Memory Architecture for Quantom-Dot Cellular Automata a Thesis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Magnetic Recording and Readout Memory
SNS college of Technology Coimbatore-641 035 MAGNETIC RECORDING AND READOUT MEMORY Nowadays, large number of information are stored in (or) retrieved from the storage devices, by using devices is magnetic recording heads and they function according to the principle of magnetic induction. Generally Ferro or Ferrimagnetic materials are used in the storage devices because in this type of materials only the magnetic interaction between only two dipoles align themselves parallel to each other. Due to this parallel alignment even if we apply small amount of magnetic field, a large value of magnetization is produced. By using this property information are stored in storage devices. In the storage devices, the recording of digital data (0‟s and 1‟s) depends upon the direction of magnetization in the medium. Magnetic parameters for Recording 1. When current is passed through a coil, a magnetic field is induced. This principle called “Electromagnetic Induction” is used in storage devices. 2. The case with which the material can be magnetized is another parameter. 3. We know the soft magnetic materials are the materials which can easily be magnetized and demagnetized. Hence a data can be stored and erased easily. Such magnetic materials are used in temporary storage devices. 4. Similarly, we know hard magnetic materials cannot be easily magnetized and demagnetized. So such magnetic materials are used in permanent storage devices. 5. In soft magnetic materials, the electrical resistance varies with respect to the magnetization and this effect is called magneto-resistance. This parameter is used in specific thin film systems. 19PYB102 & PHYSICS OF MATERIALS AND PHOTONICS D.SENGOTTAIYAN /AP/PHYSICS Page 1 SNS college of Technology Coimbatore-641 035 The magnetic medium is made of magnetic materials (Ferro or Ferric oxide) deposited on this plastic. -

Magnetic Storage- Magnetic-Core Memory, Magnetic Tape,RAM
Magnetic storage- From magnetic tape to HDD Juhász Levente 2016.02.24 Table of contents 1. Introduction 2. Magnetic tape 3. Magnetic-core memory 4. Bubble memory 5. Hard disk drive 6. Applications, future prospects 7. References 1. Magnetic storage - introduction Magnetic storage: Recording & storage of data on a magnetised medium A form of „non-volatile” memory Data accessed using read/write heads Widely used for computer data storage, audio and video applications, magnetic stripe cards etc. 1. Magnetic storage - introduction 2. Magnetic tape 1928 Germany: Magnetic tape for audio recording by Fritz Pfleumer • Fe2O3 coating on paper stripes, further developed by AEG & BASF 1951: UNIVAC- first use of magnetic tape for data storage • 12,7 mm Ni-plated brass-phosphorus alloy tape • 128 characters /inch data density • 7000 ch. /s writing speed 2. Magnetic tape 2. Magnetic tape 1950s: IBM : patented magnetic tape technology • 12,7 mm wide magnetic tape on a 26,7 cm reel • 370-730 m long tapes 1980: 1100 m PET –based tape • 18 cm reel for developers • 7, 9 stripe tapes (8 bit + parity) • Capacity up to 140 MB DEC –tapes for personal use 2. Magnetic tape 2014: Sony & IBM recorded 148 Gbit /squareinch tape capacity 185 TB! 2. Magnetic tape Remanent structural change in a magnetic medium Analog or digital recording (binary storage) Longitudinal or perpendicular recording Ni-Fe –alloy core in tape head 2. Magnetic tape Hysteresis in magnetic recording 40-150 kHz bias signal applied to the tape to remove its „magnetic history” and „stir” the magnetization Each recorded signal will encounter the same magnetic condition Current in tape head proportional to the signal to be recorded 2. -

Investigation of Fast Initialization of Spacecraft Bubble Memory Systems Karen T, Looney, Charles D, Nichols., and Paul J, Hayes
N 8 4 - 2 7 0 7 7 NASA Technical Memorandum 85832 INVESTIGATION OF FAST INITIALIZATION OF SPACECRAFT BUBBLE MEMORY SYSTEMS KAREN T, LOONEY, CHARLES D, NICHOLS., AND PAUL J, HAYES JUNE 1984 NASA National Aeronautics and Space Administration Langley Research Center Hampton, Virginia 23665 SUMMARY Bubble domain technology offers significant improvement in reliability and functionality for spacecraft onboard memory applications. In considering potential memory system organizations, minimization of power in high capacity bubble memory systems necessitates the activation of only the desired portions of the memory. In power strobing arbitrary memory segments, a capability of fast turn-on is required. Bubble device architectures, which provide redundant loop coding in the bubble device, limit the initialization speed. Alternate initialization techniques have been investigated to overcome this design limitation. An initialization technique using a small amount of external storage has been demonstrated, using software written in 8085 assembly language and PL/M. ' This technique provides several orders of magnitude improvement over the normal initialization time. INTRODUCTION Bubble memory systems are quickly becoming a preferred storage medium in environments where a non-volatile storage medium is required. The utilization of a bubble storage system offers the benefits of increased reliability, reduced maintainance, and permanent data integrity. The implementaton of large bubble memory systems in spacecraft applications requires that the memory modules be power strobed for the conservation of the available energy resources. Each time a module is turned on for use it must be initialized to code the redundant loop information of the selected bubble devices into the bubble controller. Present structures of bubble systems dictate that a faster initialization procedure is needed in order to capitalize on the advantages offered by a bubble memory system. -

Megabits to Megabytes: Bubble Memory System Design and Board Layout
A Publication of Intel Corporation September/October 1985 INTEL BRINGS HARMONY TO THE FACTORYFLOOR ApPLICATION NOTE Megabits to Megabytes: System Overview The Intel bubble memory solution consists of a highly so Bubble Memory System phisticated Bubble Memory Controller (BMC) that can sup port up to an entire megabyte for the 7200 controller, or up Design and Board Layout to four megabytes using the new 7225 Four-Megabit Bubble Memory Controller. In other words, one controller can sup by Steven K. Knapp port up to eight Bubble Storage Units (BSUs). he sophisticated seven-component bubble memory se Bubble Memory Controller (BMC) Tlection from Intel represents the most integrated solution The Bubble Memory Controller is a VLSI chip that provides for reliable, non-volatile memory applications. Bubble mem a complete bi-directional interface between the host micro ory's solid-state operation can offer much higher system processor system and the Bubble Memory Storage Unit reliability than that obtainable with other mass storage tech (BSU). The bubble memory designer's primary task is to nologies such as standard tape and disk drives, both of interface the Bubble Memory Controller (BMC) to the host which can suffer due to shock and vibration. Bubble memory microprocessor system. The interface to the BMC is much is compact, requires no routine maintenance, and can op like that of any standard peripheral controller, such as a erate in extreme temperatures, making it ideal for applica floppy-disk controller or a DMA controller. The actual electri tions such as industrial control or military systems that require cal interface between the BMC and the BSU is provided by consistent and maintenance-free operation. -
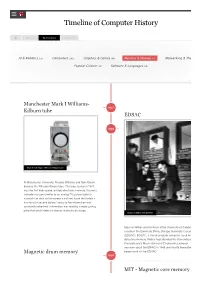
Timeline of Computer History
Timeline of Computer History By Year By Category Search AI & Robotics (55) Computers (145) Graphics & Games (48) Memory & Storage (61)(61) Networking & The Popular Culture (50) Software & Languages (60) Manchester Mark I Williams- 1947 Kilburn tube EDSAC 1949 Manchester Mark I Williams-Kilburn tube At Manchester University, Freddie Williams and Tom Kilburn develop the Williams-Kilburn tube. The tube, tested in 1947, was the first high-speed, entirely electronic memory. It used a cathode ray tube (similar to an analog TV picture tube) to store bits as dots on the screen’s surface. Each dot lasted a fraction of a second before fading so the information was constantly refreshed. Information was read by a metal pickup plate that would detect a change in electrical charge. Maurice Wilkes with EDSAC Maurice Wilkes and his team at the University of Cambrid construct the Electronic Delay Storage Automatic Calcula (EDSAC). EDSAC, a stored program computer, used me delay line memory. Wilkes had attended the University of Pennsylvania's Moore School of Engineering summer sessions about the ENIAC in 1946 and shortly thereafter Magnetic drum memory began work on the EDSAC. 1950 MIT - Magnetic core memory ERA founders with various magnetic drum memories Eager to enhance America’s codebreaking capabilities, the US Navy contracts with Engineering Research Associates (ERA) for a stored program computer. The result was Atlas, completed in 1950. Atlas used magnetic drum memory, which stored information on the outside of a rotating cylinder coated with ferromagnetic material and circled by read/write heads in Jay Forrester holding early core memory plane fixed positions. -

System-On-A-Chip
System-on-a-chip From Wikipedia, the free encyclopedia Jump to: navigation, search System-on-a-chip or system on chip (SoC or SOC) is an idea of integrating all components of a computer or other electronic system into a single integrated circuit (chip). It may contain digital, analog, mixed-signal, and often radio-frequency functions – all on one chip. A typical application is in the area of embedded systems. If it is not feasible to construct an SoC for a particular application, an alternative is a system in package (SiP) comprising a number of chips in a single package. SoC is believed to be more cost effective since it increases the yield of the fabrication and because its packaging is simpler. Contents [hide] • 1 Structure • 2 Design flow • 3 Fabrication • 4 See also • 5 External links [edit] Structure y513719001187192499 from [email protected] was published by D-Publish on August 15, 2007 Microcontroller-based System-on-a-Chip A typical SoC consists of: • One or more microcontroller, microprocessor or DSP core(s). • Memory blocks including a selection of ROM, RAM, EEPROM and Flash. • Timing sources including oscillators and phase-locked loops. • Peripherals including counter-timers, real-time timers and power-on reset generators. • External interfaces including industry standards such as USB, FireWire, Ethernet, USART, SPI. • Analog interfaces including ADCs and DACs. • Voltage regulators and power management circuits. These blocks are connected by either a proprietary or industry-standard bus such as the AMBA bus from ARM. DMA controllers route data directly between external interfaces and memory, by-passing the processor core and thereby increasing the data throughput of the SoC. -

Adaptation of Magnetic Bubble Memory in a Standard Microcomputer Environment
Calhoun: The NPS Institutional Archive Theses and Dissertations Thesis Collection 1981 Adaptation of magnetic bubble memory in a standard microcomputer environment Hicklin, Michael S. Monterey, California. Naval Postgraduate School http://hdl.handle.net/10945/20407 %M\- '('''''•''-• ,v?j'' -'''"I- IK?:<J,e4;^/>':f';^.•^''' >if"4';r;.'i.'''; „ " ? ..^' V V DUDLEY KNOX LIBRARY NAVAL P^STCr^-iJATE SCHOOL MONiEmE,, CA;..F. 93940 NAVAL POSTGRADUATE SCHOOL Monterey, California THESIS ADAPTATION OF MAGNETIC BUBBLE MEMORY IN A STANDARD MICROCOMPUTER ENVIRONMENT by Michael S. Hicklin and Jeffrey A. Neufeld December 1981 Thesis Advisor: R- R. Stilwell Approved for public release; distribution unlimited T20Z 1 ; IINCT^SSTFTED SKCuniTV CLASSiriCATlOM OF THIS ^ACe fWhmit 0«« Enlmfd) READ INSTRUCTTONS REPORT DOCUMENTATION PAGE BEFORE COMPLETTNO FORM \ nIpONT NUMaCM 2. OOVT ACCKtSiOM NO. 1 *eCl^ltNT"S CATALOG NUMBER 4. Sublltlmi 5. TITLE fmta TYPE OF REPORT ft PEOtOO COWERED Mas ter ' s Thesis Adaptation of Magnetic Bubble Memory in December 1981 a Standard Microcomputer Environment • . Pe«FO«MINO ORG. REPORT NUMSCR 7. AuThONi'*> • . CONTRACT OR GRANT NLMSCRC*; Michael S, Hicklin Jeffrey A, Neuf eld * PCMFOffMIMa OnOANlZATION NAMC ANO AOOMCtS 10. PROGRAM ELEMENT PROJECT T*S< AREA « WORK UNIT NUMBERS Naval Postgraduate School Monterey, California 93940 n CONTROLLING OFFICE NAMC AND AODMCSt 12. REPORT OATE Naval Postgraduate School December 1981 Monterey, California 93940 IS NUMBER OF PACES U MONlTOHiNC AGENCY NAME * AOORCStC'/ aillarwnt tram Catttroltlni OHIe») IS. SECUNITY CLASS, (ol Ihit r*>ortj Naval Postgraduate School Unclas s if ied Monterey, California 93940 rSa. OCCLASSIFICATION/ OOWNGRAOlNG SCHCOULC l«. OlSTRlSUTtON STATEMENT re/ tM« Ktptrt) Approved for public release; distribution unlimited 17. -

Review of Various Data Storage Techniques
International Journal of Science and Research (IJSR), India Online ISSN: 2319-7064 Review of Various Data Storage Techniques Rajeshwar Dass1, Namita2 1Department of Electronics and Communication Engineering DCRUST, Murthal, Sonepat, India [email protected] [email protected] Abstract: The data storage is one of the basic requirements of today’s technical world. Improved and new multimedia applications are demanding for more and more storage space. Hence to meet this requirement day by day new techniques are coming in to the picture. This paper summarizes the various techniques used for the storage of data, their characteristics & applications with their comparative analysis. Keywords: Memory, semiconductor storage, magnetic storage, optical storage. 1. Introduction Cost: Since the beginning of computing, hard drives have come down in price, and they continue to do so. Big Storing of data is very important and basic requirement of advantage of main memory is that has become a lot cheaper, today's life. All the applications we are using require the but its storage limitation is still a big factor. A RAM stick storage of many programs and day by day the applications often holds less than 1 percent of the data capacity of a hard are improving and the memory requirement is increasing and drive with the same price. to meet the current storage requirement we are reached to holography and 3D optical storing techniques, as for various Various types of magnetic memories are: multimedia applications the storage need is increasing day by day. 2.1 Magnetic tape This paper is organized as Section II describes the magnetic Today, except in some of the cases where we require legacy storage, its different types, advantages and disadvantages, compatibility, magnetic tape is generally used in cartridges Section III describes the semiconductor storage, its different for computers. -

Electronic Inventions and Discoveries
w Electronii In ItfililllatullHHI Discovert A- (KB Electronics from its earliest beginnings to the present day Fourth Edition ^5p jm ,#* GWA-Dummer Digitized by the Internet Archive in 2012 with funding from Gordon Bell http://archive.org/details/electronicinvent14gwad Electronic Inventions and Discoveries Electronic Inventions and Discoveries Electronics from its earliest beginnings to the present day 4th revised and expanded edition G W A Dummer MBE, CEng, FIEE, FIEEE, US Medal of Freedom (former Supt. Applied Physics, Royal Radar Establishment, UK) Institute of Physics Publishing Bristol and Philadelphia © G W A Dummer 1997 All rights reserved. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without the prior permission of the publisher. Multiple copying is permitted in accordance with the terms of licences issued by the Copyright Licensing Agency under the terms of its agreement with the Committee of Vice-Chancellors and Principals. First edition 1977 published under the title Electronic Inventions 1745-1976 Second edition 1978 {Electronic Inventions and Discoveries) Third revised edition 1983 British Library Cataloguing-in-Publication Data A catalogue record for this book is available from the British Library ISBN 7503 0376 X (hbk) ISBN 7503 0493 6 (pbk) Library of Congress Cataloging-in-Publication Data are available Published by Institute of Physics Publishing, wholly owned by The Institute of Physics, London Institute of Physics Publishing, Dirac House, Temple Back, Bristol BS1 6BE, UK US Editorial Office: Institute of Physics Publishing, The Public Ledger Building, Suite 1035, 150 South Independence Mall West, Philadelphia, PA 19106, USA Printed in the UK by J W Arrowsmith Ltd, Bristol. -

Bubble Memory System Design and Board Layout
APPLICATION AP-187 NOTE December 1984 MEGABITS TO MEGABYTES: Bubble Memory System Design and Board Layout STEVEN KNAPP APPLICATIONS ENGINEER INTEL CORPORATION @ Intel Corporation, 1984 Order Number: 290002-001 Intel Corporation makes no warranty for the use of its products and assumes no responsibility for any errors which may appear in this document nor does it make a commitment to update the information contained herein. Intel retains the right to make changes to these specifications at any time, without notice. Contact your local sales office to obtain the latest specifications before placing your order. The following are trademarks of Intel Corporation and may only be used to identify Intel Products: BITBUS, COMMputer, CREDIT, Data Pipeline, GENIUS, i, t ICE, iCS, iDBP, iDIS, 121CE, iLBX, im, iMMX, Insite, Intel, intel, intelBOS, Intelevi sion, inteligent identifier, inteligent Programming, Intellec, Intellink, iOSP, iPDS, iSBC, iSBX, iSDM, iSXM, Library Manager, MCS, Mega chassis, MICROMAINFRAME, MULTIBUS, MULTICHANNEL, MULTI MODULE, Plug-A-Bubble, PROMPT, Promware, QUEST, QUEX, Rip plemode, RMX/80, RUPI, Seamless, SOLO, SYSTEM 2000, and UPI, and the combination of ICE, iCS, iRMX, iSBC, MCS, or UPI and a numer ical suffix. MDS is an ordering code only and is not used as a product name or trademark. MDS~ is a registered trademark of Mohawk Data Sciences Corporation. 'MULTIBUS is a patented Intel bus. Additional copies of this manual or other Intel literature may be obtained from: Intel Corporation Liturature Department 3065 Bowers Avenue Santa Clara, CA 95051 MEGABITS TO CONTENTS PAGE MEGABYTES INTRODUCTION 1 Bubble Memory System Purpose and readership 1 Design SYSTEM OVERVIEW 1 and Board Layout One-megabit product line 1 SYSTEM EXPANSION 1 Board real-estate guidelines ......••....... -

The History of Computer Storage Innovation from 1928 to Today
1100//1122//2200115 TThhe HHiissttooryr y oof CCoommppuutteer SSttoorraagge ffrroom 1199338 - 2200113 | ZZeettttaa..nneett Enterprise-grade Cloud Backup 1.877.469.3882 and Disaster Recovery Login Blog Contact Us Pricing PRODUCTS IT INITIATIVES RESOURCES CUSTOMERS PARTNERS ABOUT US SEARCH The History of Computer Storage Innovation from 1928 to Today Humankind has always tried to find ways to store information. In today s modern age, people have become accustomed to technological terminology, such as CD-ROM, USB Key, and DVD. Floppy disks and cassette tapes have been forgetting except for the most nostalgic. Subsequent generations have simply forgotten about the technology that helped evolve the efficient computer storage systems we all use everyday. As time humanity continues to push the envelope of innovation to create new possibilities. 1920s 1928 Magnetic Tape Fritz Pfleumer, a German engineer, patented magnetic tape in 1928. He based his invention off Vlademar Poulsen's magnetic wire. 1930s 1932 Magnetic Drum G. Taushek, an Austrian innovator, invented the magnetic drum in 1932. He based his invention off a discovery credited to Fritz Pfleumer. 1940s 1946 Williams Tube Professor Fredrick C. Williams and his colleagues developed the first random access computer memory at the University of Manchester located in the United Kingdom. He used a series of electrostatic cathode- ray tubes for digital storage. A storage of 1024 bits of information was successfully implemented in 1948. Selectron Tube In 1948, The Radio Corporation of America (RCA) developed the Selectron tube, an early form of computer memory, which resembled the Williams-Kilburn design. 1949 Delay Line Memory The delay line memory consists of imparting an information pattern into a delay path. -
A Comparative Study of Evolution of Storage Media and Cloud
International Journal on Recent and Innovation Trends in Computing and Communication ISSN: 2321-8169 Volume: 1 Issue: 2 089 - 091 ____________________________________________________________________________________________________________________ A Comparative Study of Evolution of Storage Media and Cloud Halkar Rachappa Asst. Prof. & Head Dept. of Computer Science SKNG Govt. First Grade College GANGAVATHI (Karnataka) e-mail: [email protected] Abstract: At present, a number of devices are available in market to handle huge amount of data. The speed of growth in the field of data storage is unbelievable. Researchers are trying day by day to find ways to store information. Most commo0n storage media used are CD-ROM, USB Key, and DVD etc. Floppy disks and cassette tapes have been forgetting except for the most nostalgic. The next generations have simply forgotten about the technology that helped evolve the efficient computer storage systems we all use every day. As time humanity continues to push the envelope of innovation to create new possibilities. In today concern security and centralization of data is most important issue. Cloud computing is the most popular way for centralized data access. In this research paper previously used storage media and cloud storage is studied along with their benefits and future scope. Keywords: Cloud Computing Survey, Data Storage, Public Cloud, SaaS __________________________________________________*****_________________________________________________ I. INTRODUCTION 1946 Williams TubeProfessor Fredrick C. Williams and his colleagues developed the first In past 80s and 90s the use of data was comparatively very random access computer memory at the less. Floppies or CDs are used to store and carry small University of Manchester located in the United amount of data.