Arxiv:1901.04985V1 [Cs.DC] 12 Jan 2019 Computing Power of Embedded Or Edge Devices, Neural Net- Tion, Saving Computing Resources
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

106 INKSCAPE – FREE VECTOR GRAPHICS EDITOR Grabareva A
INKSCAPE – FREE VECTOR GRAPHICS EDITOR Grabareva A. Supervisor: Voevodina M. E-mail: [email protected], [email protected] Kharkiv, О.М. Beketov National University of Urban Economy in Kharkiv Inkscape is a cross-platform, powerful enough and in many ways competitive free vector graphics editor with open source code, and in which the SVG format is used as the main standard for work. It is convenient for creating both artistic and technical illustrations. Inkscape is an analogue of such graphic editors as Corel Draw, Adobe Illustrator, Xara X and Freehand. Intended use: - illustrations for office circulars, presentations, creation of logos, business cards, posters; - technical illustrations (diagrams, graphics, etc.); - vector graphics for high-quality printing (with preliminary import of SVG into Scribus); - web graphics – from banners to site layouts, icons for applications and website buttons, - graphics for games. Main characteristics of Inkscape: - the program is free and distributed under the GNU General Public License; - cross-platform; - the program supports the following document formats: import – almost all popular and frequently used formats: SVG, JPEG, GIF, BMP, EPS, PDF, PNG, ICO, and many additional ones, such as SVGZ, EMF, PostScript, AI, Dia, Sketch, TIFF, XPM, WMF, WPG, GGR, ANI, CUR, PCX, PNM, RAS, TGA, WBMP, XBM, XPM; export – the main formats are PNG and SVG and many additional EPS, PostScript, PDF, Dia, AI, Sketch, POV-Ray, LaTeX, OpenDocument Draw, GPL, EMF, POV, DXF; - there is support for layers; - -

Release Notes for Fedora 15
Fedora 15 Release Notes Release Notes for Fedora 15 Edited by The Fedora Docs Team Copyright © 2011 Red Hat, Inc. and others. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/. The original authors of this document, and Red Hat, designate the Fedora Project as the "Attribution Party" for purposes of CC-BY-SA. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, JBoss, MetaMatrix, Fedora, the Infinity Logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. For guidelines on the permitted uses of the Fedora trademarks, refer to https:// fedoraproject.org/wiki/Legal:Trademark_guidelines. Linux® is the registered trademark of Linus Torvalds in the United States and other countries. Java® is a registered trademark of Oracle and/or its affiliates. XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries. All other trademarks are the property of their respective owners. -

Camcorder Multimedia Framework with Linux and Gstreamer
Camcorder multimedia framework with Linux and GStreamer W. H. Lee, E. K. Kim, J. J. Lee , S. H. Kim, S. S. Park SWL, Samsung Electronics [email protected] Abstract Application Applications Layer Along with recent rapid technical advances, user expec- Multimedia Middleware Sequencer Graphics UI Connectivity DVD FS tations for multimedia devices have been changed from Layer basic functions to many intelligent features. In order to GStreamer meet such requirements, the product requires not only a OSAL HAL OS Layer powerful hardware platform, but also a software frame- Device Software Linux Kernel work based on appropriate OS, such as Linux, support- Drivers codecs Hardware Camcorder hardware platform ing many rich development features. Layer In this paper, a camcorder framework is introduced that is designed and implemented by making use of open Figure 1: Architecture diagram of camcorder multime- source middleware in Linux. Many potential develop- dia framework ers can be referred to this multimedia framework for camcorder and other similar product development. The The three software layers on any hardware platform are overall framework architecture as well as communica- application, middleware, and OS. The architecture and tion mechanisms are described in detail. Furthermore, functional operation of each layer is discussed. Addi- many methods implemented to improve the system per- tionally, some design and implementation issues are ad- formance are addressed as well. dressed from the perspective of system performance. The overall software architecture of a multimedia 1 Introduction framework is described in Section 2. The framework design and its operation are introduced in detail in Sec- It has recently become very popular to use the internet to tion 3. -
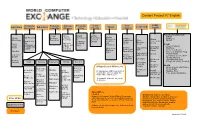
Content Project V7 English
Content Project V7 English Public Computer Entrepre- Climate Program- Solar Water Tech Leadership Agriculture Recycling Education neurship Change ming Energy Literacy Health Potential and Growth CD3W Videos BFOIT CD3W IEARN We Recycle Business Lessons Introduction Resources CD3W CD3W Resources Getting Where GirlRising Resources Resources Readings to on Solar Started with Class UNGEI How to Set Computer Energy on Water There Is No and Ubuntu Manage- Doctor Peace Up Nat’l Geo Program- 10.04 ment STEM Computer a Climate.gov ming Sanitation Corps UNESCO Khan Academy Books Refurbishing CLEAN Getting Empowering Center and more UN Lesson HIV/AIDS WikiSlice Plans on Started with Girls Library Ck-12 Textbooks Adrodok Water OpenOffice Intro to Computer Prog Empowering Medline Thinkersmith Vegetable How to Girls-School Computer Sci in a Box Garden Assemble a Computer Ubuntu Manual Life Skills Childhood LibreOffice Guides Healthy Illness Harvest Math Science Reference Writing Soc.Sci. Promoting Comp. for Class. Guidesl Powerful Health for People Health Wikipedia and Wikibooks Children Hesperian Health Guides Khan Video BlueMall Medline Learning Volunteer- Teach AIDS Khan Video Lessons Basic 20 Gigabytes with thousands of Health Medline Plus Lessons Spelling Center ism Activities for Language searchable articles using the Pop. Council Activities Ck-12 Kiwix offline wiki-reader Primary Gr. Ck-12 Textbooks Dictionary Common World Map Textbooks Sense Project HIV Toolkit Wiki HowTo Thousands of books for youth WikiSlice Compositio of all ages Unesco -Animals -

The Gnome Desktop Comes to Hp-Ux
GNOME on HP-UX Stormy Peters Hewlett-Packard Company 970-898-7277 [email protected] THE GNOME DESKTOP COMES TO HP-UX by Stormy Peters, Jim Leth, and Aaron Weber At the Linux World Expo in San Jose last August, a consortium of companies, including Hewlett-Packard, inaugurated the GNOME Foundation to further the goals of the GNOME project. An organization of open-source software developers, the GNOME project is the major force behind the GNOME desktop: a powerful, open-source desktop environment with an intuitive user interface, a component-based architecture, and an outstanding set of applications for both developers and users. The GNOME Foundation will provide resources to coordinate releases, determine future project directions, and promote GNOME through communication and press releases. At the same conference in San Jose, Hewlett-Packard also announced that GNOME would become the default HP-UX desktop environment. This will enhance the user experience on HP-UX, providing a full feature set and access to new applications, and also will allow commonality of desktops across different vendors' implementations of UNIX and Linux. HP will provide transition tools for migrating users from CDE to GNOME, and support for GNOME will be available from HP. Those users who wish to remain with CDE will continue to be supported. Hewlett-Packard, working with Ximian, Inc. (formerly known as Helix Code), will be providing the GNOME desktop on HP-UX. Ximian is an open-source desktop company that currently employs many of the original and current developers of GNOME, including Miguel de Icaza. They have developed and contributed applications such as Evolution and Red Carpet to GNOME. -

This Is a Free, User-Editable, Open Source Software Manual. Table of Contents About Inkscape
This is a free, user-editable, open source software manual. Table of Contents About Inkscape....................................................................................................................................................1 About SVG...........................................................................................................................................................2 Objectives of the SVG Format.................................................................................................................2 The Current State of SVG Software........................................................................................................2 Inkscape Interface...............................................................................................................................................3 The Menu.................................................................................................................................................3 The Commands Bar.................................................................................................................................3 The Toolbox and Tool Controls Bar........................................................................................................4 The Canvas...............................................................................................................................................4 Rulers......................................................................................................................................................5 -

Does That Look Right?
Gregory Helmstetter Digital Preservation Final Project December 15, 2017 Does That Look Right? Playback Software in Digital Preservation With the ubiquity of digital files persisting throughout every aspect of modern life, from cell phone videos to time-based art to video preservation and archiving, one major question is often asked when playing back a digital file: Does that look right? This is an important question for several reasons. First, this is often the first question conservators, preservationists, or archivists ask when playing back video on any platform, whether it be in digital playback software or on analog machines. Second, as of the writing of this paper, I am frankly still questioning whether or not particular digital videos look the way they were intended to look and still questioning how software plays a role in the presentation of videos. And third, the results of this paper and the informal case study I conducted specifically to test playback software may generate more questions that conservators, et al, should ask when playing back digital files. This paper, therefore, will survey a number of playback software tools that archives rely on in quality control processes (particularly as they pertain to large-scale digital preservation workflows); it will consider the critical role that software plays when displaying digital content for preservation and quality control processes and how software is integrated into these workflows; and it will outline and address issues one might encounter when playing digital video files on different software. The Case Study First it will be beneficial to discuss from where this idea originated. -

Video Compression Optimized for Racing Drones
Video compression optimized for racing drones Henrik Theolin Computer Science and Engineering, master's level 2018 Luleå University of Technology Department of Computer Science, Electrical and Space Engineering Video compression optimized for racing drones November 10, 2018 Preface To my wife and son always! Without you I'd never try to become smarter. Thanks to my supervisor Staffan Johansson at Neava for providing room, tools and the guidance needed to perform this thesis. To my examiner Rickard Nilsson for helping me focus on the task and reminding me of the time-limit to complete the report. i of ii Video compression optimized for racing drones November 10, 2018 Abstract This thesis is a report on the findings of different video coding tech- niques and their suitability for a low powered lightweight system mounted on a racing drone. Low latency, high consistency and a robust video stream is of the utmost importance. The literature consists of multiple comparisons and reports on the efficiency for the most commonly used video compression algorithms. These reports and findings are mainly not used on a low latency system but are testing in a laboratory environment with settings unusable for a real-time system. The literature that deals with low latency video streaming and network instability shows that only a limited set of each compression algorithms are available to ensure low complexity and no added delay to the coding process. The findings re- sulted in that AVC/H.264 was the most suited compression algorithm and more precise the x264 implementation was the most optimized to be able to perform well on the low powered system. -

2.5 Gstreamer
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND MULTIMEDIA SROVNÁNÍ MULTIMEDIÁLNÍCH FRAMEWORKŮ COMPARISON OF MULTIMEDIA FRAMEWORKS BAKALÁŘSKÁ PRÁCE BACHELOR‘S THESIS AUTOR PRÁCE ZDENKO BRANDEJS AUTHOR VEDOUCÍ PRÁCE ING. DAVID BAŘINA SUPERVISOR BRNO 2016 Abstrakt Cílem této práce je vytvořit srovnání nejznámějších multimediálních frameworků podle podporovaných platforem, formátů a využití. Seznámit se s multimediálními frameworky a jejich knihovnami pro práci s multimédii. Konkrétně se jedná o Video for Windows, DirectShow, Media Foundation, FFmpeg, GStreamer, xine a QuickTime. Detailně popsat jak jednotlivé technologie fungují včetně jejich architektury. Vytvoření webového tutoriálu, kde se uplatní teoretické znalosti při tvorbě přehrávačů. Abstract The aim of this work is to create a comparison of the most famous multimedia frameworks according to supported platforms, formats and usage. To familiarize with a multimedia frameworks and their libraries for work with multimedia. Concretely with Video for Windows, DirectShow, Media Foundation, FFmpeg, GStreamer, xine and QuickTime. Describe in detail, how separate technologies work including their architectures. Building web tutorial, where will apply theoretical knowledge during creating players. Klíčová slova Multimédia, framework, Video for Windows, DirectShow, GStreamer, FFmpeg, xine, QuickTime, Media Foundation, srovnání, tutoriál, přehrávač, graf filtrů, řetězení. Keywords Multimedia, framework, Video for Windows, DirectShow, GStreamer, FFmpeg, xine, QuickTime, Media Foundation, comparison, tutorial, player, filter graph, pipeline. Citace BRANDEJS, Zdenko. Srovnání multimediálních frameworků. Brno, 2016. 20 s. Bakalářská práce. Vysoké učení technické v Brně, Fakulta informačních technologií. Vedoucí práce David Bařina. Název bakalářské práce v jazyce práce Prohlášení Prohlašuji, že jsem tuto bakalářskou práci vypracoval samostatně pod vedením Ing. -

LIFE Packages
LIFE packages Index Office automation Desktop Internet Server Web developpement Tele centers Emulation Health centers Graphics High Schools Utilities Teachers Multimedia Tertiary schools Programming Database Games Documentation Internet - Firefox - Browser - Epiphany - Nautilus - Ftp client - gFTP - Evolution - Mail client - Thunderbird - Internet messaging - Gaim - Gaim - IRC - XChat - Gaim - VoIP - Skype - Videomeeting - Gnome meeting - GnomeBittorent - P2P - aMule - Firefox - Download manager - d4x - Telnet - Telnet Web developpement - Quanta - Bluefish - HTML editor - Nvu - Any text editor - HTML galerie - Album - Web server - XAMPP - Collaborative publishing system - Spip Desktop - Gnome - Desktop - Kde - Xfce Graphics - Advanced image editor - The Gimp - KolourPaint - Simple image editor - gPaint - TuxPaint - CinePaint - Video editor - Kino - OpenOffice Draw - Vector vraphics editor - Inkscape - Dia - Diagram editor - Kivio - Electrical CAD - Electric - 3D modeller/render - Blender - CAD system - QCad Utilities - Calculator - gCalcTool - gEdit - gxEdit - Text editor - eMacs21 - Leafpad - Application finder - Xfce4-appfinder - Desktop search tool - Beagle - File explorer - Nautilus -Archive manager - File-Roller - Nautilus CD Burner - CD burner - K3B - GnomeBaker - Synaptic - System updates - apt-get - IPtables - Firewall - FireStarter - BackupPC - Backup - Amanda - gnome-terminal - Terminal - xTerm - xTerminal - Scanner - Xsane - Partition editor - gParted - Making image of disks - Partitimage - Mirroring over network - UDP Cast -

The Official Ubuntu Book
Praise for Previous Editions of The Official Ubuntu Book “The Official Ubuntu Book is a great way to get you started with Ubuntu, giving you enough information to be productive without overloading you.” —John Stevenson, DZone book reviewer “OUB is one of the best books I’ve seen for beginners.” —Bill Blinn, TechByter Worldwide “This book is the perfect companion for users new to Linux and Ubuntu. It covers the basics in a concise and well-organized manner. General use is covered separately from troubleshooting and error-handling, making the book well-suited both for the beginner as well as the user that needs extended help.” —Thomas Petrucha, Austria Ubuntu User Group “I have recommended this book to several users who I instruct regularly on the use of Ubuntu. All of them have been satisfied with their purchase and have even been able to use it to help them in their journey along the way.” —Chris Crisafulli, Ubuntu LoCo Council, Florida Local Community Team “This text demystifies a very powerful Linux operating system . In just a few weeks of having it, I’ve used it as a quick reference a half-dozen times, which saved me the time I would have spent scouring the Ubuntu forums online.” —Darren Frey, Member, Houston Local User Group This page intentionally left blank The Official Ubuntu Book Seventh Edition This page intentionally left blank The Official Ubuntu Book Seventh Edition Matthew Helmke Amber Graner With Kyle Rankin, Benjamin Mako Hill, and Jono Bacon Upper Saddle River, NJ • Boston • Indianapolis • San Francisco New York • Toronto • Montreal • London • Munich • Paris • Madrid Capetown • Sydney • Tokyo • Singapore • Mexico City Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. -

Developing Multimedia Applications with DCCP
BEFN$?FN DCCP ;\m\cfg`e^dlck`d\[`XXggc`ZXk`fejn`k_;::G :FE><JK@FE :FEKIFC 8eeX#=fkfc`X The DCCP protocol gives multimedia developers a powerful alternative to TCP and UDP. BY LEANDRO MELO DE SALES ver the past few years, develop- In this article, I examine the DCCP DCCP inherits the connection-oriented ers have unveiled a new genera- protocol and show how to enable DCCP and congestion-control features from Ftion of network applications that in Linux. Also, I will explain how to use TCP, and, from UDP, DCCP inherits unre- transmit and receive multimedia content the GStreamer DCCP plugin to create a liable transmission. over the Internet. New multimedia appli- simple client-server DCCP application. In addition to connection-oriented and cations based on technologies such as DCCP was first introduced by Kohler congestion-control features, TCP provides Voice over IP, Internet radio, online gam- et al. in July 2001 at the IETF transport reliable data transfer. This reliability fea- ing, and video conferencing are becom- group. The DCCP protocol provides spe- ture limits the transmission rate for a ing increasingly popular thanks to the cific features designed to address some given connection. When packets are lost, availability of development libraries and of the problems developers have faced TCP decreases its transmission rate, and it the abundance of high-speed networks. writing multimedia applications with increases the transmission rate again In the past, most Internet applications TCP and UDP, such as delay and jitter when it sends packets successfully. To have used either the Transmission Con- caused by network congestion.