Cutting Patterns in DW Griffith's Biographs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

RESTORATION RESTORATION 660 Mason Ridge Center Dr
REGRETS, REALITY, REGRETS, REALITY, RESTORATION RESTORATION Regrets: whose life is not plagued by at least a few of these nagging leftovers from the past? The things we regret doing—or not doing, as the case may be—can wear us down, reshaping our lives and our sense of self, in the process. Left unattended, regrets erode our self-esteem, our willingness to press on, even our ability to think clearly. Everything becomes shrouded by the guilt, the pain we’ve caused, the sense that lives have been ruined, or at least dreadfully altered, by our foolish mistakes. 660 Mason Ridge Center Dr. What’s happened in our lives, however, does not have to dictate the present—or the future. We can move beyond the crippling anguish and pain our decisions St. Louis, Missouri 63141-8557 may have caused. Still, restoration—true restoration— is not purely a matter of willpower and positive think- ing. It’s turning to the One who has taken all our griefs, 1-800-876-9880 • www.lhm.org sorrows, anxieties, blunders, and misdeeds to the cross and where, once and for all time, He won for us an ultimate victory, through His death and resurrection. In Jesus there is a way out of your past. There is no 6BE159 sin beyond pardon. Even as Peter was devastated by his callousness toward the Savior’s predicament and arrest, he was restored—by the grace of God—to a REGRETS, REALITY, life that has made a difference in the lives of untold millions through the centuries. 6BE159 660 Mason Ridge Center Dr. -

2014 National History Bee National Championships Round
2014 National History Bee National Championships Bee Finals BEE FINALS 1. Two men employed by this scientist, Jack Phillips and Harold Bride, were aboard the Titanic, though only the latter survived. A company named for this man was embroiled in an insider trading scandal involving Rufus Isaacs and Herbert Samuel, members of H.H. Asquith's cabinet. He shared the Nobel Prize with Karl Ferdinand Braun, and one of his first tests was aboard the SS Philadelphia, which managed a range of about two thousand miles for medium-wave transmissions. For the point, name this Italian inventor of the radio. ANSWER: Guglielmo Marconi 048-13-94-25101 2. A person with this surname died while piloting a plane and performing a loop over his office. Another person with this last name was embroiled in an arms-dealing scandal with the business Ottavio Quattrochi and was killed by a woman with an RDX-laden belt. This last name is held by "Sonia," an Italian-born Catholic who declined to become prime minister in 2004. A person with this last name declared "The Emergency" and split the Congress Party into two factions. For the point, name this last name shared by Sanjay, Rajiv, and Indira, the latter of whom served as prime ministers of India. ANSWER: Gandhi 048-13-94-25102 3. This man depicted an artist painting a dog's portrait with his family in satire of a dog tax. Following his father's commitment to Charenton asylum, this painter was forced to serve as a messenger boy for bailiffs, an experience which influenced his portrayals of courtroom scenes. -

Papéis Normativos E Práticas Sociais
Agnes Ayres (1898-194): Rodolfo Valentino e Agnes Ayres em “The Sheik” (1921) The Donovan Affair (1929) The Affairs of Anatol (1921) The Rubaiyat of a Scotch Highball Broken Hearted (1929) Cappy Ricks (1921) (1918) Bye, Bye, Buddy (1929) Too Much Speed (1921) Their Godson (1918) Into the Night (1928) The Love Special (1921) Sweets of the Sour (1918) The Lady of Victories (1928) Forbidden Fruit (1921) Coals for the Fire (1918) Eve's Love Letters (1927) The Furnace (1920) Their Anniversary Feast (1918) The Son of the Sheik (1926) Held by the Enemy (1920) A Four Cornered Triangle (1918) Morals for Men (1925) Go and Get It (1920) Seeking an Oversoul (1918) The Awful Truth (1925) The Inner Voice (1920) A Little Ouija Work (1918) Her Market Value (1925) A Modern Salome (1920) The Purple Dress (1918) Tomorrow's Love (1925) The Ghost of a Chance (1919) His Wife's Hero (1917) Worldly Goods (1924) Sacred Silence (1919) His Wife Got All the Credit (1917) The Story Without a Name (1924) The Gamblers (1919) He Had to Camouflage (1917) Detained (1924) In Honor's Web (1919) Paging Page Two (1917) The Guilty One (1924) The Buried Treasure (1919) A Family Flivver (1917) Bluff (1924) The Guardian of the Accolade (1919) The Renaissance at Charleroi (1917) When a Girl Loves (1924) A Stitch in Time (1919) The Bottom of the Well (1917) Don't Call It Love (1923) Shocks of Doom (1919) The Furnished Room (1917) The Ten Commandments (1923) The Girl Problem (1919) The Defeat of the City (1917) The Marriage Maker (1923) Transients in Arcadia (1918) Richard the Brazen (1917) Racing Hearts (1923) A Bird of Bagdad (1918) The Dazzling Miss Davison (1917) The Heart Raider (1923) Springtime à la Carte (1918) The Mirror (1917) A Daughter of Luxury (1922) Mammon and the Archer (1918) Hedda Gabler (1917) Clarence (1922) One Thousand Dollars (1918) The Debt (1917) Borderland (1922) The Girl and the Graft (1918) Mrs. -

Teacher Support Materials to Use With
Teacher support materials to use with Brief Plot Summary Discussion Questions Historical Drawings and Photos for Discussion Detailed Plot Summary Historical Background What Did You Read? – Form Book Report – Form Word Play Activity Fill in the Blanks Review Activity Brief Plot Summary For Gold and Blood tells the story of two Chinese brothers, Soo and Ping Lee, who, like many Chinese immigrants, leave their home in China to go to California in 1851. They hope to strike it rich in the Gold Rush and send money back to their family. In the gold fields, they make a big strike but are cheated out of it. After 12 years of prospecting, they split up. Soo joins the Chinese workers who build the Central Pacific Railroad, while Ping opens a laundry in San Francisco. With little to show for his work, Soo also goes to San Francisco. Both men face prejudice and violence. In time they join rival factions in the community of Chinatown, Ping with one of the Chinese Six Families and Soo with a secret, illegal tong. The story ends after the 1906 earthquake. This dramatic historical novel portrays the complicated lives of typical immigrants from China and many other countries. Think about it For Gold and Blood Discussion Questions Chapter 1 Leaving Home 1. If you were Ping, would you leave home for the possibility of finding gold so far away? 2. The brothers had to pay money to get out of the country. Does that happen now? 3. Do you think it’s possible to get rich fast without breaking the law? 4. -
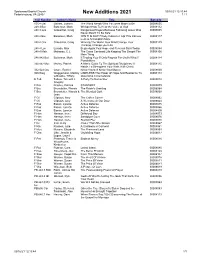
New Additions 2021 1 / 1
Spotswood Baptist Church 03/16/21 12:10:44 Federicksburg, VA 22407 New Additions 2021 1 / 1 Call Number Author's Name Title Barcode 155.4 Gai Gaines, Joanna The World Needs Who You were Made to Be 00008055 248.3 Bat Batterson, Mark Whisper:How To Hear the Voice of God 00008112 248.3 Gro Groeschel, Craig Dangerous Prayers:Because Following Jesus Was 00008095 Never Meant To Be Safe 248.4 Bat Batterson, Mark WIN THE DAY:7 Daily Habits to Help YOu bStress 00008117 Less & Accomplish More 248.4 Gro Groeschel, Craig Winning The WarIn Your Mind:Change Your 00008129 Thinking, Change your Life 248.4 Luc Lucado, Max Begin Again:Your Hope and Renewal Start Today 00008054 248.4 Mah Mahaney, C.J. The Cross Centered Life:Keeping The Gospel The 00008106 Main Thing 248.842 Bat Batterson, Mark If:Trading Your If Only Regrets For God's What If 00008114 Possibilities 248.842 Mor Morley, Patrick A Man's Guide To The Spiritual Disciplines:12 00008115 Habits To Strengthen Your Walk With Christ 332.024 Cru Cruze, Rachel Know Yourself Know Your Money 00008060 920 Weg Weggemann, Mallory LIMITLESS:The Power Of Hope And Resilience To 00008118 w/Brooks, Tiffany Overcome Circumstance E Teb Tebow, Tim w/A.J. A Party To Remember 00008018 Gregory F Bra Bradley, Patricia STANDOFF 00008079 F Bru Brunstetter, Wanda The Robin's Greeting 00008084 F Bru Brunstetter, Wanda & The Blended Quilt 00008068 Jean F Cli Clipston, Amy The Coffee Corner 00008062 F Cli Clipston, Amy A Welcome At Our Door 00008064 F Eas Eason, Lynette Active Defense 00008015 F Eas Eason, Lynette Active -

Film and Politics
Politics and Film PS 350 – Spring 2015 Instructor: Jay Steinmetz – [email protected] Office hours and location: Wednesdays – 3 to 5, PLC 808 GTFs: TBD Culture constitutes shared signs and expressions that can reveal, determine, and otherwise influence politics. The film medium is perfectly tailored for this: the power of moving image with sound, reflected in public spaces, produces politically charged identities and influences the way spectators see themselves and their shared communities. Moreover, the interwoven nature of the economic and social in cinema makes it an especially intriguing site for observing change of political culture over time. The economic commodity of the cinema is necessarily social—a nexus of public and shared images of the world. Conversely, the social constraints (ie moral regulation or censorship of film content) is necessarily shaped by economic factors. The “Dream Machine” of Hollywood is a potent meaning-making site not just for Americans but across the world (today, roughly half of a Hollywood film’s revenue often comes from overseas), and so this course will pay close attention to Hollywood film texts and contexts in a global setting. The second half of the term (starting in Week 5) will shift to a comparative approach, contrasting American and Italian film styles, industries, regulatory concerns, and economic strategies. Analytic comparison is a crucial aspect of this course—be it comparisons across genres, time periods, films, or industries—and will culminate in a comparative research paper due on Week 10. There will be one film screening in class every week. Please note: Attendance to these screenings is part of your class responsibilities. -

E/2021/NGO/XX Economic and Social Council
United Nations E/2021/NGO/XX Economic and Social Distr.: General July 2021 Council Original: English and French 2021 session 13 July 2021 – 16 July 2021 Agenda item 5 ECOSOC High-level Segment Statement submitted by organizations in consultative status with the Economic and Social Council * The Secretary-General has received the following statements, which are being circulated in accordance with paragraphs 30 and 31 of Economic and Social Council resolution 1996/31. Table of Contents1 1. Abshar Atefeha Charity Institute, Chant du Guépard dans le Désert, Charitable Institute for Protecting Social Victims, The, Disability Association of Tavana, Ertegha Keyfiat Zendegi Iranian Charitable Institute, Iranian Thalassemia Society, Family Health Association of Iran, Iran Autism Association, Jameh Ehyagaran Teb Sonnati Va Salamat Iranian, Maryam Ghasemi Educational Charity Institute, Network of Women's Non-governmental Organizations in the Islamic Republic of Iran, Organization for Defending Victims of Violence,Peivande Gole Narges Organization, Rahbord Peimayesh Research & Educational Services Cooperative, Society for Protection of Street & Working Children, Society of Iranian Women Advocating Sustainable Development of Environment, The Association of Citizens Civil Rights Protection "Manshour-e Parseh" 2. ACT Alliance-Action by Churches Together, Anglican Consultative Council, Commission of the Churches on International Affairs of the World Council of Churches, Lutheran World Federation, Presbyterian Church (USA), United Methodist Church - General Board of Church and Society 3. Adolescent Health and Information Projects, European Health Psychology Society, Institute for Multicultural Counseling and Education Services, Inc., International Committee For Peace And Reconciliation, International Council of Psychologists, International Federation of Business * The present statements are issued without formal editing. -

The Silent Film Project
The Silent Film Project Films that have completed scanning – Significant titles in bold: May 1, 2018 TITLE YEAR STUDIO DIRECTOR STAR 1. [1934 Walt Disney Promo] 1934 Disney 2. 13 Washington Square 1928 Universal Melville W. Brown Alice Joyce 3. Adventures of Bill and [1921] Pathegram Robert N. Bradbury Bob Steele Bob, The (Skunk, The) 4. African Dreams [1922] 5. After the Storm (Poetic [1935] William Pizor Edgar Guest, Gems) Al Shayne 6. Agent (AKA The Yellow 1922 Vitagraph Larry Semon Larry Semon Fear), The 7. Aladdin And The 1917 Fox Film C. M. Franklin Francis Wonderful Lamp Carpenter 8. Alexandria 1921 Burton Holmes Burton Holmes 9. An Evening With Edgar A. [1938] Jam Handy Louis Marlowe Edgar A. Guest Guest 10. Animals of the Cat Tribe 1932 Eastman Teaching 11. Arizona Cyclone, The 1934 Imperial Prod. Robert E. Tansey Wally Wales 12. Aryan, The 1916 Triangle William S. Hart William S. Hart 13. At First Sight 1924 Hal Roach J A. Howe Charley Chase 14. Auntie's Portrait 1914 Vitagraph George D. Baker Ethel Lee 15. Autumn (nature film) 1922 16. Babies Prohibited 1913 Thanhouser Lila Chester 17. Barbed Wire 1927 Paramount Rowland V. Lee Pola Negri 18. Barnyard Cavalier 1922 Christie Bobby Vernon 19. Barnyard Wedding [1920] Hal Roach 20. Battle of the Century 1927 Hal Roach Clyde Bruckman Oliver Hardy, Stan Laurel 21. A Beast at Bay 1912 Biograph D.W. Griffith Mary Pickford 22. Bebe Daniels & Ben Lyon 1931- Bebe Daniels, home movies 1935 Ben Lyon 23. Bell Boy 13 1923 Thomas Ince William Seiter Douglas Maclean 24. -

Those Crazy Lay Fiduciaries
Fall 2019 DDelawareelaware Vol. 15 No. 4 BBankeranker Those Crazy Lay Fiduciaries What to Watch for When Working with Them COLLABORATION builds better solutions for your clients. For more than a century, we have helped individuals and families thrive with our comprehensive wealth management solutions. Let’s work together to provide your clients with the resources to meet their complex needs. For more information about how we can help you achieve your goals, call Nick Adams at 302.636.6103 or Tony Lunger at 302.651.8743. wilmingtontrust.com Wilmington Trust is a registered service mark. Wilmington Trust Corporation is a wholly owned subsidiary of M&T Bank Corporation. ©2019 Wilmington Trust Corporation and its affiliates. All rights reserved. 33937 191016 VF $ ? Fall 2019 DBA ! Vol. 15, No. 4 Delaware Bankers Association The Delaware Bankers Association P.O. Box 781 Dover, DE 19903-0781 Phone: (302) 678-8600 Fax: (302) 678-5511 www.debankers.com The Quarterly Publication of the Delaware Bankers Association BOARD OF DIRECTORS $ CHAIR Elizabeth D. Albano P. 10 P. 14 P. 24 Executive Vice President Artisans’ Bank CHAIR-ELECT PAST-CHAIR Joe Westcott Cynthia D.M. Brown Market President President Capital One ? Commonwealth Trust Company DIRECTORS-AT-LARGE Thomas M. Forrest Eric G. Hoerner President & CEO Chief Executive Officer U.S. Trust Company of Delaware MidCoast Community Bank DIRECTORS Dominic C. Canuso Lisa P. Kirkwood Contents EVP & Chief Financial Officer SVP, Regional Vice President WSFS Bank TD Bank View from the Chair ................................................................. 4 Larry Drexler Nicholas P. Lambrow President’s Report ..................................................................... 6 Gen. Counsel, Head of Legal & Chief President, Delaware Region What’s New at the DBA ........................................................ -

• Housirig the Jews. Labor the Negro
• . I / f :CATHOLIC WORKER Subscriptions Vol. XV. No. 6 September, 19~8 25c Per· Year Price le "There is a fight against "Why is it that Com Housirig Communism that produces The Jews. munism flourishes in coun Labor I have a vague· remembrance, no results. What really mat There• continues to be among tries that have Christians? In an article titled "Toward almost as though I had dreamed it, ters is to achieve, in the face some Chl'istians a ·persistent and Is it not the consequence Peace in Labor," (Colliers' March \ of my father telling me that the of Communism; the Chris never dying detestation of the Jew. of a great disappointm~nt? 6, 1948) Senator Robert Taft old Irish Brehon Code had a law, tian ideal of community. Our God, who as man was ~ Jew, This disappointment, how makes the outright claims that his called the Law of Ancient Lights, "The characteristic_of Ma would be unwelcome in· the-homes ever, comes not from Chris law has b1ought peace to the field forbidding anyone to shut out the terialism is violence; that of these Christians, He would not tianity, but from, Chris of labor relations, has kept the sun, and the moon and the stars, of Christianity is Love." · be acceptable "in the best circles." tians." rights granted labor by the Wag He and His Blessed Mother and St. from another man's window. The Cardinal Saliege . Cardinal Saliege ner Act intact, is supported by idea of such a good law, so full of Joseph would, by agreement among many union leaders, and has wisdom and depth, fascinated me, Chr~stians, be excluded from apart brought justice to, labor. -

Idioms-And-Expressions.Pdf
Idioms and Expressions by David Holmes A method for learning and remembering idioms and expressions I wrote this model as a teaching device during the time I was working in Bangkok, Thai- land, as a legal editor and language consultant, with one of the Big Four Legal and Tax companies, KPMG (during my afternoon job) after teaching at the university. When I had no legal documents to edit and no individual advising to do (which was quite frequently) I would sit at my desk, (like some old character out of a Charles Dickens’ novel) and prepare language materials to be used for helping professionals who had learned English as a second language—for even up to fifteen years in school—but who were still unable to follow a movie in English, understand the World News on TV, or converse in a colloquial style, because they’d never had a chance to hear and learn com- mon, everyday expressions such as, “It’s a done deal!” or “Drop whatever you’re doing.” Because misunderstandings of such idioms and expressions frequently caused miscom- munication between our management teams and foreign clients, I was asked to try to as- sist. I am happy to be able to share the materials that follow, such as they are, in the hope that they may be of some use and benefit to others. The simple teaching device I used was three-fold: 1. Make a note of an idiom/expression 2. Define and explain it in understandable words (including synonyms.) 3. Give at least three sample sentences to illustrate how the expression is used in context. -

National Film Registry
National Film Registry Title Year EIDR ID Newark Athlete 1891 10.5240/FEE2-E691-79FD-3A8F-1535-F Blacksmith Scene 1893 10.5240/2AB8-4AFC-2553-80C1-9064-6 Dickson Experimental Sound Film 1894 10.5240/4EB8-26E6-47B7-0C2C-7D53-D Edison Kinetoscopic Record of a Sneeze 1894 10.5240/B1CF-7D4D-6EE3-9883-F9A7-E Rip Van Winkle 1896 10.5240/0DA5-5701-4379-AC3B-1CC2-D The Kiss 1896 10.5240/BA2A-9E43-B6B1-A6AC-4974-8 Corbett-Fitzsimmons Title Fight 1897 10.5240/CE60-6F70-BD9E-5000-20AF-U Demolishing and Building Up the Star Theatre 1901 10.5240/65B2-B45C-F31B-8BB6-7AF3-S President McKinley Inauguration Footage 1901 10.5240/C276-6C50-F95E-F5D5-8DCB-L The Great Train Robbery 1903 10.5240/7791-8534-2C23-9030-8610-5 Westinghouse Works 1904 1904 10.5240/F72F-DF8B-F0E4-C293-54EF-U A Trip Down Market Street 1906 10.5240/A2E6-ED22-1293-D668-F4AB-I Dream of a Rarebit Fiend 1906 10.5240/4D64-D9DD-7AA2-5554-1413-S San Francisco Earthquake and Fire, April 18, 1906 1906 10.5240/69AE-11AD-4663-C176-E22B-I A Corner in Wheat 1909 10.5240/5E95-74AC-CF2C-3B9C-30BC-7 Lady Helen’s Escapade 1909 10.5240/0807-6B6B-F7BA-1702-BAFC-J Princess Nicotine; or, The Smoke Fairy 1909 10.5240/C704-BD6D-0E12-719D-E093-E Jeffries-Johnson World’s Championship Boxing Contest 1910 10.5240/A8C0-4272-5D72-5611-D55A-S White Fawn’s Devotion 1910 10.5240/0132-74F5-FC39-1213-6D0D-Z Little Nemo 1911 10.5240/5A62-BCF8-51D5-64DB-1A86-H A Cure for Pokeritis 1912 10.5240/7E6A-CB37-B67E-A743-7341-L From the Manger to the Cross 1912 10.5240/5EBB-EE8A-91C0-8E48-DDA8-Q The Cry of the Children 1912 10.5240/C173-A4A7-2A2B-E702-33E8-N