Analyzing Right-Wing Youtube Channels:Hate
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Unlikely Identities
Unlikely Identities: In May of 1911 an Ottoman deputy from Thessaloniki, Dimitar Vlahov, interjected Abu Ibrahim and the himself in a parliamentary debate about Zionism in Palestine with a question: “Are Politics of Possibility in 2 Arab peasants opposed to the Jews?” 1 Late Ottoman Palestine Answering himself, he declared that there was no enmity between Arab and Samuel Dolbee & Shay Hazkani Jewish peasants since, in his estimation, “They are brothers [onlar kardeştir], and like brothers they are trying to live.” Noting that in the past few weeks “anti- Semitism” had appeared on the pages of newspapers, he reiterated his message of familial bonds: “Whatever happens, the truth is in the open. Among Jewish, Arab, and Turkish peasants, there is nothing that will cause conflict. They are brothers.” Vlahov Efendi’s somewhat simplistic message of coexistence was not popular, appearing as it did in the midst of a charged debate about Zionist land acquisitions in Palestine.3 Other deputies in parliament pressed him about the source of his information on these apparent familial ties between peasants. He had mentioned “Arab newspapers,” but ʿAbd al-Mehdi Bey of Karbala wanted to know which ones he had consulted to support his claims. “In Jaffa there is a newspaper that appears named ‘Palestine,’” Vlahov replied. Commotion in the hall interrupted his speech at this point, but Vlahov continued, explaining how the paper suggested Hadera [Khdeira], south of Haifa, had been “nothing but wild animals” thirty years before but had recently become economically prosperous through Zionist settlement. Rishon LeZion, one of the first Zionist colonies, was another engine of development, as its tax revenue had increased a hundred- fold in the previous three decades, he claimed. -

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
1 TABLE OF CONTENTS 2 I. INTRODUCTION ...................................................................................................... 2 3 II. JURISDICTION AND VENUE ................................................................................. 8 4 III. PARTIES .................................................................................................................... 9 5 A. Plaintiffs .......................................................................................................... 9 6 B. Defendants ....................................................................................................... 9 7 IV. FACTUAL ALLEGATIONS ................................................................................... 17 8 A. Alphabet’s Reputation as a “Good” Company is Key to Recruiting Valuable Employees and Collecting the User Data that Powers Its 9 Products ......................................................................................................... 17 10 B. Defendants Breached their Fiduciary Duties by Protecting and Rewarding Male Harassers ............................................................................ 19 11 1. The Board Has Allowed a Culture Hostile to Women to Fester 12 for Years ............................................................................................. 19 13 a) Sex Discrimination in Pay and Promotions: ........................... 20 14 b) Sex Stereotyping and Sexual Harassment: .............................. 23 15 2. The New York Times Reveals the Board’s Pattern -

The Armenian Genocide
The Armenian Genocide During World War I, the Ottoman Empire carried out what most international experts and historians have concluded was one of the largest genocides in the world's history, slaughtering huge portions of its minority Armenian population. In all, over 1 million Armenians were put to death. To this day, Turkey denies the genocidal intent of these mass murders. My sense is that Armenians are suffering from what I would call incomplete mourning, and they can't complete that mourning process until their tragedy, their wounds are recognized by the descendants of the people who perpetrated it. People want to know what really happened. We are fed up with all these stories-- denial stories, and propaganda, and so on. Really the new generation want to know what happened 1915. How is it possible for a massacre of such epic proportions to take place? Why did it happen? And why has it remained one of the greatest untold stories of the 20th century? This film is made possible by contributions from John and Judy Bedrosian, the Avenessians Family Foundation, the Lincy Foundation, the Manoogian Simone Foundation, and the following. And others. A complete list is available from PBS. The Armenians. There are between six and seven million alive today, and less than half live in the Republic of Armenia, a small country south of Georgia and north of Iran. The rest live around the world in countries such as the US, Russia, France, Lebanon, and Syria. They're an ancient people who originally came from Anatolia some 2,500 years ago. -

Audio-Visual Genres and Polymediation in Successful Spanish Youtubers †,‡
future internet Article Audio-Visual Genres and Polymediation in Successful Spanish YouTubers †,‡ Lorenzo J. Torres Hortelano Department of Sciences of Communication, Universidad Rey Juan Carlos, 28943 Fuenlabrada, Madrid, Spain; [email protected]; Tel.: +34-914888445 † This paper is dedicated to our colleague in INFOCENT, Javier López Villanueva, who died on 31 December 2018 during the finalization of this article, RIP. ‡ A short version of this article was presented as “Populism, Media, Politics, and Immigration in a Globalized World”, in Proceedings of the 13th Global Communication Association Conference Rey Juan Carlos University, Madrid, Spain, 17–19 May 2018. Received: 8 January 2019; Accepted: 2 February 2019; Published: 11 February 2019 Abstract: This paper is part of broader research entitled “Analysis of the YouTuber Phenomenon in Spain: An Exploration to Identify the Vectors of Change in the Audio-Visual Market”. My main objective was to determine the predominant audio-visual genres among the 10 most influential Spanish YouTubers in 2018. Using a quantitative extrapolation method, I extracted these data from SocialBlade, an independent website, whose main objective is to track YouTube statistics. Other secondary objectives in this research were to analyze: (1) Gender visualization, (2) the originality of these YouTube audio-visual genres with respect to others, and (3) to answer the question as to whether YouTube channels form a new audio-visual genre. I quantitatively analyzed these data to determine how these genres are influenced by the presence of polymediation as an integrated communicative environment working in relational terms with other media. My conclusion is that we can talk about a new audio-visual genre. -

Developing a Curriculum for TEFL 107: American Childhood Classics
Minnesota State University Moorhead RED: a Repository of Digital Collections Dissertations, Theses, and Projects Graduate Studies Winter 12-19-2019 Developing a Curriculum for TEFL 107: American Childhood Classics Kendra Hansen [email protected] Follow this and additional works at: https://red.mnstate.edu/thesis Part of the American Studies Commons, Education Commons, and the English Language and Literature Commons Recommended Citation Hansen, Kendra, "Developing a Curriculum for TEFL 107: American Childhood Classics" (2019). Dissertations, Theses, and Projects. 239. https://red.mnstate.edu/thesis/239 This Project (696 or 796 registration) is brought to you for free and open access by the Graduate Studies at RED: a Repository of Digital Collections. It has been accepted for inclusion in Dissertations, Theses, and Projects by an authorized administrator of RED: a Repository of Digital Collections. For more information, please contact [email protected]. Developing a Curriculum for TEFL 107: American Childhood Classics A Plan B Project Proposal Presented to The Graduate Faculty of Minnesota State University Moorhead By Kendra Rose Hansen In Partial Fulfillment of the Requirements for the Degree of Master of Arts in Teaching English as a Second Language December, 2019 Moorhead, Minnesota Copyright 2019 Kendra Rose Hansen v Dedication I would like to dedicate this thesis to my family. To my husband, Brian Hansen, for supporting me and encouraging me to keep going and for taking on a greater weight of the parental duties throughout my journey. To my children, Aidan, Alexa, and Ainsley, for understanding when Mom needed to be away at class or needed quiet time to work at home. -

EXPRESS Express@Houndmail
MOBERLY AREA COMMUNITY COLLEGE Greyhound EXPRESS express@houndmail. macc.edu November 2013 www.macc.edu Inside Stories: Live from Fitzsimmons-John Arena By Kendra Gladbach News Express Staff Major Decisions p 2 Can’t make it to a Grey- MACC Singers p 2 Giving Back p3 hound game? Too far to Multicultural club p3 travel? Weather is too cold or roads too bad to get out? MACC is streaming Lady Arts & Life Greyhound and Greyhound basketball games live, so Big Sisters p 4 now you can curl up on A Passion for Teaching p 5 your couch, grab your pop- Spelling Bee p 6 corn, and watch the games Touring with Twain p 7 at home on your computer! Many colleges and uni- versities and even some high schools have gone to mainstreaming their athletic events and other activities. Moberly Area Community College has recently streamed their first home basketball game and will stream all home games this season. According to Scott Mc- Garvey, director of Market- Student Andrew Faulconer watches the stream from Hannibal's campus. ing and Public Relations, com’s specification, which Since MACC has re- vs. Iowa Western on Dec. 14 the process has been a long includes having web access. cruited many players from and the Lady Greyhounds vs Voice time coming. After main- What Scott McGarvey out-of-town, this will benefit Three Rivers Jan. 9, 2014. streaming the SGA Battle thought was going to be a their families by allowing If you are unable to Right From The Source p 8 of the Bands, it was clear More Than Ramen Noodles p 9 very difficult process turned them to be a part of the bas- make it to Fitzsimmons-John that MACC would be able out to be a very simple set-up. -

Pewdiepie, Popularity, and Profitability
Pepperdine Journal of Communication Research Volume 8 Article 4 2020 The 3 P's: Pewdiepie, Popularity, and Profitability Lea Medina Pepperdine University, [email protected] Eric Reed Pepperdine University, [email protected] Cameron Davis Pepperdine University, [email protected] Follow this and additional works at: https://digitalcommons.pepperdine.edu/pjcr Part of the Communication Commons Recommended Citation Medina, Lea; Reed, Eric; and Davis, Cameron (2020) "The 3 P's: Pewdiepie, Popularity, and Profitability," Pepperdine Journal of Communication Research: Vol. 8 , Article 4. Available at: https://digitalcommons.pepperdine.edu/pjcr/vol8/iss1/4 This Article is brought to you for free and open access by the Communication at Pepperdine Digital Commons. It has been accepted for inclusion in Pepperdine Journal of Communication Research by an authorized editor of Pepperdine Digital Commons. For more information, please contact [email protected], [email protected], [email protected]. 21 The 3 P’s: Pewdiepie, Popularity, & Popularity Lea Medina Written for COM 300: Media Research (Dr. Klive Oh) Introduction Channel is an online prole created on the Felix Arvid Ul Kjellberg—more website YouTube where users can upload their aectionately referred to as Pewdiepie—is original video content to the site. e factors statistically the most successful YouTuber, o his channel that will be explored are his with a net worth o over $15 million and over relationships with the viewers, his personality, 100 million subscribers. With a channel that relationship with his wife, and behavioral has uploaded over 4,000 videos, it becomes patterns. natural to uestion how one person can gain Horton and Wohl’s Parasocial such popularity and prot just by sitting in Interaction eory states that interacting front o a camera. -

Should Google Be Taken at Its Word?
CAN GOOGLE BE TRUSTED? SHOULD GOOGLE BE TAKEN AT ITS WORD? IF SO, WHICH ONE? GOOGLE RECENTLY POSTED ABOUT “THE PRINCIPLES THAT HAVE GUIDED US FROM THE BEGINNING.” THE FIVE PRINCIPLES ARE: DO WHAT’S BEST FOR THE USER. PROVIDE THE MOST RELEVANT ANSWERS AS QUICKLY AS POSSIBLE. LABEL ADVERTISEMENTS CLEARLY. BE TRANSPARENT. LOYALTY, NOT LOCK-IN. BUT, CAN GOOGLE BE TAKEN AT ITS WORD? AND IF SO, WHICH ONE? HERE’S A LOOK AT WHAT GOOGLE EXECUTIVES HAVE SAID ABOUT THESE PRINCIPLES IN THE PAST. DECIDE FOR YOURSELF WHO TO TRUST. “DO WHAT’S BEST FOR THE USER” “DO WHAT’S BEST FOR THE USER” “I actually think most people don't want Google to answer their questions. They want Google to tell them what they should be doing next.” Eric Schmidt The Wall Street Journal 8/14/10 EXEC. CHAIRMAN ERIC SCHMIDT “DO WHAT’S BEST FOR THE USER” “We expect that advertising funded search engines will be inherently biased towards the advertisers and away from the needs of consumers.” Larry Page & Sergey Brin Stanford Thesis 1998 FOUNDERS BRIN & PAGE “DO WHAT’S BEST FOR THE USER” “The Google policy on a lot of things is to get right up to the creepy line.” Eric Schmidt at the Washington Ideas Forum 10/1/10 EXEC. CHAIRMAN ERIC SCHMIDT “DO WHAT’S BEST FOR THE USER” “We don’t monetize the thing we create…We monetize the people that use it. The more people use our products,0 the more opportunity we have to advertise to them.” Andy Rubin In the Plex SVP OF MOBILE ANDY RUBIN “PROVIDE THE MOST RELEVANT ANSWERS AS QUICKLY AS POSSIBLE” “PROVIDE THE MOST RELEVANT ANSWERS AS QUICKLY -

Lightning Bolt
THE LIGHTNING BOLT CRAWFORD LEADS THE CHARGE MARIO GAME AND MOVIE REVIEWS COVID COVERAGE-THEATRE, SPORTS, TEACHERS,PROCEDURES VOLUME 33 iSSUE 1 CHANCELLOR HIGH SCHOOL 6300 HARRISON ROAD, FREDERICKSBURG, VA 22407 1 Sep/Oct 2020 RETIREMENT, RETURN TO SCHOOL, MRS. GATTIE AND CRAWFORD ADVISOR FAITH REMICK Left Mrs. Bass-Fortune is at her retirement parade on June EDITOR-IN-CHIEF 24 that was held to honor her many years at Chancellor High School. For more than three CARA SEELY hours decorated cars drove by the school, honking at Mrs. NEWS EDITOR Bass-Fortune, giving her gifts and well wishes. CARA HADDEN FEATURES EDITOR KAITLYN GARVEY SPORTS EDITOR STEPHANIE MARTINEZ & EMMA PURCELL OP-ED EDITORS Above and Left: Chancellor gets a facelift of decorated doors throughout the school. MIKAH NELSON Front Cover:New Principal Mrs. Cassandra Crawford & Back Cover: Newly Retired HAILEY PATTEN Mrs. Bass-Fortune CHARGING CORNER CHARGER FUR BABIES CONTEST MATCH THE NAME OF THE PET TO THE PICTURE AND TAKE YOUR ANSWERS TO ROOM A113 OR EMAIL LGATTIE@SPOT- SYLVANIA.K12.VA.US FOR A CHANCE TO WIN A PRIZE. HAVE A PHOTO OF YOUR FURRY FRIEND YOU WANT TO SUBMIT? EMAIL SUBMISSIONS TO [email protected]. Charger 1 Charger 2 Charger 3 Charger 4 Names to choose from. Note: There are more names than pictures! Banks, Sadie, Fenway, Bently, Spot, Bear, Prince, Thor, Sunshine, Lady Sep/Oct 2020 2 IS THERE REWARD TO THIS RISK? By Faith Remick school even for two days a many students with height- money to get our kids back Editor-In-Chief week is dangerous, and the ened behavioral needs that to school safely.” I agree. -

IFA 2020 Crisis Management Paper.Pdf
International Franchise Association Franchise Law Virtual Summit August 12-13, 2020 CRISIS MANAGEMENT IN THE ERA OF FAKE NEWS Bethany Appleby Appleby & Corcoran, LLC New Haven, Connecticut John B. Gessner Fox Rothschild LLP Dallas, Texas Kathryn M. Kotel Smoothie King Franchises, Inc. Dallas, Texas Sarah A. Walters DLA Piper LLP Dallas, Texas WEST\291447123.3 Table of Contents Page I. Introduction and Examples of PR Crises in Recent Years .................................... 1 II. Can Your Company Weather the Storm? ............................................................. 4 A. Development of a Crisis Response Plan.................................................... 6 i. The Crisis Response Team ............................................................. 6 ii. Formulating a Crisis Response Plan ............................................... 7 iii. Crisis Communication Strategies .................................................... 8 iv. Controlling Communications from Franchisees and Personnel ....... 9 v. Crisis Response Training and Mock Crisis Response Trials ......... 10 B. Considerations for Involving Franchisees ................................................ 10 III. When Crisis Happens – Run Into the Flames. .................................................... 11 A. Crisis Management Plan Execution and Parallel Paths to Resolution ..... 11 B. Stabilize Stakeholders – Owners, Franchisees and Customers .............. 13 C. Resolve Central Technical and Operational Challenges .......................... 14 D. Repair the Root -

Conservative Website Parler Forced Offline: Web Trackers 11 January 2021
Conservative website Parler forced offline: web trackers 11 January 2021 In a letter to Parler's owners, the web giant said it would suspend service by 11:59 PM on Sunday (0759 GMT Monday). Tracking website Down For Everyone Or Just Me showed Parler offline from just after midnight, suggesting its owners had not been able to find a new hosting partner. In a series of posts on Parler before the site went down, CEO John Matze accused the tech giants of a "war on free speech." "They will NOT win! We are the worlds last hope for free speech and free information," he said. The conservative social network Parler was forced offline, tracking websites showed, a day after Amazon Parler did not respond to a request for comment warned the company would lose access to its servers for from AFP. its failure to properly police violent content The social network, launched in 2018, operates much like Twitter, with profiles to follow and "parleys" instead of tweets. The conservative social network Parler was forced offline Monday, tracking websites showed, after In its early days, the platform attracted a crowd of Amazon warned the company would lose access ultra-conservative and even extreme-right users. to its servers for its failure to properly police violent content. But it now attracts many more traditional Republican voices. The site's popularity soared in recent weeks, becoming the number one download from Apple's Fox News star host Sean Hannity has 7.6 million App Store after the much larger Twitter banned US followers, while his colleague Tucker Carlson has President Donald Trump from its platform for his 4.4 million. -
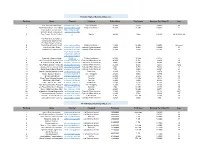
Sources & Data
YouTube Highest Earning Influencers Ranking Name Channel Category Subscribers Total views Earnings Per Video ($) Age 1 JoJo https://www.youtube.com/channel/UCeV2O_6QmFaaKBZHY3bJgsASiwa (Its JoJo Siwa) Life / Vlogging 10.6M 2.8Bn 569112 16 2 Anastasia Radzinskayahttps://www.youtube.com/channel/UCJplp5SjeGSdVdwsfb9Q7lQ (Like Nastya Vlog) Children's channel 48.6M 26.9Bn 546549 6 Coby Cotton; Cory Cotton; https://www.youtube Garrett Hilbert; Cody Jones; .com/user/corycotto 3 Tyler Toney. (Dude Perfect) n Sports 49.4M 10Bn 186783 30,30,30,33,28 FunToys Collector Disney Toys ReviewToys Review ( FunToys Collector Disney 4 Toys ReviewToyshttps://www.youtube.com/user/DisneyCollectorBR Review) Children's channel 11.6M 14.9Bn 184506 Unknown 5 Jakehttps://www.youtube.com/channel/UCcgVECVN4OKV6DH1jLkqmcA Paul (Jake Paul) Comedy / Entertainment 19.8M 6.4Bn 180090 23 6 Loganhttps://www.youtube.com/channel/UCG8rbF3g2AMX70yOd8vqIZg Paul (Logan Paul) Comedy / Entertainment 20.5M 4.9Bn 171396 24 https://www.youtube .com/channel/UChG JGhZ9SOOHvBB0Y 7 Ryan Kaji (Ryan's World) 4DOO_w Children's channel 24.1M 36.7Bn 133377 8 8 Germán Alejandro Garmendiahttps://www.youtube.com/channel/UCZJ7m7EnCNodqnu5SAtg8eQ Aranis (German Garmendia) Comedy / Entertainment 40.4M 4.2Bn 81489 29 9 Felix Kjellberg (PewDiePie)https://www.youtube.com/user/PewDiePieComedy / Entertainment 103M 24.7Bn 80178 30 10 Anthony Padilla and Ian Hecoxhttps://www.youtube.com/user/smosh (Smosh) Comedy / Entertainment 25.1M 9.3Bn 72243 32,32 11 Olajide William Olatunjihttps://www.youtube.com/user/KSIOlajidebt