Semantically Partitioned Complex Event Processing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Huiswerk Linux: Sendmail Virtual User Instellen
Huiswerk Linux: Sendmail virtual user instellen Als professioneel administrator wil je zo min mogelijk gebruikers op je Linux machine hebben. Echte Linux gebruikers hebben login-rechten op jouw server en kunnen schade aanrichten op jouw machine. Het is in de meeste gevallen niet nodig om voor iedere klant een gebruikersaccount aan te maken. De meeste klanten willen alleen dat hun e-mail werkt. De opdracht voor deze week is: maak een virtual user voor het testdomein.nl aan. Over virtual users Het nadeel van het instellen van Virtual Hosts is dat alle gebruikers geldig zijn voor ieder e-mail domein dat je aanmaakt. Stel dat je een e-mail domein ( virtual host ) voor een klant aanmaakt, zodat zij e-mail kan ontvangen via dit domein. Dit betekent dat andere gebruikers ook e-mail kunnen ontvangen voor datzelfde domein. Dit veroorzaakt veel extra spam. Het handige van virtual users is dat ze alleen bestaan voor het domein waarvoor ze zijn aangemaakt. Het sudo mechanisme Het configureren van Linux doen we namens de super-user . We moeten daarom tijdelijk inloggen als Administrator. Cygwin gebruikers Andere Linux gebruikers Sudo voor Cygwin gebruikers: rechts-klik op het icoon van de Sudo voor gebruikers van andere Linux-versies ( Ubuntu , Cygwin terminal, en kies voor Als administrator uitvoeren . Lubuntu , Kubuntu , Android , Gentoo , Debian , etc): start een Zorg er ook voor dat de Sendmail daemon is gestart: terminal met de toetsencombinatie <Ctrl><Alt>-T. We gebruiken het commando sudo om in te loggen met het su service sendmail start (become Super User) commando. Daardoor blijven we ingelogd: sudo su Feature controleren Sendmail wordt geconfigureerd via het bestand /etc/mail/sendmail.cf . -

The Art of Unix Programming Next the Art of Unix Programming
The Art of Unix Programming Next The Art of Unix Programming Eric Steven Raymond Thyrsus Enterprises <[email protected]> Copyright © 2003 Eric S. Raymond Revision History Revision 0.0 1999 esr Public HTML draft, first four chapters only. Revision 0.1 16 November 2002 esr First DocBook draft, fifteen chapters. Released to Mark Taub at AW. Revision 0.2 2 January 2003 esr First manuscript walkthrough at Chapter 7. Released to Dmitry Kirsanov at AW production. Revision 0.3 22 January 2003 esr First eighteen-chapter draft. Manuscript walkthrough at Chapter 12. Limited release for early reviewers. Revision 0.4 5 February 2003 esr Release for public review. Revision 0.41 11 February 2003 esr Corrections and additions to Mac OS case study. A bit more about binary files as caches. Added cite of Butler Lampson. Additions to history chapter. Note in futures chapter about C and exceptions. Many typo fixes. Revision 0.42 12 February 2003 esr Add fcntl/ioctl to things Unix got wrong. Dedication To Ken Thompson and Dennis Ritchie, because you inspired me. Table of Contents Requests for reviewers and copy-editors Preface Who Should Read This Book How To Use This Book Related References Conventions Used In This Book Our Case Studies Author's Acknowledgements I. Context 1. Philosophy Culture? What culture? The durability of Unix The case against learning Unix culture What Unix gets wrong What Unix gets right Open-source software Cross-platform portability and open standards The Internet The open-source community Flexibility in depth Unix is fun to hack The lessons of Unix can be applied elsewhere Basics of the Unix philosophy Rule of Modularity: Write simple parts connected by clean interfaces. -

The Healthy Programmer - Get Fit
Early praise for The Healthy Programmer Joe Kutner offers practical, readable, and well-researched advice for those who sit at a keyboard. I’ve incorporated his health-and-fitness regimen into my writing routine. ➤ Dr. Steve Overman Professor of Physical Education (retired), Jackson State University Health and programming should go together like a horse and carriage. You can’t have one without the other. In our sedentary office work, we often forget that an absence of health is as bad as a lack of programming skills. Joe points out a dozen areas where you and I can do better. Every office worker should read this book and self-reflect on health improvements. ➤ Staffan Nöteberg Author of Pomodoro Technique Illustrated This book introduced me to the term conditioned hypereating. It felt life-changing. Being aware of this has made it easier to experiment with smaller, less-ambitious changes that actually have a chance at succeeding. I’m very curious to see where this puts me a year from now. ➤ Katrina Owen Developer, Jumpstart Lab The Healthy Programmer is excellent. In many ways it’s a spiritual continuation of The Hacker’s Diet. ➤ Stephen Ball Senior Rails programmer, PhishMe, Inc. The Healthy Programmer Get Fit, Feel Better, and Keep Coding Joe Kutner The Pragmatic Bookshelf Dallas, Texas • Raleigh, North Carolina Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and The Pragmatic Programmers, LLC was aware of a trademark claim, the designations have been printed in initial capital letters or in all capitals. -

INSIDE HORTON, KANSAS Special Tax Hometown of Section Kevin & Included in Angela Strube Holton Recorder Subscribers This Edition
SALUTE TON INSIDE HORTON, KANSAS Special tax Hometown of section Kevin & included in Angela Strube Holton Recorder subscribers this edition. for 30 years. CSerin te acson County Community for years See pages 8-9. Volume 153, Issue 6 HOLTON, KANSAS • Wednesday, January 22, 2020 14 Pages $1.00 Livestock Expo is Saturday In previous years, Holton veterinarian Tim Parks was one of the fea tured presenters at the Jackson Coun ty Livestock Association’s annual Livestock Exposition. This year, Parks — who owned and operated Heartland Veterinary Clinic in Holton from 1998 to 2015 — will be the featured speaker at the 35thannual Livestock Expo, set for this District court cases Saturday at the Northeast Kansas Heritage Complex south of down about 24 percent Holton. Doors to the Heritage By Brian Sanders Much of the decrease Complex’s exhibition hall will After seeing a dramatic in the 2019 total could open at 5 p.m. for the expo’s rise from 2017 to 2018 be found in the number steak dinner, which will be in the number of cases of criminal misdemeanor served from 5:30 p.m. to 7 p.m. handled in Jackson County cases — 187, which was The program will begin District Court, 2019 was less than half of the 2018 at 6 p.m. and feature Parks, a somewhat quieter year total of 411 misdemeanors representing Mer ck Animal in comparison, thanks in handled by court personnel. Health. The program will also part to sizable decreases Felony cases were up feature the announcement of in criminal misdemeanor slightly, from 294 in 2018 JCLA’s Distinguished Stockman filings and traffic tickets. -
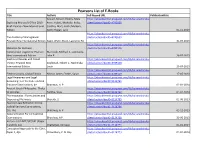
Pearsons List of E-Books
Pearsons List of E-Books Title Authors Full Record URL PublicationDate Grauer, Robert; Poatsy, Mary https://ebookcentral.proquest.com/lib/banarashinduu Exploring Microsoft Office 2010 Anne; Hulett, Michelle; Krebs, /detail.action?docID=4742025 Brief: Pearson New International Cynthia; Mast, Keith; Mulbery, Edition Keith; Hogan, Lynn 01-11-2013 https://ebookcentral.proquest.com/lib/banarashinduu The Anatomy Coloring Book: /detail.action?docID=4742630 Pearson New International Edition Kapit, Wynn; Elson, Lawrence M. 31-07-2013 https://ebookcentral.proquest.com/lib/banarashinduu Materials for Civil and /detail.action?docID=4789156 Construction Engineers: Pearson Mamlouk, Michael S.; Zaniewski, New International Edition John P. 26-07-2013 Electronic Devices and Circuit https://ebookcentral.proquest.com/lib/banarashinduu Theory: Pearson New Boylestad, Robert L.; Nashelsky, /detail.action?docID=4789158 International Edition Louis 23-07-2013 https://ebookcentral.proquest.com/lib/banarashinduu Electric Circuits, Global Edition Nilsson James; Riedel, Susan /detail.action?docID=4789159 17-05-2013 Legal Awareness and Legal https://ebookcentral.proquest.com/lib/banarashinduu Reasoning : For the CLAT and LLB /detail.action?docID=5124761 Entrance Examinations, 4e Bhardwaj, A. P. 01-01-2014 Ancient Greek Philosophy : Thales https://ebookcentral.proquest.com/lib/banarashinduu to Socrates Tankha, Vijay /detail.action?docID=5124762 01-01-2014 Pharmaceutics : Formulations and https://ebookcentral.proquest.com/lib/banarashinduu Dispensing Pharmacy Bharath, S. /detail.action?docID=5124765 01-06-2013 Pearson Legal Refresher for the https://ebookcentral.proquest.com/lib/banarashinduu Judicial Services Examinations, /detail.action?docID=5124766 2/e, The Bhardwaj, A. P. 01-12-2013 General English For Competitive https://ebookcentral.proquest.com/lib/banarashinduu Examinations Bhardwaj, A.P. -

I, NILES HERALD-SPECFATOR
i,NILES HERALD-SPECFATOR M Hon. M Loci NEwsSiNCE1951. Thursda. \ovcniber 6. 2tJI- nikssuntm.curn WRAP?OFffS compar3' cHIcM1OSL:N-ur GO Ringling Bros. pitches its tents in the Chicago I area for a month's stay beginning today. Diabetes Awareness SEE S1LCIAE SECTION INSIDE Nues voters take away mayor's power to fill trustee vacancies I PAGE 6 Nues Herald-Spectator ©2014 Sun-Times Media All rights reserved I VISA PLATINUM :8.95% APR* Get 2,500 honu reward points. The perfect card for every hoIiday -i: T1i Sfl1N sZOCvorLO9 h 09b9 nwccu.com i847i647u1O3C Is a 8930 1ukeqr Rd. Morton Grove IL F.iOO5 ¿?:000Do 3.Sitl güOOO 6TO_Dp4Ol ThURSDAY NOVEMBER 6 2014 A PIONEER PRESS PUBUCATION NIL LAKESHORE Recycling Systems Proudly serving Chica goland since 1999 Recyàling NIL A PIONEER PRESS PUBUCATION THURSDAY NOVEMBER 6 2014 mrsteam is my happy place... BANNER KITCHEN & BATH SHOWROOM Visit our luxury showroom at: 1020 East Lake Cook Roads Buffalo Grove . 847.520.6100BannerPlumbing.com 4 THURSDAY, NOVEMBER 6, 2014 A PIONEER PRESS PUBLICATION NIL I NILES HERALD -SPECTATOR BAZAARS Ms Hoprg. Ms LOCAL Ntows SulcE 1951. Holiday shopping Gift ideas abound at TiuOThY P. Knight CEO holiday boutiques John Pide Jill McDermott PAGE 42 Editor VP of Advertising 847-682-5907 ADVflSINO Rsckre News Editor kuIiuvs&Advertising Director 312-321-2259 312-646-9552 [email protected] [email protected] Ryzi Ilium. Managing Editor for Sports Diby 847-486-9200 312-321-2694 Uassifleé 847-486-9200 milsson@pioneerlocaLcom E [email protected] Lipis: [email protected] suntïmesreprints.com I ObiIuauies: 847-998-3400, option 6, or [email protected] pioneerlocal.mycapture.com SERVICE & NEW SUBSCRIBS MAILING ADDRESS P1)001: 877-855-7722 350 N. -
Practices of an Agile Developer
Prepared exclusively for Elliot Soloway What readers are saying about Practices of an Agile Developer The “What It Feels Like” sections are just gold—it’s one thing to tell someone to do this; it’s quite another to put it into practice and know you’re doing it right. Nathaniel T. Schutta Coauthor, Foundations of Ajax The book is what I’ve come to expect from the Pragmatic Bookshelf: short, easy to read, to the point, deep, insightful and useful. It should be a valuable resource for people wanting to do “agile.” Forrest Chang Software Lead When I started reading Practices of an Agile Developer, I kept thinking, “Wow, a lot of developers need this book.” It did not take long to real- ize that I needed this book. I highly recommend it to developers of all experience levels. Guerry A. Semones Senior Software Engineer, Appistry Practices of an Agile Developer uses common sense and experience to illustrate why you should consider adopting agile practices on your projects. This is precisely the kind of real-world, experiential informa- tion that is most difficult to glean from a book. Matthew Johnson Principal Software Engineer Prepared exclusively for Elliot Soloway I was familiar with some of the practices mentioned since I own other books from the Pragmatic Bookshelf, but this book brings a lot of those ideas together and presents them in a clear, concise, organized format. I would highly recommend this book to a new developer or to a development team that wanted to get “agile.” Scott Splavec Senior Software Engineer With agile practices spreading across the industry, there is a growing need to understand what it really means to be “agile.” This book is a concise and practical guide to becoming just that. -

Announcement
Announcement 49 articles, 2016-07-02 18:00 1 Microsoft Paid Too Much for LinkedIn Due to Bidding War with Salesforce, Google Redmond is paying $$26.2 billion for LinkedIn 2016-07-02 10:34 2KB (1.02/2) news.softpedia.com 2 Advanced Concepts of Java Object Serialization Probe serialization and its related concepts and learn to delineate (0.03/2) some of its nooks and crannies, along with their implementation in the Java API. 2016-07-02 00:00 7KB www.developer.com 3 Understanding Gradle, the Android Build System Review the basics of Gradle, the Android Build System. (0.01/2) 2016-07-02 00:00 2KB www.developer.com 4 Using the Executor Framework to Deal with Java Threads Examine the Java core framework and its uses with a little (0.01/2) background idea to begin with. 2016-07-02 00:00 6KB www.developer.com 5 Twilio IPO May Be Key Indicator for Other Unicorns in 2016 NEWS ANALYSIS: A good response from investors June 23 could help determine whether companies such as Dropbox, Uber and others decide to test the waters this year. 2016-07-02 13:36 4KB www.eweek.com 6 Microsoft Streamlines Visual Studio Installation Microsoft is refactoring its Visual Studio installation to be smaller, faster, more reliable and easier to manage. 2016-07-02 13:36 5KB www.eweek.com 7 Eclipse Foundation Ships Neon Release Train The Eclipse Foundation shipped its eleventh annual release train, featuring 84 projects and 69 million lines of code from nearly 800 developers. -

Installation
List Wrangler - Email Mailing List Manager for GTK+ By Frank Cox September 3, 2012 [email protected] Abstract Do you have a mailing list of people that you send periodic emails to? If so, List Wrangler is the program that you need to manage your mailing list and send out the emails. I maintain an email mailing list of people who want to be notiied when a new movie is booked at my movie theatre. I wrote List Wrangler for the purpose of managing that mailing list, and also as a way to learn GTK+ programming. This is my rst graphical program. Though I have been writing programs for several decades on a lot of dierent computers, everything I've written prior to this point has been text mode (ncurses and the like) or utility programs that don't have any user interface at all. Part I Installation 1 Requirements List Wrangler is a self-contained program that consists entirely of one single binary le. However, there are a few other things that must also be installed on your computer before it will actually work as intended. Since this is a GTK+ program, you must, of course, have GTK+ installed on your computer. I created this program using GTK2-2.18.9 on a Centos 6 computer. I have no idea how well it will work (if at all) on a computer that uses GTK+ version 3 since I don't currently have one of those. The program uses the SQLite database engine to handle the record-keeping functions so you will also need to have SQLite installed on your computer. -

Huiswerk Linux: Instellen Virtual Host
Huiswerk Linux: Instellen virtual host Professionele Internet Service Providers (ISPs) beheren grote hoeveelheden domeinnamen. E-mail naar deze domeinen wordt in principe door een enkele server verwerkt. De opdracht voor deze week is: configureer Sendmail zodanig dat ook e-mail van andere domeinen kan worden ontvangen. Het sudo mechanisme Het configureren van Linux doen we namens de super-user . We moeten daarom tijdelijk inloggen als Administrator. Cygwin gebruikers Andere Linux gebruikers Sudo voor Cygwin gebruikers: rechts-klik op het icoon van de Sudo voor gebruikers van andere Linux-versies ( Ubuntu , Cygwin terminal, en kies voor Als administrator uitvoeren . Lubuntu , Kubuntu , Android , Gentoo , Debian , etc): start een Zorg er ook voor dat de Sendmail daemon is gestart: terminal met de toetsencombinatie <Ctrl><Alt>-T. We gebruiken het commando sudo om in te loggen met het su service sendmail start (become Super User) commando. Daardoor blijven we ingelogd: sudo su Virtual host instellen Sendmail ontvangt standaard alleen e-mail voor het domein waarin je machine zich bevindt. Als je wilt dat e-mail voor een ander domein geaccepteerd word, moet je dat aangeven in het local-host- names bestandje. Open dit met de vi tekst-editor: vi /etc/mail/local-host-names Dit bestand ziet er per Linux versie verschillend uit, maar de instellingen zijn hetzelfde. Toets i (insert) om naar de INSERT modus te gaan en voeg de volgende regel toe: testdomein.nl Toets <Esc> om uit de INSERT modus te komen en geef de commando’s w (write) en q (quit): :wq Het bestand wordt nu opgeslagen en we zijn terug op de command-line. -

Software Design Pattern 1 Software Design Pattern
Software design pattern 1 Software design pattern In software engineering, a software design pattern is a general, reusable solution to a commonly occurring problem within a given context in software design. It is not a finished design that can be transformed directly into source or machine code. Rather, it is a description or template for how to solve a problem that can be used in many different situations. Design patterns are formalized best practices that the programmer can use to solve common problems when designing an application or system. Object-oriented design patterns typically show relationships and interactions between classes or objects, without specifying the final application classes or objects that are involved. Patterns that imply mutable state may be unsuited for functional programming languages, some patterns can be rendered unnecessary in languages that have built-in support for solving the problem they are trying to solve, and object-oriented patterns are not necessarily suitable for non-object-oriented languages. Design patterns may be viewed as a structured approach to computer programming intermediate between the levels of a programming paradigm and a concrete algorithm. History Patterns originated as an architectural concept by Christopher Alexander as early as 1966 (c.f. "The Pattern of Streets," JOURNAL OF THE AIP, September, 1966, Vol. 32, No. 3, pp. 273-278). In 1987, Kent Beck and Ward Cunningham began experimenting with the idea of applying patterns to programming – specifically pattern languages – and presented their results at the OOPSLA conference that year. In the following years, Beck, Cunningham and others followed up on this work. -

Ausgabe 06/2014 Als
freiesMagazin Juni 2014 Topthemen dieser Ausgabe Ubuntu und Kubuntu 14.04 LTS Seite 3 Ubuntu 14.04 LTS „Trusty Tahr“ ist die neue, fünf Jahre lang unterstützte Version von Ubuntu. Der Artikel soll helfen, zu entscheiden, ob es sich lohnt, die nächsten fünf Jahre auf „Trusty Tahr“ zu setzen. Daneben wird auch noch ein Blick auf Kubuntu, das KDE als Desktop-Umgebung einsetzt, geworfen. (weiterlesen) GPS: Tracks und Routen erstellen mit QLandkarte GT Seite 10 Mit dem Programm QLandkarte GT ist es möglich, auf der Grundlage der Karten von Open- StreetMap Tracks und Routen zu generieren und diese auf ein GPS-Gerät zu exportieren. Die Möglichkeiten der Software sind sehr vielfältig, deshalb erschließen sich dem Einsteiger nicht sofort die wichtigsten Funktionen. Ziel des Artikels ist es deshalb, dem Neuling einen schnellen Einstieg zu verschaffen. (weiterlesen) Professionelles Database Publishing Seite 21 Es gibt eine Reihe von Dokumenten, die sich nur schwer mit freier Software erstellen lassen. Für normale Texte wie Bücher oder Abschlussarbeiten gibt es LibreOffice und LATEX, für Zeitschrif- tensatz (DTP) gibt es beispielsweise Scribus. Doch vollautomatisch aus Datenbanken erzeugte Dokumente lassen sich oft nur schwer mit den genannten Programmen erzeugen. Hier soll der „speedata Publisher“ helfen, der in diesem Artikel vorgestellt wird. (weiterlesen) © freiesMagazin CC-BY-SA 4.0 Ausgabe 06/2014 ISSN 1867-7991 MAGAZIN Editorial Icon-Wettbewerb tikels geht. Als Layouter muss man die Bilder an Inhalt Wir haben Anfang Mai einen kleinen Wettbewerb die richtige Stelle im Text setzen und, um schöne Linux allgemein ausgeschrieben, bei dem es darum ging, neue Umbrüche oder Textverteilung zu erreichen, auch Ubuntu und Kubuntu 14.04 LTS S.