Coding and Noncoding Expression Patterns Associated with Rare Obesity-Related Disorders: Prader–Willi and Alström Syndromes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Haplotypes of CYP1B1 and CCDC57 Genes in an Afro-Caribbean Female
Molecular Biology Reports (2019) 46:3299–3306 https://doi.org/10.1007/s11033-019-04790-y ORIGINAL ARTICLE Haplotypes of CYP1B1 and CCDC57 genes in an Afro‑Caribbean female population with uterine leiomyoma Angela T. Alleyne1 · Virgil S. Bideau1 Received: 13 December 2018 / Accepted: 28 March 2019 / Published online: 13 April 2019 © Springer Nature B.V. 2019 Abstract Uterine leiomyomas (UL) are prevalent benign tumors, especially among women of African ancestry. The disease also has genetic liability and is infuenced by risk factors such as hormones and obesity. This study investigates the haplotypes of the Cytochrome P450 1B1 gene (CYP1B1) related to hormones and coiled-coil domain containing 57 gene (CCDC57) related to obesity in Afro-Caribbean females. Each haplotype was constructed from unphased sequence data using PHASE v.2.1 software and Haploview v.4.2 was used for linkage disequilibrium (LD) studies. There were contrasting LD observed among the single nucleotide polymorphisms of CYP1B1 and CCDC5. Accordingly, the GTA haplotype of CYP1B1 was signifcantly associated with UL risk (P = 0.02) while there was no association between CCDC57 haplotypes and UL (P = 0.2) for the ATG haplotype. As such, our fndings suggest that the Asp449Asp polymorphism and GTA haplotype of CYP1B1 may contribute to UL susceptibility in women of Afro-Caribbean ancestry in this population. Keywords SNP · Fibroids · Haplotyping · Estrogen · Linkage disequilibrium Introduction consistently having a higher risk of UL development than White women [4]. However cumulatively Black women have Globally, 20–25% of women are clinically diagnosed with an earlier onset for diagnosis than White women [2, 10]. -

Histone Isoform H2A1H Promotes Attainment of Distinct Physiological
Bhattacharya et al. Epigenetics & Chromatin (2017) 10:48 DOI 10.1186/s13072-017-0155-z Epigenetics & Chromatin RESEARCH Open Access Histone isoform H2A1H promotes attainment of distinct physiological states by altering chromatin dynamics Saikat Bhattacharya1,4,6, Divya Reddy1,4, Vinod Jani5†, Nikhil Gadewal3†, Sanket Shah1,4, Raja Reddy2,4, Kakoli Bose2,4, Uddhavesh Sonavane5, Rajendra Joshi5 and Sanjay Gupta1,4* Abstract Background: The distinct functional efects of the replication-dependent histone H2A isoforms have been dem- onstrated; however, the mechanistic basis of the non-redundancy remains unclear. Here, we have investigated the specifc functional contribution of the histone H2A isoform H2A1H, which difers from another isoform H2A2A3 in the identity of only three amino acids. Results: H2A1H exhibits varied expression levels in diferent normal tissues and human cancer cell lines (H2A1C in humans). It also promotes cell proliferation in a context-dependent manner when exogenously overexpressed. To uncover the molecular basis of the non-redundancy, equilibrium unfolding of recombinant H2A1H-H2B dimer was performed. We found that the M51L alteration at the H2A–H2B dimer interface decreases the temperature of melting of H2A1H-H2B by ~ 3 °C as compared to the H2A2A3-H2B dimer. This diference in the dimer stability is also refected in the chromatin dynamics as H2A1H-containing nucleosomes are more stable owing to M51L and K99R substitu- tions. Molecular dynamic simulations suggest that these substitutions increase the number of hydrogen bonds and hydrophobic interactions of H2A1H, enabling it to form more stable nucleosomes. Conclusion: We show that the M51L and K99R substitutions, besides altering the stability of histone–histone and histone–DNA complexes, have the most prominent efect on cell proliferation, suggesting that the nucleosome sta- bility is intimately linked with the physiological efects observed. -

Analysis of Trans Esnps Infers Regulatory Network Architecture
Analysis of trans eSNPs infers regulatory network architecture Anat Kreimer Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate School of Arts and Sciences COLUMBIA UNIVERSITY 2014 © 2014 Anat Kreimer All rights reserved ABSTRACT Analysis of trans eSNPs infers regulatory network architecture Anat Kreimer eSNPs are genetic variants associated with transcript expression levels. The characteristics of such variants highlight their importance and present a unique opportunity for studying gene regulation. eSNPs affect most genes and their cell type specificity can shed light on different processes that are activated in each cell. They can identify functional variants by connecting SNPs that are implicated in disease to a molecular mechanism. Examining eSNPs that are associated with distal genes can provide insights regarding the inference of regulatory networks but also presents challenges due to the high statistical burden of multiple testing. Such association studies allow: simultaneous investigation of many gene expression phenotypes without assuming any prior knowledge and identification of unknown regulators of gene expression while uncovering directionality. This thesis will focus on such distal eSNPs to map regulatory interactions between different loci and expose the architecture of the regulatory network defined by such interactions. We develop novel computational approaches and apply them to genetics-genomics data in human. We go beyond pairwise interactions to define network motifs, including regulatory modules and bi-fan structures, showing them to be prevalent in real data and exposing distinct attributes of such arrangements. We project eSNP associations onto a protein-protein interaction network to expose topological properties of eSNPs and their targets and highlight different modes of distal regulation. -

Gene Family: Gene Duplication and Retrotransposon Insertion
21 Bucentaur (Bcnt)1 Gene Family: Gene Duplication and Retrotransposon Insertion Shintaro Iwashita and Naoki Osada Iwaki Meisei University / National Institute of Genetics Japan 1. Introduction Members of multiple gene families in higher organisms allow for more refined cellular signaling networks and structural organization toward more stable physiological homeostasis. Gene duplication is one the most powerful ways of providing an opportunity to create a novel gene(s) because a novel function might be acquired without the loss of the original gene function (Ohno, 1970). Gene duplication can result from unequal crossing over by recombination, retroposition of cDNA, or whole-genome duplication. Furthermore, a replication-based mechanism of change in gene copy number has been proposed recently (Hastings et al., 2009). Gene duplication generated by retroposition is frequently accompanied by deleterious effects because the insertion of cDNA into the genome is nearly random or unlinks the original gene location resulting in an alteration of the original vital functions of the target genes. Thus retroelements such as transposable elements and endogenous retroviruses have been thought of as “selfish”. On the other hand, gene duplication caused by unequal crossing over generally results in tandem alignment, which less frequently disrupts the functions of other genes. Recent genome-wide studies have demonstrated that retroelements can definitely contribute to the creation of individual novel genes and the modulation of gene expression, which allows for the dynamic diversity of biological systems, such as placental evolution (Rawn & Cross, 2008). It is now recognized that tandem duplication and retroposition are among the key factors that initiate the creation of novel gene family members (Brosius, 2005; Sorek, 2007; Kaessmann, 2010). -

A Genetic Screen Identifies the Triple T Complex Required for DNA Damage Signaling and ATM and ATR Stability
Downloaded from genesdev.cshlp.org on September 27, 2021 - Published by Cold Spring Harbor Laboratory Press A genetic screen identifies the Triple T complex required for DNA damage signaling and ATM and ATR stability Kristen E. Hurov, Cecilia Cotta-Ramusino, and Stephen J. Elledge1 Howard Hughes Medical Institute and Department of Genetics, Harvard Medical School, Division of Genetics, Brigham and Women’s Hospital, Boston, Massachusetts 02115, USA In response to DNA damage, cells activate a complex signal transduction network called the DNA damage response (DDR). To enhance our current understanding of the DDR network, we performed a genome-wide RNAi screen to identify genes required for resistance to ionizing radiation (IR). Along with a number of known DDR genes, we discovered a large set of novel genes whose depletion leads to cellular sensitivity to IR. Here we describe TTI1 (Tel two-interacting protein 1) and TTI2 as highly conserved regulators of the DDR in mammals. TTI1 and TTI2 protect cells from spontaneous DNA damage, and are required for the establishment of the intra-S and G2/M checkpoints. TTI1 and TTI2 exist in multiple complexes, including a 2-MDa complex with TEL2 (telomere maintenance 2), called the Triple T complex, and phosphoinositide-3-kinase-related protein kinases (PIKKs) such as ataxia telangiectasia-mutated (ATM). The components of the TTT complex are mutually dependent on each other, and act as critical regulators of PIKK abundance and checkpoint signaling. [Keywords: TTI1; TEL2; TTI2; PIKK; TTT complex; IR sensitivity] Supplemental material is available at http://www.genesdev.org. Received April 5, 2010; revised version accepted July 22, 2010. -

Bayesian Hierarchical Modeling of High-Throughput Genomic Data with Applications to Cancer Bioinformatics and Stem Cell Differentiation
BAYESIAN HIERARCHICAL MODELING OF HIGH-THROUGHPUT GENOMIC DATA WITH APPLICATIONS TO CANCER BIOINFORMATICS AND STEM CELL DIFFERENTIATION by Keegan D. Korthauer A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Statistics) at the UNIVERSITY OF WISCONSIN–MADISON 2015 Date of final oral examination: 05/04/15 The dissertation is approved by the following members of the Final Oral Committee: Christina Kendziorski, Professor, Biostatistics and Medical Informatics Michael A. Newton, Professor, Statistics Sunduz Kele¸s,Professor, Biostatistics and Medical Informatics Sijian Wang, Associate Professor, Biostatistics and Medical Informatics Michael N. Gould, Professor, Oncology © Copyright by Keegan D. Korthauer 2015 All Rights Reserved i in memory of my grandparents Ma and Pa FL Grandma and John ii ACKNOWLEDGMENTS First and foremost, I am deeply grateful to my thesis advisor Christina Kendziorski for her invaluable advice, enthusiastic support, and unending patience throughout my time at UW-Madison. She has provided sound wisdom on everything from methodological principles to the intricacies of academic research. I especially appreciate that she has always encouraged me to eke out my own path and I attribute a great deal of credit to her for the successes I have achieved thus far. I also owe special thanks to my committee member Professor Michael Newton, who guided me through one of my first collaborative research experiences and has continued to provide key advice on my thesis research. I am also indebted to the other members of my thesis committee, Professor Sunduz Kele¸s,Professor Sijian Wang, and Professor Michael Gould, whose valuable comments, questions, and suggestions have greatly improved this dissertation. -

00006396 201510000 00004
King’s Research Portal DOI: 10.1097/j.pain.0000000000000200 Document Version Publisher's PDF, also known as Version of record Link to publication record in King's Research Portal Citation for published version (APA): Livshits, G., Macgregor, A. J., Gieger, C., Malkin, I., Moayyeri, A., Grallert, H., Emeny, R. T., Spector, T., Kastenmuller, G., & Williams, F. M. K. (2015). An omics investigation into chronic widespread musculoskeletal pain reveals epiandrosterone sulfate as a potential biomarker. Pain, 156(10), 1845-1851. https://doi.org/10.1097/j.pain.0000000000000200 Citing this paper Please note that where the full-text provided on King's Research Portal is the Author Accepted Manuscript or Post-Print version this may differ from the final Published version. If citing, it is advised that you check and use the publisher's definitive version for pagination, volume/issue, and date of publication details. And where the final published version is provided on the Research Portal, if citing you are again advised to check the publisher's website for any subsequent corrections. General rights Copyright and moral rights for the publications made accessible in the Research Portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognize and abide by the legal requirements associated with these rights. •Users may download and print one copy of any publication from the Research Portal for the purpose of private study or research. •You may not further distribute the material or use it for any profit-making activity or commercial gain •You may freely distribute the URL identifying the publication in the Research Portal Take down policy If you believe that this document breaches copyright please contact [email protected] providing details, and we will remove access to the work immediately and investigate your claim. -

CCDC57 CRISPR/Cas9 KO Plasmid (M): Sc-427913
SANTA CRUZ BIOTECHNOLOGY, INC. CCDC57 CRISPR/Cas9 KO Plasmid (m): sc-427913 BACKGROUND APPLICATIONS The Clustered Regularly Interspaced Short Palindromic Repeats (CRISPR) and CCDC57 CRISPR/Cas9 KO Plasmid (m) is recommended for the disruption of CRISPR-associated protein (Cas9) system is an adaptive immune response gene expression in mouse cells. defense mechanism used by archea and bacteria for the degradation of foreign genetic material (4,6). This mechanism can be repurposed for other 20 nt non-coding RNA sequence: guides Cas9 functions, including genomic engineering for mammalian systems, such as to a specific target location in the genomic DNA gene knockout (KO) (1,2,3,5). CRISPR/Cas9 KO Plasmid products enable the U6 promoter: drives gRNA scaffold: helps Cas9 identification and cleavage of specific genes by utilizing guide RNA (gRNA) expression of gRNA bind to target DNA sequences derived from the Genome-scale CRISPR Knock-Out (GeCKO) v2 library developed in the Zhang Laboratory at the Broad Institute (3,5). Termination signal Green Fluorescent Protein: to visually REFERENCES verify transfection CRISPR/Cas9 Knockout Plasmid CBh (chicken β-Actin 1. Cong, L., et al. 2013. Multiplex genome engineering using CRISPR/Cas hybrid) promoter: drives systems. Science 339: 819-823. 2A peptide: expression of Cas9 allows production of both Cas9 and GFP from the 2. Mali, P., et al. 2013. RNA-guided human genome engineering via Cas9. same CBh promoter Science 339: 823-826. Nuclear localization signal 3. Ran, F.A., et al. 2013. Genome engineering using the CRISPR-Cas9 system. Nuclear localization signal SpCas9 ribonuclease Nat. Protoc. 8: 2281-2308. -

Metallothionein Monoclonal Antibody, Clone N11-G
Metallothionein monoclonal antibody, clone N11-G Catalog # : MAB9787 規格 : [ 50 uL ] List All Specification Application Image Product Rabbit monoclonal antibody raised against synthetic peptide of MT1A, Western Blot (Recombinant protein) Description: MT1B, MT1E, MT1F, MT1G, MT1H, MT1IP, MT1L, MT1M, MT2A. Immunogen: A synthetic peptide corresponding to N-terminus of human MT1A, MT1B, MT1E, MT1F, MT1G, MT1H, MT1IP, MT1L, MT1M, MT2A. Host: Rabbit enlarge Reactivity: Human, Mouse Immunoprecipitation Form: Liquid Enzyme-linked Immunoabsorbent Assay Recommend Western Blot (1:1000) Usage: ELISA (1:5000-1:10000) The optimal working dilution should be determined by the end user. Storage Buffer: In 20 mM Tris-HCl, pH 8.0 (10 mg/mL BSA, 0.05% sodium azide) Storage Store at -20°C. Instruction: Note: This product contains sodium azide: a POISONOUS AND HAZARDOUS SUBSTANCE which should be handled by trained staff only. Datasheet: Download Applications Western Blot (Recombinant protein) Western blot analysis of recombinant Metallothionein protein with Metallothionein monoclonal antibody, clone N11-G (Cat # MAB9787). Lane 1: 1 ug. Lane 2: 3 ug. Lane 3: 5 ug. Immunoprecipitation Enzyme-linked Immunoabsorbent Assay ASSP5 MT1A MT1B MT1E MT1F MT1G MT1H MT1M MT1L MT1IP Page 1 of 5 2021/6/2 Gene Information Entrez GeneID: 4489 Protein P04731 (Gene ID : 4489);P07438 (Gene ID : 4490);P04732 (Gene ID : Accession#: 4493);P04733 (Gene ID : 4494);P13640 (Gene ID : 4495);P80294 (Gene ID : 4496);P80295 (Gene ID : 4496);Q8N339 (Gene ID : 4499);Q86YX0 (Gene ID : 4490);Q86YX5 -
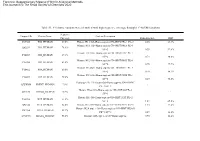
Table S1. 49 Histone Variants Were Identified with High Sequence Coverage Through LC-MS/MS Analysis Electronic Supplementary
Electronic Supplementary Material (ESI) for Analytical Methods. This journal is © The Royal Society of Chemistry 2020 Table S1. 49 histone variants were identified with high sequence coverage through LC-MS/MS analysis Sequence Uniprot IDs Protein Name Protein Description Coverage Ratio E2+/E2- RSD P07305 H10_HUMAN 67.5% Histone H1.0 OS=Homo sapiens GN=H1F0 PE=1 SV=3 4.85 23.3% Histone H1.1 OS=Homo sapiens GN=HIST1H1A PE=1 Q02539 H11_HUMAN 74.4% SV=3 0.35 92.6% Histone H1.2 OS=Homo sapiens GN=HIST1H1C PE=1 P16403 H12_HUMAN 67.1% SV=2 0.73 80.6% Histone H1.3 OS=Homo sapiens GN=HIST1H1D PE=1 P16402 H13_HUMAN 63.8% SV=2 0.75 77.7% Histone H1.4 OS=Homo sapiens GN=HIST1H1E PE=1 P10412 H14_HUMAN 69.0% SV=2 0.70 80.3% Histone H1.5 OS=Homo sapiens GN=HIST1H1B PE=1 P16401 H15_HUMAN 79.6% SV=3 0.29 98.3% Testis-specific H1 histone OS=Homo sapiens GN=H1FNT Q75WM6 H1FNT_HUMAN 7.8% \ \ PE=2 SV=3 Histone H1oo OS=Homo sapiens GN=H1FOO PE=2 Q8IZA3 H1FOO_HUMAN 5.2% \ \ SV=1 Histone H1t OS=Homo sapiens GN=HIST1H1T PE=2 P22492 H1T_HUMAN 31.4% SV=4 1.42 65.0% Q92522 H1X_HUMAN 82.6% Histone H1x OS=Homo sapiens GN=H1FX PE=1 SV=1 1.15 33.2% Histone H2A type 1 OS=Homo sapiens GN=HIST1H2AG P0C0S8 H2A1_HUMAN 99.2% PE=1 SV=2 0.57 26.8% Q96QV6 H2A1A_HUMAN 58.0% Histone H2A type 1-A OS=Homo sapiens 0.90 11.2% GN=HIST1H2AA PE=1 SV=3 Histone H2A type 1-B/E OS=Homo sapiens P04908 H2A1B_HUMAN 99.2% GN=HIST1H2AB PE=1 SV=2 0.92 30.2% Histone H2A type 1-C OS=Homo sapiens Q93077 H2A1C_HUMAN 100.0% GN=HIST1H2AC PE=1 SV=3 0.76 27.6% Histone H2A type 1-D OS=Homo sapiens P20671 -

Environmental Influences on Endothelial Gene Expression
ENDOTHELIAL CELL GENE EXPRESSION John Matthew Jeff Herbert Supervisors: Prof. Roy Bicknell and Dr. Victoria Heath PhD thesis University of Birmingham August 2012 University of Birmingham Research Archive e-theses repository This unpublished thesis/dissertation is copyright of the author and/or third parties. The intellectual property rights of the author or third parties in respect of this work are as defined by The Copyright Designs and Patents Act 1988 or as modified by any successor legislation. Any use made of information contained in this thesis/dissertation must be in accordance with that legislation and must be properly acknowledged. Further distribution or reproduction in any format is prohibited without the permission of the copyright holder. ABSTRACT Tumour angiogenesis is a vital process in the pathology of tumour development and metastasis. Targeting markers of tumour endothelium provide a means of targeted destruction of a tumours oxygen and nutrient supply via destruction of tumour vasculature, which in turn ultimately leads to beneficial consequences to patients. Although current anti -angiogenic and vascular targeting strategies help patients, more potently in combination with chemo therapy, there is still a need for more tumour endothelial marker discoveries as current treatments have cardiovascular and other side effects. For the first time, the analyses of in-vivo biotinylation of an embryonic system is performed to obtain putative vascular targets. Also for the first time, deep sequencing is applied to freshly isolated tumour and normal endothelial cells from lung, colon and bladder tissues for the identification of pan-vascular-targets. Integration of the proteomic, deep sequencing, public cDNA libraries and microarrays, delivers 5,892 putative vascular targets to the science community. -

Repertoire of Morphable Proteins in an Organism
Repertoire of morphable proteins in an organism Keisuke Izumi, Eitaro Saho, Ayuka Kutomi, Fumiaki Tomoike and Tetsuji Okada Department of Life Science, Gakushuin University, Tokyo, Japan ABSTRACT All living organisms have evolved to contain a set of proteins with variable physical and chemical properties. Efforts in the field of structural biology have contributed to uncovering the shape and the variability of each component. However, quantification of the variability has been performed mostly by multiple pair-wise comparisons. A set of experimental coordinates for a given protein can be used to define the “morphness/unmorphness”. To understand the evolved repertoire in an organism, here we show the results of global analysis of more than a thousand Escherichia coli proteins, by the recently introduced method, distance scoring analysis (DSA). By collecting a new index “UnMorphness Factor” (UMF), proposed in this study and determined from DSA for each of the proteins, the lowest and the highest boundaries of the experimentally observable structural variation are comprehensibly defined. The distribution plot of UMFs obtained for E. coli represents the first view of a substantial fraction of non-redundant proteome set of an organism, demonstrating how rigid and flexible components are balanced. The present analysis extends to evaluate the growing data from single particle cryo-electron microscopy, providing valuable information on effective interpretation to structural changes of proteins and the supramolecular complexes. Subjects Biochemistry, Bioinformatics, Biophysics, Molecular Biology Keywords Protein, Structure, Crystallography, cryo-EM, E. coli, Human, PDB, Coordinates Submitted 21 October 2019 Accepted 20 January 2020 INTRODUCTION Published 11 February 2020 Self-replicating (living) species are defined by the presence of a genome that is used to Corresponding author Tetsuji Okada, produce a set of proteins and RNAs.