A Web Tool for Super-Enhancer Associated
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Multidrug Transporter MRP4/ABCC4 As a Key Determinant of Pancreatic
www.nature.com/scientificreports OPEN Multidrug transporter MRP4/ ABCC4 as a key determinant of pancreatic cancer aggressiveness A. Sahores1, A. Carozzo1, M. May1, N. Gómez1, N. Di Siervi1, M. De Sousa Serro1, A. Yanef1, A. Rodríguez‑González2, M. Abba3, C. Shayo2 & C. Davio1* Recent fndings show that MRP4 is critical for pancreatic ductal adenocarcinoma (PDAC) cell proliferation. Nevertheless, the signifcance of MRP4 protein levels and function in PDAC progression is still unclear. The aim of this study was to determine the role of MRP4 in PDAC tumor aggressiveness. Bioinformatic studies revealed that PDAC samples show higher MRP4 transcript levels compared to normal adjacent pancreatic tissue and circulating tumor cells express higher levels of MRP4 than primary tumors. Also, high levels of MRP4 are typical of high-grade PDAC cell lines and associate with an epithelial-mesenchymal phenotype. Moreover, PDAC patients with high levels of MRP4 depict dysregulation of pathways associated with migration, chemotaxis and cell adhesion. Silencing MRP4 in PANC1 cells reduced tumorigenicity and tumor growth and impaired cell migration. Transcriptomic analysis revealed that MRP4 silencing alters PANC1 gene expression, mainly dysregulating pathways related to cell-to-cell interactions and focal adhesion. Contrarily, MRP4 overexpression signifcantly increased BxPC-3 growth rate, produced a switch in the expression of EMT markers, and enhanced experimental metastatic incidence. Altogether, our results indicate that MRP4 is associated with a more aggressive phenotype in PDAC, boosting pancreatic tumorigenesis and metastatic capacity, which could fnally determine a fast tumor progression in PDAC patients. Pancreatic ductal adenocarcinoma (PDAC) is one of the most lethal human malignancies, due to its late diag- nosis, inherent resistance to treatment and early dissemination 1. -

Role of RUNX1 in Aberrant Retinal Angiogenesis Jonathan D
Page 1 of 25 Diabetes Identification of RUNX1 as a mediator of aberrant retinal angiogenesis Short Title: Role of RUNX1 in aberrant retinal angiogenesis Jonathan D. Lam,†1 Daniel J. Oh,†1 Lindsay L. Wong,1 Dhanesh Amarnani,1 Cindy Park- Windhol,1 Angie V. Sanchez,1 Jonathan Cardona-Velez,1,2 Declan McGuone,3 Anat O. Stemmer- Rachamimov,3 Dean Eliott,4 Diane R. Bielenberg,5 Tave van Zyl,4 Lishuang Shen,1 Xiaowu Gai,6 Patricia A. D’Amore*,1,7 Leo A. Kim*,1,4 Joseph F. Arboleda-Velasquez*1 Author affiliations: 1Schepens Eye Research Institute/Massachusetts Eye and Ear, Department of Ophthalmology, Harvard Medical School, 20 Staniford St., Boston, MA 02114 2Universidad Pontificia Bolivariana, Medellin, Colombia, #68- a, Cq. 1 #68305, Medellín, Antioquia, Colombia 3C.S. Kubik Laboratory for Neuropathology, Massachusetts General Hospital, 55 Fruit St., Boston, MA 02114 4Retina Service, Massachusetts Eye and Ear Infirmary, Department of Ophthalmology, Harvard Medical School, 243 Charles St., Boston, MA 02114 5Vascular Biology Program, Boston Children’s Hospital, Department of Surgery, Harvard Medical School, 300 Longwood Ave., Boston, MA 02115 6Center for Personalized Medicine, Children’s Hospital Los Angeles, Los Angeles, 4650 Sunset Blvd, Los Angeles, CA 90027, USA 7Department of Pathology, Harvard Medical School, 25 Shattuck St., Boston, MA 02115 Corresponding authors: Joseph F. Arboleda-Velasquez: [email protected] Ph: (617) 912-2517 Leo Kim: [email protected] Ph: (617) 912-2562 Patricia D’Amore: [email protected] Ph: (617) 912-2559 Fax: (617) 912-0128 20 Staniford St. Boston MA, 02114 † These authors contributed equally to this manuscript Word Count: 1905 Tables and Figures: 4 Diabetes Publish Ahead of Print, published online April 11, 2017 Diabetes Page 2 of 25 Abstract Proliferative diabetic retinopathy (PDR) is a common cause of blindness in the developed world’s working adult population, and affects those with type 1 and type 2 diabetes mellitus. -

Bcl-2–Modifying Factor Induces Renal Proximal Tubular Cell Apoptosis in Diabetic Mice Garnet J
ORIGINAL ARTICLE Bcl-2–Modifying Factor Induces Renal Proximal Tubular Cell Apoptosis in Diabetic Mice Garnet J. Lau,1 Nicolas Godin,1 Hasna Maachi,1 Chao-Sheng Lo,1 Shyh-Jong Wu,1 Jian-Xin Zhu,1 Marie-Luise Brezniceanu,1 Isabelle Chénier,1 Joelle Fragasso-Marquis,1 Jean-Baptiste Lattouf,1 Jean Ethier,1 Janos G. Filep,2 Julie R. Ingelfinger,3 Viji Nair,4 Matthias Kretzler,4 Clemens D. Cohen,5 Shao-Ling Zhang,1 and John S.D. Chan1 – This study investigated the mechanisms underlying tubular apopto- than glomerular pathology (2 5). For example, examination sis in diabetes by identifying proapoptotic genes that are differen- of nephrons from proteinuric diabetic patients shows that tially upregulated by reactive oxygen species in renal proximal 71% of glomeruli display glomerulotubular junction abnor- tubular cells (RPTCs) in models of diabetes. Total RNAs isolated malities and 8–17% of glomeruli are atubular glomeruli (6,7). from renal proximal tubules (RPTs) of 20-week-old heterozygous The mechanisms underlying tubular atrophy are incom- db/m+, db/db,anddb/db catalase (CAT)-transgenic (Tg) mice were pletely delineated. Studies have shown that high glucose used for DNA chip microarray analysis. Real-time quantitative PCR (HG) concentrations are associated with increased reactive assays, immunohistochemistry, and mice rendered diabetic with oxygen species (ROS) production, which inhibits proximal streptozotocin were used to validate the proapoptotic gene expres- – sion in RPTs. Cultured rat RPTCs were used to confirm the apoptotic tubular function and induces apoptosis (8 10). Apoptosis activity and regulation of proapoptotic gene expression. Addition- has been detected in renal proximal tubular cells (RPTCs) ally, studies in kidney tissues from patients with and without diabe- of diabetic mice (11,12) and rats (13,14) as well as in RPTCs teswereusedtoconfirm enhanced proapoptotic gene expression in of diabetic patients (15–17), suggesting that tubular apo- RPTs. -
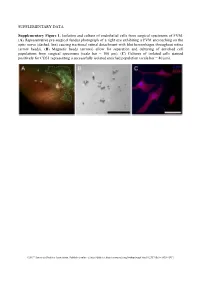
Supplementary Figures and Tables
SUPPLEMENTARY DATA Supplementary Figure 1. Isolation and culture of endothelial cells from surgical specimens of FVM. (A) Representative pre-surgical fundus photograph of a right eye exhibiting a FVM encroaching on the optic nerve (dashed line) causing tractional retinal detachment with blot hemorrhages throughout retina (arrow heads). (B) Magnetic beads (arrows) allow for separation and culturing of enriched cell populations from surgical specimens (scale bar = 100 μm). (C) Cultures of isolated cells stained positively for CD31 representing a successfully isolated enriched population (scale bar = 40 μm). ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Figure 2. Efficient siRNA knockdown of RUNX1 expression and function demonstrated by qRT-PCR, Western Blot, and scratch assay. (A) RUNX1 siRNA induced a 60% reduction of RUNX1 expression measured by qRT-PCR 48 hrs post-transfection whereas expression of RUNX2 and RUNX3, the two other mammalian RUNX orthologues, showed no significant changes, indicating specificity of our siRNA. Functional inhibition of Runx1 signaling was demonstrated by a 330% increase in insulin-like growth factor binding protein-3 (IGFBP3) RNA expression level, a known target of RUNX1 inhibition. Western blot demonstrated similar reduction in protein levels. (B) siRNA- 2’s effect on RUNX1 was validated by qRT-PCR and western blot, demonstrating a similar reduction in both RNA and protein. Scratch assay demonstrates functional inhibition of RUNX1 by siRNA-2. ns: not significant, * p < 0.05, *** p < 0.001 ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Table 1. -

Supplemental Information
Supplemental Information Supplemental Figures Supplemental Figure 1. Quantitation of bioluminescent imaging data in Figure 1B. 1 Supplemental Figure 2. Impact of Brg1 shRNAs on proliferation of immortalized murine embryonic fibroblasts (iMEFs), BCR-ABL/p19-/- B cell acute lymphoblastic leukemia (B-ALL), murine breast cancer cells (4T1), and BrafV600E melanoma. A) shRNA/GFP competition assay in indicated murine cell lines. Rpa3 shRNA targeting replication protein A3 serves as a positive control. shRNA targeting Renilla luciferase is included as a negative control. B) Western blotting for additional Brg1 shRNAs in the indicated cell lines transduced with the Ren or Brg1 LMN-shRNAs. A representative experiment of three biological replicates is shown. 2 Supplemental Figure 3. Effect of Brg1 shRNAs on proliferation of human leukemia cell lines. A) shRNA/GFP competition assay in the indicated human cell lines with shRen.713, shBrg1.4471, or shSpt16.3249. All shRNAs were evaluated in a timecourse of GFP% measurements at days 4, 8, 12, 16, 20, and 24. CML-BC indicates chronic myeloid leukemia blast crisis. B) Western blotting of SPT16 levels in whole cell lysates prepared from HeLa cells transduced with the indicated MLP shRNA constructs following puromycin selection. 3 Supplemental Figure 4. Expression and functional validation of SWI/SNF subunits in MLL-AF9/NrasG12D leukemia. A) RPKM values for genes encoding SWI/SNF complex subunits from polyA+ tail RNA-seq performed in RN2 cell line. B) shRNA/GFP competition assay with two independent shRNAs targeting indicated SWI/SNF subunits. Experiments were performed in RN2 cells as in Figure 1A. n=2-3. C) RT-qPCR was performed to test the knockdown efficiency of indicted SWI/SNF subunit shRNAs. -

GATA2 Regulates Mast Cell Identity and Responsiveness to Antigenic Stimulation by Promoting Chromatin Remodeling at Super- Enhancers
ARTICLE https://doi.org/10.1038/s41467-020-20766-0 OPEN GATA2 regulates mast cell identity and responsiveness to antigenic stimulation by promoting chromatin remodeling at super- enhancers Yapeng Li1, Junfeng Gao 1, Mohammad Kamran1, Laura Harmacek2, Thomas Danhorn 2, Sonia M. Leach1,2, ✉ Brian P. O’Connor2, James R. Hagman 1,3 & Hua Huang 1,3 1234567890():,; Mast cells are critical effectors of allergic inflammation and protection against parasitic infections. We previously demonstrated that transcription factors GATA2 and MITF are the mast cell lineage-determining factors. However, it is unclear whether these lineage- determining factors regulate chromatin accessibility at mast cell enhancer regions. In this study, we demonstrate that GATA2 promotes chromatin accessibility at the super-enhancers of mast cell identity genes and primes both typical and super-enhancers at genes that respond to antigenic stimulation. We find that the number and densities of GATA2- but not MITF-bound sites at the super-enhancers are several folds higher than that at the typical enhancers. Our studies reveal that GATA2 promotes robust gene transcription to maintain mast cell identity and respond to antigenic stimulation by binding to super-enhancer regions with dense GATA2 binding sites available at key mast cell genes. 1 Department of Immunology and Genomic Medicine, National Jewish Health, Denver, CO 80206, USA. 2 Center for Genes, Environment and Health, National Jewish Health, Denver, CO 80206, USA. 3 Department of Immunology and Microbiology, University of Colorado Anschutz Medical Campus, Aurora, ✉ CO 80045, USA. email: [email protected] NATURE COMMUNICATIONS | (2021) 12:494 | https://doi.org/10.1038/s41467-020-20766-0 | www.nature.com/naturecommunications 1 ARTICLE NATURE COMMUNICATIONS | https://doi.org/10.1038/s41467-020-20766-0 ast cells (MCs) are critical effectors in immunity that at key MC genes. -

Proteins Interact with Their Pro-Survival Partner MCL-1
Promiscuous and selective: how intrinsically disordered BH3- proteins interact with their pro-survival partner MCL-1. Liza Dahal, Tristan O.C. Kwan, Jeffery J. Hollins and Jane Clarke1 1Corresponding author, Email: [email protected] Department of Chemistry, University of Cambridge, Lensfield Road, Cambridge, CB2 1EW Highlights • Despite differences in residual helicity BH3 peptides bind equally fast to MCL-1. • Differences in stabilities results from off-rates, altering complex lifetimes. • This difference arises from variation in interactions at MCL-1 binding interface. GRAPHICAL ABSTRACT Promiscuous and selective: how intrinsically disordered BH3- proteins interact with their pro-survival partner MCL-1. Liza Dahal, Tristan O.C. Kwan, JefFery J. Hollins and Jane Clarke1 1Corresponding author, Email: [email protected] Department of Chemistry, University of Cambridge, Lensfield Road, Cambridge, CB2 1EW Abstract 1 The BCL-2 family of proteins plays a central role in regulating cell survival and apoptosis. Disordered BH3-only proteins bind promiscuously to a number of different BCL-2 proteins, with binding affinities that vary by orders of magnitude. Here we investigate the basis for these differences in affinity. We show that eight different disordered BH3 proteins all bind to their BCL-2 partner (MCL-1) very rapidly, and that the differences in sequences result in different dissociation rates. Similarly, mutation of the binding surface of MCL-1 generally affects association kinetics in the same way for all BH3 peptides but has significantly -

CLDND1 (NM 001040183) Human Tagged ORF Clone – RC211544
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for RC211544 CLDND1 (NM_001040183) Human Tagged ORF Clone Product data: Product Type: Expression Plasmids Product Name: CLDND1 (NM_001040183) Human Tagged ORF Clone Tag: Myc-DDK Symbol: CLDND1 Synonyms: C3orf4; GENX-3745; Z38 Vector: pCMV6-Entry (PS100001) E. coli Selection: Kanamycin (25 ug/mL) Cell Selection: Neomycin ORF Nucleotide >RC211544 ORF sequence Sequence: Red=Cloning site Blue=ORF Green=Tags(s) TTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCC GCCGCGATCGCC ATGGATAACCGTTTTGCTACAGCATTTGTAATTGCTTGTGTGCTGAGCCTCATTTCCACCATCTACATGG CAGCCTCCATTGGCACAGACTTCTGGTATGAATATCGAAGTCCAGTTCAAGAAAATTCCAGTGATTTGAA TAAAAGCATCTGGGATGAATTCATTAGTGATGAGGCAGATGAAAAGACTTATAATGATGCACTTTTTCGA TACAATGGCACAGTGGGATTGTGGAGACGGTGTATCACCATACCCAAAAACATGCATTGGTATAGCCCAC CAGAAAGGACAGAGTCATTTGATGTGGTCACAAAATGTGTGAGTTTCACACTAACTGAGCAGTTCATGGA GAAATTTGTTGATCCCGGAAACCACAATAGCGGGATTGATCTCCTTAGGACCTATCTTTGGCGTTGCCAG TTCCTTTTACCTTTTGTGAGTTTAGGTTTGATGTGCTTTGGGGCTTTGATCGGACTTTGTGCTTGCATTT GCCGAAGCTTATATCCCACCATTGCCACGGGCATTCTCCATCTCCTTGCAGGTCTGTGTACACTGGGCTC AGTAAGTTGTTATGTTGCTGGAATTGAACTACTCCACCAGAAACTAGAGCTCCCTGACAATGTATCCGGT GAATTTGGATGGTCCTTCTGCCTGGCTTGTGTCTCTGCTCCCTTACAGTTCATGGCTTCTGCTCTCTTCA TCTGGGCTGCTCACACCAACCGGAAAGAGTACACCTTAATGAAGGCATATCGTGTGGCA ACGCGTACGCGGCCGCTCGAGCAGAAACTCATCTCAGAAGAGGATCTGGCAGCAAATGATATCCTGGATT ACAAGGATGACGACGATAAGGTTTAA -

Transcriptional Regulation of Cancer Genes in the Xiphophorus
Transcriptional regulation of cancer genes in the Xiphophorus melanoma system Dissertation zur Erlangung des naturwissenschaftlichen Doktorgrades der Julius-Maximilians-Universität Würzburg vorgelegt von Janine Regneri aus Herdecke Würzburg 2013 Eingereicht am: ....................................................................................................................... Mitglieder der Promotionskommission: Vorsitzender: .......................................................................................................................... Gutachter : .............................................................................................................................. Gutachter: ............................................................................................................................... Tag des Promotionskolloquiums: ............................................................................................. Doktorurkunde ausgehändigt am: ............................................................................................ Eidesstattliche Erklärung Gemäß §4, Abs. 3, Ziff. 3, 5 und 8 der Promotionsordnung der Fakultät für Biologie der Bayerischen Julius-Maximilians-Universität Würzburg Hiermit erkläre ich ehrenwörtlich, dass ich die vorliegende Dissertation selbständig angefertigt und keine anderen als die angegebenen Quellen und Hilfsmittel verwendet habe. Ich erkläre weiterhin, dass die vorliegende Dissertation weder in gleicher, noch in ähnlicher Form bereits in einem anderen Prüfungsverfahren -

Database and Bioinformatic Analysis of BCL-2 Family Proteins and BH3-Only Proteins Abdel Aouacheria, Vincent Navratil, Christophe Combet
Database and Bioinformatic Analysis of BCL-2 Family Proteins and BH3-Only Proteins Abdel Aouacheria, Vincent Navratil, Christophe Combet To cite this version: Abdel Aouacheria, Vincent Navratil, Christophe Combet. Database and Bioinformatic Analysis of BCL-2 Family Proteins and BH3-Only Proteins. Gavathiotis E. BCL-2 Family Proteins. Methods in Molecular Biology, 1877, Springer Nature, pp.23-43, 2019, Methods in Molecular Biology, 978-1-4939- 8860-0. 10.1007/978-1-4939-8861-7_2. hal-02347884 HAL Id: hal-02347884 https://hal.archives-ouvertes.fr/hal-02347884 Submitted on 5 Nov 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Copyright Database and bioinformatic analysis of BCL-2 family proteins and BH3-only proteins Abdel Aouacheria 1,*, Vincent Navratil 2 and Christophe Combet 3 1 ISEM, Institut des Sciences de l’Evolution de Montpellier, Université de Montpellier, UMR 5554, CNRS, IRD, EPHE, Place Eugène Bataillon, 34095 Montpellier, France 2 PRABI, Rhône Alpes Bioinformatics Center, UCBL, Lyon1, Université de Lyon, Lyon, France. 3 Centre de Recherche en Cancérologie de Lyon, UMR Inserm U1052, CNRS 5286, Université Claude Bernard Lyon 1, Centre Léon Bérard, Lyon, France. -

Gene Expression in Blood Reflects Smoking Exposure Among Cancer
www.nature.com/scientificreports OPEN Gene expression in blood refects smoking exposure among cancer‑free women in the Norwegian Women and Cancer (NOWAC) postgenome cohort Nikita Baiju1*, Torkjel M. Sandanger1, Pål Sætrom2,3,4,5 & Therese H. Nøst1,5 Active smoking has been linked to modulated gene expression in blood. However, there is a need for a more thorough understanding of how quantitative measures of smoking exposure relate to diferentially expressed genes (DEGs) in whole‑blood among ever smokers. This study analysed microarray‑based gene expression profles from whole‑blood samples according to smoking status and quantitative measures of smoking exposure among cancer‑free women (n = 1708) in the Norwegian Women and Cancer postgenome cohort. When compared with never smokers and former smokers, current smokers had 911 and 1082 DEGs, respectively and their biological functions could indicate systemic impacts of smoking. LRRN3 was associated with smoking status with the lowest FDR‑adjusted p‑value. When never smokers and all former smokers were compared, no DEGs were observed, but LRRN3 was diferentially expressed when never smokers were compared with former smokers who quit smoking ≤ 10 years ago. Further, LRRN3 was positively associated with smoking intensity, pack‑years, and comprehensive smoking index score among current smokers; and negatively associated with time since cessation among former smokers. Consequently, LRRN3 expression in whole‑blood is a molecular signal of smoking exposure that could supplant self‑reported smoking data in further research targeting blood‑based markers related to the health efects of smoking. Tobacco smoking is one of the major threats to public health, and it is currently responsible for more than 8 million deaths worldwide each year 1. -

Cldnd1 (NM 171826) Mouse Tagged ORF Clone – MR203231 | Origene
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for MR203231 Cldnd1 (NM_171826) Mouse Tagged ORF Clone Product data: Product Type: Expression Plasmids Product Name: Cldnd1 (NM_171826) Mouse Tagged ORF Clone Tag: Myc-DDK Symbol: Cldnd1 Synonyms: 1110019C08Rik; AA407103; AI849195; AW489850; Cldn25 Vector: pCMV6-Entry (PS100001) E. coli Selection: Kanamycin (25 ug/mL) Cell Selection: Neomycin ORF Nucleotide >MR203231 ORF sequence Sequence: Red=Cloning site Blue=ORF Green=Tags(s) TTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCC GCCGCGATCGCC ATGGATAACCGTTTTGCTACTGCGTTTGTGATTGCTTGTGTGCTTAGTCTGATTTCCACCATCTACATGG CGGCCTCCATAGGCACGGACTTCTGGTATGAGTATCGAAGTCCCATTCAAGAGAATTCAAGTGACTCGAA TAAAATCGCCTGGGAAGATTTCCTCGGTGACGAGGCGGATGAGAAGACTTACAACGATGTTCTGTTCCGA TACAACGGCAGCTTGGGGCTGTGGAGACGGTGCATCACCATACCCAAAAACACTCACTGGTATGCGCCAC CGGAAAGGACAGAGTCATTTGATGTGGTTACCAAATGCATGAGTTTCACACTAAACGAGCAGTTCATGGA GAAGTATGTGGACCCCGGCAACCACAATAGCGGCATCGACCTGCTTCGCACCTACCTGTGGCGCTGCCAG TTCCTTTTACCCTTCGTCAGCTTGGGCTTGATGTGCTTTGGGGCGTTGATTGGCCTCTGTGCCTGTATCT GCCGCAGCCTGTATCCCACCCTCGCCACTGGCATTCTCCATCTCCTTGCAGGTCTGTGCACACTGGGCTC CGTGAGTTGCTATGTTGCCGGCATTGAACTCTTACATCAGAAAGTAGAGCTGCCCAAGGATGTATCTGGA GAATTTGGATGGTCCTTCTGCCTGGCCTGCGTCTCGGCTCCCTTACAGTTCATGGCGGCCGCTCTCTTCA TCTGGGCTGCCCACACCAACCGGAAAGAGTACACCTTAATGAAGGCTTATCGTGTGGCA ACGCGTACGCGGCCGCTCGAGCAGAAACTCATCTCAGAAGAGGATCTGGCAGCAAATGATATCCTGGATT