Matrix Algebra for Beginners, Part I Matrices, Determinants, Inverses
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introduction to Linear Bialgebra
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by University of New Mexico University of New Mexico UNM Digital Repository Mathematics and Statistics Faculty and Staff Publications Academic Department Resources 2005 INTRODUCTION TO LINEAR BIALGEBRA Florentin Smarandache University of New Mexico, [email protected] W.B. Vasantha Kandasamy K. Ilanthenral Follow this and additional works at: https://digitalrepository.unm.edu/math_fsp Part of the Algebra Commons, Analysis Commons, Discrete Mathematics and Combinatorics Commons, and the Other Mathematics Commons Recommended Citation Smarandache, Florentin; W.B. Vasantha Kandasamy; and K. Ilanthenral. "INTRODUCTION TO LINEAR BIALGEBRA." (2005). https://digitalrepository.unm.edu/math_fsp/232 This Book is brought to you for free and open access by the Academic Department Resources at UNM Digital Repository. It has been accepted for inclusion in Mathematics and Statistics Faculty and Staff Publications by an authorized administrator of UNM Digital Repository. For more information, please contact [email protected], [email protected], [email protected]. INTRODUCTION TO LINEAR BIALGEBRA W. B. Vasantha Kandasamy Department of Mathematics Indian Institute of Technology, Madras Chennai – 600036, India e-mail: [email protected] web: http://mat.iitm.ac.in/~wbv Florentin Smarandache Department of Mathematics University of New Mexico Gallup, NM 87301, USA e-mail: [email protected] K. Ilanthenral Editor, Maths Tiger, Quarterly Journal Flat No.11, Mayura Park, 16, Kazhikundram Main Road, Tharamani, Chennai – 600 113, India e-mail: [email protected] HEXIS Phoenix, Arizona 2005 1 This book can be ordered in a paper bound reprint from: Books on Demand ProQuest Information & Learning (University of Microfilm International) 300 N. -

Lesson 2: the Multiplication of Polynomials
NYS COMMON CORE MATHEMATICS CURRICULUM Lesson 2 M1 ALGEBRA II Lesson 2: The Multiplication of Polynomials Student Outcomes . Students develop the distributive property for application to polynomial multiplication. Students connect multiplication of polynomials with multiplication of multi-digit integers. Lesson Notes This lesson begins to address standards A-SSE.A.2 and A-APR.C.4 directly and provides opportunities for students to practice MP.7 and MP.8. The work is scaffolded to allow students to discern patterns in repeated calculations, leading to some general polynomial identities that are explored further in the remaining lessons of this module. As in the last lesson, if students struggle with this lesson, they may need to review concepts covered in previous grades, such as: The connection between area properties and the distributive property: Grade 7, Module 6, Lesson 21. Introduction to the table method of multiplying polynomials: Algebra I, Module 1, Lesson 9. Multiplying polynomials (in the context of quadratics): Algebra I, Module 4, Lessons 1 and 2. Since division is the inverse operation of multiplication, it is important to make sure that your students understand how to multiply polynomials before moving on to division of polynomials in Lesson 3 of this module. In Lesson 3, division is explored using the reverse tabular method, so it is important for students to work through the table diagrams in this lesson to prepare them for the upcoming work. There continues to be a sharp distinction in this curriculum between justification and proof, such as justifying the identity (푎 + 푏)2 = 푎2 + 2푎푏 + 푏 using area properties and proving the identity using the distributive property. -

21. Orthonormal Bases
21. Orthonormal Bases The canonical/standard basis 011 001 001 B C B C B C B0C B1C B0C e1 = B.C ; e2 = B.C ; : : : ; en = B.C B.C B.C B.C @.A @.A @.A 0 0 1 has many useful properties. • Each of the standard basis vectors has unit length: q p T jjeijj = ei ei = ei ei = 1: • The standard basis vectors are orthogonal (in other words, at right angles or perpendicular). T ei ej = ei ej = 0 when i 6= j This is summarized by ( 1 i = j eT e = δ = ; i j ij 0 i 6= j where δij is the Kronecker delta. Notice that the Kronecker delta gives the entries of the identity matrix. Given column vectors v and w, we have seen that the dot product v w is the same as the matrix multiplication vT w. This is the inner product on n T R . We can also form the outer product vw , which gives a square matrix. 1 The outer product on the standard basis vectors is interesting. Set T Π1 = e1e1 011 B C B0C = B.C 1 0 ::: 0 B.C @.A 0 01 0 ::: 01 B C B0 0 ::: 0C = B. .C B. .C @. .A 0 0 ::: 0 . T Πn = enen 001 B C B0C = B.C 0 0 ::: 1 B.C @.A 1 00 0 ::: 01 B C B0 0 ::: 0C = B. .C B. .C @. .A 0 0 ::: 1 In short, Πi is the diagonal square matrix with a 1 in the ith diagonal position and zeros everywhere else. -

What's in a Name? the Matrix As an Introduction to Mathematics
St. John Fisher College Fisher Digital Publications Mathematical and Computing Sciences Faculty/Staff Publications Mathematical and Computing Sciences 9-2008 What's in a Name? The Matrix as an Introduction to Mathematics Kris H. Green St. John Fisher College, [email protected] Follow this and additional works at: https://fisherpub.sjfc.edu/math_facpub Part of the Mathematics Commons How has open access to Fisher Digital Publications benefited ou?y Publication Information Green, Kris H. (2008). "What's in a Name? The Matrix as an Introduction to Mathematics." Math Horizons 16.1, 18-21. Please note that the Publication Information provides general citation information and may not be appropriate for your discipline. To receive help in creating a citation based on your discipline, please visit http://libguides.sjfc.edu/citations. This document is posted at https://fisherpub.sjfc.edu/math_facpub/12 and is brought to you for free and open access by Fisher Digital Publications at St. John Fisher College. For more information, please contact [email protected]. What's in a Name? The Matrix as an Introduction to Mathematics Abstract In lieu of an abstract, here is the article's first paragraph: In my classes on the nature of scientific thought, I have often used the movie The Matrix to illustrate the nature of evidence and how it shapes the reality we perceive (or think we perceive). As a mathematician, I usually field questions elatedr to the movie whenever the subject of linear algebra arises, since this field is the study of matrices and their properties. So it is natural to ask, why does the movie title reference a mathematical object? Disciplines Mathematics Comments Article copyright 2008 by Math Horizons. -

Multivector Differentiation and Linear Algebra 0.5Cm 17Th Santaló
Multivector differentiation and Linear Algebra 17th Santalo´ Summer School 2016, Santander Joan Lasenby Signal Processing Group, Engineering Department, Cambridge, UK and Trinity College Cambridge [email protected], www-sigproc.eng.cam.ac.uk/ s jl 23 August 2016 1 / 78 Examples of differentiation wrt multivectors. Linear Algebra: matrices and tensors as linear functions mapping between elements of the algebra. Functional Differentiation: very briefly... Summary Overview The Multivector Derivative. 2 / 78 Linear Algebra: matrices and tensors as linear functions mapping between elements of the algebra. Functional Differentiation: very briefly... Summary Overview The Multivector Derivative. Examples of differentiation wrt multivectors. 3 / 78 Functional Differentiation: very briefly... Summary Overview The Multivector Derivative. Examples of differentiation wrt multivectors. Linear Algebra: matrices and tensors as linear functions mapping between elements of the algebra. 4 / 78 Summary Overview The Multivector Derivative. Examples of differentiation wrt multivectors. Linear Algebra: matrices and tensors as linear functions mapping between elements of the algebra. Functional Differentiation: very briefly... 5 / 78 Overview The Multivector Derivative. Examples of differentiation wrt multivectors. Linear Algebra: matrices and tensors as linear functions mapping between elements of the algebra. Functional Differentiation: very briefly... Summary 6 / 78 We now want to generalise this idea to enable us to find the derivative of F(X), in the A ‘direction’ – where X is a general mixed grade multivector (so F(X) is a general multivector valued function of X). Let us use ∗ to denote taking the scalar part, ie P ∗ Q ≡ hPQi. Then, provided A has same grades as X, it makes sense to define: F(X + tA) − F(X) A ∗ ¶XF(X) = lim t!0 t The Multivector Derivative Recall our definition of the directional derivative in the a direction F(x + ea) − F(x) a·r F(x) = lim e!0 e 7 / 78 Let us use ∗ to denote taking the scalar part, ie P ∗ Q ≡ hPQi. -

Algebra of Linear Transformations and Matrices Math 130 Linear Algebra
Then the two compositions are 0 −1 1 0 0 1 BA = = 1 0 0 −1 1 0 Algebra of linear transformations and 1 0 0 −1 0 −1 AB = = matrices 0 −1 1 0 −1 0 Math 130 Linear Algebra D Joyce, Fall 2013 The products aren't the same. You can perform these on physical objects. Take We've looked at the operations of addition and a book. First rotate it 90◦ then flip it over. Start scalar multiplication on linear transformations and again but flip first then rotate 90◦. The book ends used them to define addition and scalar multipli- up in different orientations. cation on matrices. For a given basis β on V and another basis γ on W , we have an isomorphism Matrix multiplication is associative. Al- γ ' φβ : Hom(V; W ) ! Mm×n of vector spaces which though it's not commutative, it is associative. assigns to a linear transformation T : V ! W its That's because it corresponds to composition of γ standard matrix [T ]β. functions, and that's associative. Given any three We also have matrix multiplication which corre- functions f, g, and h, we'll show (f ◦ g) ◦ h = sponds to composition of linear transformations. If f ◦ (g ◦ h) by showing the two sides have the same A is the standard matrix for a transformation S, values for all x. and B is the standard matrix for a transformation T , then we defined multiplication of matrices so ((f ◦ g) ◦ h)(x) = (f ◦ g)(h(x)) = f(g(h(x))) that the product AB is be the standard matrix for S ◦ T . -

Things You Need to Know About Linear Algebra Math 131 Multivariate
the standard (x; y; z) coordinate three-space. Nota- tions for vectors. Geometric interpretation as vec- tors as displacements as well as vectors as points. Vector addition, the zero vector 0, vector subtrac- Things you need to know about tion, scalar multiplication, their properties, and linear algebra their geometric interpretation. Math 131 Multivariate Calculus We start using these concepts right away. In D Joyce, Spring 2014 chapter 2, we'll begin our study of vector-valued functions, and we'll use the coordinates, vector no- The relation between linear algebra and mul- tation, and the rest of the topics reviewed in this tivariate calculus. We'll spend the first few section. meetings reviewing linear algebra. We'll look at just about everything in chapter 1. Section 1.2. Vectors and equations in R3. Stan- Linear algebra is the study of linear trans- dard basis vectors i; j; k in R3. Parametric equa- formations (also called linear functions) from n- tions for lines. Symmetric form equations for a line dimensional space to m-dimensional space, where in R3. Parametric equations for curves x : R ! R2 m is usually equal to n, and that's often 2 or 3. in the plane, where x(t) = (x(t); y(t)). A linear transformation f : Rn ! Rm is one that We'll use standard basis vectors throughout the preserves addition and scalar multiplication, that course, beginning with chapter 2. We'll study tan- is, f(a + b) = f(a) + f(b), and f(ca) = cf(a). We'll gent lines of curves and tangent planes of surfaces generally use bold face for vectors and for vector- in that chapter and throughout the course. -

Handout 9 More Matrix Properties; the Transpose
Handout 9 More matrix properties; the transpose Square matrix properties These properties only apply to a square matrix, i.e. n £ n. ² The leading diagonal is the diagonal line consisting of the entries a11, a22, a33, . ann. ² A diagonal matrix has zeros everywhere except the leading diagonal. ² The identity matrix I has zeros o® the leading diagonal, and 1 for each entry on the diagonal. It is a special case of a diagonal matrix, and A I = I A = A for any n £ n matrix A. ² An upper triangular matrix has all its non-zero entries on or above the leading diagonal. ² A lower triangular matrix has all its non-zero entries on or below the leading diagonal. ² A symmetric matrix has the same entries below and above the diagonal: aij = aji for any values of i and j between 1 and n. ² An antisymmetric or skew-symmetric matrix has the opposite entries below and above the diagonal: aij = ¡aji for any values of i and j between 1 and n. This automatically means the digaonal entries must all be zero. Transpose To transpose a matrix, we reect it across the line given by the leading diagonal a11, a22 etc. In general the result is a di®erent shape to the original matrix: a11 a21 a11 a12 a13 > > A = A = 0 a12 a22 1 [A ]ij = A : µ a21 a22 a23 ¶ ji a13 a23 @ A > ² If A is m £ n then A is n £ m. > ² The transpose of a symmetric matrix is itself: A = A (recalling that only square matrices can be symmetric). -

Schaum's Outline of Linear Algebra (4Th Edition)
SCHAUM’S SCHAUM’S outlines outlines Linear Algebra Fourth Edition Seymour Lipschutz, Ph.D. Temple University Marc Lars Lipson, Ph.D. University of Virginia Schaum’s Outline Series New York Chicago San Francisco Lisbon London Madrid Mexico City Milan New Delhi San Juan Seoul Singapore Sydney Toronto Copyright © 2009, 2001, 1991, 1968 by The McGraw-Hill Companies, Inc. All rights reserved. Except as permitted under the United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a database or retrieval system, without the prior writ- ten permission of the publisher. ISBN: 978-0-07-154353-8 MHID: 0-07-154353-8 The material in this eBook also appears in the print version of this title: ISBN: 978-0-07-154352-1, MHID: 0-07-154352-X. All trademarks are trademarks of their respective owners. Rather than put a trademark symbol after every occurrence of a trademarked name, we use names in an editorial fashion only, and to the benefit of the trademark owner, with no intention of infringement of the trademark. Where such designations appear in this book, they have been printed with initial caps. McGraw-Hill eBooks are available at special quantity discounts to use as premiums and sales promotions, or for use in corporate training programs. To contact a representative please e-mail us at [email protected]. TERMS OF USE This is a copyrighted work and The McGraw-Hill Companies, Inc. (“McGraw-Hill”) and its licensors reserve all rights in and to the work. -
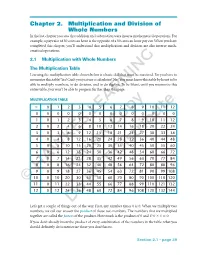
Chapter 2. Multiplication and Division of Whole Numbers in the Last Chapter You Saw That Addition and Subtraction Were Inverse Mathematical Operations
Chapter 2. Multiplication and Division of Whole Numbers In the last chapter you saw that addition and subtraction were inverse mathematical operations. For example, a pay raise of 50 cents an hour is the opposite of a 50 cents an hour pay cut. When you have completed this chapter, you’ll understand that multiplication and division are also inverse math- ematical operations. 2.1 Multiplication with Whole Numbers The Multiplication Table Learning the multiplication table shown below is a basic skill that must be mastered. Do you have to memorize this table? Yes! Can’t you just use a calculator? No! You must know this table by heart to be able to multiply numbers, to do division, and to do algebra. To be blunt, until you memorize this entire table, you won’t be able to progress further than this page. MULTIPLICATION TABLE ϫ 012 345 67 89101112 0 000 000LEARNING 00 000 00 1 012 345 67 89101112 2 024 681012Copy14 16 18 20 22 24 3 036 9121518212427303336 4 0481216 20 24 28 32 36 40 44 48 5051015202530354045505560 6061218243036424854606672Distribute 7071421283542495663707784 8081624324048566472808896 90918273HAWKESReview645546372819099108 10 0 10 20 30 40 50 60 70 80 90 100 110 120 ©11 0 11 22 33 44NOT 55 66 77 88 99 110 121 132 12 0 12 24 36 48 60 72 84 96 108 120 132 144 Do Let’s get a couple of things out of the way. First, any number times 0 is 0. When we multiply two numbers, we call our answer the product of those two numbers. -

Grade 7/8 Math Circles the Scale of Numbers Introduction
Faculty of Mathematics Centre for Education in Waterloo, Ontario N2L 3G1 Mathematics and Computing Grade 7/8 Math Circles November 21/22/23, 2017 The Scale of Numbers Introduction Last week we quickly took a look at scientific notation, which is one way we can write down really big numbers. We can also use scientific notation to write very small numbers. 1 × 103 = 1; 000 1 × 102 = 100 1 × 101 = 10 1 × 100 = 1 1 × 10−1 = 0:1 1 × 10−2 = 0:01 1 × 10−3 = 0:001 As you can see above, every time the value of the exponent decreases, the number gets smaller by a factor of 10. This pattern continues even into negative exponent values! Another way of picturing negative exponents is as a division by a positive exponent. 1 10−6 = = 0:000001 106 In this lesson we will be looking at some famous, interesting, or important small numbers, and begin slowly working our way up to the biggest numbers ever used in mathematics! Obviously we can come up with any arbitrary number that is either extremely small or extremely large, but the purpose of this lesson is to only look at numbers with some kind of mathematical or scientific significance. 1 Extremely Small Numbers 1. Zero • Zero or `0' is the number that represents nothingness. It is the number with the smallest magnitude. • Zero only began being used as a number around the year 500. Before this, ancient mathematicians struggled with the concept of `nothing' being `something'. 2. Planck's Constant This is the smallest number that we will be looking at today other than zero. -

Geometric-Algebra Adaptive Filters Wilder B
1 Geometric-Algebra Adaptive Filters Wilder B. Lopes∗, Member, IEEE, Cassio G. Lopesy, Senior Member, IEEE Abstract—This paper presents a new class of adaptive filters, namely Geometric-Algebra Adaptive Filters (GAAFs). They are Faces generated by formulating the underlying minimization problem (a deterministic cost function) from the perspective of Geometric Algebra (GA), a comprehensive mathematical language well- Edges suited for the description of geometric transformations. Also, (directed lines) differently from standard adaptive-filtering theory, Geometric Calculus (the extension of GA to differential calculus) allows Fig. 1. A polyhedron (3-dimensional polytope) can be completely described for applying the same derivation techniques regardless of the by the geometric multiplication of its edges (oriented lines, vectors), which type (subalgebra) of the data, i.e., real, complex numbers, generate the faces and hypersurfaces (in the case of a general n-dimensional quaternions, etc. Relying on those characteristics (among others), polytope). a deterministic quadratic cost function is posed, from which the GAAFs are devised, providing a generalization of regular adaptive filters to subalgebras of GA. From the obtained update rule, it is shown how to recover the following least-mean squares perform calculus with hypercomplex quantities, i.e., elements (LMS) adaptive filter variants: real-entries LMS, complex LMS, that generalize complex numbers for higher dimensions [2]– and quaternions LMS. Mean-square analysis and simulations in [10]. a system identification scenario are provided, showing very good agreement for different levels of measurement noise. GA-based AFs were first introduced in [11], [12], where they were successfully employed to estimate the geometric Index Terms—Adaptive filtering, geometric algebra, quater- transformation (rotation and translation) that aligns a pair of nions.