Autonomous Management of Internet of Things Technologies
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
![LIST of NOSQL DATABASES [Currently 150]](https://docslib.b-cdn.net/cover/8918/list-of-nosql-databases-currently-150-418918.webp)
LIST of NOSQL DATABASES [Currently 150]
Your Ultimate Guide to the Non - Relational Universe! [the best selected nosql link Archive in the web] ...never miss a conceptual article again... News Feed covering all changes here! NoSQL DEFINITION: Next Generation Databases mostly addressing some of the points: being non-relational, distributed, open-source and horizontally scalable. The original intention has been modern web-scale databases. The movement began early 2009 and is growing rapidly. Often more characteristics apply such as: schema-free, easy replication support, simple API, eventually consistent / BASE (not ACID), a huge amount of data and more. So the misleading term "nosql" (the community now translates it mostly with "not only sql") should be seen as an alias to something like the definition above. [based on 7 sources, 14 constructive feedback emails (thanks!) and 1 disliking comment . Agree / Disagree? Tell me so! By the way: this is a strong definition and it is out there here since 2009!] LIST OF NOSQL DATABASES [currently 150] Core NoSQL Systems: [Mostly originated out of a Web 2.0 need] Wide Column Store / Column Families Hadoop / HBase API: Java / any writer, Protocol: any write call, Query Method: MapReduce Java / any exec, Replication: HDFS Replication, Written in: Java, Concurrency: ?, Misc: Links: 3 Books [1, 2, 3] Cassandra massively scalable, partitioned row store, masterless architecture, linear scale performance, no single points of failure, read/write support across multiple data centers & cloud availability zones. API / Query Method: CQL and Thrift, replication: peer-to-peer, written in: Java, Concurrency: tunable consistency, Misc: built-in data compression, MapReduce support, primary/secondary indexes, security features. -

Apache Geronimo Uncovered a View Through the Eyes of a Websphere Application Server Expert
Apache Geronimo uncovered A view through the eyes of a WebSphere Application Server expert Skill Level: Intermediate Adam Neat ([email protected]) Author Freelance 16 Aug 2005 Discover the Apache Geronimo application server through the eyes of someone who's used IBM WebSphere® Application Server for many years (along with other commercial J2EE application servers). This tutorial explores the ins and outs of Geronimo, comparing its features and capabilities to those of WebSphere Application Server, and provides insight into how to conceptually architect sharing an application between WebSphere Application Server and Geronimo. Section 1. Before you start This tutorial is for you if you: • Use WebSphere Application Server daily and are interested in understanding more about Geronimo. • Want to gain a comparative groundwork understanding of Geronimo and WebSphere Application Server. • Are considering sharing applications between WebSphere Application Server and Geronimo. • Simply want to learn and understand what other technologies are out there (which I often do). Prerequisites Apache Geronimo uncovered © Copyright IBM Corporation 1994, 2008. All rights reserved. Page 1 of 23 developerWorks® ibm.com/developerWorks To get the most out of this tutorial, you should have a basic familiarity with the IBM WebSphere Application Server product family. You should also posses a general understanding of J2EE terminology and technologies and how they apply to the WebSphere Application Server technology stack. System requirements If you'd like to implement the two technologies included in this tutorial, you'll need the following software and components: • IBM WebSphere Application Server. The version I'm using as a base comparison is IBM WebSphere Application Server, Version 6.0. -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -
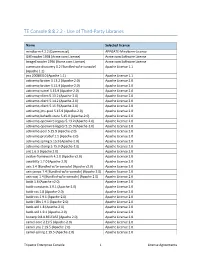
TE Console 8.8.2.2 - Use of Third-Party Libraries
TE Console 8.8.2.2 - Use of Third-Party Libraries Name Selected License mindterm 4.2.2 (Commercial) APPGATE-Mindterm-License GifEncoder 1998 (Acme.com License) Acme.com Software License ImageEncoder 1996 (Acme.com License) Acme.com Software License commons-discovery 0.2 [Bundled w/te-console] Apache License 1.1 (Apache 1.1) jrcs 20080310 (Apache 1.1) Apache License 1.1 activemQ-broker 5.13.2 (Apache-2.0) Apache License 2.0 activemQ-broker 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-camel 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-client 5.13.2 (Apache-2.0) Apache License 2.0 activemQ-client 5.14.2 (Apache-2.0) Apache License 2.0 activemQ-client 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-jms-pool 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-kahadb-store 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-openwire-legacy 5.13.2 (Apache-2.0) Apache License 2.0 activemQ-openwire-legacy 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-pool 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-protobuf 1.1 (Apache-2.0) Apache License 2.0 activemQ-spring 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-stomp 5.15.9 (Apache-2.0) Apache License 2.0 ant 1.6.3 (Apache 2.0) Apache License 2.0 avalon-framework 4.2.0 (Apache v2.0) Apache License 2.0 awaitility 1.7.0 (Apache-2.0) Apache License 2.0 axis 1.4 [Bundled w/te-console] (Apache v2.0) Apache License 2.0 axis-jaxrpc 1.4 [Bundled w/te-console] (Apache 2.0) Apache License 2.0 axis-saaj 1.4 [Bundled w/te-console] (Apache 2.0) Apache License 2.0 batik 1.6 (Apache v2.0) Apache License 2.0 batik-constants -
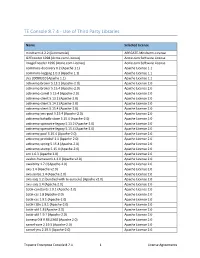
TE Console 8.7.4 - Use of Third Party Libraries
TE Console 8.7.4 - Use of Third Party Libraries Name Selected License mindterm 4.2.2 (Commercial) APPGATE-Mindterm-License GifEncoder 1998 (Acme.com License) Acme.com Software License ImageEncoder 1996 (Acme.com License) Acme.com Software License commons-discovery 0.2 (Apache 1.1) Apache License 1.1 commons-logging 1.0.3 (Apache 1.1) Apache License 1.1 jrcs 20080310 (Apache 1.1) Apache License 1.1 activemq-broker 5.13.2 (Apache-2.0) Apache License 2.0 activemq-broker 5.15.4 (Apache-2.0) Apache License 2.0 activemq-camel 5.15.4 (Apache-2.0) Apache License 2.0 activemq-client 5.13.2 (Apache-2.0) Apache License 2.0 activemq-client 5.14.2 (Apache-2.0) Apache License 2.0 activemq-client 5.15.4 (Apache-2.0) Apache License 2.0 activemq-jms-pool 5.15.4 (Apache-2.0) Apache License 2.0 activemq-kahadb-store 5.15.4 (Apache-2.0) Apache License 2.0 activemq-openwire-legacy 5.13.2 (Apache-2.0) Apache License 2.0 activemq-openwire-legacy 5.15.4 (Apache-2.0) Apache License 2.0 activemq-pool 5.15.4 (Apache-2.0) Apache License 2.0 activemq-protobuf 1.1 (Apache-2.0) Apache License 2.0 activemq-spring 5.15.4 (Apache-2.0) Apache License 2.0 activemq-stomp 5.15.4 (Apache-2.0) Apache License 2.0 ant 1.6.3 (Apache 2.0) Apache License 2.0 avalon-framework 4.2.0 (Apache v2.0) Apache License 2.0 awaitility 1.7.0 (Apache-2.0) Apache License 2.0 axis 1.4 (Apache v2.0) Apache License 2.0 axis-jaxrpc 1.4 (Apache 2.0) Apache License 2.0 axis-saaj 1.2 [bundled with te-console] (Apache v2.0) Apache License 2.0 axis-saaj 1.4 (Apache 2.0) Apache License 2.0 batik-constants -

2007 Javaonesm Conference Word “BENEFIT” Is in Green Instead of Orange
there are 3 cover versions: Prospect 1 (Java) It should say “... Save $200!” on the front and back cover. The first early bird pricing on the IFC and IBC should be “$2,495”, and the word “BENEFIT” is in orange. ADVANCE CONFERENCE GUIDE Prospect 2 (Non-Java) The front cover photo and text is different from Prospect 1. The text of the introduction Last Chance to Save $200! Register by April 4, 2007, at java.sun.com/javaone paragraphs on the IFC is also different, the 2007 JavaOneSM Conference word “BENEFIT” is in green instead of orange. Features Java Technology, Open Source, Web 2.0, Emerging Technologies, and More Don’t miss this year’s newly expanded content. Advance your development skills with hundreds of expert-led, in-depth technical sessions in nine tracks over four days: The back cover and the IBC are the same as Consumer Technologies | Java™ SE | Desktop | Java EE | Java ME Prospect 1. The Next-Generation Web | Open Source | Services and Integration | Tools and Languages How to navigate this brochure and easily find what you need... Alumni For other information for Home Conference Overview JavaOnePavilion this year’s Conference, visit java.sun.com/javaone. It should say “... Save $300!” on the front Registration Conference-at-a-Glance Special Programs and back cover. The first early bird pricing on Hyperlinks Bookmark Buttons Search Click on any of the underlined Use the bookmark tab to Click on the buttons at the top Pull down from the Edit menu and the IFC and IBC should be “$2,395”, and the links to visit specific web sites. -

Apache Camel
Apache Camel USER GUIDE Version 2.9.7 Copyright 2007-2013, Apache Software Foundation 1 Table of Contents Table of Contents......................................................................... ii Chapter 1 Introduction ...................................................................................1 Chapter 1 Quickstart.......................................................................................1 Chapter 1 Getting Started..............................................................................7 Chapter 1 Architecture................................................................................ 17 Chapter 1 Enterprise Integration Patterns.............................................. 37 Chapter 1 Cook Book ................................................................................... 42 Chapter 1 Tutorials..................................................................................... 122 Chapter 1 Language Appendix.................................................................. 221 Chapter 1 DataFormat Appendix............................................................. 297 Chapter 1 Pattern Appendix..................................................................... 383 Chapter 1 Component Appendix ............................................................. 532 Index ................................................................................................0 ii APACHE CAMEL CHAPTER 1 °°°° Introduction Apache Camel ª is a versatile open-source integration framework based on known Enterprise -

Summary of Experience Technologies
Chalakanth Reddy http://www.linkedin.com/in/chalakanth 213 Pennsylvania Ave Emsworth, PA 15202 blog at http://www.seonthemon.com/wp351 412 527 6900 Summary of Experience This is a précis of the summary I have placed in LinkedIn, and at my blog i . Since 2001, I have played lead and architect roles in various J2EE initiatives. Earlier experience, from 1994 on, includes development in other environments (C, C++, Visual Basic), after sales customer service, quality assurance, and technical editing. The breadth, and longevity of my experience has made me a solid generalist, bolstered by good analytical, and communication skills. My responsibilities as a System Architect have included research and choice of technologies; large-grained and detailed design; training, and mentoring programming, business analysis, and QA resources; coding high risk, and complex work; agile project planning, and delivery; empowering management and business stakeholders with education about technology choices, design decisions, and implementation issues. The bulk of the work has been in P & C insurance, with a couple of years in the real estate appraisals industry. I have done considerable business analysis work, informed by knowledge gained during my tenures in quality assurance, technical editing, and customer service – learn to separate pure business requirements, the essence of the business, from all considerations of the technical solution. This work has also sensitized me to the value of user experience, and usability. As suggested in these blog postsii, I believe that user experience in the enterprise iii is more than just the graphical user interface that a business useriv sees. I believe in the need for, and the possibility of, quality in software engineeringv, while remaining aware of the many practical, and legitimate obstacles to achieving that goal. -

CA Service Catalog
CA Service Catalog Notes de parution r12.6 La présente documentation, qui inclut des systèmes d'aide et du matériel distribués électroniquement (ci-après nommés "Documentation"), vous est uniquement fournie à titre informatif et peut être à tout moment modifiée ou retirée par CA. La présente Documentation ne peut être copiée, transférée, reproduite, divulguée, modifiée ou dupliquée, en tout ou partie, sans autorisation préalable et écrite de CA. La présente Documentation est confidentielle et demeure la propriété exclusive de CA. Elle ne peut pas être utilisée ou divulguée, sauf si (i) un autre accord régissant l'utilisation du logiciel CA mentionné dans la Documentation passé entre vous et CA stipule le contraire ; ou (ii) si un autre accord de confidentialité entre vous et CA stipule le contraire. Nonobstant ce qui précède, si vous êtes titulaire de la licence du ou des produits logiciels décrits dans la Documentation, vous pourrez imprimer ou mettre à disposition un nombre raisonnable de copies de la Documentation relative à ces logiciels pour une utilisation interne par vous-même et par vos employés, à condition que les mentions et légendes de copyright de CA figurent sur chaque copie. Le droit de réaliser ou de mettre à disposition des copies de la Documentation est limité à la période pendant laquelle la licence applicable du logiciel demeure pleinement effective. Dans l'hypothèse où le contrat de licence prendrait fin, pour quelque raison que ce soit, vous devrez renvoyer à CA les copies effectuées ou certifier par écrit que toutes les copies partielles ou complètes de la Documentation ont été retournées à CA ou qu'elles ont bien été détruites. -

How to Build J2EE Applications Using Novell Technologies: Part 1 How-To Article NOVELL APPNOTES
How to Build J2EE Applications Using Novell Technologies: Part 1 How-To Article NOVELL APPNOTES J. Jeffrey Hanson Chief Architect Zareus Inc. [email protected] This AppNote is the first in a series that will outline a platform and methodology for developing applications on NetWare with the Java 2 Platform Enterprise Edition (J2EE) using a service-oriented architecture. This AppNote introduces the technologies for the series and tells how to get started by enabling NetWare to respond to HTTP requests with static documents and dynamic scripts generated by Java Server Pages (JSPs) and servlets. Contents: • Introduction • Java and J2EE Application Technologies • The Four Tiers • Web Services and the Services Framework • Getting Started • Conclusion To pics Java application development, J2EE Products Java 2 Enterprise Edition Audience developers Level intermediate Prerequisite Skills familiarity with Java programming Operating System n/a To ols none Sample Code no May 2002 83 Introduction This is the first of a series of AppNotes that will outline a platform and methodology for Java 2 Platform Enterprise Edition (J2EE) application development on NetWare using a service-oriented architecture. This AppNote introduces the technologies for the series, including Java Messaging Service (JMS), servlets, Java Server Pages (JSP), Enterprise JavaBeans (EJB), and so on. It also introduces some J2EE enhancement technologies, including Novell eDirectory/ LDAP, Java Management Extensions (JMX), Jini, and JavaSpaces. It presents a complete, service-oriented platform for developing, deploying, and managing applications and services, using proven design patterns. These applications and services can be deployed and used within multi-tier client/server environments, peer-to-peer environments, fat-client environments, and X Internet environments. -

Attachments: # 1 Appendix a (Joint
Oracle America, Inc. v. Google Inc. Doc. 525 Att. 1 Appendix A Dockets.Justia.com 1 MORRISON & FOERSTER LLP MICHAEL A. JACOBS (Bar No. 111664) 2 [email protected] MARC DAVID PETERS (Bar No. 211725) 3 [email protected] DANIEL P. MUINO (Bar No. 209624) 4 [email protected] 755 Page Mill Road 5 Palo Alto, CA 94304-1018 Telephone: (650) 813-5600 / Facsimile: (650) 494-0792 6 BOIES, SCHILLER & FLEXNER LLP 7 DAVID BOIES (Admitted Pro Hac Vice) [email protected] 8 333 Main Street Armonk, NY 10504 9 Telephone: (914) 749-8200 / Facsimile: (914) 749-8300 STEVEN C. HOLTZMAN (Bar No. 144177) 10 [email protected] 1999 Harrison St., Suite 900 11 Oakland, CA 94612 Telephone: (510) 874-1000 / Facsimile: (510) 874-1460 12 ORACLE CORPORATION 13 DORIAN DALEY (Bar No. 129049) [email protected] 14 DEBORAH K. MILLER (Bar No. 95527) [email protected] 15 MATTHEW M. SARBORARIA (Bar No. 211600) [email protected] 16 500 Oracle Parkway Redwood City, CA 94065 17 Telephone: (650) 506-5200 / Facsimile: (650) 506-7114 18 Attorneys for Plaintiff ORACLE AMERICA, INC. 19 20 UNITED STATES DISTRICT COURT 21 NORTHERN DISTRICT OF CALIFORNIA 22 SAN FRANCISCO DIVISION 23 ORACLE AMERICA, INC. Case No. CV 10-03561 WHA 24 Plaintiff, JOINT TRIAL EXHIBIT LIST 25 v. 26 GOOGLE INC. 27 Defendant. 28 JOINT TRIAL EXHIBIT LIST CASE NO. CV 10-03561 WHA pa-1490805 Case No. CV 10‐03561 WHA Oracle America, Inc. v. Google Inc. JOINT EXHIBIT LIST TRIAL EXHIBIT DATE DESCRIPTION BEGPRODBATE ENDPRODBATE GOOGLE'S ORACLE'S LIMITATIONS DATE DATE NO. -

Apache Tomcat 6
Professional Apache Tomcat 6 Vivek Chopra Sing Li Jeff Genender Wiley Publishing, Inc. ffirs.indd iii 7/11/07 6:54:43 PM ffirs.indd ii 7/11/07 6:54:43 PM Professional Apache Tomcat 6 Introduction xxiii Chapter 1: Apache Tomcat 1 Chapter 2: Web Applications: Servlets, JSPs, and More 13 Chapter 3: Tomcat Installation 29 Chapter 4: Tomcat Architecture 51 Chapter 5: Basic Tomcat Configuration 69 Chapter 6: Advanced Tomcat Features 103 Chapter 7: Web Application Configuration 135 Chapter 8: Web Application Administration 173 Chapter 9: Class Loaders 205 Chapter 10: HTTP Connectors 221 Chapter 11: Tomcat and Apache HTTP Server 243 Chapter 12: Tomcat and IIS 285 Chapter 13: JDBC Connectivity 309 Chapter 14: Tomcat Security 335 Chapter 15: Shared Tomcat Hosting 387 Chapter 16: Monitoring and Managing Tomcat with JMX 419 Chapter 17: Clustering 455 Chapter 18: Embedded Tomcat 493 Chapter 19: Logging 505 Chapter 20: Performance Testing 533 Chapter 21: Performance Tuning 561 Appendix A: Tomcat and IDEs 585 Appendix B: Apache Ant 597 Index 621 ffirs.indd i 7/11/07 6:54:42 PM ffirs.indd ii 7/11/07 6:54:43 PM Professional Apache Tomcat 6 Vivek Chopra Sing Li Jeff Genender Wiley Publishing, Inc. ffirs.indd iii 7/11/07 6:54:43 PM Professional Apache Tomcat 6 Published by Wiley Publishing, Inc. 10475 Crosspoint Boulevard Indianapolis, IN 46256 www.wiley.com Copyright © 2007 by Wiley Publishing, Inc., Indianapolis, Indiana Published simultaneously in Canada ISBN: 978-0-471-75361-2 Manufactured in the United States of America 10 9 8 7 6 5 4 3 2 1 Library of Congress Cataloging-in-Publication Data Chopra, Vivek.