CS307: Principles of Programming Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Syntax-Directed Translation, Parse Trees, Abstract Syntax Trees
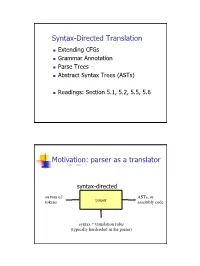
Syntax-Directed Translation Extending CFGs Grammar Annotation Parse Trees Abstract Syntax Trees (ASTs) Readings: Section 5.1, 5.2, 5.5, 5.6 Motivation: parser as a translator syntax-directed translation stream of ASTs, or tokens parser assembly code syntax + translation rules (typically hardcoded in the parser) 1 Mechanism of syntax-directed translation syntax-directed translation is done by extending the CFG a translation rule is defined for each production given X Æ d A B c the translation of X is defined in terms of translation of nonterminals A, B values of attributes of terminals d, c constants To translate an input string: 1. Build the parse tree. 2. Working bottom-up • Use the translation rules to compute the translation of each nonterminal in the tree Result: the translation of the string is the translation of the parse tree's root nonterminal Why bottom up? a nonterminal's value may depend on the value of the symbols on the right-hand side, so translate a non-terminal node only after children translations are available 2 Example 1: arith expr to its value Syntax-directed translation: the CFG translation rules E Æ E + T E1.trans = E2.trans + T.trans E Æ T E.trans = T.trans T Æ T * F T1.trans = T2.trans * F.trans T Æ F T.trans = F.trans F Æ int F.trans = int.value F Æ ( E ) F.trans = E.trans Example 1 (cont) E (18) Input: 2 * (4 + 5) T (18) T (2) * F (9) F (2) ( E (9) ) int (2) E (4) * T (5) Annotated Parse Tree T (4) F (5) F (4) int (5) int (4) 3 Example 2: Compute type of expr E -> E + E if ((E2.trans == INT) and (E3.trans == INT) then E1.trans = INT else E1.trans = ERROR E -> E and E if ((E2.trans == BOOL) and (E3.trans == BOOL) then E1.trans = BOOL else E1.trans = ERROR E -> E == E if ((E2.trans == E3.trans) and (E2.trans != ERROR)) then E1.trans = BOOL else E1.trans = ERROR E -> true E.trans = BOOL E -> false E.trans = BOOL E -> int E.trans = INT E -> ( E ) E1.trans = E2.trans Example 2 (cont) Input: (2 + 2) == 4 1. -

Layout-Sensitive Generalized Parsing
Layout-sensitive Generalized Parsing Sebastian Erdweg, Tillmann Rendel, Christian K¨astner,and Klaus Ostermann University of Marburg, Germany Abstract. The theory of context-free languages is well-understood and context-free parsers can be used as off-the-shelf tools in practice. In par- ticular, to use a context-free parser framework, a user does not need to understand its internals but can specify a language declaratively as a grammar. However, many languages in practice are not context-free. One particularly important class of such languages is layout-sensitive languages, in which the structure of code depends on indentation and whitespace. For example, Python, Haskell, F#, and Markdown use in- dentation instead of curly braces to determine the block structure of code. Their parsers (and lexers) are not declaratively specified but hand-tuned to account for layout-sensitivity. To support declarative specifications of layout-sensitive languages, we propose a parsing framework in which a user can annotate layout in a grammar. Annotations take the form of constraints on the relative posi- tioning of tokens in the parsed subtrees. For example, a user can declare that a block consists of statements that all start on the same column. We have integrated layout constraints into SDF and implemented a layout- sensitive generalized parser as an extension of generalized LR parsing. We evaluate the correctness and performance of our parser by parsing 33 290 open-source Haskell files. Layout-sensitive generalized parsing is easy to use, and its performance overhead compared to layout-insensitive parsing is small enough for practical application. 1 Introduction Most computer languages prescribe a textual syntax. -

Derivatives of Parsing Expression Grammars
Derivatives of Parsing Expression Grammars Aaron Moss Cheriton School of Computer Science University of Waterloo Waterloo, Ontario, Canada [email protected] This paper introduces a new derivative parsing algorithm for recognition of parsing expression gram- mars. Derivative parsing is shown to have a polynomial worst-case time bound, an improvement on the exponential bound of the recursive descent algorithm. This work also introduces asymptotic analysis based on inputs with a constant bound on both grammar nesting depth and number of back- tracking choices; derivative and recursive descent parsing are shown to run in linear time and constant space on this useful class of inputs, with both the theoretical bounds and the reasonability of the in- put class validated empirically. This common-case constant memory usage of derivative parsing is an improvement on the linear space required by the packrat algorithm. 1 Introduction Parsing expression grammars (PEGs) are a parsing formalism introduced by Ford [6]. Any LR(k) lan- guage can be represented as a PEG [7], but there are some non-context-free languages that may also be represented as PEGs (e.g. anbncn [7]). Unlike context-free grammars (CFGs), PEGs are unambiguous, admitting no more than one parse tree for any grammar and input. PEGs are a formalization of recursive descent parsers allowing limited backtracking and infinite lookahead; a string in the language of a PEG can be recognized in exponential time and linear space using a recursive descent algorithm, or linear time and space using the memoized packrat algorithm [6]. PEGs are formally defined and these algo- rithms outlined in Section 3. -

Parse Forest Diagnostics with Dr. Ambiguity
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by CWI's Institutional Repository Parse Forest Diagnostics with Dr. Ambiguity H. J. S. Basten and J. J. Vinju Centrum Wiskunde & Informatica (CWI) Science Park 123, 1098 XG Amsterdam, The Netherlands {Jurgen.Vinju,Bas.Basten}@cwi.nl Abstract In this paper we propose and evaluate a method for locating causes of ambiguity in context-free grammars by automatic analysis of parse forests. A parse forest is the set of parse trees of an ambiguous sentence. Deducing causes of ambiguity from observing parse forests is hard for grammar engineers because of (a) the size of the parse forests, (b) the complex shape of parse forests, and (c) the diversity of causes of ambiguity. We first analyze the diversity of ambiguities in grammars for programming lan- guages and the diversity of solutions to these ambiguities. Then we introduce DR.AMBIGUITY: a parse forest diagnostics tools that explains the causes of ambiguity by analyzing differences between parse trees and proposes solutions. We demonstrate its effectiveness using a small experiment with a grammar for Java 5. 1 Introduction This work is motivated by the use of parsers generated from general context-free gram- mars (CFGs). General parsing algorithms such as GLR and derivates [35,9,3,6,17], GLL [34,22], and Earley [16,32] support parser generation for highly non-deterministic context-free grammars. The advantages of constructing parsers using such technology are that grammars may be modular and that real programming languages (often requiring parser non-determinism) can be dealt with efficiently1. -

Formal Languages - 3
Formal Languages - 3 • Ambiguity in PLs – Problems with if-then-else constructs – Harder problems • Chomsky hierarchy for formal languages – Regular and context-free languages – Type 1: Context-sensitive languages – Type 0 languages and Turing machines Formal Languages-3, CS314 Fall 01© BGRyder 1 Dangling Else Ambiguity (Pascal) Start ::= Stmt Stmt ::= Ifstmt | Astmt Ifstmt ::= IF LogExp THEN Stmt | IF LogExp THEN Stmt ELSE Stmt Astmt ::= Id := Digit Digit ::= 0|1|2|3|4|5|6|7|8|9 LogExp::= Id = 0 Id ::= a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z How are compound if statements parsed using this grammar?? Formal Languages-3, CS314 Fall 01© BGRyder 2 1 IF x = 0 THEN IF y = 0 THEN z := 1 ELSE w := 2; Start Parse Tree 1 Stmt Ifstmt IF LogExp THEN Stmt Ifstmt Id = 0 IF LogExp THEN Stmt ELSE Stmt x Id = 0 Astmt Astmt Id := Digit y Id := Digit z 1 w 2 Formal Languages-3, CS314 Fall 01© BGRyder 3 IF x = 0 THEN IF y = 0 THEN z := 1 ELSE w := 2; Start Stmt Parse Tree 2 Ifstmt Q: which tree is correct? IF LogExp THEN Stmt ELSE Stmt Id = 0 Ifstmt Astmt IF LogExp THEN Stmt x Id := Digit Astmt Id = 0 w 2 Id := Digit y z 1 Formal Languages-3, CS314 Fall 01© BGRyder 4 2 How Solve the Dangling Else? • Algol60: use block structure if x = 0 then begin if y = 0 then z := 1 end else w := 2 • Algol68: use statement begin/end markers if x = 0 then if y = 0 then z := 1 fi else w := 2 fi • Pascal: change the if statement grammar to disallow parse tree 2; that is, always associate an else with the closest if Formal Languages-3, CS314 Fall 01© BGRyder 5 New Pascal Grammar Start ::= Stmt Stmt ::= Stmt1 | Stmt2 Stmt1 ::= IF LogExp THEN Stmt1 ELSE Stmt1 | Astmt Stmt2 ::= IF LogExp THEN Stmt | IF LogExp THEN Stmt1 ELSE Stmt2 Astmt ::= Id := Digit Digit ::= 0|1|2|3|4|5|6|7|8|9 LogExp::= Id = 0 Id ::= a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z Note: only if statements with IF..THEN..ELSE are allowed after the THEN clause of an IF-THEN-ELSE statement. -

Ordered Sets in the Calculus of Data Structures
Exercise 1: Balanced Parentheses Show that the following balanced parentheses grammar is ambiguous (by finding two parse trees for some input sequence) and find unambiguous grammar for the same language. B ::= | ( B ) | B B Remark • The same parse tree can be derived using two different derivations, e.g. B -> (B) -> (BB) -> ((B)B) -> ((B)) -> (()) B -> (B) -> (BB) -> ((B)B) -> (()B) -> (()) this correspond to different orders in which nodes in the tree are expanded • Ambiguity refers to the fact that there are actually multiple parse trees, not just multiple derivations. Towards Solution • (Note that we must preserve precisely the set of strings that can be derived) • This grammar: B ::= | A A ::= ( ) | A A | (A) solves the problem with multiple symbols generating different trees, but it is still ambiguous: string ( ) ( ) ( ) has two different parse trees Solution • Proposed solution: B ::= | B (B) • this is very smart! How to come up with it? • Clearly, rule B::= B B generates any sequence of B's. We can also encode it like this: B ::= C* C ::= (B) • Now we express sequence using recursive rule that does not create ambiguity: B ::= | C B C ::= (B) • but now, look, we "inline" C back into the rules for so we get exactly the rule B ::= | B (B) This grammar is not ambiguous and is the solution. We did not prove this fact (we only tried to find ambiguous trees but did not find any). Exercise 2: Dangling Else The dangling-else problem happens when the conditional statements are parsed using the following grammar. S ::= S ; S S ::= id := E S ::= if E then S S ::= if E then S else S Find an unambiguous grammar that accepts the same conditional statements and matches the else statement with the nearest unmatched if. -

14 a Simple Compiler - the Front End
Compilers and Compiler Generators © P.D. Terry, 2000 14 A SIMPLE COMPILER - THE FRONT END At this point it may be of interest to consider the construction of a compiler for a simple programming language, specifically that of section 8.7. In a text of this nature it is impossible to discuss a full-blown compiler, and the value of our treatment may arguably be reduced by the fact that in dealing with toy languages and toy compilers we shall be evading some of the real issues that a compiler writer has to face. However, we hope the reader will find the ensuing discussion of interest, and that it will serve as a useful preparation for the study of much larger compilers. The technique we shall follow is one of slow refinement, supplementing the discussion with numerous asides on the issues that would be raised in compiling larger languages. Clearly, we could opt to develop a completely hand-crafted compiler, or simply to use a tool like Coco/R. We shall discuss both approaches. Even when a compiler is constructed by hand, having an attributed grammar to describe it is very worthwhile. On the source diskette can be found a great deal of code, illustrating different stages of development of our system. Although some of this code is listed in appendices, its volume precludes printing all of it. Some of it has deliberately been written in a way that allows for simple modification when attempting the exercises, and is thus not really of "production quality". For example, in order to allow components such as the symbol table handler and code generator to be used either with hand-crafted or with Coco/R generated systems, some compromises in design have been necessary. -

Parsing 1. Grammars and Parsing 2. Top-Down and Bottom-Up Parsing 3
Syntax Parsing syntax: from the Greek syntaxis, meaning “setting out together or arrangement.” 1. Grammars and parsing Refers to the way words are arranged together. 2. Top-down and bottom-up parsing Why worry about syntax? 3. Chart parsers • The boy ate the frog. 4. Bottom-up chart parsing • The frog was eaten by the boy. 5. The Earley Algorithm • The frog that the boy ate died. • The boy whom the frog was eaten by died. Slide CS474–1 Slide CS474–2 Grammars and Parsing Need a grammar: a formal specification of the structures allowable in Syntactic Analysis the language. Key ideas: Need a parser: algorithm for assigning syntactic structure to an input • constituency: groups of words may behave as a single unit or phrase sentence. • grammatical relations: refer to the subject, object, indirect Sentence Parse Tree object, etc. Beavis ate the cat. S • subcategorization and dependencies: refer to certain kinds of relations between words and phrases, e.g. want can be followed by an NP VP infinitive, but find and work cannot. NAME V NP All can be modeled by various kinds of grammars that are based on ART N context-free grammars. Beavis ate the cat Slide CS474–3 Slide CS474–4 CFG example CFG’s are also called phrase-structure grammars. CFG’s Equivalent to Backus-Naur Form (BNF). A context free grammar consists of: 1. S → NP VP 5. NAME → Beavis 1. a set of non-terminal symbols N 2. VP → V NP 6. V → ate 2. a set of terminal symbols Σ (disjoint from N) 3. -

Disambiguation Filters for Scannerless Generalized LR Parsers
Disambiguation Filters for Scannerless Generalized LR Parsers Mark G. J. van den Brand1,4, Jeroen Scheerder2, Jurgen J. Vinju1, and Eelco Visser3 1 Centrum voor Wiskunde en Informatica (CWI) Kruislaan 413, 1098 SJ Amsterdam, The Netherlands {Mark.van.den.Brand,Jurgen.Vinju}@cwi.nl 2 Department of Philosophy, Utrecht University Heidelberglaan 8, 3584 CS Utrecht, The Netherlands [email protected] 3 Institute of Information and Computing Sciences, Utrecht University P.O. Box 80089, 3508TB Utrecht, The Netherlands [email protected] 4 LORIA-INRIA 615 rue du Jardin Botanique, BP 101, F-54602 Villers-l`es-Nancy Cedex, France Abstract. In this paper we present the fusion of generalized LR pars- ing and scannerless parsing. This combination supports syntax defini- tions in which all aspects (lexical and context-free) of the syntax of a language are defined explicitly in one formalism. Furthermore, there are no restrictions on the class of grammars, thus allowing a natural syntax tree structure. Ambiguities that arise through the use of unrestricted grammars are handled by explicit disambiguation constructs, instead of implicit defaults that are taken by traditional scanner and parser gener- ators. Hence, a syntax definition becomes a full declarative description of a language. Scannerless generalized LR parsing is a viable technique that has been applied in various industrial and academic projects. 1 Introduction Since the introduction of efficient deterministic parsing techniques, parsing is considered a closed topic for research, both by computer scientists and by practi- cioners in compiler construction. Tools based on deterministic parsing algorithms such as LEX & YACC [15,11] (LALR) and JavaCC (recursive descent), are con- sidered adequate for dealing with almost all modern (programming) languages. -

Abstract Syntax Trees & Top-Down Parsing
Abstract Syntax Trees & Top-Down Parsing Review of Parsing • Given a language L(G), a parser consumes a sequence of tokens s and produces a parse tree • Issues: – How do we recognize that s ∈ L(G) ? – A parse tree of s describes how s ∈ L(G) – Ambiguity: more than one parse tree (possible interpretation) for some string s – Error: no parse tree for some string s – How do we construct the parse tree? Compiler Design 1 (2011) 2 Abstract Syntax Trees • So far, a parser traces the derivation of a sequence of tokens • The rest of the compiler needs a structural representation of the program • Abstract syntax trees – Like parse trees but ignore some details – Abbreviated as AST Compiler Design 1 (2011) 3 Abstract Syntax Trees (Cont.) • Consider the grammar E → int | ( E ) | E + E • And the string 5 + (2 + 3) • After lexical analysis (a list of tokens) int5 ‘+’ ‘(‘ int2 ‘+’ int3 ‘)’ • During parsing we build a parse tree … Compiler Design 1 (2011) 4 Example of Parse Tree E • Traces the operation of the parser E + E • Captures the nesting structure • But too much info int5 ( E ) – Parentheses – Single-successor nodes + E E int 2 int3 Compiler Design 1 (2011) 5 Example of Abstract Syntax Tree PLUS PLUS 5 2 3 • Also captures the nesting structure • But abstracts from the concrete syntax a more compact and easier to use • An important data structure in a compiler Compiler Design 1 (2011) 6 Semantic Actions • This is what we’ll use to construct ASTs • Each grammar symbol may have attributes – An attribute is a property of a programming language construct -

Introduction to Programming Languages and Syntax
Programming Languages Session 1 – Main Theme Programming Languages Overview & Syntax Dr. Jean-Claude Franchitti New York University Computer Science Department Courant Institute of Mathematical Sciences Adapted from course textbook resources Programming Language Pragmatics (3rd Edition) Michael L. Scott, Copyright © 2009 Elsevier 1 Agenda 11 InstructorInstructor andand CourseCourse IntroductionIntroduction 22 IntroductionIntroduction toto ProgrammingProgramming LanguagesLanguages 33 ProgrammingProgramming LanguageLanguage SyntaxSyntax 44 ConclusionConclusion 2 Who am I? - Profile - ¾ 27 years of experience in the Information Technology Industry, including thirteen years of experience working for leading IT consulting firms such as Computer Sciences Corporation ¾ PhD in Computer Science from University of Colorado at Boulder ¾ Past CEO and CTO ¾ Held senior management and technical leadership roles in many large IT Strategy and Modernization projects for fortune 500 corporations in the insurance, banking, investment banking, pharmaceutical, retail, and information management industries ¾ Contributed to several high-profile ARPA and NSF research projects ¾ Played an active role as a member of the OMG, ODMG, and X3H2 standards committees and as a Professor of Computer Science at Columbia initially and New York University since 1997 ¾ Proven record of delivering business solutions on time and on budget ¾ Original designer and developer of jcrew.com and the suite of products now known as IBM InfoSphere DataStage ¾ Creator of the Enterprise -

LLLR Parsing: a Combination of LL and LR Parsing
LLLR Parsing: a Combination of LL and LR Parsing Boštjan Slivnik University of Ljubljana, Faculty of Computer and Information Science, Ljubljana, Slovenia [email protected] Abstract A new parsing method called LLLR parsing is defined and a method for producing LLLR parsers is described. An LLLR parser uses an LL parser as its backbone and parses as much of its input string using LL parsing as possible. To resolve LL conflicts it triggers small embedded LR parsers. An embedded LR parser starts parsing the remaining input and once the LL conflict is resolved, the LR parser produces the left parse of the substring it has just parsed and passes the control back to the backbone LL parser. The LLLR(k) parser can be constructed for any LR(k) grammar. It produces the left parse of the input string without any backtracking and, if used for a syntax-directed translation, it evaluates semantic actions using the top-down strategy just like the canonical LL(k) parser. An LLLR(k) parser is appropriate for grammars where the LL(k) conflicting nonterminals either appear relatively close to the bottom of the derivation trees or produce short substrings. In such cases an LLLR parser can perform a significantly better error recovery than an LR parser since the most part of the input string is parsed with the backbone LL parser. LLLR parsing is similar to LL(∗) parsing except that it (a) uses LR(k) parsers instead of finite automata to resolve the LL(k) conflicts and (b) does not perform any backtracking.