BBC Position Paper
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

PERFORMED IDENTITIES: HEAVY METAL MUSICIANS BETWEEN 1984 and 1991 Bradley C. Klypchak a Dissertation Submitted to the Graduate
PERFORMED IDENTITIES: HEAVY METAL MUSICIANS BETWEEN 1984 AND 1991 Bradley C. Klypchak A Dissertation Submitted to the Graduate College of Bowling Green State University in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY May 2007 Committee: Dr. Jeffrey A. Brown, Advisor Dr. John Makay Graduate Faculty Representative Dr. Ron E. Shields Dr. Don McQuarie © 2007 Bradley C. Klypchak All Rights Reserved iii ABSTRACT Dr. Jeffrey A. Brown, Advisor Between 1984 and 1991, heavy metal became one of the most publicly popular and commercially successful rock music subgenres. The focus of this dissertation is to explore the following research questions: How did the subculture of heavy metal music between 1984 and 1991 evolve and what meanings can be derived from this ongoing process? How did the contextual circumstances surrounding heavy metal music during this period impact the performative choices exhibited by artists, and from a position of retrospection, what lasting significance does this particular era of heavy metal merit today? A textual analysis of metal- related materials fostered the development of themes relating to the selective choices made and performances enacted by metal artists. These themes were then considered in terms of gender, sexuality, race, and age constructions as well as the ongoing negotiations of the metal artist within multiple performative realms. Occurring at the juncture of art and commerce, heavy metal music is a purposeful construction. Metal musicians made performative choices for serving particular aims, be it fame, wealth, or art. These same individuals worked within a greater system of influence. Metal bands were the contracted employees of record labels whose own corporate aims needed to be recognized. -

University of Oklahoma Graduate College Performing Gender: Hell Hath No Fury Like a Woman Horned a Thesis Submitted to the Gradu
UNIVERSITY OF OKLAHOMA GRADUATE COLLEGE PERFORMING GENDER: HELL HATH NO FURY LIKE A WOMAN HORNED A THESIS SUBMITTED TO THE GRADUATE FACULTY in partial fulfillment of the requirements for the Degree of MASTER OF ARTS By GLENN FLANSBURG Norman, Oklahoma 2021 PERFORMING GENDER: HELL HATH NO FURY LIKE A WOMAN HORNED A THESIS APPROVED FOR THE GAYLORD COLLEGE OF JOURNALISM AND MASS COMMUNICATION BY THE COMMITTEE CONSISTING OF Dr. Ralph Beliveau, Chair Dr. Meta Carstarphen Dr. Casey Gerber © Copyright by GLENN FLANSBURG 2021 All Rights Reserved. iv TABLE OF CONTENTS Abstract ........................................................................................................................................... vi Introduction .................................................................................................................................... 1 Heavy Metal Reigns…and Quickly Dies ....................................................................................... 1 Music as Discourse ...................................................................................................................... 2 The Hegemony of Heavy Metal .................................................................................................. 2 Theory ......................................................................................................................................... 3 Encoding/Decoding Theory ..................................................................................................... 3 Feminist Communication -

Song & Music in the Movement
Transcript: Song & Music in the Movement A Conversation with Candie Carawan, Charles Cobb, Bettie Mae Fikes, Worth Long, Charles Neblett, and Hollis Watkins, September 19 – 20, 2017. Tuesday, September 19, 2017 Song_2017.09.19_01TASCAM Charlie Cobb: [00:41] So the recorders are on and the levels are okay. Okay. This is a fairly simple process here and informal. What I want to get, as you all know, is conversation about music and the Movement. And what I'm going to do—I'm not giving elaborate introductions. I'm going to go around the table and name who's here for the record, for the recorded record. Beyond that, I will depend on each one of you in your first, in this first round of comments to introduce yourselves however you wish. To the extent that I feel it necessary, I will prod you if I feel you've left something out that I think is important, which is one of the prerogatives of the moderator. [Laughs] Other than that, it's pretty loose going around the table—and this will be the order in which we'll also speak—Chuck Neblett, Hollis Watkins, Worth Long, Candie Carawan, Bettie Mae Fikes. I could say things like, from Carbondale, Illinois and Mississippi and Worth Long: Atlanta. Cobb: Durham, North Carolina. Tennessee and Alabama, I'm not gonna do all of that. You all can give whatever geographical description of yourself within the context of discussing the music. What I do want in this first round is, since all of you are important voices in terms of music and culture in the Movement—to talk about how you made your way to the Freedom Singers and freedom singing. -

Saw 3 1080P Dual
Saw 3 1080p dual click here to download Saw III UnRated English Movie p 6CH & p Saw III full movie hindi p dual audio download Quality: p | p Bluray. Saw III UnRated English Movie p 6CH & p BluRay-Direct Links. Download Saw part 3 full movie on ExtraMovies Genre: Crime | Horror | Exciting. Saw III () Saw III P TORRENT Saw III P TORRENT Saw III [DVDRip] [Spanish] [Ac3 ] [Dual Spa-Eng], Gigabyte, 3, 1. Download Saw III p p Movie Download hd popcorns, Direct download p p high quality movies just in single click from HDPopcorns. Jeff is an anguished man, who grieves and misses his young son that was killed by a driver in a car accident. He has become obsessed for. saw dual audio p movies free Download Link . 2 saw 2 mkv dual audio full movie free download, Keyword 3 saw 2 mkv dual audio full movie free. Our Site. IMDB: / MPA: R. Language: English. Available in: p I p. Download Saw 3 Full HD Movie p Free High Quality with Single Click High Speed Downloading Platform. Saw III () BRRip p Latino/Ingles Nuevas y macabras aventuras Richard La Cigueña () BRRIP HD p Dual Latino / Ingles. Horror · Jigsaw kidnaps a doctor named to keep him alive while he watches his new apprentice Videos. Saw III -- Trailer for the third installment in this horror film series. Saw III 27 Oct Descargar Saw 3 HD p Latino – Nuevas y macabras aventuras del siniestro Jigsaw, Audio: Español Latino e Inglés Sub (Dual). Saw III () UnRated p BluRay English mb | Language ; The Gravedancers p UnRated BRRip Dual Audio by. -

A Flickering Tribute to Mason's Music Scene
From Dolly Parton to Megadeth: A Flickering Tribute to Mason’s Music Scene ver the past 30+ years, Mason’s 10,000-seat arena has been a big part of campus life and the Northern Virginia community. Since its 1985 opening, the Patriot Center (now EagleBank Arena) has been visited by more than 12 million patrons for more than 3,600 events that have ranged from ultimate fighting to the Harlem Globetrotters. InO 2010, Billboard magazine ranked the Patriot Center No. 8 nationwide and No. 18 worldwide among top-grossing venues with a capacity between 10,001 and 15,000. As the venue for both Disney On Ice and the Ringling Bros. and Barnum and Bailey Circus, the arena has been the place where many area children saw their first circus or their favorite animated movie come to life. Many have graduated from high school and college there. Adults also have fond memories of their concerts. We recently asked a Fairfax, Virginia, group on Facebook to tell us about their favorite Patriot Center concert, and received 82 responses. The list of performers is long and diverse, running the gamut from Dolly Parton to Megadeth. 10 | FASTER FARTHER: THE CAMPAIGN FOR GEORGE MASON UNIVERSITY WARNING: READING THIS LIST MIGHT MAKE YOU WANT TO RAISE YOUR LIGHTER IN MEMORY. Facebook mentions talked about Poison, Chicago, Tears for Fears, Green Day, The Cult, Lenny Kravitz, Ronnie Milsap, Sarah McLachlan, One Direction, George Jones, Mumford and Sons, Vanilla Ice, Beastie Boys, Randy Travis, The Wiggles, Phish, Dan Fogelberg, Kenny Rogers, Duran Duran, The Killers, the Moody Blues, Tom Petty and the Heartbreakers, Bob Dylan, Bruce Springsteen, and Prince, among others. -

Smartset® Saw – Operation and Maintenance
Operation and Maintenance Manual SmartSet ® Saw Component Saw Copyright © 2005, 2008 MiTek®. All rights reserved. 001047 Patented. See Legal Notice for list of patents. Rev. B Operation and Maintenance Manual ® SmartSet Saw Component Saw U.S. and other patents pending. MiTek 001047 Machinery Division Revision B 301 Fountain Lakes Industrial Dr. Revision date 20 February 2008 Print date 14 March 2008 St. Charles, MO 63303 Revised by R. Widder phone: 800-523-3380 Approved by G. McNeelege fax: 636-328-9218 www.mii.com Applicability: PN 78610 Contents Preliminary Pages Contents. ii Trademark . vii Legal Notice . vii Notice of Change. viii Safety (English) Safety Indicators . x Safety Rules . xi Lockout/Tagout . xiii Lockout/Tagout Guidelines . xiii Electrical Lockout/Tagout Procedures . xiv Pneumatic System Lockout/Tagout Procedure . xvii Troubleshooting With an Energized Machine . xvii Restricted Zone . xviii Seguridad (Español) Indicadores de seguridad . xx Reglas de seguridad . xxi Bloqueo/Etiquetado . xxiv Pautas de bloqueo/etiquetado . xxiv Procedimientos de bloqueo/etiquetado eléctricos xxv Procedimiento de bloqueo/etiquetado del sistema neumático . .xxviii Solución de problemas con una máquina energizada xxviii Zonas restringida . xxix General Information Chapter 1 Introduction to This Manual . 2 Purpose of This Manual . 2 Using This Manual . 2 Introduction to This Equipment . 3 Purpose of the Equipment . 3 Overview of the Equipment . 3 Components and Options . 3 System Identification . 5 General Specifications . 6 Prior to Installation Chapter 2 MiTek’s Responsibilities . 7 Prior to Installation . 7 During Installation . 7 Customer’s Responsibilities . 8 Space Requirements . 9 Location Requirements . 10 Electrical Requirements . 11 Pneumatic System Requirements . 11 Shipping Information . 11 Customer-Supplied Parts . -

Jigsaw: Torture Porn Rebooted? Steve Jones After a Seven-Year Hiatus
Originally published in: Bacon, S. (ed.) Horror: A Companion. Oxford: Peter Lang, 2019. This version © Steve Jones 2018 Jigsaw: Torture Porn Rebooted? Steve Jones After a seven-year hiatus, ‘just when you thought it was safe to go back to the cinema for Halloween’ (Croot 2017), the Saw franchise returned. Critics overwhelming disapproved of franchise’s reinvigoration, and much of that dissention centred around a label that is synonymous with Saw: ‘torture porn’. Numerous critics pegged the original Saw (2004) as torture porn’s prototype (see Lidz 2009, Canberra Times 2008). Accordingly, critics such as Lee (2017) characterised Jigsaw’s release as heralding an unwelcome ‘torture porn comeback’. This chapter will investigate the legitimacy of this concern in order to determine what ‘torture porn’ is and means in the Jigsaw era. ‘Torture porn’ originates in press discourse. The term was coined by David Edelstein (2006), but its implied meanings were entrenched by its proliferation within journalistic film criticism (for a detailed discussion of the label’s development and its implied meanings, see Jones 2013). On examining the films brought together within the press discourse, it becomes apparent that ‘torture porn’ is applied to narratives made after 2003 that centralise abduction, imprisonment, and torture. These films focus on protagonists’ fear and/or pain, encoding the latter in a manner that seeks to ‘inspire trepidation, tension, or revulsion for the audience’ (Jones 2013, 8). The press discourse was not principally designed to delineate a subgenre however. Rather, it allowed critics to disparage popular horror movies. Torture porn films – according to their detractors – are comprised of violence without sufficient narrative or character development (see McCartney 2007, Slotek 2009). -

Screendollars Newsletter 2021-04-26.Pdf
Monday, April 26, 2021 | No. 165 One of the things moviegoers like most about going to theatres is seeing films on the Big Screen, "the way they were meant to be seen." What people don't realize is that when films started in the mid-1890s, there were neither screens nor projectors. The very short films of that era were meant to be seen individually by looking into peep show machines in arcades. Those Kinetoscope devices were one of many inventions from Thomas Edison's factory in West Orange, NJ. Since Edison was monetizing his Kinetoscopes quite well, he had no interest in developing a machine to project film images on walls. Others, however, saw a big future in showing films to groups of people. Peep show owners, in fact, were very vocal in pressing Edison to devise a Film projection to large audiences was much more way to show life size images on arcade walls. This led to the Vitascope profitable than viewing through individual kiosks, since projection system, developed by Washington, DC inventor Thomas Armat, fewer machines were needed in proportion to the but then marketed by Edison's organization as if it were his own invention. number of viewers - Click to Play The first public Vitascope screening took place April 23, 1896 at Koster & Biel's Music Hall, a vaudeville house in New York's Herald Square at 34th Street near Broadway, the site today of Macy's. It would have premiered three days earlier, but it took longer than expected to install the machinery. That first night audience was dazzled by film images projected on a 20 foot canvas screen set within a gilded frame. -

Critical Essays on James Wan
H-Announce Critical Essays on James Wan Announcement published by Matthew Edwards on Tuesday, February 12, 2019 Type: Call for Papers Date: May 31, 2019 Location: United Kingdom Subject Fields: Film and Film History, Popular Culture Studies Critical Essays on James Wan Deadline for abstract submissions: May, 2019 Full name / name of organization: Matthew Edwards/ Independent Scholar Contact email: [email protected] Fernando Gabriel Pagnoni Berns/Universidad de Buenos Aires (Argentina). http://artes.filo.uba.ar/la-literatura-de-las-artes-combinadas-ii contact mail: [email protected] Critical Essays on James Wan Edited by Matthew Edwards and Fernando Gabriel Pagnoni Berns Critical essays are sought on the cinema of Malaysian/Australian director, screenwriter and producer James Wan. As 2018 marks Wan’s first incursion into superhero cinema with Aquaman, a film that reportedly is DC Films’ biggest worldwide grosser, critical attention on the director keeps intensifying. With huge critical and box office successes such as Saw (2004), a film that kickstarted a whole franchise, The Conjuring I and II (2013 and 2016), films that started a whole filmic universe, together with Death Sentence (2007), Insidious I and II (2010 and 2013), Furious 7 (2015) and Dead Silence (2007), it can be argued that we are facing a new Hollywood auteur with an identity of his own. Still, there is a striking lack of critical studies on the works of James Wan, even Citation: Matthew Edwards. Critical Essays on James Wan. H-Announce. 02-12-2019. https://networks.h-net.org/node/73374/announcements/3703216/critical-essays-james-wan Licensed under a Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 United States License. -
Dima Music Watch PPT Slides2
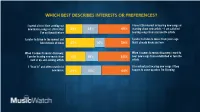
Which best describes interests or preferences? I spend a lot of time seeking out I have little interest in hearing new songs or new music; songs or artists that 26% 24% 49% learning about new artists – I am satisfied I’ve not heard before hearing songs from my favorite artists I prefer to listen to the newest and I prefer to listen to music from years ago latest music of today 45% 16% 39% that I already know and love When it comes to music discovery, When it comes to music discovery, I want to I prefer hearing new music from 31% 19% 50% hear new songs from established or favorite new or up-and-coming artists artists I “lean in” and often search for I’m content just hearing new songs if they new music 24% 31% 44% happen to come up when I’m listening Any Music Streaming Service 63% AM/FM Radio Broadcast or Digital 52% sources Heard/Saw on Social Media or Dance/Video App 50% Friend(s)/family spoke to me about it or played it for me 39% Music is played in a movie (theme song or as background music) 35% Which of the following sources do I heard or saw the music played on Facebook, Twitter, Snapchat or Instagram 34% you find most helpful for hearing or Music in video games (e.g. Fortnite, Grand Theft Auto/GTA, etc.) 33% Played on a TV show (theme song, soundtrack or as background music) 33% learning about new songs and Recommended songs or albums from online music shopping sites (iTunes, Amazon, etc.) 32% artists, or for rediscovering songs Recommendations/postings from artists I like on Facebook, Twitter, Snapchat or Instagram 30% I saw postings/tweets/alerts, etc. -

OSC 2015 Radial Arm Saw Brochure 6.2016 Digital.Pub
MOTORS All Super Duty, Heavy Duty, and Contractor Duty Series motors are manufactured in our Northern Iowa facility. Producing our own motors allows us to uphold a very high level of quality in our machines. These totally enclosed fan cooled (TEFC) motors are manufactured with cooling ducts that move air through the motor laminations to keep them cool while keeping the internal portion of the motor sealed from dust and contamination. These motors also offer the added benefit of an integrated electro-mechanical brake system. These brake systems continue to operate even when the power drops out. Electronic brake systems cannot compete with their durability or reliability. CAST CONSTRUCTION Original Saw Company’s Radial Arm Saws are manufactured utilizing high quality heavy cast iron and cast aluminum construction. These high quality American castings provide a very rigid, vibration-free cutting platform to perform many different sawing and dado operations. It is because of this construction we can proudly say our machines are the best in the industry. Many of the machines we produce today will be around for generations PARTS AND SERVICE Original Saw Company strives for customer satisfaction. We stock a full supply of service parts for everything we manufacture as well as older units. We will work through any issues you may run across during the life of your machine. This is the way Original Saw treats it customers when issues arise whether it is 1 year after the sale or 10 years later; whether it is a machine problem or an application issue. This is why Original Saw Company is the one to rely on now and in the future. -

Complete Portable Saws Catalog (PDF)
Portable Saws & Accessories Heavy-duty Saws… Fast, accurate cutting on the job site! CS Unitec's portable saws and tools are ideal for cutting pipe, structural steel, tanks, bolts, angle iron, concrete and other materials, including plastic and wood. We offer ATEX Certified the widest range of portable pneumatic, electric and hydraulic saws in the industry. Our saws can be used as hand-held tools or with an assortment of clamps for pipe Selected air and and other materials. All CS Unitec saws are heavy-duty for use in industry and hydraulic models in our line are ATEX construction. Our complete saw line includes pneumatic-, electric- and hydraulic- Certified for working in powered tools, saw blades and accessories, all available for prompt delivery. Ex Zones. Contact us for more information. CS Unitec is the industry leader in: • Portable saws for cutting pipe, metal, concrete, etc. • Compact, lightweight, hand-held and clamp-mounted saws • The best power-to-weight ratios • Long-lasting, heavy-duty saw blades for fast cutting of steel, stainless steel, Inconel, chrome, Hastelloy, aluminum, iron, plastics, masonry, concrete and other materials We offer: • Pneumatic-, electric- and hydraulic-powered saws • Clamps for 90˚ cutting of pipe, structural steel and other materials • Compact sizes for sawing in confined spaces Tool and Accessory Index: Portable Reciprocating Saws p. 4-13 Chain Saws p. 29-33 Pneumatic – Low Air Volume p. 5-7 10 HP Hydraulic with Brake p. 29 Pneumatic 4 HP Pneumatic p. 30 1.3 HP – The CAT p. 10 4 HP Pneumatic with Brake p. 31 Hydraulic 1.2 HP Pneumatic p.