1 Pinngortitaleriffik Greenland Institute Of
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Pdf Dokument
Udskriftsdato: 2. oktober 2021 BEK nr 517 af 23/05/2018 (Historisk) Bekendtgørelse om ændring af den fortegnelse over valgkredse, der indeholdes i lov om folketingsvalg i Grønland Ministerium: Social og Indenrigsministeriet Journalnummer: Økonomi og Indenrigsmin., j.nr. 20175132 Senere ændringer til forskriften LBK nr 916 af 28/06/2018 Bekendtgørelse om ændring af den fortegnelse over valgkredse, der indeholdes i lov om folketingsvalg i Grønland I medfør af § 8, stk. 1, i lov om folketingsvalg i Grønland, jf. lovbekendtgørelse nr. 255 af 28. april 1999, fastsættes: § 1. Fortegnelsen over valgkredse i Grønland affattes som angivet i bilag 1 til denne bekendtgørelse. § 2. Bekendtgørelsen træder i kraft den 1. juni 2018. Stk. 2. Bekendtgørelse nr. 476 af 17. maj 2011 om ændring af den fortegnelse over valgkredse, der indeholdes i lov om folketingsvalg i Grønland, ophæves. Økonomi- og Indenrigsministeriet, den 23. maj 2018 Simon Emil Ammitzbøll-Bille / Christine Boeskov BEK nr 517 af 23/05/2018 1 Bilag 1 Ilanngussaq Fortegnelse over valgkredse i hver kommune Kommuneni tamani qinersivinnut nalunaarsuut Kommune Valgkredse i Valgstedet eller Valgkredsens område hver kommune afstemningsdistrikt (Tilknyttede bosteder) (Valgdistrikt) (Afstemningssted) Kommune Nanortalik 1 Nanortalik Nanortalik Kujalleq 2 Aappilattoq (Kuj) Aappilattoq (Kuj) Ikerasassuaq 3 Narsaq Kujalleq Narsaq Kujalleq 4 Tasiusaq (Kuj) Tasiusaq (Kuj) Nuugaarsuk Saputit Saputit Tasia 5 Ammassivik Ammassivik Qallimiut Qorlortorsuaq 6 Alluitsup Paa Alluitsup Paa Alluitsoq Qaqortoq -

Port Charges in Greenland Payment of Port Charges and Filing A
Port Charges in Greenland When ships call at ports in Greenland, they are required to pay port charges. Port charges are payable for any call at port, at ports listed in Annex 1. Example: If a ship calls at three ports, e.g. Qaqortoq, Maniitsoq, and Ilulissat, port charges are payable at all three ports. Payment of Port Charges and Filing a Declaration Port charges are payable when the ship departs from a port. Payment must be made to the local port authorities. At the same time, a ship's officer or another crew member at the bridge must file a declaration with the local port authorities. This declaration must include information regarding the type of ship, GRT/GT, number of days commenced in the port, and an approval of the calculated port charges. Cruise ships must file a declaration including, among other details, information on the number and nationalities of its passengers. These declarations should be filed as instructed by the local port authorities. Both declarations can be retrieved from the Tax Agency website: www.aka.gl. The local port authorities will send the port charges and the declaration to the Tax Agency. The shipping company, owner, operator, charterer, or forwarder is liable for payment of the port charges. Concealment of information, giving false or misleading information, and non-payment of port charges will incur penalties. Calculation of Port Charges Port charges are paid as per gross tonnage (GT/GRT) at the following rates: Type of Ship Rate in Danish Kroner per Gross Tonnage (GT/GRT) 1 Cruise ships DKK 1.10 per commenced 24- hour period 2 Passenger ships DKK 0.70 per commenced 24- hour period 3 Fishing vessels registered outside Greenland DKK 0.70 per commenced 24- hour period 4 Ships adapted for freight transport and other DKK 0.70 per commenced week ships The statement of the ship's gross tonnage is rounded down to the nearest gross ton or gross registered ton. -
![[BA] COUNTRY [BA] SECTION [Ba] Greenland](https://docslib.b-cdn.net/cover/8330/ba-country-ba-section-ba-greenland-398330.webp)
[BA] COUNTRY [BA] SECTION [Ba] Greenland
[ba] Validity date from [BA] COUNTRY [ba] Greenland 26/08/2013 00081 [BA] SECTION [ba] Date of publication 13/08/2013 [ba] List in force [ba] Approval [ba] Name [ba] City [ba] Regions [ba] Activities [ba] Remark [ba] Date of request number 153 Qaqqatisiaq (Royal Greenland Seagfood A/S) Nuuk Vestgronland [ba] FV 219 Markus (Qajaq Trawl A/S) Nuuk Vestgronland [ba] FV 390 Polar Princess (Polar Seafood Greenland A/S) Qeqertarsuaq Vestgronland [ba] FV 401 Polar Qaasiut (Polar Seafood Greenland A/S) Nuuk Vestgronland [ba] FV 425 Sisimiut (Royal Greenland Seafood A/S) Nuuk Vestgronland [ba] FV 4406 Nataarnaq (Ice Trawl A/S) Nuuk Vestgronland [ba] FV 4432 Qeqertaq Fish ApS Ilulissat Vestgronland [ba] PP 4469 Akamalik (Royal Greenland Seafood A/S) Nuuk Vestgronland [ba] FV 4502 Regina C (Niisa Trawl ApS) Nuuk Vestgronland [ba] FV 4574 Uummannaq Seafood A/S Uummannaq Vestgronland [ba] PP 4615 Polar Raajat A/S Nuuk Vestgronland [ba] CS 4659 Greenland Properties A/S Maniitsoq Vestgronland [ba] PP 4660 Arctic Green Food A/S Aasiaat Vestgronland [ba] PP 4681 Sisimiut Fish ApS Sisimiut Vestgronland [ba] PP 4691 Ice Fjord Fish ApS Nuuk Vestgronland [ba] PP 1 / 5 [ba] List in force [ba] Approval [ba] Name [ba] City [ba] Regions [ba] Activities [ba] Remark [ba] Date of request number 4766 Upernavik Seafood A/S Upernavik Vestgronland [ba] PP 4768 Royal Greenland Seafood A/S Qeqertarsuaq Vestgronland [ba] PP 4804 ONC-Polar A/S Alluitsup Paa Vestgronland [ba] PP 481 Upernavik Seafood A/S Upernavik Vestgronland [ba] PP 4844 Polar Nanoq (Sigguk A/S) Nuuk Vestgronland -

Ilulissat Icefjord
World Heritage Scanned Nomination File Name: 1149.pdf UNESCO Region: EUROPE AND NORTH AMERICA __________________________________________________________________________________________________ SITE NAME: Ilulissat Icefjord DATE OF INSCRIPTION: 7th July 2004 STATE PARTY: DENMARK CRITERIA: N (i) (iii) DECISION OF THE WORLD HERITAGE COMMITTEE: Excerpt from the Report of the 28th Session of the World Heritage Committee Criterion (i): The Ilulissat Icefjord is an outstanding example of a stage in the Earth’s history: the last ice age of the Quaternary Period. The ice-stream is one of the fastest (19m per day) and most active in the world. Its annual calving of over 35 cu. km of ice accounts for 10% of the production of all Greenland calf ice, more than any other glacier outside Antarctica. The glacier has been the object of scientific attention for 250 years and, along with its relative ease of accessibility, has significantly added to the understanding of ice-cap glaciology, climate change and related geomorphic processes. Criterion (iii): The combination of a huge ice sheet and a fast moving glacial ice-stream calving into a fjord covered by icebergs is a phenomenon only seen in Greenland and Antarctica. Ilulissat offers both scientists and visitors easy access for close view of the calving glacier front as it cascades down from the ice sheet and into the ice-choked fjord. The wild and highly scenic combination of rock, ice and sea, along with the dramatic sounds produced by the moving ice, combine to present a memorable natural spectacle. BRIEF DESCRIPTIONS Located on the west coast of Greenland, 250-km north of the Arctic Circle, Greenland’s Ilulissat Icefjord (40,240-ha) is the sea mouth of Sermeq Kujalleq, one of the few glaciers through which the Greenland ice cap reaches the sea. -

Arctic Marine Aviation Transportation
SARA FRENCh, WAlTER AND DuNCAN GORDON FOundation Response CapacityandSustainableDevelopment Arctic Transportation Infrastructure: Transportation Arctic 3-6 December 2012 | Reykjavik, Iceland 3-6 December2012|Reykjavik, Prepared for the Sustainable Development Working Group Prepared fortheSustainableDevelopment Working By InstituteoftheNorth,Anchorage, Alaska,USA PROCEEDINGS: 20 Decem B er 2012 ICElANDIC coast GuARD INSTITuTE OF ThE NORTh INSTITuTE OF ThE NORTh SARA FRENCh, WAlTER AND DuNCAN GORDON FOundation Table of Contents Introduction ................................................................................ 5 Acknowledgments ......................................................................... 6 Abbreviations and Acronyms .......................................................... 7 Executive Summary ....................................................................... 8 Chapters—Workshop Proceedings................................................. 10 1. Current infrastructure and response 2. Current and future activity 3. Infrastructure and investment 4. Infrastructure and sustainable development 5. Conclusions: What’s next? Appendices ................................................................................ 21 A. Arctic vignettes—innovative best practices B. Case studies—showcasing Arctic infrastructure C. Workshop materials 1) Workshop agenda 2) Workshop participants 3) Project-related terminology 4) List of data points and definitions 5) List of Arctic marine and aviation infrastructure AlASkA DepartmENT OF ENvIRONmental -

Report on the Availability of Whale Meat in Greenland
1 Greenland survey: 77% of restaurants served whale meat in 2011/2012 Greenland claims that its current Aboriginal Subsistence Whaling (ASW) quota of 175 minke whales, 16 fin whales, nine humpback whales and two bowhead whales a year is insufficient to meet the nutritional needs of Greenlanders (people born in Greenland). It claims in its 2012 Needs Statement that West Greenland alone now requires 730 tonnes of whale meat annually. Greenland has around 50 registered restaurants used by tourists, including several in hotels, plus another 25 smaller "cafeterias, hot dog stands, grill bars, ice cream shops, etc.” which are licensed separately.1 WDCS, the Whale and Dolphin Conservation Society, visited Greenland in May 2011 to assess the availability of whale meat in registered restaurants. In September 2011, WDCS and the Animal Welfare Institute (AWI) visited again. In June 2012, AWI conducted (i) a telephone and email survey of all restaurants (31) for which contact information (phone/email) was available and (ii) extensive internet research in multiple languages of web entries referencing whale meat in Greenland’s restaurants in 2011/2012. Whale meat, including fin, bowhead and minke whale, was available to tourists at 24 out of 31 (77.4%) restaurants visited, contacted, and/or researched online in Greenland in 2011/2012. In addition, one other restaurant for which there was no online record of it serving whale meat indicated, when contacted, that though it did not currently have whale meat on the menu it could be provided if requested in advance for a large enough group. Others that did not have whale meat said that they could provide an introduction to a local family that would. -
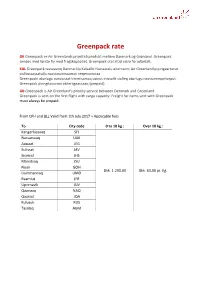
Greenpack Rate
Greenpack rate DK Greenpack er Air Greenlands prioritetsprodukt mellem Danmark og Grønland. Greenpack sendes med første fly med fragtkapacitet. Greenpack skal altid være forudbetalt. KAL Greenpack tassaavoq Danmarkip Kalaallit Nunaatalu akornanni Air Greenlandip pingaartutut siulliussassatullu nassiussinissamut neqeroorutaa. Greenpacki atorlugu nassiussat timmisartoq usinut inissalik siulleq atorlugu nassiunneqartarput. Greenpack pinngitsoorani akileriigaassaaq (prepaid). GB Greenpack is Air Greenland's priority service between Denmark and Greenland. Greenpack is sent on the first flight with cargo capacity. Freight for items sent with Greenpack must always be prepaid. From CPH and BLL Valid from 1th July 2017 + Applicable fees To City code 0 to 10 kg.: Over 10 kg.: Kangerlussuaq SFJ Narsarsuaq UAK Aasiaat JEG Ilulissat JAV Sisimiut JHS Maniitsoq JSU Nuuk GOH Dkk. 1.290,00 Dkk. 63,00 pr. Kg. Uummannaq UMD Paamiut JFR Upernavik JUV Qaanaaq NAQ Qaarsut JQA Kulusuk KUS Tasiilaq AGM MAMAQ DK Faste priser - Forsendelser op til og med 10 kg koster 300,- kroner - Forsendelser mellem 11 og 20 kg koster 500,- kroner Den lave pris for MAMAQ forsendelser, gør at disse har den laveste prioritet og at der kan forekomme lange leveringstider til nogle af destinationerne. Betingelser Fryse-/kølekapaciteten i de forskellige stationer kan være begrænset. Derfor kan det være en god idé at tjekke om stationen har plads til at opbevare dit gods indtil det kan komme med flyveren, eller hvornår godset bedst kan indleveres. KAL Akit aalajangersimasut - 10 kg-t tikillugit nassiussat 300 koruuneqarput - 11 aamma 20 kg-t akornanni nassiussat 500 koruuneqarput MAMAQ akikitsuliaavoq, taamaammallu usinik pingaarnersiuilluni tulleriiaarinermi kingullertut inissisimalluni. Taamaammat ilaatigooriarluni apuuffissamut ingerlanera sivisusarsinnaavoq. Nassiussat killeqarnerat Mittarfiit assigiinngitsut qerisunik/nillataartunik tigusisinnaanerat killeqarsinnaavoq. -

Natural Resources in the Nanortalik District
National Environmental Research Institute Ministry of the Environment Natural resources in the Nanortalik district An interview study on fishing, hunting and tourism in the area around the Nalunaq gold project NERI Technical Report No. 384 National Environmental Research Institute Ministry of the Environment Natural resources in the Nanortalik district An interview study on fishing, hunting and tourism in the area around the Nalunaq gold project NERI Technical Report No. 384 2001 Christain M. Glahder Department of Arctic Environment Data sheet Title: Natural resources in the Nanortalik district Subtitle: An interview study on fishing, hunting and tourism in the area around the Nalunaq gold project. Arktisk Miljø – Arctic Environment. Author: Christian M. Glahder Department: Department of Arctic Environment Serial title and no.: NERI Technical Report No. 384 Publisher: Ministry of Environment National Environmental Research Institute URL: http://www.dmu.dk Date of publication: December 2001 Referee: Peter Aastrup Greenlandic summary: Hans Kristian Olsen Photos & Figures: Christian M. Glahder Please cite as: Glahder, C. M. 2001. Natural resources in the Nanortalik district. An interview study on fishing, hunting and tourism in the area around the Nalunaq gold project. Na- tional Environmental Research Institute, Technical Report No. 384: 81 pp. Reproduction is permitted, provided the source is explicitly acknowledged. Abstract: The interview study was performed in the Nanortalik municipality, South Green- land, during March-April 2001. It is a part of an environmental baseline study done in relation to the Nalunaq gold project. 23 fishermen, hunters and others gave infor- mation on 11 fish species, Snow crap, Deep-sea prawn, five seal species, Polar bear, Minke whale and two bird species; moreover on gathering of mussels, seaweed etc., sheep farms, tourist localities and areas for recreation. -

The Necessity of Close Collaboration 1 2 the Necessity of Close Collaboration the Necessity of Close Collaboration
The Necessity of Close Collaboration 1 2 The Necessity of Close Collaboration The Necessity of Close Collaboration 2017 National Spatial Planning Report 2017 autumn assembly Ministry of Finances and Taxes November 2017 The Necessity of Close Collaboration 3 The Necessity of Close Collaboration 2017 National Spatial Planning Report Ministry of Finances and Taxes Government of Greenland November 2017 Photos: Jason King, page 5 Bent Petersen, page 6, 113 Leiff Josefsen, page 12, 30, 74, 89 Bent Petersen, page 11, 16, 44 Helle Nørregaard, page 19, 34, 48 ,54, 110 Klaus Georg Hansen, page 24, 67, 76 Translation from Danish to English: Tuluttut Translations Paul Cohen [email protected] Layout: allu design Monika Brune www.allu.gl Printing: Nuuk Offset, Nuuk 4 The Necessity of Close Collaboration Contents Foreword . .7 Chapter 1 1.0 Aspects of Economic and Physical Planning . .9 1.1 Construction – Distribution of Public Construction Funds . .10 1.2 Labor Market – Localization of Public Jobs . .25 1.3 Demographics – Examining Migration Patterns and Causes . 35 Chapter 2 2.0 Tools to Secure a Balanced Development . .55 2.1 Community Profiles – Enhancing Comparability . .56 2.2 Sector Planning – Enhancing Coordination, Prioritization and Cooperation . 77 Chapter 3 3.0 Basic Tools to Secure Transparency . .89 3.1 Geodata – for Structure . .90 3.2 Baseline Data – for Systematization . .96 3.3 NunaGIS – for an Overview . .101 Chapter 4 4.0 Summary . 109 Appendixes . 111 The Necessity of Close Collaboration 5 6 The Necessity of Close Collaboration Foreword A well-functioning public adminis- by the Government of Greenland. trative system is a prerequisite for a Hence, the reports serve to enhance modern democratic society. -

Trafikopgave 1 Qaanaq Distrikt 2011 2012 2013 2014 Passagerer 1168
Trafikopgave 1 Qaanaq distrikt 2011 2012 2013 2014 Passagerer 1168 1131 1188 934 Post i kg 12011 9668 1826 10661 Fragt i kg 37832 29605 28105 41559 Trafikopgave 2 Upernavik distrikt 2011 2012 2013 2014 Passagerer 4571 4882 5295 4455 Post i kg 22405 117272 19335 39810 Fragt i kg 37779 32905 32338 39810 Trafikopgave 3 Uumannaq distrikt 2011 2012 2013 2014 Passagerer 10395 9321 10792 9467 Post i kg 38191 34973 36797 37837 Fragt i kg 72556 56129 75480 54168 Trafikopgave 5 Disko distrikt, vinter 2011 2012 2013 2014 Passagerer 5961 7161 6412 6312 Post i kg 23851 28436 22060 23676 Fragt i kg 24190 42560 32221 29508 Trafikopgave 7 Sydgrønland distrikt 2011 2012 2013 2014 Passagerer 39546 43908 27104 30135 Post i kg 115245 107713 86804 93497 Fragt i kg 232661 227371 159999 154558 Trafikopgave 8 Tasiilaq distrikt 2011 2012 2013 2014 Passagerer 12919 12237 12585 11846 Post i kg 50023 57163 45005 43717 Fragt i kg 93034 115623 105175 103863 Trafikopgave 9 Ittoqqortoormiit distrikt 2011 2012 2013 2014 Passagerer 1472 1794 1331 1459 Post i kg 10574 10578 9143 9028 Fragt i kg 29097 24840 12418 15181 Trafikopgave 10 Helårlig beflyvning af Qaanaaq fra Upernavik 2011 2012 2013 2014 Passagerer 1966 1246 2041 1528 Post i kg 22070 11465 20512 14702 Fragt i kg 44389 18489 43592 20786 Trafikopgave 11 Helårlig beflyvning af Nerlerit Inaat fra Island Nedenstående tal er for strækningen Kulusuk - Nerlerit Inaat baseret på en trekantflyvning Nuuk-Kulusuk-Nerlerit Inaat' 2011 2012 2013 2014 Passagerer 4326 4206 1307 1138 Post i kg 21671 19901 9382 5834 Fragt i kg -

Kitaa Kujataa Avanersuaq Tunu Kitaa
Oodaap Qeqertaa (Oodaaq(Oodaaq Island) Ø) KapCape Morris Morris Jesup Jesup D AN L Nansen Land N IAD ATN rd LS Fjio I Freuchen PEARY LAND ce NR den IAH Land pen Ukioq kaajallallugu / Year-round nde TC Ukioq kaajallallugu / Hele året I IES STATION NORD RC UkiupUkiup ilaannaa ilaannaa / Kun / Seasonal visse perioder Tartupaluk HN (Hans Ø)Island) I RC SP N Wa Mylius-Erichsen IN UkioqUkioq kaajallallugu kaajallallugu / Hele / Year-round året shington Land WR Land OP UkiupUkiup ilaannaa ilaannaa / Kun / Seasonal visse perioder Da RN ugaard -Jense ND CO n Land LA R NS K E n Sermersuaq S rde UllersuaqUllersuaq (Humbolt(Humbolt Gletscher) Glacier) S fjo U rds (Cape(Kap Alexander) Alexander) M lvfje S gha Ingleeld Land RA Nio D Siorapaluk U KN Kitsissut (Carey Islands)Øer) QAANAAQ Moriusaq AVANERSUAQ Ille de France Pitufk Thule (Thule Air Base) LL AAU U G Germania LandDANMARKSHAVN CapeKap York York G E E K Savissivik K O O C C H B Q H i C A ( m Dronning M K O u F Y Margrethe II e s A F l s S Land Shannon v S e I i T N l T l r e i a B B r ZACKENBERG AU s Kullorsuaq a YG u DANEBORG y a ) Clavering Ø T q Nuussuaq Clavering Island Innarsuit Tasiusaq Ymer ØIsland UPERNAVIK Aappilattoq TraillTraill Island Ø Kangersuatsiaq Upernavik Kujalleq Summit MESTERSVIG (3.238 m) Sigguup Nunaa Stauning (Svartenhuk) AlperAlps Nuugaatsiaq Illorsuit Jameson Land Ukkusissat Niaqornat Nerlerit Inaat Qaarsut Saatut (Constable Pynt)Point) Kangertittivaq UUMMANNAQNuussuaq Ikerasak TUNU ITTOQQORTOORMIIT QEQERTARSUAQQEQERTARSUAQ (Disko (Disko Island) Ø) AVANNAA EastØstgrønland -

Dartmouth Wild Greenland Escape Brochure
WILD GREENLAND ESCAPE 6 DAYS/5 NIGHTS | ABOARD NATIONAL GEOGRAPHIC RESOLUTION JULY 12-17, 2022 | TRAVEL WITH PROFESSOR MEREDITH KELLY Venture to the fjord-laced coast of western Greenland, where hardy Inuit communities perched at the edge of the Greenland Uummannaq ice cap carry on their timeless way of life. Qilakitsoq Explore archaeological sites and vibrant Ilulissat modern-day villages, glide into breathtaking Davis Strait fjords by Zodiac or kayak, watch for the GREENLAND Ataneq Northern Lights as we explore the ins and outs of this rugged coastline. Take Sisimiut Kangerlussuaq an unforgettable cruise amid the massive ARCTIC CIRCLE icebergs of the Illulissat Icefjord and meet local people who live off the land and sea as their ancestors before them did for millennia. DAY 1: U.S./Kangerlussuaq, Greenland Fly by chartered aircraft to Kangerlussuaq on Greenland’s western coast. Settle into your cabin aboard National Geographic Resolution, the newest ship in the fleet. (L,D) DAY 2: Greenland’s West Coast & Sisimiut Cruise the length of Kangerlussuaq Fjord en route to Sisimiut. Dozens of deep fjords carve into Greenland’s west coast, many with glaciers fed by the ice cap that covers 80% of the country. At Sisimiut, a former whaling port, visit the museum and wander amid a jumble of wooden 18th-century buildings. There are several walking options to explore in and around town. (B,L,D) DAY 3: Ilulissat & Disko Bay Sail into Disko Bay and set out to explore a tongue of the Greenland ice cap. Take an extraordinary cruise among towering icebergs of the UNESCO World Heritage-designated Ilulissat Icefjord.