Statistical Analysis for Monotonic Trends, Tech Notes 6, NNPSMP Tech Notes Is a Series of Publications That Shares This Unique November 2011
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

12.6 Sign Test (Web)
12.4 Sign test (Web) Click on 'Bookmarks' in the Left-Hand menu and then click on the required section. 12.6 Sign test (Web) 12.6.1 Introduction The Sign Test is a one sample test that compares the median of a data set with a specific target value. The Sign Test performs the same function as the One Sample Wilcoxon Test, but it does not rank data values. Without the information provided by ranking, the Sign Test is less powerful (9.4.5) than the Wilcoxon Test. However, the Sign Test is useful for problems involving 'binomial' data, where observed data values are either above or below a target value. 12.6.2 Sign Test The Sign Test aims to test whether the observed data sample has been drawn from a population that has a median value, m, that is significantly different from (or greater/less than) a specific value, mO. The hypotheses are the same as in 12.1.2. We will illustrate the use of the Sign Test in Example 12.14 by using the same data as in Example 12.2. Example 12.14 The generation times, t, (5.2.4) of ten cultures of the same micro-organisms were recorded. Time, t (hr) 6.3 4.8 7.2 5.0 6.3 4.2 8.9 4.4 5.6 9.3 The microbiologist wishes to test whether the generation time for this micro- organism is significantly greater than a specific value of 5.0 hours. See following text for calculations: In performing the Sign Test, each data value, ti, is compared with the target value, mO, using the following conditions: ti < mO replace the data value with '-' ti = mO exclude the data value ti > mO replace the data value with '+' giving the results in Table 12.14 Difference + - + ----- + - + - + + Table 12.14 Signs of Differences in Example 12.14 12.4.p1 12.4 Sign test (Web) We now calculate the values of r + = number of '+' values: r + = 6 in Example 12.14 n = total number of data values not excluded: n = 9 in Example 12.14 Decision making in this test is based on the probability of observing particular values of r + for a given value of n. -

Trend Analysis and Forecasting the Spread of COVID-19 Pandemic in Ethiopia Using Box– Jenkins Modeling Procedure
International Journal of General Medicine Dovepress open access to scientific and medical research Open Access Full Text Article ORIGINAL RESEARCH Trend Analysis and Forecasting the Spread of COVID-19 Pandemic in Ethiopia Using Box– Jenkins Modeling Procedure Yemane Asmelash Introduction: COVID-19, which causes severe acute respiratory syndrome, is spreading Gebretensae 1 rapidly across the world, and the severity of this pandemic is rising in Ethiopia. The main Daniel Asmelash 2 objective of the study was to analyze the trend and forecast the spread of COVID-19 and to develop an appropriate statistical forecast model. 1Department of Statistics, College of Natural and Computational Science, Methodology: Data on the daily spread between 13 March, 2020 and 31 August 2020 were Aksum University, Aksum, Ethiopia; collected for the development of the autoregressive integrated moving average (ARIMA) 2 Department of Clinical Chemistry, model. Stationarity testing, parameter testing and model diagnosis were performed. In School of Biomedical and Laboratory Sciences, College of Medicine and Health addition, candidate models were obtained using autocorrelation function (ACF) and partial Sciences, University of Gondar, Gondar, autocorrelation functions (PACF). Finally, the fitting, selection and prediction accuracy of the Ethiopia ARIMA models was evaluated using the RMSE and MAPE model selection criteria. Results: A total of 51,910 confirmed COVID-19 cases were reported from 13 March to 31 August 2020. The total recovered and death rates as of 31 August 2020 were 37.2% and 1.57%, respectively, with a high level of increase after the mid of August, 2020. In this study, ARIMA (0, 1, 5) and ARIMA (2, 1, 3) were finally confirmed as the optimal model for confirmed and recovered COVID-19 cases, respectively, based on lowest RMSE, MAPE and BIC values. -

An Overview of Environmental Statistics
An Overview of Environmental Statistics Richard L. Smith Department of Statistics and Operations Research University of North Carolina Chapel Hill, N.C., U.S.A. Theme Day in Environmental Statistics 55th Session of ISI Sydney, April 6, 2005 http://www.stat.unc.edu/postscript/rs/isitutorial.pdf 1 Environmental Statistics is by now an extremely broad field, in- volving application of just about every technique of statistics. Examples: • Pollution in atmosphere and water systems • Effects of pollution on human health and ecosystems • Uncertainties in forecasting climate and weather • Dynamics of ecological time series • Environmental effects on the genome and many more. 2 Some common themes: • Most problems involve time series of observations, but also spatial sampling, often involving irregular grids • Design of a spatial sampling scheme or a monitor network is important • Often the greatest interest is in extremes, for example – Air pollution standards often defined by number of cross- ings of a high threshold – Concern over impacts of climate change often focussed on climate extremes. Hence, must be able to character- ize likely frequencies of extreme events in future climate scenarios • Use of numerical models — not viewed in competition, but how we can use statistics to improve the information derived from models 3 I have chosen here to focus on three topics that have applications across several of these areas: I. Spatial and spatio-temporal statistics • Interpolation of an air pollution or meteorological field • Comparing data measured on different spatial scales • Assessing time trends in data collected on a spatial net- work II. Network design • Choosing where to place the monitors to satisfy some optimality criterion related to prediction or estimation III. -

Public Health & Intelligence
Public Health & Intelligence PHI Trend Analysis Guidance Document Control Version Version 1.5 Date Issued March 2017 Author Róisín Farrell, David Walker / HI Team Comments to [email protected] Version Date Comment Author Version 1.0 July 2016 1st version of paper David Walker, Róisín Farrell Version 1.1 August Amending format; adding Róisín Farrell 2016 sections Version 1.2 November Adding content to sections Róisín Farrell, Lee 2016 1 and 2 Barnsdale Version 1.3 November Amending as per Róisín Farrell 2016 suggestions from SAG Version 1.4 December Structural changes Róisín Farrell, Lee 2016 Barnsdale Version 1.5 March 2017 Amending as per Róisín Farrell, Lee suggestions from SAG Barnsdale Contents 1. Introduction ........................................................................................................................................... 1 2. Understanding trend data for descriptive analysis ................................................................................. 1 3. Descriptive analysis of time trends ......................................................................................................... 2 3.1 Smoothing ................................................................................................................................................ 2 3.1.1 Simple smoothing ............................................................................................................................ 2 3.1.2 Median smoothing .......................................................................................................................... -

Data Analysis Considerations in Producing 'Comparable' Information
Data Analysis Considerations in Producing ‘Comparable’ Information for Water Quality Management Purposes Lindsay Martin Griffith, Assistant Engineer, Brown and Caldwell Robert C. Ward, Professor, Colorado State University Graham B. McBride, Principal Scientist, NIWA (National Institute of Water and Atmospheric Research), Hamilton, New Zealand Jim C. Loftis, Professor, Colorado State University A report based on thesis material prepared by the lead author as part of the requirement for the degree of Master of Science from Colorado State University February 2001 ABSTRACT Water quality monitoring is being used in local, regional, and national scales to measure how water quality variables behave in the natural environment. A common problem, which arises from monitoring, is how to relate information contained in data to the information needed by water resource management for decision-making. This is generally attempted through statistical analysis of the monitoring data. However, how the selection of methods with which to routinely analyze the data affects the quality and comparability of information produced is not as well understood as may first appear. To help understand the connectivity between the selection of methods for routine data analysis and the information produced to support management, the following three tasks were performed. S An examination of the methods that are currently being used to analyze water quality monitoring data, including published criticisms of them. S An exploration of how the selection of methods to analyze water quality data can impact the comparability of information used for water quality management purposes. S Development of options by which data analysis methods employed in water quality management can be made more transparent and auditable. -

1 Sample Sign Test 1
Non-Parametric Univariate Tests: 1 Sample Sign Test 1 1 SAMPLE SIGN TEST A non-parametric equivalent of the 1 SAMPLE T-TEST. ASSUMPTIONS: Data is non-normally distributed, even after log transforming. This test makes no assumption about the shape of the population distribution, therefore this test can handle a data set that is non-symmetric, that is skewed either to the left or the right. THE POINT: The SIGN TEST simply computes a significance test of a hypothesized median value for a single data set. Like the 1 SAMPLE T-TEST you can choose whether you want to use a one-tailed or two-tailed distribution based on your hypothesis; basically, do you want to test whether the median value of the data set is equal to some hypothesized value (H0: η = ηo), or do you want to test whether it is greater (or lesser) than that value (H0: η > or < ηo). Likewise, you can choose to set confidence intervals around η at some α level and see whether ηo falls within the range. This is equivalent to the significance test, just as in any T-TEST. In English, the kind of question you would be interested in asking is whether some observation is likely to belong to some data set you already have defined. That is to say, whether the observation of interest is a typical value of that data set. Formally, you are either testing to see whether the observation is a good estimate of the median, or whether it falls within confidence levels set around that median. -

Initialization Methods for Multiple Seasonal Holt–Winters Forecasting Models
mathematics Article Initialization Methods for Multiple Seasonal Holt–Winters Forecasting Models Oscar Trull 1,* , Juan Carlos García-Díaz 1 and Alicia Troncoso 2 1 Department of Applied Statistics and Operational Research and Quality, Universitat Politècnica de València, 46022 Valencia, Spain; [email protected] 2 Department of Computer Science, Pablo de Olavide University, 41013 Sevilla, Spain; [email protected] * Correspondence: [email protected] Received: 8 January 2020; Accepted: 13 February 2020; Published: 18 February 2020 Abstract: The Holt–Winters models are one of the most popular forecasting algorithms. As well-known, these models are recursive and thus, an initialization value is needed to feed the model, being that a proper initialization of the Holt–Winters models is crucial for obtaining a good accuracy of the predictions. Moreover, the introduction of multiple seasonal Holt–Winters models requires a new development of methods for seed initialization and obtaining initial values. This work proposes new initialization methods based on the adaptation of the traditional methods developed for a single seasonality in order to include multiple seasonalities. Thus, new methods to initialize the level, trend, and seasonality in multiple seasonal Holt–Winters models are presented. These new methods are tested with an application for electricity demand in Spain and analyzed for their impact on the accuracy of forecasts. As a consequence of the analysis carried out, which initialization method to use for the level, trend, and seasonality in multiple seasonal Holt–Winters models with an additive and multiplicative trend is provided. Keywords: forecasting; multiple seasonal periods; Holt–Winters, initialization 1. Introduction Exponential smoothing methods are widely used worldwide in time series forecasting, especially in financial and energy forecasting [1,2]. -

Signed-Rank Tests for ARMA Models
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector JOURNAL OF MULTIVARIATE ANALYSIS 39, l-29 ( 1991) Time Series Analysis via Rank Order Theory: Signed-Rank Tests for ARMA Models MARC HALLIN* Universith Libre de Bruxelles, Brussels, Belgium AND MADAN L. PURI+ Indiana University Communicated by C. R. Rao An asymptotic distribution theory is developed for a general class of signed-rank serial statistics, and is then used to derive asymptotically locally optimal tests (in the maximin sense) for testing an ARMA model against other ARMA models. Special cases yield Fisher-Yates, van der Waerden, and Wilcoxon type tests. The asymptotic relative efficiencies of the proposed procedures with respect to each other, and with respect to their normal theory counterparts, are provided. Cl 1991 Academic Press. Inc. 1. INTRODUCTION 1 .l. Invariance, Ranks and Signed-Ranks Invariance arguments constitute the theoretical cornerstone of rank- based methods: whenever weaker unbiasedness or similarity properties can be considered satisfying or adequate, permutation tests, which generally follow from the usual Neyman structure arguments, are theoretically preferable to rank tests, since they are less restrictive and thus allow for more powerful results (though, of course, their practical implementation may be more problematic). Which type of ranks (signed or unsigned) should be adopted-if Received May 3, 1989; revised October 23, 1990. AMS 1980 subject cIassifications: 62Gl0, 62MlO. Key words and phrases: signed ranks, serial rank statistics, ARMA models, asymptotic relative effhziency, locally asymptotically optimal tests. *Research supported by the the Fonds National de la Recherche Scientifique and the Minist&e de la Communaute Franpaise de Belgique. -
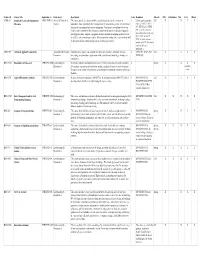
The Complete List of Courses, Including Course Descriptions, Prerequisites
Course ID Course Title Equivalent to Home Dept. Description Units Requisites Offered PhD Informatics MS Cert. Minor ACBS 513 Statistical Genetics for Quantitative ANS/GENE 513 Animal & Biomedical This course provide the student with the statistical tools to describe variation in 3 A basic genetic principles Fall X X X X Measures Sciences quantitative traits, particularly the decomposition of variation into genetic, environmental, course as ANS 213, GENE and gene by environment interaction components. Convariance (resemblance) between 433, GENE 533, or GENE relatives and heritability will be discussed, along with the topics of epistasis, oligogenic 545. A current course on and polygenic traits, complex segregation analysis, methods of mapping quantitative trait basic statistical principles as GENE 509C or MATH loci (QTL), and estimation procedures. Microarrays have multiple uses, each of which will 509C. A course in linear be discussed and the corresponding statistical analyses described. models as MATH 561 and in statistical inference mathematics. AREC 559 Advanced Applied Econometrics Agricultural & Resource Emphasis in the course is on econometric model specification, estimation, inference, 4 AREC 517, ECON 518, Fall X X X X Economics forecasting, and simulation. Applications with actual data and modeling techniques are ECON 549 emphasized. BIOS 576B Biostatistics for Research CPH/EPID 576B Epidemiology & Descriptive statistics and statistical inference relevant to biomedical research, including 3SpringXXX X Biostatistics data analysis, regression and correlation analysis, analysis of variance, survival analysis, available biological assay, statistical methods for epidemiology and statistical evaluation of clinical online literature. BIOS 576C Applied Biostatistics Analysis CPH/EPID 576C Epidemiology & Integrate methods in biostatistics (EPID 576A, B) and Epidemiology (EPID 573A, B) to 3 BIOS/EPID 576A, Fall X X X X Biostatistics develop analytical skills in an epidemiological project setting. -

6 Single Sample Methods for a Location Parameter
6 Single Sample Methods for a Location Parameter If there are serious departures from parametric test assumptions (e.g., normality or symmetry), nonparametric tests on a measure of central tendency (usually the median) are used. Recall: M is a median of a random variable X if P (X M) = P (X M) = :5. • ≤ ≥ The distribution of X is symmetric about c if P (X c x) = P (X c + x) for all x. • ≤ − ≥ For symmetric continuous distributions, the median M = the mean µ. Thus, all conclusions • about the median can also be applied to the mean. If X be a binomial random variable with parameters n and p (denoted X B(n; p)) then • n ∼ P (X = x) = px(1 p)n−x for x = 0; 1; : : : ; n x − n n! where = and k! = k(k 1)(k 2) 2 1: • x x!(n x)! − − ··· · − Tables exist for the cdf P (X x) for various choices of n and p. The probabilities and • cdf values are also easy to produce≤ using SAS or R. Thus, if X B(n; :5), we have • ∼ n P (X = x) = (:5)n x x n P (X x) = (:5)n ≤ k k X=0 P (X x) = P (X n x) because the B(n; :5) distribution is symmetric. ≤ ≥ − For sample sizes n > 20 and p = :5, a normal approximation (with continuity correction) • to the binomial probabilities is often used instead of binomial tables. (x :5) :5n { Calculate z = ± − : Use x+:5 when x < :5n and use x :5 when x > :5n. :5pn − { The value of z is compared to N(0; 1), the standard normal distribution. -

Tests of Hypotheses Using Statistics
Tests of Hypotheses Using Statistics Adam Massey¤and Steven J. Millery Mathematics Department Brown University Providence, RI 02912 Abstract We present the various methods of hypothesis testing that one typically encounters in a mathematical statistics course. The focus will be on conditions for using each test, the hypothesis tested by each test, and the appropriate (and inappropriate) ways of using each test. We conclude by summarizing the di®erent tests (what conditions must be met to use them, what the test statistic is, and what the critical region is). Contents 1 Types of Hypotheses and Test Statistics 2 1.1 Introduction . 2 1.2 Types of Hypotheses . 3 1.3 Types of Statistics . 3 2 z-Tests and t-Tests 5 2.1 Testing Means I: Large Sample Size or Known Variance . 5 2.2 Testing Means II: Small Sample Size and Unknown Variance . 9 3 Testing the Variance 12 4 Testing Proportions 13 4.1 Testing Proportions I: One Proportion . 13 4.2 Testing Proportions II: K Proportions . 15 4.3 Testing r £ c Contingency Tables . 17 4.4 Incomplete r £ c Contingency Tables Tables . 18 5 Normal Regression Analysis 19 6 Non-parametric Tests 21 6.1 Tests of Signs . 21 6.2 Tests of Ranked Signs . 22 6.3 Tests Based on Runs . 23 ¤E-mail: [email protected] yE-mail: [email protected] 1 7 Summary 26 7.1 z-tests . 26 7.2 t-tests . 27 7.3 Tests comparing means . 27 7.4 Variance Test . 28 7.5 Proportions . 28 7.6 Contingency Tables . -

Advanced Statistics for Environmental Professionals
Advanced Statistics for Environmental Professionals Bernard J. Morzuch Department of Resource Economics University of Massachusetts Amherst, Massachusetts [email protected] Table of Contents TOPIC PAGE How Does A Statistic Like A Sample Mean Behave? ................................................................................ 1 The Central Limit Theorem ........................................................................................................................ 3 The Standard Nonnal Distribution .............................................................................................................. 5 Statistical Estimation ................................................................................................................................... 5 The t-distribution ....................................................................................................................................... 13 Appearance Of The t-distribution ............................................................................................................. 14 Situation Where We Use t In Place Of z: Confidence Intervals ............................................................... 16 t-table ....................................................................................................................................................... 17 An Upper One-Sided (1-a) Confidence Interval For µ .......................................................................... 18 Another Confidence Interval Example................................................................