When Speakers Are All Ears: Characterizing Misactivations of Iot Smart Speakers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

FIT to WORK: IMPROVING the SECURITY of MONITORED EMPLOYEES' HEALTH DATA Elizabeth A. Brown INTRODUCTION Imagine Coming to Work
FIT TO WORK: IMPROVING THE SECURITY OF MONITORED EMPLOYEES' HEALTH DATA Elizabeth A. Brown1 INTRODUCTION Imagine coming to work one day and finding that your employer has given everyone in the company a wearable FitBit health monitor, free of charge. You pop the FitBit on, grateful for another bit of help in managing the health concerns that nag at you persistently but which never quite rise to the top of your priority list. At your next performance review, your supervisor expresses concern about your anxiety levels. Although your work output is slightly off, she notes, there has been a correlation in your lack of sleep and exercise, and she suspects you are depressed. You wonder how your employer might know these things, whether or not they are true, and then you remember the FitBit. Your supervisor then tells you that the promotion you had wanted is going to a colleague who is “better equipped to handle the demands of the job.” You interview for another job, and are asked to provide the password to the HealthDrive account that centralizes the fitness data all the apps on your iPhone collect about you during the day. Similar scenarios are playing out now in workplaces across the country, and will do so more frequently as the personal health sensor market and employee monitoring trends continue to grow. Employers are making key decisions based on employees’ biometric data, collected from specialized devices like a FitBit or the health-related apps installed on mobile phones. BP, for example, adjusts its employees’ health care premiums depending on how much physical activity their wearable FitBit devices monitor – devices that BP provides to thousands of employees, their spouses, and retirees for free. -

Listen Only When Spoken To: Interpersonal Communication Cues As Smart Speaker Privacy Controls
Proceedings on Privacy Enhancing Technologies ; 2020 (2):251–270 Abraham Mhaidli*, Manikandan Kandadai Venkatesh, Yixin Zou, and Florian Schaub Listen Only When Spoken To: Interpersonal Communication Cues as Smart Speaker Privacy Controls Abstract: Internet of Things and smart home technolo- 1 Introduction gies pose challenges for providing effective privacy con- trols to users, as smart devices lack both traditional Internet of Things (IoT) and smart home devices have screens and input interfaces. We investigate the poten- gained considerable traction in the consumer market [4]. tial for leveraging interpersonal communication cues as Technologies such as smart door locks, smart ther- privacy controls in the IoT context, in particular for mostats, and smart bulbs offer convenience and utility smart speakers. We propose privacy controls based on to users [4]. IoT devices often incorporate numerous sen- two kinds of interpersonal communication cues – gaze sors from microphones to cameras. Though these sensors direction and voice volume level – that only selectively are essential for the functionality of these devices, they activate a smart speaker’s microphone or voice recog- may cause privacy concerns over what data such devices nition when the device is being addressed, in order to and their sensors collect, how the data is processed, and avoid constant listening and speech recognition by the for what purposes the data is used [35, 41, 46, 47, 70]. smart speaker microphones and reduce false device acti- Additionally, these sensors are often in the background vation. We implement these privacy controls in a smart or hidden from sight, continuously collecting informa- speaker prototype and assess their feasibility, usability tion. -

Personification and Ontological Categorization of Smart Speaker-Based Voice Assistants by Older Adults
“Phantom Friend” or “Just a Box with Information”: Personification and Ontological Categorization of Smart Speaker-based Voice Assistants by Older Adults ALISHA PRADHAN, University of Maryland, College Park, USA LEAH FINDLATER, University of Washington, USA AMANDA LAZAR, University of Maryland, College Park, USA As voice-based conversational agents such as Amazon Alexa and Google Assistant move into our homes, researchers have studied the corresponding privacy implications, embeddedness in these complex social environments, and use by specific user groups. Yet it is unknown how users categorize these devices: are they thought of as just another object, like a toaster? As a social companion? Though past work hints to human- like attributes that are ported onto these devices, the anthropomorphization of voice assistants has not been studied in depth. Through a study deploying Amazon Echo Dot Devices in the homes of older adults, we provide a preliminary assessment of how individuals 1) perceive having social interactions with the voice agent, and 2) ontologically categorize the voice assistants. Our discussion contributes to an understanding of how well-developed theories of anthropomorphism apply to voice assistants, such as how the socioemotional context of the user (e.g., loneliness) drives increased anthropomorphism. We conclude with recommendations for designing voice assistants with the ontological category in mind, as well as implications for the design of technologies for social companionship for older adults. CCS Concepts: • Human-centered computing → Ubiquitous and mobile devices; • Human-centered computing → Personal digital assistants KEYWORDS Personification; anthropomorphism; ontology; voice assistants; smart speakers; older adults. ACM Reference format: Alisha Pradhan, Leah Findlater and Amanda Lazar. -

Samrt Speakers Growth at a Discount.Pdf
Technology, Media, and Telecommunications Predictions 2019 Deloitte’s Technology, Media, and Telecommunications (TMT) group brings together one of the world’s largest pools of industry experts—respected for helping companies of all shapes and sizes thrive in a digital world. Deloitte’s TMT specialists can help companies take advantage of the ever- changing industry through a broad array of services designed to meet companies wherever they are, across the value chain and around the globe. Contact the authors for more information or read more on Deloitte.com. Technology, Media, and Telecommunications Predictions 2019 Contents Foreword | 2 Smart speakers: Growth at a discount | 24 1 Technology, Media, and Telecommunications Predictions 2019 Foreword Dear reader, Welcome to Deloitte Global’s Technology, Media, and Telecommunications Predictions for 2019. The theme this year is one of continuity—as evolution rather than stasis. Predictions has been published since 2001. Back in 2009 and 2010, we wrote about the launch of exciting new fourth-generation wireless networks called 4G (aka LTE). A decade later, we’re now making predic- tions about 5G networks that will be launching this year. Not surprisingly, our forecast for the first year of 5G is that it will look a lot like the first year of 4G in terms of units, revenues, and rollout. But while the forecast may look familiar, the high data speeds and low latency 5G provides could spur the evolution of mobility, health care, manufacturing, and nearly every industry that relies on connectivity. In previous reports, we also wrote about 3D printing (aka additive manufacturing). Our tone was posi- tive but cautious, since 3D printing was growing but also a bit overhyped. -

Your Voice Assistant Is Mine: How to Abuse Speakers to Steal Information and Control Your Phone ∗ †
Your Voice Assistant is Mine: How to Abuse Speakers to Steal Information and Control Your Phone ∗ y Wenrui Diao, Xiangyu Liu, Zhe Zhou, and Kehuan Zhang Department of Information Engineering The Chinese University of Hong Kong {dw013, lx012, zz113, khzhang}@ie.cuhk.edu.hk ABSTRACT General Terms Previous research about sensor based attacks on Android platform Security focused mainly on accessing or controlling over sensitive compo- nents, such as camera, microphone and GPS. These approaches Keywords obtain data from sensors directly and need corresponding sensor invoking permissions. Android Security; Speaker; Voice Assistant; Permission Bypass- This paper presents a novel approach (GVS-Attack) to launch ing; Zero Permission Attack permission bypassing attacks from a zero-permission Android application (VoicEmployer) through the phone speaker. The idea of 1. INTRODUCTION GVS-Attack is to utilize an Android system built-in voice assistant In recent years, smartphones are becoming more and more popu- module – Google Voice Search. With Android Intent mechanism, lar, among which Android OS pushed past 80% market share [32]. VoicEmployer can bring Google Voice Search to foreground, and One attraction of smartphones is that users can install applications then plays prepared audio files (like “call number 1234 5678”) in (apps for short) as their wishes conveniently. But this convenience the background. Google Voice Search can recognize this voice also brings serious problems of malicious application, which have command and perform corresponding operations. With ingenious been noticed by both academic and industry fields. According to design, our GVS-Attack can forge SMS/Email, access privacy Kaspersky’s annual security report [34], Android platform attracted information, transmit sensitive data and achieve remote control a whopping 98.05% of known malware in 2013. -

Smart Speakers & Their Impact on Music Consumption
Everybody’s Talkin’ Smart Speakers & their impact on music consumption A special report by Music Ally for the BPI and the Entertainment Retailers Association Contents 02"Forewords 04"Executive Summary 07"Devices Guide 18"Market Data 22"The Impact on Music 34"What Comes Next? Forewords Geoff Taylor, chief executive of the BPI, and Kim Bayley, chief executive of ERA, on the potential of smart speakers for artists 1 and the music industry Forewords Kim Bayley, CEO! Geoff Taylor, CEO! Entertainment Retailers Association BPI and BRIT Awards Music began with the human voice. It is the instrument which virtually Smart speakers are poised to kickstart the next stage of the music all are born with. So how appropriate that the voice is fast emerging as streaming revolution. With fans consuming more than 100 billion the future of entertainment technology. streams of music in 2017 (audio and video), streaming has overtaken CD to become the dominant format in the music mix. The iTunes Store decoupled music buying from the disc; Spotify decoupled music access from ownership: now voice control frees music Smart speakers will undoubtedly give streaming a further boost, from the keyboard. In the process it promises music fans a more fluid attracting more casual listeners into subscription music services, as and personal relationship with the music they love. It also offers a real music is the killer app for these devices. solution to optimising streaming for the automobile. Playlists curated by streaming services are already an essential Naturally there are challenges too. The music industry has struggled to marketing channel for music, and their influence will only increase as deliver the metadata required in a digital music environment. -

A Technical Assistance Guide on Integrated Early Childhood Programs
DOCUMENT RESUME ED 361 957 EC 302 427 AUTHOR Holden, Leah; And Others TITLE Wilting Integration: A Technical Assistance Guideon Integrated Early Childhood Programs. The Early Integration Training Project. INSTITUTION Ohio State Univ., Columbus. Center for Special Needs Populations. SPONS AGENCY Special Education Programs (ED/OSERS), Washington, DC. Early Education Program for Children with Disabilities. PUB DATE 93 CONTRACT 24P90004 NOTE 118p. AVAILABLE FROMNCHRTM-Special Education, Oklahoma State University, 816 West 6th St., Stillwater, OK 74078-0435 ($11.25, including postage and handling). PUB TYPE Guides Non-Classroom Use (055) EDRS PRICE MF01/PC05 Plus Postage. DESCRIPTORS Change Strategies; Classroom Environment; Conflict Resolution; *Disabilities; Early Childhood Education; Early Intervention; Educational Change; *Edutzational Practices; Family Involvement; Handicrafts; Leadership; *Mainstreaming; Normalization (Handicapped); *Program Development; *Social Integration; Student Characteristics; Teamwork; Technical Assistance IDENTIFIERS *Quilting ABSTRACT This guide was developed to help people meet the challenge of developing early childhoodprograms that are inclusive of all children, regardless of disability. The manualwas written in the spirit of a quilting book, in its recognition of the importance of the quiltmaker's (and the program developer's)own adaptations, creativity, and inspiration. Quotations from quilting booksand illustrations of popular quilting patternsare included in the margin notes. The manual was assembled -

Gilmore Girls Movie List
Gilmore Girls Movie List 2 Fast 2 Furious Anywhere But Here Boy in the Plastic 2000 Year Old Apocalypse Now Bubble, The Man, The Arctic Flight Brazil 2001: A Space Armageddon Breakfast at Odyssey Arrival of a Train, Tiffany's 40 Year Old Virgin, The Breakfast Club, The Arthur The 8 Mile Attack of the 50 Breakin' 2: Electric A.I. Artificial Foot Women Boogaloo Intelligence Austin Powers: The Breaking Away A Beautiful Mind Spy Who Shagged Brian's Song A Brief History of Me Bride of Chucky Time Auto Focus Bridge on the River A Nightmare on Elm Autumn in New Kwai, The Street York Bridges of Madison A Room with a Babe County, The View Babe: Pig in the Bright Eyes A Star Is Born City Bring Me the Head A Streetcar Named Back to the Future of Alfredo Garcia Desire Bad Seed, The Bringing Up Baby A Woman Under Bambi Broadcast News The Influence Banger Sisters, The Broadway Danny Ace Ventura: Pet Barbarella Rose Detective Basic Instinct Brokeback Alice Doesn't Live Beaches Mountain Here Anymore Beethoven Brown Bunny, The Alice In Ben-Hur Bugsy Wonderland Being There Bugsy Malone Alive Bend It Like Bull Durham All About Eve Beckham Bullets Over All in the Family Benji Broadway All the President's Better Off Dead… Butch Cassidy and Men Beverly Hills Cop the Sundance Kid Almost Famous Bewitched BUtterfield 8 American Gigolo Big One, The Bye Bye Birdie American Splendor Blades of Glory Cabaret Amityville Horror, Blow Cabin Boy The Blue Crush Caged Heat An Affair to Blue -

Reuters Institute: the Future of Voice and the Implications for News
DIGITAL NEWS PROJECT NOVEMBER 2018 The Future of Voice and the Implications for News Nic Newman Contents About the Author 4 Acknowledgements 4 Executive Summary 5 1. Methodology and Approach 8 2. What is Voice? 10 3. How Voice is Being Used Today 14 4. News Usage in Detail 23 5. Publisher Strategies and Monetisation 32 6. Future Developments and Conclusions 40 References 43 Appendix: List of Interviewees 44 THE REUTERS INSTITUTE FOR THE STUDY OF JOURNALISM About the Author Nic Newman is Senior Research Associate at the Reuters Institute and lead author of the Digital News Report, as well as an annual study looking at trends in technology and journalism. He is also a consultant on digital media, working actively with news companies on product, audience, and business strategies for digital transition. Acknowledgements The author is particularly grateful to media companies and experts for giving their time to share insights for this report in such an enthusiastic and open way. Particular thanks, also, to Peter Stewart for his early encouragement and for his extremely informative daily Alexa ‘flash briefings’ on the ever changing voice scene. The author is also grateful to Differentology andY ouGov for the professionalism with which they carried out the qualitative and quantitative research respectively and for the flexibility in accommodating our complex and often changing requirements. The research team at the Reuters Institute provided valuable advice on methodology and content and the author is grateful to Lucas Graves and Rasmus Kleis Nielsen for their constructive and thoughtful comments on the manuscript. Also thanks to Alex Reid at the Reuters Institute for keeping the publication on track at all times. -

Western Outlaws and Angels
‘SAND DOLLAR COVE’ Cast Bios CHAD MICHAEL MURRAY (Brody) – Chad Michael Murray first rose to prominence with fan favorite roles on the Warner Bros. dramas “Dawson’s Creek” and “Gilmore Girls.” He became a household name with his leading role as Lucas Scott in the massive Warner Bros. television hit “One Tree Hill” from 2003-2012, during which he won three Teen Choice Awards. He showcased his talents as a leading actor playing the outcast-turned-cool-kid throughout his near-decade run. He took position behind the camera as well, both writing and directing an episode of the series. Murray is currently in production on the action-thriller Killing Field, starring as Eric, a man whose life on his serene farm is interrupted when a cop and a pair of dangerous criminals shows up. Bruce Willis, Kate Katzman, Donna D’errico, Swen Temmel, and Zack Ward also star. Murray most recently wrapped production on Ted Bundy: American Boogeyman, starring as America’s most infamous serial killer. The film is slated for theatrical release in August 2021 through Fathom Events. He will also be seen in the upcoming “The Fortress” and “The Fortress 2,” also starring Bruce Willis as well as Jesse Metcalfe. Recently, he starred in the television movies “Colors of Love” and “Too Close for Christmas,” both opposite Jessica Lowndes. Murray has also starred in Lionsgate’s 2020 action film “Survive the Night” alongside Bruce Willis; the Hallmark Channel original movie “Write Before Christmas,” alongside Torrey DeVitto; seasons three and four of the hit teen drama “Riverdale,” in which he played an enigmatic cult leader; and as Atticus Virtue in the family sci-fi thriller Max Winslow and the House of Secrets, which told the story of five teenagers who competed to win a mansion owned by entrepreneur and scientist, Virtue. -
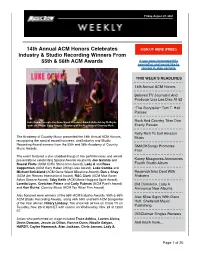
14Th Annual ACM Honors Celebrates Industry & Studio Recording Winners from 55Th & 56Th ACM Awards
August 27, 2021 The MusicRow Weekly Friday, August 27, 2021 14th Annual ACM Honors Celebrates SIGN UP HERE (FREE!) Industry & Studio Recording Winners From 55th & 56th ACM Awards If you were forwarded this newsletter and would like to receive it, sign up here. THIS WEEK’S HEADLINES 14th Annual ACM Honors Beloved TV Journalist And Producer Lisa Lee Dies At 52 “The Storyteller“ Tom T. Hall Passes Luke Combs accepts the Gene Weed Milestone Award while Ashley McBryde Rock And Country Titan Don looks on. Photo: Getty Images / Courtesy of the Academy of Country Music Everly Passes Kelly Rich To Exit Amazon The Academy of Country Music presented the 14th Annual ACM Honors, Music recognizing the special award honorees, and Industry and Studio Recording Award winners from the 55th and 56th Academy of Country SMACKSongs Promotes Music Awards. Four The event featured a star-studded lineup of live performances and award presentations celebrating Special Awards recipients Joe Galante and Kacey Musgraves Announces Rascal Flatts (ACM Cliffie Stone Icon Award), Lady A and Ross Fourth Studio Album Copperman (ACM Gary Haber Lifting Lives Award), Luke Combs and Michael Strickland (ACM Gene Weed Milestone Award), Dan + Shay Reservoir Inks Deal With (ACM Jim Reeves International Award), RAC Clark (ACM Mae Boren Alabama Axton Service Award), Toby Keith (ACM Merle Haggard Spirit Award), Loretta Lynn, Gretchen Peters and Curly Putman (ACM Poet’s Award) Old Dominion, Lady A and Ken Burns’ Country Music (ACM Tex Ritter Film Award). Announce New Albums Also honored were winners of the 55th ACM Industry Awards, 55th & 56th Alex Kline Signs With Dann ACM Studio Recording Awards, along with 55th and 56th ACM Songwriter Huff, Sheltered Music of the Year winner, Hillary Lindsey. -

Understanding and Mitigating Security Risks of Voice-Controlled Third-Party Functions on Virtual Personal Assistant Systems
Dangerous Skills: Understanding and Mitigating Security Risks of Voice-Controlled Third-Party Functions on Virtual Personal Assistant Systems Nan Zhang∗, Xianghang Mi∗, Xuan Fengy∗, XiaoFeng Wang∗, Yuan Tianz and Feng Qian∗ ∗Indiana University, Bloomington Email: fnz3, xmi, xw7, [email protected] yBeijing Key Laboratory of IOT Information Security Technology, Institute of Information Engineering, CAS, China Email: [email protected] zUniversity of Virginia Email: [email protected] Abstract—Virtual personal assistants (VPA) (e.g., Amazon skills by Amazon and actions by Google1) to offer further Alexa and Google Assistant) today mostly rely on the voice helps to the end users, for example, order food, manage bank channel to communicate with their users, which however is accounts and text friends. In the past year, these ecosystems known to be vulnerable, lacking proper authentication (from the user to the VPA). A new authentication challenge, from the VPA are expanding at a breathtaking pace: Amazon claims that service to the user, has emerged with the rapid growth of the VPA already 25,000 skills have been uploaded to its skill market to ecosystem, which allows a third party to publish a function (called support its VPA (including the Alexa service running through skill) for the service and therefore can be exploited to spread Amazon Echo) [1] and Google also has more than one thousand malicious skills to a large audience during their interactions actions available on its market for its Google Home system with smart speakers like Amazon Echo and Google Home. In this paper, we report a study that concludes such remote, large- (powered by Google Assistant).