Lecture #11: Communication Methods Questions?
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Nubus Physical Designs
Macintosh Technical Notes ® Developer Technical Support #234: NuBus Physical Designs—Beware Revised by: Rich Collyer December 1989 Written by: Rich Collyer June 1989 This Technical Note discusses the possible problems you might run into while designing a NuBus™ card. It covers some of the specifications which, if not followed, will have problems with current Macintosh machines, and possibly future machines. Changes since June 1989: Added warnings about the no component area and full-size NuBus cards. If you are making a NuBus card for the Macintosh II family of computers, then you have to be very careful to follow the physical specifications which are listed in the NuBus specifications (IEEE P1196). There are two areas where some developers have run into problems. The first problem has to do with not positioning the external connector properly. The result is that some products have problems with the external hole on the back of the Macintosh IIcx. The second problem has to do with developers who run ribbon cables over the top of their boards to connect two boards. If a slot is not cut into the top of the board to allow the ribbon cable to sit below the top of the card, then the boards will have problems in our machines. External Connector The NuBus specification allows for an external connector plastics opening of only 74.55 mm x 11.90 mm. The Macintosh II and IIx allowed a significantly larger hole than the specification (80.00 mm x 17.00 mm) and some developers incorrectly assumed that Apple would continue to allow for this larger size. -

Dell EMC Openmanage CIM Reference Guide Version 9.1 Notes, Cautions, and Warnings
Dell EMC OpenManage CIM Reference Guide Version 9.1 Notes, cautions, and warnings NOTE: A NOTE indicates important information that helps you make better use of your product. CAUTION: A CAUTION indicates either potential damage to hardware or loss of data and tells you how to avoid the problem. WARNING: A WARNING indicates a potential for property damage, personal injury, or death. Copyright © 2017 Dell Inc. or its subsidiaries. All rights reserved. Dell, EMC, and other trademarks are trademarks of Dell Inc. or its subsidiaries. Other trademarks may be trademarks of their respective owners. 2017 - 12 Rev. A00 Contents 1 Introduction....................................................................................................................................................6 Server Administrator..........................................................................................................................................................6 Documenting CIM Classes and Their Properties........................................................................................................... 6 Base Classes................................................................................................................................................................. 7 Parent Classes.............................................................................................................................................................. 7 Classes That Describe Relationships........................................................................................................................ -

Designing PCI Cards and Drivers for Power Macintosh Computers
Designing PCI Cards and Drivers for Power Macintosh Computers Revised Edition Revised 3/26/99 Technical Publications © Apple Computer, Inc. 1999 Apple Computer, Inc. Adobe, Acrobat, and PostScript are Even though Apple has reviewed this © 1995, 1996 , 1999 Apple Computer, trademarks of Adobe Systems manual, APPLE MAKES NO Inc. All rights reserved. Incorporated or its subsidiaries and WARRANTY OR REPRESENTATION, EITHER EXPRESS OR IMPLIED, WITH No part of this publication may be may be registered in certain RESPECT TO THIS MANUAL, ITS reproduced, stored in a retrieval jurisdictions. QUALITY, ACCURACY, system, or transmitted, in any form America Online is a service mark of MERCHANTABILITY, OR FITNESS or by any means, mechanical, Quantum Computer Services, Inc. FOR A PARTICULAR PURPOSE. AS A electronic, photocopying, recording, Code Warrior is a trademark of RESULT, THIS MANUAL IS SOLD “AS or otherwise, without prior written Metrowerks. IS,” AND YOU, THE PURCHASER, ARE permission of Apple Computer, Inc., CompuServe is a registered ASSUMING THE ENTIRE RISK AS TO except to make a backup copy of any trademark of CompuServe, Inc. ITS QUALITY AND ACCURACY. documentation provided on Ethernet is a registered trademark of CD-ROM. IN NO EVENT WILL APPLE BE LIABLE Xerox Corporation. The Apple logo is a trademark of FOR DIRECT, INDIRECT, SPECIAL, FrameMaker is a registered Apple Computer, Inc. INCIDENTAL, OR CONSEQUENTIAL trademark of Frame Technology Use of the “keyboard” Apple logo DAMAGES RESULTING FROM ANY Corporation. (Option-Shift-K) for commercial DEFECT OR INACCURACY IN THIS purposes without the prior written Helvetica and Palatino are registered MANUAL, even if advised of the consent of Apple may constitute trademarks of Linotype-Hell AG possibility of such damages. -

Power Macintosh 9500 Series
K Service Source Power Macintosh 9500 Series Power Macintosh 9500/120, 9500/132, 9500/150, 9500/180MP, and 9500/200 K Service Source Basics Power Macintosh 9500 Series Basics Overview - 1 Overview The Power Macintosh 9500 Series computers are based on the PowerPC 604 microprocessor and support the industry-standard PCI (Peripheral Component Interconnect) bus specification. These computers are the most flexible, expandable, and highest-performance systems from Apple to date. The microprocessor for the Power Macintosh 9500 Series computers is on separate plug-in card, which allows for easy upgrades. The Power Macintosh 9500 family includes five versions: the 9500/120, the 9500/132, the 9500/150, the 9500/180MP (multi-processor), and the 9500/200. Basics Overview - 2 Features of the Power Macintosh 9500 Series include • 120, 132, 150, 180 (multi-processor) or 200 MHz PowerPC 604 microprocessor card with built-in FPU • Six PCI expansion slots • 10 MB per second internal SCSI channel, 5 MB per second external SCSI channel • 512K Level 2 cache • DRAM expansion up to 1536 MB using 168-pin, 70 ns, 64-bit DIMMs • A PCI Apple Accelerated Graphics card included with some configurations (the Power Macintosh 9500 Series does not include on-board video support) • Built-in AAUI and 10BASE-T Ethernet • AppleCD™ 600i 4x or1200i 8x CD-ROM drive • CD-quality stereo sound in/out • Mac™ OS system software 7.5.2, 7.5.3, or 7.5.3 Revision 2 Basics Configurations - 3 Configurations The Power Macintosh 9500/120 comes standard with • 120 MHz PowerPC 604 processor -

PCI Local Bus Specification Revision 3.0 June 2002Junedecember 5February 3, 20043 28, 2002
PCI Local Bus Specification Revision 3.0 June 2002JuneDecember 5February 3, 20043 28, 2002 PCI LOCAL BUS SPECIFICATION, REV. 3.0 PCI SPECIFICATIONS REVISION REVISION HISTORY DATE 1.0 Original issue. 6/22/92 2.0 Incorporated connector and add-in card specification. 4/30/93 2.1 Incorporated clarifications and added 66 MHz chapter. 6/1/95 2.2 Incorporated ECNs and improved readability. 12/18/98 2.3 Incorporated ECNs, errata, and deleted 5 volt only keyed 3/29/02 add-in cards. 3.0 Incorporated ECNs, errata, and Rremoved support for the 212/305/ 5.0 volt keyed system board connector. Moved the 043 Expansion ROM description to the PCI Firmware Specification. The PCI Special Interest Group-SIG disclaims all warranties and liability for the use of this document and the information contained herein and assumes no responsibility for any errors that may appear in this document, nor does the PCI-SIG Special Interest Group make a commitment to update the information contained herein. Contact the PCI-SIG Special Interest Group office to obtain the latest revision of the specification. Questions regarding the PCI specification or membership in the PCI-SIG Special Interest Grou may be forwarded to: PCI-SIG Special Interest Group 5440 SW Westgate Drive Suite 217 Portland, Oregon 97221 Phone: 800-433-5177 (Inside the U.S.) 503-291-2569 (Outside the U.S.) Fax: 503-297-1090 e-mail [email protected] http://www.pcisig.com DISCLAIMER This PCI Local Bus Specification is provided "“as is" ” with no warranties whatsoever, including any warranty of merchantability, noninfringement, fitness for any particular purpose, or any warranty otherwise arising out of any proposal, specification, or sample. -

LL5200 ISA to Vmebus LINK
LL5200 ISA to VMEbus LINK FEATURES · High speed bus to bus link · Fiber Optic or Coax Cable · Up to 2Km system separation · Programmable address windows · Symmetrical Master/Slave operation · Both busses run independently · Remote Reset Function · 16/24/32 Bit VME, 24 Bit ISA addresses · Programmable byte swapping · VMEbus system controller functions SUMMARY APPLICATIONS LL5200 is an ISA to VMEbus link that allows the physical LL5200 and other Lextel Bus Links are being used to solve address space of an ISA bus based computer (PC/AT) to be these kinds of problems: mapped into that of the VMEbus, and vice-versa. Bus masters on either bus can have direct, random access to the other bus. BUS EXTENSION: When equipment needs to be Remote memory and IO devices appear to be within the local connected up to 2Km apart without machine, even though they may be physically located up to loss of throughput. 2Km away. BUS CONVERSION: When one bus architecture needs to Up to 4096 VMEbus address segments, or 'windows', can be be used with another. mapped into the ISA Bus address space. A single window of ISA address space can be mapped into the VMEbus. The size BUS EXPANSION: When more bus slots are needed and base address of the ISA window is programmable. In addition, the addresses can be translated as they pass across NOISE IMMUNITY: Fiber optics are immune to EMI, RFI the link. and crosstalk. Unlike a simple bus repeater, the LL5200 does not tie up both HIGH SPEED DATA: When a standard LAN isn't fast systems when one is in use. -

Powerpc and Power Macintosh L Technical Information
L Technical PowerPC and Information Power Macintosh Recently, both Apple Computer and IBM have introduced products based on the PowerPC™ microprocessor. The PowerPC microprocessor is a result of collaboration between three industry leaders: Apple, IBM, and Motorola. This cooperative project was announced in 1991. The project’s goal was to advance the evolution of the personal computer in five major areas: • PowerPC – Apple, IBM, and Motorola agreed to develop a family of RISC microprocessors. • Interoperability – IBM and Apple agreed to work together to ensure that Macintosh® computers work smoothly with large, networked IBM enterprise systems. This involves products in networking and communication. • PowerOpen® – IBM and Apple agreed to co-develop a new version of the UNIX® operating system that takes advantage of the strengths of the PowerPC microprocessor. • Kaleida – A new company called Kaleida was created to work on new standards for multimedia products. • Taligent – A new company called Taligent was created to develop an object-oriented operating system. While there have been advances in all of these areas, the announcement of the Power Macintosh has focused industry attention on the PowerPC chip. (Note: Microprocessors are often referred to as ‘chips’ or ‘computer chips’.) The PowerPC microprocessor The term PowerPC describes a family of microprocessors that may be used in a variety of computers. Apple Computer has introduced a series of computers based on this microprocessor which they will call Power Macintoshes™. IBM computers that contain the PowerPC microprocessor will be part of the RS6000 series. The RS6000 series is a high-end UNIX product. The Power Macintosh, on the other hand, is intended as a broad- based consumer product. -

(2) Patent Application Publication (10) Pub. No.: US 2015/0081508 A1 Schwall Et Al
US 2015008 1508A1 (19) United States (2) Patent Application Publication (10) Pub. No.: US 2015/0081508 A1 Schwall et al. (43) Pub. Date: Mar. 19, 2015 (54) TECHNIQUES FOR FACILITATING Publication Classification ELECTRONIC TRADING (51) Int. Cl. (71) Applicant: IEX Group, Inc., New York, NY (US) G06Q 40/04 (2012.01) (52) U.S. CI. (72) Inventors: John Schwall, Staten Island, NY (US); CPC ..…. G06Q 40/04 (2013.01) Matthew Norbert Trudeau, Brooklyn, USPC ..…. 705/37 NY (US) (73) Assignee: IEX Group, Inc. (57) ABSTRACT (21) Appl. No.: 14/487,320 A number of techniques for improving electronic trading are disclosed. According to some embodiments, a user portal (22) Filed: Sep. 16, 2014 may be provided in an electronic trading system for educa tional and informational purposes and also to assist investors Related U.S. Application Data in configuring their routing or trading preferences for elec (60) Provisional application No. 61/879,104, filed on Sep. tronic trading orders to be submitted to the electronic trading 17, 2013. system. TLL Example: Reallocation via TLL Portal Patent Application Publication Mar. 19, 2015 Sheet 1 of 31 US 2015/0081508 A1 Patent Application Publication Mar. 19, 2015 Sheet 2 of 31 US 2015/0081508 A1 Patent Application Publication Mar. 19, 2015 Sheet 3 of 31 US 2015/0081508 A1 Patent Application Publication Mar. 19, 2015 Sheet 4 of 31 US 2015/0081508 A1 Patent Application Publication Mar. 19, 2015 Sheet 5 of 31 US 2015/0081508 A1 Patent Application Publication Mar. 19, 2015 Sheet 6 of 31 US 2015/0081508 A1 Patent Application Publication Mar. -

PCI Code and ID Assignment Specification Revision 1.11 24 Jan 2019
PCI Code and ID Assignment Specification Revision 1.11 24 Jan 2019 PCI CODE AND ID ASSIGNMENT SPECIFICATION, REV. 1.11 Revision Revision History Date 1.0 Initial release. 9/9/2010 1.1 Incorporated approved ECNs. 3/15/2012 1.2 Incorporated ECN for Accelerator Class code, added PI for xHCI. 3/15/2012 Updated section 1.2, Base Class 01h, Sub-class 00h by adding 1.3 9/4/2012 Programming Interfaces 11h, 12h, 13h, and 21h. Added Notes 3, 4, and 5. Updated Section 1.2, Base Class 01h, to add Sub-class 09h. Updated Section 1.9, Base Class 08h to add Root Complex Event Collector, Sub-class 07h 1.4 Updated Section 1 and added Section 1.20, to define Base Class 13h. 8/29/2013 Updated Chapter 3 to define Extended Capability IDs 001Dh through 0022h. Reformatted Notes in Sections 1.2 and 1.7 through 1.10. Updated references to NVM Express in Section 1.9, Base Class 08h Updated Section 1.2, to clarify SOP entries in Base Class 01h, add proper reference to NVMHCI, update UFS entries, and address other minor 1.5 3/6/2014 editorial issues. Updated Section 3, Extended Capability ID descriptions 19h, 1Ch, 1Fh. Updated Section 1.3, Class 02h, to add Sub-Class 08h. 1.6 Updated Section 1.14, Base Class 0Dh, to add Sub-Classes 40h and 41h. 12/9/2014 Updated Section 2 to add Capability ID 14h. Added Designated Vendor-Specific Extended Capability ID. 1.7 Updated/Modified Section 1.5, Base Class 04h, for Multimedia devices to 8/13/2015 accurately reflect use of this class for High Definition Audio (HD-A). -
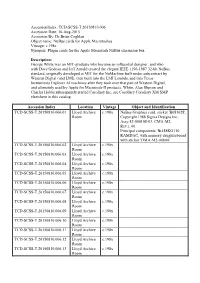
TCD-SCSS-T.20150810.006 Accession Date
AccessionIndex: TCD-SCSS-T.20150810.006 Accession Date: 10-Aug-2015 Accession By: Dr.Brian Coghlan Object name: NuBus cards for Apple Macintoshes Vintage: c.198x Synopsis: Plugin cards for the Apple Macintosh NuBus expansion bus. Description: George White was an MIT-graduate who became an influential designer, and who with Dave Godeau and Jeff Arnold created the elegant IEEE 1196-1987 32-bit NuBus standard, originally developed at MIT for the NuMachine built under subcontract by Western Digital (and LMI), then built into the LMI Lambda, and into Texas Instruments Explorer AI machines after they took over that part of Western Digital, and ultimately used by Apple for Macintosh-II products. White, Alan Slipson and Charles Hobbs subsequently started Corollary Inc, see Corollary Corollary XM SMP elsewhere in this catalog. Accession Index Location Vintage Object and Identification TCD-SCSS-T.20150810.006.01 Lloyd Archive c.198x NuBus Graphics card, sticker 'B081628', Room Copyright 1988 Sigma Designs Inc., Assy.52-000108-03, CMA-M2, Rev.1.40. Principal components: Bt458KG110 RAMDAC, with memory daughterboard with sticker 'DMA-M2-00800'. TCD-SCSS-T.20150810.006.02 Lloyd Archive c.198x Room TCD-SCSS-T.20150810.006.03 Lloyd Archive c.198x Room TCD-SCSS-T.20150810.006.04 Lloyd Archive c.198x Room TCD-SCSS-T.20150810.006.05 Lloyd Archive c.198x Room TCD-SCSS-T.20150810.006.06 Lloyd Archive c.198x Room TCD-SCSS-T.20150810.006.07 Lloyd Archive c.198x Room TCD-SCSS-T.20150810.006.08 Lloyd Archive c.198x Room TCD-SCSS-T.20150810.006.09 Lloyd Archive -

Standard I/O Interfaces
STANDARD I/O INTERFACES The processor bus is the bus defied by the signals on the processor chip itself. Devices that require a very high-speed connection to the processor, such as the main memory, may be connected directly to this bus. For electrical reasons, only a few devices can be connected in this manner. The motherboard usually provides another bus that can support more devices. The two buses are interconnected by a circuit, which we will call a bridge, that translates the signals and protocols of one bus into those of the other. Devices connected to the expansion bus appear to the processor as if they were connected directly to the processor’s own bus. The only difference is that the bridge circuit introduces a small delay in data transfers between the processor and those devices. It is not possible to define a uniform standard for the processor bus. The structure of this bus is closely tied to the architecture of the processor. It is also dependent on the electrical characteristics of the processor chip, such as its clock speed. The expansion bus is not subject to these limitations, and therefore it can use a standardized signaling scheme. A number of standards have been developed. Some have evolved by default, when a particular design became commercially successful. For example, IBM developed a bus they called ISA (Industry Standard Architecture) for their personal computer known at the time as PC AT. Some standards have been developed through industrial cooperative efforts, even among competing companies driven by their common self-interest in having compatible products. -

Ethernet Network Interface Adaptor for the Apple Macintosh II Nubus
Ethernet Network Interface Adapter for the Apple Macintosh II NuBus AN-686 National Semiconductor Ethernet Network Interface Application Note 686 Adapter for the Apple Andrew C. Pagnon Macintosh II NuBus June 1990 INTRODUCTION dress bus interface latches store the NuBus address from The gradual move in recent years towards distributed pro- the multiplexed address/data bus, and the data bus inter- cessing units with a need for these to communicate and the face consists of buffers and latches to assemble the 16-bit increasing demand for peripheral usage optimization has re- RAM buffer data into a 32-bit word for the NuBus. sulted in the fast growth of Local Area Networks. In an at- Transmission/Reception tempt to standardize communications between networks For Ethernet transmissions the host CPU writes data into the International Standards Organization (ISO) has pro- the transmit area of the adapter card buffer memory over posed a seven layer reference model called the Open Sys- the NuBus interface. The host CPU then sets up the NIC to tem Interconnect (OSI) which provides an independent transmit the data by writing to its internal registers. The NIC framework for all the emerging network standards. The responds by fetching the data into its internal FIFO using its IEEE has defined a number of these standards (802.3 to local DMA channel, from where it is sent to the SNI-CTI and 802.6) covering the two lower layer functions, physical and onto the Ethernet cable. Once the data has been transmit- data link layers. ted the NIC issues an interrupt back to the host CPU and National Semiconductor provides a three chip set which sets a status bit in its internal register.