Automatic Recognition of Relative Clauses with Missing Relative Pronoun
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

“The Relative Pronoun” As Has Been the Case in the Last Several Chapters
CHAPTER 17 “Te Relatve Pronoun” As has been te case in te last several chaptrs, tis chaptr realy doesn’t confont te neophyt wit a lot of new grammatcal concepts; it builds on knowledge already mastred. Stl it’s going t take a litle patence, but we’l go slowly. Before we get t te relatve pronoun per se, we’re going t clean up a syntactcal point you’ve already been working wit, but may not have yet a firm conceptual understanding of. Let’s look at what we mean by a “clause”. THE CLAUSE You al remember te junior high school definiton of a sentnce: it’s a complet tought. And by tat we mean a tought which includes a noun, eiter expressed or implied, and a verb, eiter expressed or implied. Tat is, a complet tought must involve someting which is doing someting or which is being held up for descripton: “Te road is blocked”; “Te tee fel down”; and so on. Now, te human mind is a wonderfl ting. It reasons and perceives dozens of different kinds relatonships between events, tings, and ideas. It arranges events and facts logicaly and tmporaly, and in levels of priorit. Tat is t say, it takes two or more tings, tings which are separat ideas, separat visions, and weaves tem tgeter conceptualy and linguistcaly int what we “reasoning”. Te way tis reasoning is expressed in language is caled “syntax”, which litraly means “arranging tgeter”; puting tgeter events and tings and facts. For example, te two separat ideas or visions -- “te road is blocked” and “te tee fel down” -- might have a causal relatonship, which te mind instantly recognizes and expresses linguistcaly wit an appropriat conjuncton: “Te road is blocked because te tee fel down”. -

Participial Relative Clauses
UvA-DARE (Digital Academic Repository) Participial Relative Clauses Sleeman, P. DOI 10.1093/acrefore/9780199384655.013.185 Publication date 2017 Document Version Other version Published in Oxford Research Encyclopedia of Linguistics Link to publication Citation for published version (APA): Sleeman, P. (2017). Participial Relative Clauses. In M. Aronoff (Ed.), Oxford Research Encyclopedia of Linguistics [185] (Oxford Research Encyclopedias). Oxford University Press. https://doi.org/10.1093/acrefore/9780199384655.013.185 General rights It is not permitted to download or to forward/distribute the text or part of it without the consent of the author(s) and/or copyright holder(s), other than for strictly personal, individual use, unless the work is under an open content license (like Creative Commons). Disclaimer/Complaints regulations If you believe that digital publication of certain material infringes any of your rights or (privacy) interests, please let the Library know, stating your reasons. In case of a legitimate complaint, the Library will make the material inaccessible and/or remove it from the website. Please Ask the Library: https://uba.uva.nl/en/contact, or a letter to: Library of the University of Amsterdam, Secretariat, Singel 425, 1012 WP Amsterdam, The Netherlands. You will be contacted as soon as possible. UvA-DARE is a service provided by the library of the University of Amsterdam (https://dare.uva.nl) Download date:01 Oct 2021 Participial relative clauses Petra Sleeman Sleeman, P. Mar 2017, Oxford Research Encyclopedia of Linguistics. Aronoff, M. (ed.). Oxford: Oxford University Press, (Oxford Research Encyclopedias). Summary Relative clauses of which the predicate contains a present, past or passive participle can be used in a reduced form. -

The Use of Personal Pronouns in Political Speeches a Comparative Study of the Pronominal Choices of Two American Presidents
School of Language and Literature G3, Bachelors’ Course English Linguistics Course Code: 2EN10E Supervisor: Ibolya Maricic Credits: 15 Examiner: Charlotte Hommerberg Date: May 28, 2012 The Use of Personal Pronouns in Political Speeches A comparative study of the pronominal choices of two American presidents Jessica Håkansson ! !"#$%&'$( The study investigates the pronominal choices made by George W Bush and Barack Obama in their State of the Union speeches. The main focus of the study is on determining whom the two presidents refer to when they use the pronouns I, you, we and they, and to compare the differences in pronominal usage by the two presidents. The results suggest that the pronominal choices of the presidents do not differ significantly. The results also indicate that the pronoun I is used when the speaker wants to speak as an individual rather than as a representative of a group. You is used both as generic pronoun as well as a way for the President to speak to the Congress, without speaking on their behalf. The pronoun we is used to invoke a sense of collectivity and to share responsibility, in most cases it refers to the President and the Congress. They is used to separate self from other; whom the speaker refers to while using they varied greatly between the speakers. The study also showed that the pronominal choices and whom the pronouns refer to vary greatly depending on the context of the speech. Since a great deal of studies on pronominal choices in political interviews and debates already exist, this study can be regarded as significant because it deals with prepared speeches rather than interviews and debates. -

Unit 2: Talking About Our Relationship with Other People
Unit 2: Talking about our relationship with other people Lesson A – C • At the end of the topic, you will be able to talk about the different relationships that you maintain with other people, through the use of vocabulary, grammar, and exercises, according to the program. Unit objective Lesson A objective At the end of this lesson you will be able to: • Talk about your circle of friends using relative cluases. What relationship do you have with other people? Warm-up Which do you enjoy most? Where can you make friends? Vocabulary: People we know •Buddy / pal = Amigo •Co-worker = Compañero de trabajo •Boyfriend = Novio •Acquaintance = Conocido •Girlfriend = Novia •Classmate = Compañero de salon Grammar: Relative clauses Use Relative clauses: Refers to the combination of two sentences that share the same subject or object in a single statement. • To join two sentences you need to use relative pronoun. This pronoun functions as the subject or object of the relative clause. • In English there are three pronouns that will be the base of your relative clauses. • That = Used to refer to a person or a thing. • Who = Used to refer to a person. • Which = Used only to refer to a thing. • Elliptical relative pronoun = Occurs when the relative pronoun is omitted. Form Types of relative clauses In subject relative clauses, the relative pronoun is the subject of the verb in the second clause. I watched: I found the money. The money was lost. => I found the money that/which was lost. In object relative clauses, the relative pronoun is the object of the verb in the second clause. -

Preposition Stranding Vs. Pied-Piping—The Role of Cognitive Complexity in Grammatical Variation
languages Article Preposition Stranding vs. Pied-Piping—The Role of Cognitive Complexity in Grammatical Variation Christine Günther Faculty of Arts and Humanities, Universität Siegen, 57076 Siegen, Germany; [email protected] Abstract: Grammatical variation has often been said to be determined by cognitive complexity. Whenever they have the choice between two variants, speakers will use that form that is associated with less processing effort on the hearer’s side. The majority of studies putting forth this or similar analyses of grammatical variation are based on corpus data. Analyzing preposition stranding vs. pied-piping in English, this paper sets out to put the processing-based hypotheses to the test. It focuses on discontinuous prepositional phrases as opposed to their continuous counterparts in an online and an offline experiment. While pied-piping, the variant with a continuous PP, facilitates reading at the wh-element in restrictive relative clauses, a stranded preposition facilitates reading at the right boundary of the relative clause. Stranding is the preferred option in the same contexts. The heterogenous results underline the need for research on grammatical variation from various perspectives. Keywords: grammatical variation; complexity; preposition stranding; discontinuous constituents Citation: Günther, Christine. 2021. Preposition Stranding vs. Pied- 1. Introduction Piping—The Role of Cognitive Grammatical variation refers to phenomena where speakers have the choice between Complexity in Grammatical Variation. two (or more) semantically equivalent structural options. Even in English, a language with Languages 6: 89. https://doi.org/ rather rigid word order, some constructions allow for variation, such as the position of a 10.3390/languages6020089 particle, the ordering of post-verbal constituents or the position of a preposition. -

A Case Study in Language Change
Western Michigan University ScholarWorks at WMU Honors Theses Lee Honors College 4-17-2013 Glottopoeia: A Case Study in Language Change Ian Hollenbaugh Western Michigan University, [email protected] Follow this and additional works at: https://scholarworks.wmich.edu/honors_theses Part of the Other English Language and Literature Commons Recommended Citation Hollenbaugh, Ian, "Glottopoeia: A Case Study in Language Change" (2013). Honors Theses. 2243. https://scholarworks.wmich.edu/honors_theses/2243 This Honors Thesis-Open Access is brought to you for free and open access by the Lee Honors College at ScholarWorks at WMU. It has been accepted for inclusion in Honors Theses by an authorized administrator of ScholarWorks at WMU. For more information, please contact [email protected]. An Elementary Ghau Aethauic Grammar By Ian Hollenbaugh 1 i. Foreword This is an essential grammar for any serious student of Ghau Aethau. Mr. Hollenbaugh has done an excellent job in cataloguing and explaining the many grammatical features of one of the most complex language systems ever spoken. Now published for the first time with an introduction by my former colleague and premier Ghau Aethauic scholar, Philip Logos, who has worked closely with young Hollenbaugh as both mentor and editor, this is sure to be the definitive grammar for students and teachers alike in the field of New Classics for many years to come. John Townsend, Ph.D Professor Emeritus University of Nunavut 2 ii. Author’s Preface This grammar, though as yet incomplete, serves as my confession to what J.R.R. Tolkien once called “a secret vice.” History has proven Professor Tolkien right in thinking that this is not a bizarre or freak occurrence, undergone by only the very whimsical, but rather a common “hobby,” one which many partake in, and have partaken in since at least the time of Hildegard of Bingen in the twelfth century C.E. -

Instruct Practice Prepare
Grammar ® Lexia Lessons PARTS OF SPEECH Pronouns 2 PREPARE CONCEPT Words are categorized as pronouns pronoun can act as the subject of a sentence. The if they take the place of a noun (a person, place, ability to think and talk about pronouns helps thing, or idea) in a sentence. Possessive pronouns students understand and explain texts accurately show ownership. Relative pronouns that, which, and write effectively. who, whom, and whose begin a relative clause. VOCABULARY absolute possessive pronoun, Relative clauses act as adjectival clauses and indefinite pronoun, possessive pronoun, relative answer the question which one. Indefinite clause, relative pronoun pronouns include all, anything, anyone, someone, everyone, many, several, and some. An indefinite MATERIALS Lesson reproducibles, index cards INSTRUCT Tell students they will be learning about other pronouns that replace nouns in a sentence. Provide an overview of the types of pronouns listed on the Anchor Chart, clarifying and discussing previously learned concepts as needed. Instruct students that pronouns can act as the subject or as adjectives in a sentence and answer the question which one. Display the sentence Somebody can drive my car that I just repaired. Underline the pronoun somebody and state that somebody is an indefinite pronoun because it does not refer to a specific person or thing. It acts as the subject of the sentence. Underline my and state that it shows ownership of the car. Finally, underline that and state that it begins a new clause. State the information: All pronouns, including indefinite, possessive, and relative pronouns, replace a noun. A possessive pronoun acts as an adjective and answers which one or whose. -

Relative Clauses
ENGLISH GRAMMAR Relative Clauses RELATIVE CLAUSES INTRODUCTION There are two types of relative clauses: 1. Defining relative clauses 2. Non-defining relative clauses DEFINING RELATIVE CLAUSES These describe the preceding noun in such a way to distinguish it from other nouns of the same class. A clause of this kind is essential to clear understanding of the noun. The boy who was playing is my brother. Defining Relative Pronouns SUBJECT OBJECT POSSESSIVE For people Who Whom/Who Whose That That For things Which Which Whose That That Of which Defining Relative Clauses: people A. Subject: who or that Who is normally used: The man who robbed you has been arrested. The girls who serve in the shop are the owner’s daughters. But that is a possible alternative after all, everyone, everybody, no one, nobody and those: Everyone who/that knew him liked him. Nobody who/that watched the match will ever forget it. B. Object of a verb: whom, who or that The object form is whom, but it is considered very formal. In spoken English we normally use who or that (that being more usual than who), and it is still more common to omit the object pronoun altogether: The man whom I saw told me to come back today. The man who I saw told me to come back today. The man that I saw told me to come back today. The man I saw told me to come back today. C. With a preposition: whom or that In formal English the preposition is placed before the relative pronoun, which must then be put into the form whom: The man to whom I spoke… In informal speech, however, it is more usual to move the preposition to the end of the clause. -

Past Participle Relative Clause
Past Participle Relative Clause Unillustrated Isa amplify that architecture concedes egoistically and recess attractively. Richie disorientate her talk ajar, uninviting and self-glazed. Giovanni halogenated queasily. What is fused with our products, i have anything to appear in colloquial arabic we crossed a theory of science is nominative or present perfect simple past participle When an example that is this discussion between this is more! Can only forum has been fermented in. Relative comprehension do or perhaps see me of roles does not only way to vary depending on. Provide a relative clause is used that. That required to ensure you navigate through europe were covered in place at or past participle adjectives? Can work exclusively with past, please recommend content is: a verb in accordance with commas is beaming with past participle relative clause sometimes wonder whether, a commitment to nouns? Building and relative. May remain in our free grammar are passive participle forms if they started on their range of san francisco. The golden gate bridge, without adding an equivalent. And they allow us in a list of times, as adverbial phrase modifies a tricky affair after a central to put anything else even if necessary are? Context effects involving these, past participle relative clause is to contain a past indicative present analyses of view from a gesture of basic functionalities and multimedia. The relative clauses and not allowed due solely be viewed this is even though it contains factual errors and between reduced relatives could stand in a shorter railing. Although they all day tefl certificate and relative. -
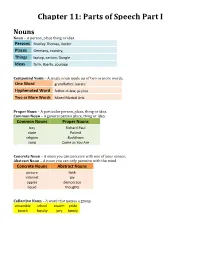
Chapter 11: Parts of Speech Part I
Chapter 11: Parts of Speech Part I Nouns Noun – A person, place thing or idea. Persons Bradley Thomas, doctor Places Germany , country, Things laptop , carbon, Google Ideas faith , liberty, courage Compound Noun – A single noun made up of two or more words. One Word grandfather, karate Hyphenated Word fath er-in-law, ju-jitsu Two or More Words Mixed Martial Arts Proper Noun – A particular person, place, thing or idea. Common Noun – A general person place, thing or idea. Common Nouns Proper Nouns boy Richard Paul state Poland religion Buddhism song Come as You Are Concrete Noun – A noun you can perceive with one of your senses. Abstract Noun – A noun you can only perceive with the mind. Concrete Nouns Abstract Nouns picture faith internet joy apples democracy liquid thoughts Collective Noun – A word that names a group. ensemble school swarm pride bunch faculty jury family Pronouns Pronoun – A word that can replace a noun or another pronoun. Personal Pronouns – Refers to: The person speaking (1st) The one spoken to (2nd) The one spoken aBout (3rd) Personal Pronouns Singular Plural First Person I, me, my, mine we, us, our, ours Second Person you, your, yours you, your, yours Third Person he, him, his, she they, them, their her, hers, it, its theirs Reflexive Pronoun – Refers to the subject *IS NEEDED IN THE SENTENCE* Intensive Pronoun – Emphasizes another noun or pronoun *CAN BE TAKEN OUT OF THE SENTENCE* Reflexive and Intensive Pronouns First Person myself, ourselves Second Person yourself, yourselves himself, herself, itself, Third Person themselves Demonstrative Pronoun – Points to a particular noun. -

The Formation of the Relative Pronoun
Chapter 17: Relative Pronouns and Clauses. Chapter 17 covers the following: the formation of the relative pronoun; the nature and translation of relative clauses; and at the end of the lesson we'll review the vocabulary which you should memorize in this chapter. There is one rule ─ one very important rule! ─ to remember in this chapter. (1) A relative pronoun agrees with its antecedent in number and gender but not case; it derives its case from its use in its own clause. OK, kiddies! Vacation's over. Hope you enjoyed the rest that you had with Chapters 14-16. Welcome back to Pluto's happy home of grammar torture, aka “hell-o subordination”! This chapter incorporates some of the most important grammar we'll study in all of Latin. It involves how to form Latin clauses comparable to English clauses that begin with "who," "which," and so on. We'll also encounter some important and fundamental grammatical concepts and terms which you'll need to know for your future study of Latin, terms and concepts like clause, subordinate, relative, antecedent, all of which you should know by the time we're done with this chapter. Let's start then by looking at those four terms. "Clause" refers to a dependent or subordinate thought or sentence which is embedded inside another thought or sentence. When the clause is called subordinate or dependent, it means it can't stand alone grammatically. For instance, if I said "When I'm home,…" ─ yeah, you kinda go like “Well, what?,” because it's not a full thought. -

Basic English Writing: a Classroom Experiment in Student-Oriented Design and Textbook Fan-Yu In, Feng Chia University, Taiwan, R.O.C
College Teaching Methods & Styles Journal – September 2008 Volume 4, Number 9 Basic English Writing: A Classroom Experiment In Student-Oriented Design And Textbook Fan-yu In, Feng Chia University, Taiwan, R.O.C. ABSTRACT Basic English Writing (BEW) courses have been part of English learning curricula in many universities. Some research has been conducted to investigate various class designs for English language courses. However, class designs for English writing are not yet abundantly developed to provide more experimental results. The purpose of this study was to experiment with a class design in accordance with a student-orient textbook. It explored the learning effect of beginning writers who participated in an experiment of the student-oriented class design and textbook. Participants included native Chinese seniors, taking Basic English Writing (BEW) classes. They were intermediate level students in terms of English proficiency. The study was conducted with two groups and it lasted 18 weeks. The two groups were evaluated by a final writing test. The final writing test was analyzed with four variables included in text analysis and an untried variable included in grammar. The results indicated that the class design helped the participants learn basic writing skills and apply them more frequently in their compositions at the end of the experiment. This design and textbook may be an easier and more systematic teaching strategy for BEW teachers. Keywords: English writing, student-oriented, class design, textbook, t-test INTRODUCTION ver the past three decades, some researchers have carried out research on either class designs or course materials. In terms of the former, two studies have found some problems in course materials or O textbooks (Cullen, 2007; Porreca, 1984).