Tech-Topic-2 [Compatibility Mode]
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Video Basics ---Major Ref
Video Basics ---major ref. From Ch.5 of textbook 2 ■ Introduction ---- video industry ■ Video Imaging ---- video scan, aspect ratio ■ Color and Composite & component systems ■ From Analog To Digital Video ■ Spatial Conversions ---- video formats ■ Temporal Conversions ■ Mixing And Keying @NTUEE 1 DSP/IC Lab Video Environments Satellite DVB-S downstream(max 90 Mbps) DSS Cable Modem Cable Network DVB-C downstream(max 40 Mbps) OpenCable Home Connection DSTB IEEE 1394 / USB Ethernet 10 Mbps….. Terrestrial DVB-T/ ATSC (Plug&Play , high-data-rate) Interaction Channel DTV set DirecPC/ DirecDuo (1-way / 2-way)1. Satellite( fast PSTN/ ISDN 2. Cable Modem ( QPSK, TCP / IP for PSTN/ ISDN modem 3. SDSL / ADSL / VDSL ….. @NTUEE 2 DSP/IC Lab 1 Video Service Environments Service Provision HFC POTS Wireless Cable DVB-S DVB-C (Full Service (xDSL access) (MMDS) DVB-T (high speed BB) (Cable Modem) Network) TCP / IP Hybrid Services DSTB Residential LAN (IR, RF, Wired) @NTUEE 3 DSP/IC Lab F ãñìµ@ûì > r Gï=.1 *<ÎPU½ÿ½CD *¶1nñG *ÐÍV PC ;^éuu *ñ<uïÚí Internet w7Home SpoppingHome Banking…. *PPV 2âSaDO"H2<_G.(VOD)ÛÚí ö^éGï=. *ö7GïA2Uf÷ ß[1nЯrn1<t *>1ʺ=.²ÁÞ+Gï STBw¯Gï=.1Æ *"Gï=.²2òGï STB Þ1äh¼oZÐõ1"2¤ Gï STB aöÞ^éGï=.> * õ1n<tñ)ËàÁréï=éC 4 *Gï>h Úü¶Êº=.AÓ-I FMMedium Wave ¤µÚí1 / R *Gï>Áä÷1 transm ittersÇt1ä÷ *Gï>r1ñ² ô<Gï=.> *Î BBC aGï=.Ú7ÂbÍÈzéúrp¾câ> DTT > *BDB 2£< 30! DTT nÚí *~£U>;HÞr> HDTV/SDTV > *BSkyB ~£ 6 ´[uSr> 200 !nGïá#Úí *TCIComcastÛUÀ MSOb 1997 £¦¬[àGï Cable Úí *Flextech $} BBC >Ë1Gïn(å UKFM) ö´^éGï=.> *1994 £¦Gï DBS I 1996 £¦[JGïá#r> *1997£¦Gï Cable Úír> *1998 £Î DTT r>ʺ=.²ñhk¶ 12ß 15£1´t Ngñ·ëæJUJT702::9 @NTUEE 4 DSP/IC Lab 2 Applications of Digital Video ¸®ñ *Î]]XÇæ *Internetÿñ *ñ'$7Åg e-mailì½WWW.. -

EEG CB1512 Caption Legalizer™& Relocating Bridge
EEG CB1512 Caption Legalizer™& Relocating Bridge Product Manual EEG Enterprises, Inc. 586 Main Street Farmingdale, New York 11735 TEL: (516) 293-7472 FAX: (516) 293-7417 Copyright © EEG Enterprises, Inc. 2011 All rights reserved. CB1512 HD Caption Legalizer™/ Relocating Bridge Frame Card Contents 1 Introduction 2 1.1 Product Description . 2 2 Installation 3 2.1 Back Panel . 3 3 Caption Legalizer™Operation 4 3.1 DashBoard Menus . 4 3.1.1 GPI Configuration . 5 3.1.2 RS–232 Configuration . 7 3.1.3 Second Language Service . 8 3.2 Using Smart Encoder Commands . 9 3.3 Caption Processing Control . 9 4 Additional Features 11 4.1 Non-Volatile Memory . 11 4.2 Serial Port Configuration . 12 4.3 Encoder Status Commands . 13 A Grand Alliance Interface Protocol 15 B Video/Connector Specifications 16 Copyright 2011, EEG Enterprises, Inc. All rights reserved. The contents of this manual may not be transmitted or reproduced in any form without the written permission of EEG. The revision date for this manual is July 7, 2011. Copyright © EEG Enterprises, Inc. 2011 1 CB1512 HD Caption Legalizer™/ Relocating Bridge Frame Card 1 Introduction 1.1 Product Description The CB1512 HD Caption Legalizer™and Relocating Bridge provides a powerful solution for eliminating HD captioning problems in a single modular frame card operating on the openGear platform. The frame card utilizes the user friendly DashBoard software, which is available for Windows, Mac and Linux operating systems and streamlines setup of the CB1512. The CB1512 fixes common upconversion errors and maximizes interoperability by ensuring that all data complies completely with DTV captioning standards. -

Operations Manual Tandberg EN8090 MPEG4 HD Encoder
ST.RE.E10233.1 Issue 1 REFERENCE GUIDE EN8000 MPEG-4 Part 10 (H.264/AVC) Encoders Software Version 1.0 (and later) EN8030 Standard Definition Encoder EN8090 High Definition Encoder Preliminary Pages ENGLISH (UK) ITALIANO READ THIS FIRST! LEGGERE QUESTO AVVISO PER PRIMO! If you do not understand the contents of this manual Se non si capisce il contenuto del presente manuale DO NOT OPERATE THIS EQUIPMENT. NON UTILIZZARE L’APPARECCHIATURA. Also, translation into any EC official language of this manual can be È anche disponibile la versione italiana di questo manuale, ma il costo è made available, at your cost. a carico dell’utente. SVENSKA NEDERLANDS LÄS DETTA FÖRST! LEES DIT EERST! Om Ni inte förstår informationen i denna handbok Als u de inhoud van deze handleiding niet begrijpt ARBETA DÅ INTE MED DENNA UTRUSTNING. STEL DEZE APPARATUUR DAN NIET IN WERKING. En översättning till detta språk av denna handbok kan också anskaffas, U kunt tevens, op eigen kosten, een vertaling van deze handleiding på Er bekostnad. krijgen. PORTUGUÊS SUOMI LEIA O TEXTO ABAIXO ANTES DE MAIS NADA! LUE ENNEN KÄYTTÖÄ! Se não compreende o texto deste manual Jos et ymmärrä käsikirjan sisältöä NÃO UTILIZE O EQUIPAMENTO. ÄLÄ KÄYTÄ LAITETTA. O utilizador poderá também obter uma tradução do manual para o Käsikirja voidaan myös suomentaa asiakkaan kustannuksella. português à própria custa. FRANÇAIS DANSK AVANT TOUT, LISEZ CE QUI SUIT! LÆS DETTE FØRST! Si vous ne comprenez pas les instructions contenues dans ce manuel Udstyret må ikke betjenes NE FAITES PAS FONCTIONNER CET APPAREIL. MEDMINDRE DE TIL FULDE FORSTÅR INDHOLDET AF DENNE HÅNDBOG. -

A Guide to MPEG Fundamentals and Protocol Analysis and Protocol to MPEG Fundamentals a Guide
MPEG Tutorial A Guide to MPEG Fundamentals and Protocol Analysis (Including DVB and ATSC) A Guide to MPEG Fundamentals and Protocol Analysis (Including DVB and ATSC) A Guide to MPEG Fundamentals and Protocol Analysis ii www.tektronix.com/video_audio/ A Guide to MPEG Fundamentals and Protocol Analysis A Guide to MPEG Fundamentals and Protocol Analysis Contents Section 1 – Introduction to MPEG · · · · · · · · · · · · · · · · · · · · · · · · · · · · 1 1.1 Convergence · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · 1 1.2 Why Compression is Needed · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · 1 1.3 Applications of Compression · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · 1 1.4 Introduction to Video Compression · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · 2 1.5 Introduction to Audio Compression · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · 4 1.6 MPEG Signals · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · 4 1.7 Need for Monitoring and Analysis · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · 5 1.8 Pitfalls of Compression · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · 6 Section 2 – Compression in Video · · · · · · · · · · · · · · · · · · · · · · · · · · · · 7 2.1 Spatial or Temporal Coding? · · · · · · · · · · · · · · · · · · -

Installation and Operation Guide
Installation and Operation Guide Version 3.2 Published: September 30, 2015 ® Table of Contents Notices . 7 Trademarks . 7 Copyright . 7 Contacting Support . 7 Chapter 1: Introduction . 8 Overview. 8 Features . 9 Hardware . 9 Software. 10 Options. 10 System Requirements . 11 Apple ProRes 422 Advantages . 11 In This Manual. 12 Chapter 2: Ki Pro at a Glance . .13 Overview. 13 Operator Side . 14 Controls and Displays . 14 Buttons. 15 Displays and Indicators . 17 Other Front Panel Features. 18 Connector Side. 18 Connections . 19 LTC Timecode Input And Output . 19 SDI Input and Outputs . 20 Component YPbPr . 20 CVBS Composite NTSC/PAL Output. 20 HDMI. 20 Analog 2 Channel Balanced Audio Input and Output. 21 Analog 2 Channel Unbalanced Audio Input and Output. 21 9-pin Connector . 21 Host (FireWire 800) . 21 CTRL/TC (FireWire 400). 21 Ethernet. 21 LANC Loop . 22 Lens Tap. 22 LED Indicator for IEEE 802.11 Radio . 22 Power Connector (back of unit) . 22 Storage . 22 ExpressCard/34 Memory Cards . 22 Removable Storage Modules (HDD or SSD) . 23 Formatting Media. 23 Using Ki Pro Media in Final Cut Pro. 23 Chapter 3: Ki Pro Installation. .25 Installation Overview . 25 What’s In The Box? . 26 Stand-Alone Usage . 27 Camera Mounting with Exo-skeleton. 28 Ki Pro v3.2 2 www.aja.com Exo-skeleton Setup and Adjustment . 28 Accessory Rod Kit Setup and Adjustment . 30 Applying Power . 32 Using AC Power. 33 Using DC Power. 33 Remote Network Control . 34 Network Connections . 34 TCP/IP Information You’ll Need . 35 Networking via DHCP . 35 Networking Ki Pro using a Static IP Address . -

MPEG Compression Is Lossy in That What Is Decoded Is Not Identical to the Interlinked Tables and Coded Identifiers to Separate the Programs and the Original
MPEG Tutorial A Guide to MPEG Fundamentals and Protocol Analysis (Including DVB and ATSC) A Guide to MPEG Fundamentals and Protocol Analysis Primer Section 1 – Introduction to MPEG ..............................................................................1 1.1 Convergence ............................................................................................................................................1 1.2 Why Compression Is Needed ....................................................................................................................1 1.3 Principles of Compression..........................................................................................................................1 1.4 Compression in Television Applications ....................................................................................................2 1.5 Introduction to Digital Video Compression ................................................................................................3 1.6 Introduction to Audio Compression ..........................................................................................................5 1.7 MPEG Streams..........................................................................................................................................6 1.8 Need for Monitoring and Analysis ..............................................................................................................7 1.9 Pitfalls of Compression ..............................................................................................................................7 -

(12) United States Patent (10) Patent No.: US 6,542,196 B1 Watkins (45) Date of Patent: Apr
USOO6542.196B1 (12) United States Patent (10) Patent No.: US 6,542,196 B1 Watkins (45) Date of Patent: Apr. 1, 2003 (54) ADAPTIVE FIELD PARING SYSTEM FOR 6,269,484 B1 7/2001 Simsic et al. ............... 348/448 DE-INTERLACING 6,348,949 B1 * 2/2002 McVeigh .................... 348/448 (75) Inventor: Daniel Watkins, Saratoga, CA (US) * cited by examiner (73) Assignee: LSI Logic Corporation, Milpitas, CA (US) Primaryrimary ExaminerExaminer-Sherrie CC HsiSa (*) Notice: Subject to any disclaimer, the term of this (74) Attorney, Agent, or Firm-Christopher P. Maiorana, patent is extended or adjusted under 35 PC U.S.C. 154(b) by 0 days. (57) ABSTRACT (21) Appl. No.: 09/435,184 A method for de-interlacing a decoded Video Stream com (22) Filed: Nov. 5, 1999 prising the Steps of (A) defining a sampling period, (B) 7 9 Sampling the decoded Video Stream during the Sampling (51) Int. Cl.' .................................................. H04N 7/01 period to define one or more parameters, (C) adjusting a (52) U.S. Cl. ........................................ 348/448; 348/452 threshold and a level of the decoded video stream used in (58) Field of Search ................................. 348/448, 452, processing, in response to the one or more parameters, (D) 348/441; H04N 7/01 filtering the decoded Video Stream using a filter tool Selected (56) References Cited from a plurality of filters, in response to the one or more parameterS. U.S. PATENT DOCUMENTS 6,118,488 A * 9/2000 Huang ........................ 348/448 20 Claims, 5 Drawing Sheets ASC Monitor Interlaced-60 fields/sec 1920x1080 - 16:9 704 x 480 - 16:9 704 x 480 - 4:3 (TV today) 640x480 - 4:3 Progressive-60, 30.24 frames/sec 1920x1080 - 16:9 (No. -

An-548 Application Note
AN-548 a APPLICATION NOTE One Technology Way • P.O. Box 9106 • Norwood, MA 02062-9106 • 781/329-4700 • World Wide Web Site: http://www.analog.com Video Glossary 0H The reference point of horizontal sync. Synchronization at a video interface is achieved by associat- ing a line sync datum, 0H, with every scan line. In analog video, sync is conveyed by voltage levels “blacker than black”. 0H is defined by the 50% point of the leading (or falling) edge of sync. In component digital video, sync is conveyed using digital codes 0 and 255 outside the range of the picture information. 0V The reference point of vertical (field) sync. In both NTSC and PAL systems the normal sync pulse for a horizontal line is 4.7 µs. Vertical sync is identified by broad pulses, which are serrated in order for a receiver to maintain horizontal sync even during the vertical sync interval. The start of the first broad pulse identifies the field sync datum, 0V. 1-H Horizontal scan line interval, usually 64 µs. 100/0/75/7.5 Short form for color bar signal levels, usually describing 4 amplitude levels. 1st number: white amplitude 2nd number: black amplitude 3rd number: white amplitude from which color bars are derived. 4th number: black amplitude from which color bars are derived. In this example: 75% color bars with 7.5 % setup in which the white bar has been set to 100% and the black to 0%. 100% Amplitude, 100% Saturation Common reference for 100/7.5/100/7.5 NTSC color bars. -
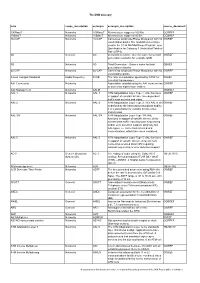
The DVB Glossary
The DVB Glossary term scope_description acronym acronym_description source_document 100BaseT Networks 100BaseT Ethernet over copper at 100 B/s GGBREF 10BaseT Networks 10BaseT Ethernet over copper at 10 B/s GGBREF 16-CAP Networks 16-CAP Carrierless Amplitude/Phase Modulation with 16 GWREF constellation points: The modulation technique used in the 51.84 Mb Mid-Range Physical Layer Specification for Category 3 Unshielded Twisted- Pair (UTP-3). 2G General 2G Second Generation - Generic name for second GWREF generation networks, for example GSM. 3G Networks 3G Third Generation - Generic name for third GBREF generation networks 64-CAP Networks 64-CAP Carrierless Amplitude/Phase Modulation with 64 GWREF constellation points. 8-level Vestigial Sideband Radio Frequency 8VSB The form of modulation specified by ATSC for PBREF terrestrial transmission AAL Connection Networks Association established by the AAL between two GWREF or more next higher layer entities. AAL Management Networks AALM GGBREF AAL-1 Networks AAL-1 ATM Adaptatation Layer Type 1: AAL functions GWREF in support of constant bit rate, time-dependent traffic such as voice and video. AAL-2 Networks AAL-2 ATM Adaptatation Layer Type 2: This AAL is still GWREF undefined by the International standards bodies. It is a placeholder for variable bit rate video transmission. AAL-3/4 Networks AAL-3/4 ATM Adaptatation Layer Type 3/4: AAL GWREF functions in support of variable bit rate, delay- tolerant data traffic requiring some sequencing and/or error detection support. Originally two AAL types, i.e. connection-oriented and connectionless, which have been combined. AAL-5 Networks AAL-5 ATM Adaptatation Layer Type 5: AAL functions GWREF in support of variable bit rate, delay-tolerant connection-oriented data traffic requiring minimal sequencing or error detection support. -

CLUX-SDI2VS SDI to PC/HD Scaler with Audio
CLUX-SDI2VS SDI to PC/HD Scaler with Audio Operation Manual DISCLAIMERS The information in this manual has been carefully checked and is believed to be accurate. Cypress Technology assumes no responsibility for any infringements of patents or other rights of third parties which may result from its use. Cypress Technology assumes no responsibility for any inaccuracies that may be contained in this document. Cypress also makes no commitment to update or to keep current the information contained in this document. Cypress Technology reserves the right to make improvements to this document and/or product at any time and without notice. COPYRIGHT NOTICE No part of this document may be reproduced, transmitted, transcribed, stored in a retrieval system, or any of its part translated into any language or computer file, in any form or by any means— electronic, mechanical, magnetic, optical, chemical, manual, or otherwise—without express written permission and consent from Cypress Technology. © Copyright 2011 by Cypress Technology. All Rights Reserved. Version 1.1 August 2011 TRADEMARK ACKNOWLEDGMENTS All products or service names mentioned in this document may be trademarks of the companies with which they are associated. SAFETY PRECAUTIONS Please read all instructions before attempting to unpack, install or operate this equipment and before connecting the power supply. Please keep the following in mind as you unpack and install this equipment: • Always follow basic safety precautions to reduce the risk of fire, electrical shock and injury to persons. • To prevent fire or shock hazard, do not expose the unit to rain, moisture or install this product near water. -

Dirac Specification
Dirac Specification Version 2.2.3 Issued: September 23, 2008 Abstract This document is the specification of the Dirac video decoder and stream syntax. Dirac is a royalty-free video compression system developed by the BBC utilising wavelet transforms and motion compensation. It is designed to be simple, flexible, yet highly effective. It can operate across a wide range of resolutions and application domains, including: internet and mobile streaming, delivery of standard-definition and high-definition television, digital television and cinema production and distribution, and low-power devices and embedded applications. The system offers several key features: • lossy and lossless coding using a common tool set • intra-coded modes for professional production applications • a special low delay mode for link adaption applications, such as the carriage of HDTV over SDTV infrastructure • motion-compensated (‘long-GOP’) modes for distribution applications • gradual quality reduction with increasing compression CONTENTS 1 Contents 1 Introduction 9 2 Scope 9 3 Conformance notation 11 4 Normative References 11 5 Definition of abbreviations and terms 12 5.1 Abbreviations .............................................. 12 5.2 Terms .................................................. 12 6 Conventions 14 6.1 State representation .......................................... 14 6.2 Number formats ............................................ 14 6.3 Data types ............................................... 14 6.3.1 Elementary data types .................................... -

Glossary&Acronymsrelating to Interactivetv-V6
Acronyms and Glossary of Terms Relating to Digital TV Systems, DVB, Interactive TV & Multimedia Home Platform (MHP) Ver. 6.2 25. DIFFERENTIAL LATENCY ...................................... 18 Introduction 26. DIGITAL TRANSMISSION CONTENT PROTECTION DTCP, 5C & 4C ENTITY .................................... 19 For acronyms, consult the "List of Acronyms and 27. DIGITAL VIDEO BROADCAST (DVB).................... 19 Abbreviated Terms" commencing on page 3 first and 28. DIGITAL VIDEO INTERFACE (DVI) ...................... 19 then the "Description of Technical Terms" if a more 29. DIGITAL VISUAL INTERFACE (DVI/HDCP).......... 19 detailed explanation is required. 30. DOLBY SUROUND PRO-LOGIC™.......................... 19 31. DOLBY® ............................................................. 19 Contents: 32. DOM - (DOCUMENT OBJECT MODEL) ................. 20 33. DSM-CC ............................................................ 20 34. DVB-J ................................................................ 20 1. LIST OF ACRONYMS AND ABBREVIATED 35. DVB-J API......................................................... 20 TERMS....................................................................... 3 36. DVB-J APPLICATION .......................................... 20 Numbers ......................................................................3 37. DVB-T ............................................................... 21 A..................................................................................4 38. DYNAMIC RANGE................................................