansingh’s akhārā in Gwalior Saarthak Singh To cite this article: Saarthak Singh (2020): The place of performance in a landscape of conquest: Raja Mansingh’s akhārā in Gwalior, South Asian History and Culture, DOI: 10.1080/19472498.2020.1719756 To link to this article: https://doi.org/10.1080/19472498.2020.1719756 Published online: 30 Jan 2020. Submit your article to this journal Article views: 21 View related articles View Crossmark data Full Terms & Conditions of access and use can be found at https://www.tandfonline.com/action/journalInformation?journalCode=rsac20 SOUTH ASIAN HISTORY AND CULTURE https://doi.org/10.1080/19472498.2020.1719756 The place of performance in a landscape of conquest: Raja Mansingh’s akhārā in Gwalior Saarthak Singh Institute of Fine Arts, New York University, New York, NY, USA ABSTRACT KEYWORDS In the forested countryside of Gwalior lie the vestiges of a little-known akhārā; landscape; amphitheatre (akhārā) attributed to Raja Mansingh Tomar (r. 1488–1518). performance; performativity; A bastioned rampart encloses the once-vibrant dance arena: a circular stage dhrupad; rāsalīlā in the centre, surrounded by orchestral platforms and an elevated viewing gallery. This purpose-built performance space is a unique monumentalized instance of widely-prevalent courtly gatherings, featuring interpretive dance accompanied by music. What makes it most intriguing is the archi- tectural play between inside|outside, between the performance stage and the wilderness landscape. -

Evaluation of the Effects of Music Therapy Using Todi Raga of Hindustani Classical Music on Blood Pressure, Pulse Rate and Respiratory Rate of Healthy Elderly Men
Volume 64, Issue 1, 2020 Journal of Scientific Research Institute of Science, Banaras Hindu University, Varanasi, India. Evaluation of the Effects of Music Therapy Using Todi Raga of Hindustani Classical Music on Blood Pressure, Pulse Rate and Respiratory Rate of Healthy Elderly Men Samarpita Chatterjee (Mukherjee) 1, and Roan Mukherjee2* 1 Department of Hindustani Classical Music (Vocal), Sangit-Bhavana, Visva-Bharati (A Central University), Santiniketan, Birbhum-731235,West Bengal, India 2 Department of Human Physiology, Hazaribag College of Dental Sciences and Hospital, Demotand, Hazaribag 825301, Jharkhand, India. [email protected] Abstract Several studies have indicated that music therapy may affect I. INTRODUCTION cardiovascular health; in particular, it may bring positive changes Music may be regarded as the projection of ideas as well as in blood pressure levels and heart rate, thereby improving the emotions through significant sounds produced by an instrument, overall quality of life. Hence, to regulate blood pressure, music voices, or both by taking into consideration different elements of therapy may be regarded as a significant complementary and alternative medicine (CAM). The respiratory rate, if maintained melody, rhythm, and harmony. Music plays an important role in within the normal range, may promote good cardiac health. The everyone’s life. Music has the power to make one experience aim of the present study was to evaluate the changes in blood harmony, emotional ecstasy, spiritual uplifting, positive pressure, pulse rate and respiratory rate in healthy and disease-free behavioral changes, and absolute tranquility. The annoyance in males (age 50-60 years), at the completion of 30 days of music life may increase in lack of melody and harmony. -

Ragang Based Raga Identification System
IOSR Journal Of Humanities And Social Science (IOSR-JHSS) Volume 16, Issue 3 (Sep. - Oct. 2013), PP 83-85 e-ISSN: 2279-0837, p-ISSN: 2279-0845. www.Iosrjournals.Org Ragang based Raga Identification system Awadhesh Pratap Singh Tomer Assistant Professor (Music-vocal), Department of Music Dr. H. S. G. Central University Sagar M.P. Gopal Sangeet Mahavidhyalaya Mahaveer Chowk Bina Distt. Sagar (M.P.) 470113 Abstract: The paper describes the importance of Ragang in the Raga classification system and its utility as being unique musical patterns; in raga identification. The idea behind the paper is to reinvestigate Ragang with a prospective to use it in digital classification and identification system. Previous works in this field are based on Swara sequence and patterns, Pakad and basic structure of Raga individually. To my best knowledge previous works doesn’t deal with the Ragang Patterns for identification and thus the paper approaches Raga identification with a Ragang (musical pattern group) base model. This work also reviews the Thaat-Raagang classification system. This describes scope in application for Automatic digital teaching of classical music by software program to analyze music (Classical vocal and instrumental). The Raag classification should be flawless and logically perfect for best ever results. Key words: Aadhar shadaj, Ati Komal Gandhar , Bahar, Bhairav, Dhanashri, Dhaivat, Gamak, Gandhar, Gitkarri, Graam, Jati Gayan, Kafi, Kanada, Kann, Komal Rishabh , Madhyam, Malhar, Meed, Nishad, Raga, Ragang, Ragini, Rishabh, Saarang, Saptak, Shruti, Shrutiantra, Swaras, Swar Prastar, Thaat, Tivra swar, UpRag, Vikrat Swar A Raga is a tonal frame work for composition and improvisation. It embodies a unique musical idea.(Balle and Joshi 2009, 1) Ragang is included in 10 point Raga classification of Saarang Dev, With Graam Raga, UpRaga and more. -

108 Melodies
SRI SRI HARINAM SANKIRTAN - l08 MELODIES - INDEX CONTENTS PAGE CONTENTS PAGE Preface 1-2 Samant Sarang 37 Indian Classical Music Theory 3-13 Kurubh 38 Harinam Phylosphy & Development 14-15 Devagiri 39 FIRST PRAHAR RAGAS (6 A.M. to 9 A.M.) THIRD PRAHAR RAGAS (12 P.M. to 3 P.M.) Vairav 16 Gor Sarang 40 Bengal Valrav 17 Bhimpalasi 4 1 Ramkal~ 18 Piloo 42 B~bhas 19 Multani 43 Jog~a 20 Dhani 44 Tori 21 Triveni 45 Jaidev 22 Palasi 46 Morning Keertan 23 Hanskinkini 47 Prabhat Bhairav 24 FOURTH PKAHAR RAGAS (3 P.M. to 6 P.M.) Gunkali 25 Kalmgara 26 Traditional Keertan of Bengal 48-49 Dhanasari 50 SECOND PRAHAR RAGAS (9 A.M. to 12 P.M.) Manohar 5 1 Deva Gandhar 27 Ragasri 52 Bha~ravi 28 Puravi 53 M~shraBhairav~ 29 Malsri 54 Asavar~ 30 Malvi 55 JonPurl 3 1 Sr~tank 56 Durga (Bilawal That) 32 Hans Narayani 57 Gandhari 33 FIFTH PRAHAR RAGAS (6 P.M. to 9 P.M.) Mwa Bilawal 34 Bilawal 35 Yaman 58 Brindawani Sarang 36 Yaman Kalyan 59 Hem Kalyan 60 Purw Kalyan 61 Hindol Bahar 94 Bhupah 62 Arana Bahar 95 Pur~a 63 Kedar 64 SEVENTH PRAHAR RAGAS (12 A.M. to 3 A.M.) Jaldhar Kedar 65 Malgunj~ 96 Marwa 66 Darbar~Kanra 97 Chhaya 67 Basant Bahar 98 Khamaj 68 Deepak 99 Narayani 69 Basant 100 Durga (Khamaj Thhat) 70 Gaur~ 101 T~lakKarnod 71 Ch~traGaur~ 102 H~ndol 72 Shivaranjini 103 M~sraKhamaj 73 Ja~tsr~ 104 Nata 74 Dhawalsr~ 105 Ham~r 75 Paraj 106 Mall Gaura 107 SIXTH PRAHAR RAGAS (9Y.M. -

A Study on the Effects of Music Listening Based on Indian Time Theory of Ragas on Patients with Pre-Hypertension
International Journal of Scientific & Engineering Research Volume 9, Issue 1, January-2018 ISSN 2229-5518 370 A STUDY ON THE EFFECTS OF MUSIC LISTENING BASED ON INDIAN TIME THEORY OF RAGAS ON PATIENTS WITH PRE-HYPERTENSION Suguna V Masters in Indian Music, PGD in Music Therapy IJSER IJSER © 2018 http://www.ijser.org International Journal of Scientific & Engineering Research Volume 9, Issue 1, January-2018 ISSN 2229-5518 371 1. ABSTRACT 1.1 INTRODUCTION: Pre-hypertension is more prevalent than hypertension worldwide. Management of pre- hypertensive state is usually with lifestyle modifications including, listening to relaxing music that can help in preventing the progressive rise in blood pressure and cardio-vascular disorders. This study was taken up to find out the effects of listening to Indian classical music based on time theory of Ragas (playing a Raga at the right time) on pre-hypertensive patients and how they respond to this concept. 1.2 AIM & OBJECTIVES: It has been undertaken with an aim to understand the effect of listening to Indian classical instrumental music based on the time theory of Ragas on pre-hypertensive patients. 1.3 SUBJECTS & METHODS: This study is a repeated measure randomized group designed study with a music listening experimental group and a control group receiving no music intervention. The study was conductedIJSER at Center for Music Therapy Education and Research at Mahatma Gandhi medical college and research institute, Pondicherry. 30 Pre-hypertensive out patients from the Department of General Medicine participated in the study after giving informed consent form. Systolic BP (SBP), Diastolic BP (DBP), Pulse Rate (PR) and Respiratory Rate (RR) measures were taken on baseline and every week for a month. -

3:3:6:3 Some Bandishes of Agra Gharana - Notations
3:3:6:3 Some Bandishes of Agra Gharana - Notations RAGA: JOG DHRUPAD (CHAUTAAL) (Composer: Haji Sujan Khan 'Sujan') Sthayi: Pratham maana Allaah, jin rachyo noor paak, Nabi ji pe rakh imaana, e re 'Sujaan' │ Antara: Valiyan mana shaahe mardaan, Taahir mana saiyadaa, Imaan mana hasanain, Deen mana kalama, Kitaab mana Quraan ││ Sthayi x o 2 o 3 4 S S Ṇ Ṉ ̣ Ṉ ̣ P ̣ Ṇ S S - M - G̱ S G̱ S Pra tha ma maa - na - A - lla- - h Ṇ Ṉ Ṇ Ṇ S - S - S Ṉ ̣ Ṉ ̣ P̣ ̣ - P ̣ Ji na ra - chyo - noo - r paa - k Ṇ S G - M P P P MP - PM P Na bi ji - pe ra kha i maa - - na M P M G̱ PM PG MS G̱ Ṉ ̣ S P P M G̱ S G̱ S E - - - - - re - - Su jaa - - - - n x o 2 o 3 4 Antara G M P N N N Ṡ Ṡ Ṡ Ṡ - Ṡ Va li ya na ma na shaa he mar daa - na ̇̇ N Ṡ Ṡ Ġ Ġ Ṁ MĠ̠ Ġ̠ Ṡ Ṉ P P Taa he ra ma na sai - ya daa - - - MP PM MG G G M P MG M G̠ S G̠ S I maa - ma ma na ha sa - - nai - - na RAGA: JOG DHRUPAD (CHAUTAAL) contd.... Ṇ S G - M P P - N NṠ - Ṡ Dee na ma - na ka la - maa - - - ki Ṡ N̠ P M G MP P - M G̠ S G̠ S Taa - ba ma na Qu - raa - - - - - na x o 2 o 3 4 RAGA: DEEPAK KEDAR (VILAMBIT TRITAL) Sthayi: Sab jhootho bhekh pasaaro re...│ Antara: Bahut chunaaye mahalhu sare, jo makari no jalo re...││ Sthayi PDPḾP Ṡ - D P (M) SR S SR Ḿ - P - RḾPD,P (P) M sa - ba - jhu - tho - (bhe) - kh pasa - - ro - re - - - , - (- ) - x 2 o 3 Antara P P Ṡ Ṡ Ṡ Ṡ ṠD ṠṘ ṠDPM SR,S S M G P P PḾP RḾPD,P (P) M bahu ta chu na ye mahe lau sa - - - - , re jo maka ri no jalo re - - -, - ( - ) - x 2 o 3 RAGA : BAHAR (TAAL: DHAMAR) (Composer: 'Shyamrang') Sthayi: Aayi bahaar ritu alabeli, Saba bana phule saraso peelee