Download Vol 12, No 1&2, Year 2019
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introducing a Micro-Wireless Architecture for Business Activity Sensing,” Proc
Pre-print Manuscript of Article: Bridgelall, R., “Introducing a Micro-wireless Architecture for Business Activity Sensing,” Proc. IEEE International Conference on RFID, Las Vegas, NV, pp. 156-164, April 16 – 17, 2008. Introducing a Micro-wireless Architecture for Business Activity Sensing Raj Bridgelall, Senior Member, IEEE Abstract—RFID performance deficiencies discovered in architectures in a manner that enables existing application recent high profile applications have highlighted the danger of requirements to be more readily addressed. This new selecting only passive tags for an application because of their architecture also enables applications that were not lowest cost relative to other types of RFID tags. previously possible. Consequentially, battery-based RFID technologies are being considered to fill those performance gaps. A mix of both A. Passive RFID passive and battery-based RFID technologies can provide a more cost effective and robust solution than a homogeneous Passive RFID systems have improved substantially since the RFID deployment. However, it is easy to choose the wrong introduction of first generation of ultra high frequency battery-based RFID technology given the confusing array of (UHF) systems. Improvements in range and interoperability, choices currently available. This paper explores the multi-tag arbitration speed, and interference susceptibility performance deficiencies of both passive and battery-based were promised and delivered with the ratification of EPC RFID technologies. A new micro-wireless technology that Class I Generation 2 (C1G2) and the ISO 18000-6 resolves these performance deficiencies is then introduced. Finally an application example is presented that demonstrates standards [1]. Although passive UHF RFID performance how the new technology can also seamlessly roam between enhancements, cost reduction, and end-user mandates helped passive and battery-based RFID infrastructures at the lowest to improve the technology adoption rate, the level of possible cost to bridge their respective performance gaps. -

3. WIRELESS NETWORKS/WI-FI What Is a Wireless Network?
1 Technological FOUNDATIONS FOR CONVERGENCE(3) 1. Digitization/Digital Storage 2. Networking/Broadband 3. WIRELESS/WI-FI 4. SPECTRUM MANAGEMENT 3. WIRELESS NETWORKS/WI-FI What Is a Wireless Network?: The Basics http://www.cisco.com/cisco/web/solutions/small_business/resource_center/articles/w ork_from_anywhere/what_is_a_wireless_network/index.html Five Qustions to Start With What is a wireless network? How is it different from a wired network? And what are the business benefits of a wireless network? The following overview answers basic questions such as What is a wireless network?, so you can decide if one is right for your business. What Is a Wireless Network? A wireless local-area network (LAN) uses radio waves to connect devices such as laptops to the Internet and to your business network and its applications. When you connect a laptop to a WiFi hotspot at a cafe, hotel, airport lounge, or other public place, you're connecting to that business's wireless network. What Is a Wireless Network vs. a Wired Network? A wired network connects devices to the Internet or other network using cables. The most common wired networks use cables connected to Ethernet ports on the network router on one end and to a computer or other device on the cable's opposite end. What Is a Wireless Network? Catching Up with Wired Networks In the past, some believed wired networks were faster and more secure than wireless networks. But continual enhancements to wireless networking standards and technologies have eroded those speed and security differences. What Is a Wireless Network?: The Benefits Small businesses can experience many benefits from a wireless network, including: • Convenience. -

Wireless Network Communications Overview for Space Mission Operations
CCSDS Historical Document This document’s Historical status indicates that it is no longer current. It has either been replaced by a newer issue or withdrawn because it was deemed obsolete. Current CCSDS publications are maintained at the following location: http://public.ccsds.org/publications/ CCSDS HISTORICAL DOCUMENT Report Concerning Space Data System Standards WIRELESS NETWORK COMMUNICATIONS OVERVIEW FOR SPACE MISSION OPERATIONS INFORMATIONAL REPORT CCSDS 880.0-G-1 GREEN BOOK December 2010 CCSDS HISTORICAL DOCUMENT Report Concerning Space Data System Standards WIRELESS NETWORK COMMUNICATIONS OVERVIEW FOR SPACE MISSION OPERATIONS INFORMATIONAL REPORT CCSDS 880.0-G-1 GREEN BOOK December 2010 CCSDS HISTORICAL DOCUMENT CCSDS REPORT CONCERNING INTEROPERABLE WIRELESS NETWORK COMMUNICATIONS AUTHORITY Issue: Informational Report, Issue 1 Date: December 2010 Location: Washington, DC, USA This document has been approved for publication by the Management Council of the Consultative Committee for Space Data Systems (CCSDS) and reflects the consensus of technical panel experts from CCSDS Member Agencies. The procedure for review and authorization of CCSDS Reports is detailed in the Procedures Manual for the Consultative Committee for Space Data Systems. This document is published and maintained by: CCSDS Secretariat Space Communications and Navigation Office, 7L70 Space Operations Mission Directorate NASA Headquarters Washington, DC 20546-0001, USA CCSDS 880.0-G-1 Page i December 2010 CCSDS HISTORICAL DOCUMENT CCSDS REPORT CONCERNING INTEROPERABLE WIRELESS NETWORK COMMUNICATIONS FOREWORD This document is a CCSDS Informational Report, which contains background and explanatory material to support the CCSDS wireless network communications Best Practices for networked wireless communications in support of space missions. Through the process of normal evolution, it is expected that expansion, deletion, or modification of this document may occur. -

Partner Directory Wind River Partner Program
PARTNER DIRECTORY WIND RIVER PARTNER PROGRAM The Internet of Things (IoT), cloud computing, and Network Functions Virtualization are but some of the market forces at play today. These forces impact Wind River® customers in markets ranging from aerospace and defense to consumer, networking to automotive, and industrial to medical. The Wind River® edge-to-cloud portfolio of products is ideally suited to address the emerging needs of IoT, from the secure and managed intelligent devices at the edge to the gateway, into the critical network infrastructure, and up into the cloud. Wind River offers cross-architecture support. We are proud to partner with leading companies across various industries to help our mutual customers ease integration challenges; shorten development times; and provide greater functionality to their devices, systems, and networks for building IoT. With more than 200 members and still growing, Wind River has one of the embedded software industry’s largest ecosystems to complement its comprehensive portfolio. Please use this guide as a resource to identify companies that can help with your development across markets. For updates, browse our online Partner Directory. 2 | Partner Program Guide MARKET FOCUS For an alphabetical listing of all members of the *Clavister ..................................................37 Wind River Partner Program, please see the Cloudera ...................................................37 Partner Index on page 139. *Dell ..........................................................45 *EnterpriseWeb -

Ambient Intelligence
Fachbereich Informatik und Elektrotechnik AmI Ambient Intelligence Ambient Intelligence, Helmut Dispert Fachbereich Informatik und Elektrotechnik BAN – BSN - WBSN Ambient Intelligence • Body Area Network - BAN • Body Sensor Network – BSN • Wireless Body Sensor Network - WBSN Wireless body-area sensor networks (WBSNs) are key components of e-health solutions. Wearable wireless sensors can monitor and collect many different physiological parameters accurately, economically and efficiently. Ambient Intelligence, Helmut Dispert Fachbereich Informatik und Elektrotechnik BAN – BSN - WBSN Body sensing To address these issues, the concept of Body Sensor Networks (BSN) was first proposed in 2002 by Prof. Guang-Zhong Yang from Imperial College London. The aim of the BSN is to provide a truly personalised monitoring platform that is pervasive, intelligent, and invisible to the user. Example BSN system: represents a patient wearing a number of sensors on his body, each of which consists of a sensor connected to a small processor, wireless transmitter, and battery pack, forming a BSN node. The BSN node captures the sensor data, processes the data and then wirelessly transmits the information to a local processing unit, shown as a personal digital assistant (PDA) in the diagram. All this has been made possible by rapid advances in computing technology. Ambient Intelligence, Helmut Dispert Fachbereich Informatik und Elektrotechnik Literature Yang, Guang-Zhong (Ed.): Body Sensor Networks, Springer, 2006 ISBN: 978-1-84628-272-0 Ambient Intelligence, -

Requirements and Challenges in Body Sensor Networks: a Survey
Journal of Theoretical and Applied Information Technology th 20 February 2015. Vol.72 No.2 © 2005 - 2015 JATIT & LLS. All rights reserved . ISSN: 1992-8645 www.jatit.org E-ISSN: 1817-3195 REQUIREMENTS AND CHALLENGES IN BODY SENSOR NETWORKS: A SURVEY VAHID AYATOLLAHITAFTI 1,* , MD ASRI NGADI 2, AND JOHAN BIN MOHAMAD SHARIF 3 1,2,3 Department of Computing, UNIVERSITI TEKNOLOGI MALAYSIA, UTM SKUDAI, JOHOR, MALAYSIA. Email: 1,* [email protected] , [email protected] , [email protected] ABSTRACT Recent advances in wireless sensor networks have provided many opportunities for researchers on wireless networks around the body such as Body Area Network (BAN) or Body Sensor Network (BSN). A BSN allows health monitoring of patients whereby caregivers receive feedback from them without disrupting their normal activities. This monitoring requires the employment of the low-power sensor nodes implanted in or worn on the human body. This paper presents a discussion of BSNs, communication standards and their characteristics. Energy, quality of service and routing are among the crucial requirements and challenges facing BSNs which are studied. The paper also provides an investigation of many existing solutions and technologies for the challenges and requirements at physical, MAC, network, transport, and application layers. Finally, some open research issues and challenges for each layer are discussed to be addressed in further research. Keywords: BSN, energy, QoS, routing. 1. INTRODUCTION With growing the aging population and increasing costs of healthcare systems, there has been considerable motivation around human’s body to improve the quality of life, made feasible by developing miniaturized, intelligent, low-power and autonomous sensor nodes. -

Resource Management for Multimedia Services in High Data Rate Wireless Networks
SPRINGER BRIEFS IN ELECTRICAL AND COMPUTER ENGINEERING Ruonan Zhang Lin Cai Jianping Pan Resource Management for Multimedia Services in High Data Rate Wireless Networks 123 SpringerBriefs in Electrical and Computer Engineering More information about this series at http://www.springer.com/series/10059 Ruonan Zhang • Lin Cai • Jianping Pan Resource Management for Multimedia Services in High Data Rate Wireless Networks 123 Ruonan Zhang Lin Cai School of Electronics and Information Department of Electrical and Computer Northwestern Polytechnical University Engineering Xi’an, Shaanxi, China University of Victoria Victoria, British Columbia, Canada Jianping Pan Department of Computer Science University of Victoria Victoria, British Columbia, Canada ISSN 2191-8112 ISSN 2191-8120 (electronic) SpringerBriefs in Electrical and Computer Engineering ISBN 978-1-4939-6717-9 ISBN 978-1-4939-6719-3 (eBook) DOI 10.1007/978-1-4939-6719-3 Library of Congress Control Number: 2016953468 © The Author(s) 2017 This work is subject to copyright. All rights are reserved by the Publisher, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed. The use of general descriptive names, registered names, trademarks, service marks, etc. in this publication does not imply, even in the absence of a specific statement, that such names are exempt from the relevant protective laws and regulations and therefore free for general use. The publisher, the authors and the editors are safe to assume that the advice and information in this book are believed to be true and accurate at the date of publication. -
A Survey on Wireless Body Area Networks for Ehealthcare Systems in Residential Environments
A survey on wireless body area networks for eHealthcare systems in residential environments Article Accepted Version Ghamari, A., Janko, B., Sherratt, S., Harwin, W., Piechockic, R. and Soltanpur, C. (2016) A survey on wireless body area networks for eHealthcare systems in residential environments. Sensors, 16 (6). 831. ISSN 1424-8220 doi: https://doi.org/10.3390/s16060831 Available at http://centaur.reading.ac.uk/65749/ It is advisable to refer to the publisher’s version if you intend to cite from the work. See Guidance on citing . Published version at: http://www.mdpi.com/1424-8220/16/6/831 To link to this article DOI: http://dx.doi.org/10.3390/s16060831 Publisher: MDPI All outputs in CentAUR are protected by Intellectual Property Rights law, including copyright law. Copyright and IPR is retained by the creators or other copyright holders. Terms and conditions for use of this material are defined in the End User Agreement . www.reading.ac.uk/centaur CentAUR Central Archive at the University of Reading Reading’s research outputs online 1 Type of the Paper (Review) 2 A Survey on Wireless Body Area Networks for 3 eHealthcare Systems in Residential Environments 4 Mohammad Ghamari 1,*, Balazs Janko 2 , R. Simon Sherratt 2, William Harwin 2, Robert 5 Piechockic 3, Cinna Soltanpur 4 6 1 Department of Electrical and Computer Engineering, University of Texas at El Paso, El Paso, Texas, USA 7 2 School of systems engineering, University of Reading, Reading, UK 8 3 School of Electrical and Electronic Engineering, Bristol University, Bristol, UK 9 4 Department of Electrical and Computer Engineering, University of Oklahoma, Norman, Oklahoma, USA 10 * Correspondence: [email protected]; Tel.: +1-915-383-4996 11 Academic Editor: name 12 Received: date; Accepted: date; Published: date 13 Abstract: The progress in wearable and implanted health monitoring technologies has strong 14 potential to alter the future of healthcare services by enabling ubiquitous monitoring of patients. -
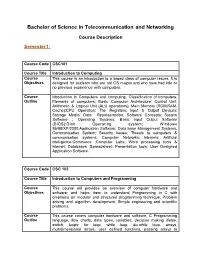
Bachelor of Science in Telecommunication and Networking
Bachelor of Science in Telecommunication and Networking Course Description Semester 1: Course Code CSC101 Course Title Introduction to Computing Course This course is an introduction to a broad class of computer issues. It is Objectives designed for students who are not CS majors and who have had little or no previous experience with computers. Course Introduction to Computers and computing; Classification of computers; Outline Elements of computers; Basic Computer Architecture; Control Unit; Arithmetic & Logical Unit (ALU operations); Main Memory (ROM,RAM, Cache);CPU Operation; The Registers; Input & Output Devices; Storage Media; Data Representation; Software Concepts; System Software ; Operating Systems; Basic Input Output Software (BIOS);Disk Operating system; Windows 95/98/XP/2000;Application Software; Data base Management Systems; Communication System; Security Issues; Threats to computers & communication systems; Computer Networks; Internets; Artificial Intelligence-Commerce ;Computer Labs; Word processing tools & Internet; Databases ;Spreadsheet; Presentation tools; User Designed Application Software. Course Code CSC 103 Course Title Introduction to Computers and Programming Course This course will provides an overview of computer hardware and Objectives software; and helps them to understand Programming in C with emphasis on modular and structured programming technique; Problem solving and algorithm development; Simple engineering and scientific problems. Course This course covers computer hardware and software, C Programming -

WO 2013/155199 Al 17 October 2013 (17.10.2013) P O P C T
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization International Bureau (10) International Publication Number (43) International Publication Date WO 2013/155199 Al 17 October 2013 (17.10.2013) P O P C T (51) International Patent Classification: ton 981 15 (US). HAWKINS, Daniel; 5563 156th Avenue A61M 35/00 (2006.01) A61B 5/00 (2006.01) SE, Bellevue, Washington 98006 (US). HYDE, Roderick, A.; 9915 - 161st Avenue N.E., Redmond, Washington (21) International Application Number: 98052 (US). KARE, Jordin, T.; 908 15th Ave. East, PCT/US20 13/036000 Seattle, Washington 981 12 (US). LEUTHARDT, Eric, (22) International Filing Date: C ; 6358 Pershing Avenue, St. Louis, Missouri 63 130 10 April 2013 (10.04.2013) (US). SCHUBERT, Elizabeth, L.; 6728 128th Avenue SE, Bellevue, Washington 98006 (US). TEGREENE, (25) Filing Language: English Clarence, T.; 5910 E Mercer Way, Mercer Island, Wash (26) Publication Language: English ington 98040 (US). WOOD, JR., Lowell, L.; 989 112th Avenue NE #23 10, Bellevue, Washington 98004 (US). (30) Priority Data: 13/445,174 12 April 2012 (12.04.2012) US (74) Agents: MALASKA, Stephen, L. et al; 11235 SE 6th 13/445,220 12 April 2012 (12.04.2012) US Street, Suite 200, Bellevue, Washington 98004-6841 (US). 13/491,677 8 June 2012 (08.06.2012) US (81) Designated States (unless otherwise indicated, for every 13/795,667 12 March 2013 (12.03.2013) US kind of national protection available): AE, AG, AL, AM, (71) Applicant: ELWHA LLC [US/US]; 11235 SE 6th Street, AO, AT, AU, AZ, BA, BB, BG, BH, BN, BR, BW, BY, Suite 200, Bellevue, Washington 98004-6481 (US). -

Lorawan Battery-Free Wireless Sensors Network Designed for Structural Health Monitoring in the Construction Domain
sensors Article LoRaWAN Battery-Free Wireless Sensors Network Designed for Structural Health Monitoring in the Construction Domain Gaël Loubet 1,* , Alexandru Takacs 1, Ethan Gardner 2 , Andrea De Luca 2 , Florin Udrea 2 and Daniela Dragomirescu 1 1 LAAS-CNRS, Université de Toulouse, CNRS, INSA, UPS, 31400 Toulouse, France; [email protected] (A.T.); [email protected] (D.D.) 2 Department of Engineering, University of Cambridge, Cambridge CB3 0FF, UK; [email protected] (E.G.); [email protected] (A.D.L.); [email protected] (F.U.) * Correspondence: [email protected] Received: 25 January 2019; Accepted: 21 March 2019; Published: 28 March 2019 Abstract: This paper addresses the practical implementation of a wireless sensors network designed to actualize cyber-physical systems that are dedicated to structural health monitoring applications in the construction domain. This network consists of a mesh grid composed of LoRaWAN battery-free wireless sensing nodes that collect physical data and communicating nodes that interface the sensing nodes with the digital world through the Internet. Two prototypes of sensing nodes were manufactured and are powered wirelessly by using a far-field wireless power transmission technique and only one dedicated RF energy source operating in the ISM 868 MHz frequency band. These sensing nodes can simultaneously perform temperature and relative humidity measurements and can transmit the measured data wirelessly over long-range distances by using the LoRa technology and the LoRaWAN protocol. Experimental results for a simplified network confirm that the periodicity of the measurements and data transmission of the sensing nodes can be controlled by the dedicated RF source (embedded in or just controlled by the associated communicating node), by tuning the radiated power density of the RF waves, and without any modification of the software or the hardware implemented in the sensing nodes. -

Technological and Educational Institute of Central Macedonia School of Technological Applications Department of Engineering Informatics
Technological and Educational Institute of Central Macedonia School of Technological Applications Department of Engineering Informatics Master’s thesis on Medium Access Control (MAC) Standards for Wireless Body Area Networks (WBANs) and Security Considerations Kiriakos Gavouchidis In partial fulfillment of the requirements for the degree of Master of Science in Communication and Information Systems Supervisor: Dr. Dimitrios Efstathiou March, 2016 Copyright © 2016 Kiriakos Gavouchidis 2 Acknowledgment A big Efxaristo (Thank you) to my supervisor, Assistant Prof. Efstathiou for the chance he gave me to write this Master Thesis in this very interesting and exciting area. He is always there, for help, for advice, for criticism, and feedback. With patience, and insightful. With encouragement, enthusiasm and many ideas. Thank you. 3 Abstract WBANs are a key element to the ubiquitous healthcare revolution. From the communication point of view, they are one of the most challenging elements for this application and also other application areas such as military, sport, or entertainment. New applications and requirements force the development of the WBAN technology, e.g. the MAC sublayer protocol and its existing and future standards. Every standard described in this Master Thesis represents an evolution of the previous standard according to the application needs with the goal to find solutions for the existing challenges in WBANs. One main issue in WBANs is to minimize energy consumption due to the fact that the nodes may be implanted in the human body, so batteries can not be replaced after a small time period. Minimal energy consumption is a critical factor for the survive of WBAN technology.