Colloquium October 2006
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Redalyc.Toolkits and Cultural Lexicon: an Ethnographic
Indiana ISSN: 0341-8642 [email protected] Ibero-Amerikanisches Institut Preußischer Kulturbesitz Alemania Andrade Ciudad, Luis; Joffré, Gabriel Ramón Toolkits and Cultural Lexicon: An Ethnographic Comparison of Pottery and Weaving in the Northern Peruvian Andes Indiana, vol. 31, 2014, pp. 291-320 Ibero-Amerikanisches Institut Preußischer Kulturbesitz Berlin, Alemania Available in: http://www.redalyc.org/articulo.oa?id=247033484009 How to cite Complete issue Scientific Information System More information about this article Network of Scientific Journals from Latin America, the Caribbean, Spain and Portugal Journal's homepage in redalyc.org Non-profit academic project, developed under the open access initiative Toolkits and Cultural Lexicon: An Ethnographic Comparison of Pottery and Weaving in the Northern Peruvian Andes Luis Andrade Ciudad and Gabriel Ramón Joffré Ponticia Universidad Católica del Perú, Lima, Perú Abstract: The ndings of an ethnographic comparison of pottery and weaving in the Northern Andes of Peru are presented. The project was carried out in villages of the six southern provinces of the department of Cajamarca. The comparison was performed tak- ing into account two parameters: technical uniformity or diversity in ‘plain’ pottery and weaving, and presence or absence of lexical items of indigenous origin – both Quechua and pre-Quechua – in the vocabulary of both handicraft activities. Pottery and weaving differ in the two observed domains. On the one hand, pottery shows more technical diver- sity than weaving: two different manufacturing techniques, with variants, were identied in pottery. Weaving with the backstrap loom ( telar de cintura ) is the only manufacturing tech- nique of probable precolonial origin in the area, and demonstrates remarkable uniformity in Southern Cajamarca, considering the toolkit and the basic sequence of ‘plain’ weaving. -

The Attributive Suffix in Pastaza Kichwa
Brigham Young University BYU ScholarsArchive Theses and Dissertations 2020-06-08 The attributive suffix in Pastaza Kichwa Barrett Wilson Hamp Brigham Young University Follow this and additional works at: https://scholarsarchive.byu.edu/etd Part of the Arts and Humanities Commons BYU ScholarsArchive Citation Hamp, Barrett Wilson, "The attributive suffix in Pastaza Kichwa" (2020). Theses and Dissertations. 8443. https://scholarsarchive.byu.edu/etd/8443 This Thesis is brought to you for free and open access by BYU ScholarsArchive. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of BYU ScholarsArchive. For more information, please contact [email protected], [email protected]. The Attributive Suffix in Pastaza Kichwa Barrett Wilson Hamp A thesis submitted to the faculty of Brigham Young University in partial fulfillment of the requirements for the degree of Master of Arts Janis Nuckolls, Chair Chris Rogers Jeff Parker Department of Linguistics Brigham Young University Copyright © 2020 Barrett Wilson Hamp All Rights Reserved ABSTRACT The Attributive Suffix in Pastaza Kichwa Barrett Wilson Hamp Department of Linguistics, BYU Master of Arts This thesis is a corpus-based description of the attributive suffix -k in Pastaza Kichwa, a Quechuan language spoken in lowland Amazonian Ecuador. The goal of this work is, first, to describe the behaviors, characteristics, and functions of the suffix using data from the Corpus of Pastaza Kichwa (Rice 2018a), and second, to offer a typological analysis of these behaviors in order to identify the most appropriate classification for the suffix. The suffix has previously been described as a nominalizer (Nuckolls & Swanson, forthcoming), and the equivalent suffix in other Quechuan varieties has been described as an agentive nominal relativizer (Weber 1983; Weber 1989; Cole 1985; Lefebvre & Muysken 1988) or a participle (Markham 1864; Weber 1989; Guardia Mayorga 1973; Catta Quelen 1985; Debenbach-Salazar Saenz 1993, Muysken 1994). -

And Topic Markers Indicate Gender and Number by Means of the Pronominal Article They Follow (Ho-Kwe M.TOP, Ko-Kwe F.TOP and Mo-Kwe PL-TOP)
The elusive topic: Towards a typology of topic markers (with special reference to cumulation with number in Bolinao and gender in Nalca) Bernhard Wälchli (Stockholm University) [email protected] Helsinki; January 22, 2020 1 The elusive topic: Towards a typology of topic markers (with special reference to cumulation with number in Bolinao and gender in Nalca) Bernhard Wälchli (Stockholm University) Abstract At least since the 1970s, topic has been widely recognized to reflect an important category in most different approaches to linguistics. However, researchers have never agreed about what exactly a topic is (researchers disagree, for instance, about whether topics express backgrounding or foregrounding) and to what extent topics are elements of syntax or discourse or both. Topics are notoriously difficult to distinguish from a range of related phenomena. Some definitions of topic are suspiciously similar to definitions of definiteness, subject, noun and contrast, so the question arises as to what extent topic is a phenomenon of its own. However, topics are also internally diverse. There is disagreement, for instance, as to whether contrastive and non-contrastive topics should be subsumed under the same notion. This talk tries to approach the category type topic bottom-up by considering cross-linguistic functional diversity in marked topics, semasiologically defined as instances of topics with explicit segmental topic markers. The first part of the talk considers the question as to whether topic markers can be defined as a gram type with one or several prototypical functions that can be studied on the basis of material from parallel texts and from descriptive sources. -

The Binding Properties of Quechua Suffixes
Work Papers of the Summer Institute of Linguistics, University of North Dakota Session Volume 37 Article 6 1993 The binding properties of Quechua suffixes David J. Weber SIL-UND Follow this and additional works at: https://commons.und.edu/sil-work-papers Part of the Linguistics Commons Recommended Citation Weber, David J. (1993) "The binding properties of Quechua suffixes," Work Papers of the Summer Institute of Linguistics, University of North Dakota Session: Vol. 37 , Article 6. DOI: 10.31356/silwp.vol37.06 Available at: https://commons.und.edu/sil-work-papers/vol37/iss1/6 This Article is brought to you for free and open access by UND Scholarly Commons. It has been accepted for inclusion in Work Papers of the Summer Institute of Linguistics, University of North Dakota Session by an authorized editor of UND Scholarly Commons. For more information, please contact [email protected]. THE BINDING PROPERTIES OF QUECHUA SUFFIXES* David Weber Summer Institute of Linguistics, Peru University of North Dakota Contents 1 Introduction 79 2 Categories and phrase structure rules · 81 2.1 Morphological categories . .- 81 2.2 Structure ........... 82 2.3 Selection and subcategorization 84 2.4 Case assignment . 86 2.5 9-roles ............. 87 2.6 The relation of morphology and syntax 89 3 Verbal inflection 90 3.1 The subject marking anomaly 94 3.2 Reflexives and reciprocals .. 97 3.3 Concluding remarks on inflection 97 4 The structure of complement clauses 98 4.1 The COMP found: case markers . 98 4.2 Object complements . 101 5 Possessives 103 5.1 The person of possessed noun phrases . -

Finding Case Through Personal Names in Parallel Texts
Finding case through personal names in parallel texts Gustav Finnveden Institutionen för lingvistik/Department of linguistics Examensarbete 15 hp /Degree 15 HE credits Lingvistik/Linguistics Kurs- eller utbildningsprogram (15 hp) /Programme (15 credits) Vårterminen/Spring term 2019 Handledare/Supervisor: Robert Östling och Bernhard Wälchli Finding case through personal name variation in parallel text Abstract The aim of this study is to evaluate whether the ‘richness’ of the marking on personal names is an adequate indirect measure of a language’s case usage. The method uses parallel texts to identify, and group by lemma, names in over a thousand languages. These groupings are compared with data for case usage from a typological database for those languages for which it is available. This material is then used to test a method for assessing whether a language uses case or not. Results indicate that the maximum number of word types a proprial lemma is attested with in a text is a useful tool for inferring case usage. However, it only yielded clear results for a subset of the languages tested. It was not particularly useful for inferring the absence of case usage. Estimation of number of case categories was also performed. An entropy measure based on word types that a personal name lemma is attested with and the occurrences of these word types was used. It was found to be a fair indicator of number of case categories for languages, if somewhat inaccurate. Markings on languages which had no case were investigated. They were found to be of several types: pragmatic markers, non-case grammatical markers and case-like markers. -

The Binding Properties of Quechua Suffixes. PUB DATE 93 NOTE 75P.; In: Work Papers of the Summer Institute of Linguistics, 1993
DOCUMENT RESUME ED 365 103 FL 021 598 AUTHOR Weber, David TITLE The Binding Properties of Quechua Suffixes. PUB DATE 93 NOTE 75p.; In: Work Papers of the Summer Institute of Linguistics, 1993. University of North Dakota Session, Volume 37; see FL 021 593. Paper originally presented at the Workshop on Language, Language Policy, and Education in the Andes (Newark, DE, November 1991). PUB TYPE Reports Research/Technical (143) (.3peeches/Conference Papers (150) EDRS PRICE MF01/PC03 Plus Postage. DESCRIPTORS *Case (Grammar); *Grammar; *Linguistic Theory; Morphology (Languages); *Quechua; Structural Analysis (Linguistics); *Suffixes; Uncommonly Taught Languages; Verbs IDENTIFIERS *Anaphora ABSTRACT This paper sketches an explicitly non-lexicalist application of grammatical theory to Huallaga (Huanuco) Quechua (HgQ). The advantages of applying binding theory to many suffixes that have previously been treated only as objects of the morphology are demonstrated. After an introduction, section 2 outlines basic assumptions 2"lut the nature of HgQ categories and structures, and section 3 discusses inflection, proposing an analysis of SUBJECT MARKING ANOMALY phenomena. Section 4 argues that HgQ's complementizers are really its case-marking suffixes. Section 5 deals with the possessive suffixes, showing that in Agr-P they are mildly anaphoric. Section 6 focuses on switch reference, deriving a wide range of facts from some structural assumptions and then claiming that "-r" 'advss' is anaphoric and the possessive suffixes in Agr-S are pronominal. Section 7 discusses "infinitives," claiming that "-y" is anaphoric. Section 8 discusses uses of "-q," claiming that it is anaphoric. Section 9 sketches one verb incorporation phenomenon and shows how this fits in with other claims made here. -

Alain Fabre 2005- Diccionario Etnolingüístico Y Guía Bibliográfica De Los Pueblos Indígenas Sudamericanos
Alain Fabre 2005- Diccionario etnolingüístico y guía bibliográfica de los pueblos indígenas sudamericanos. 1 QUECHUA [Última modificación: 19/06/16] QUECHUA Se considera que, hacia mediados de la década del 80, algunas 12.500.000 personas en total manejaban una variedad del quechua como lengua principal: (1) Perú [4.402.023 hablantes, el 24.09% de la población total del país], (2) Ecuador [2.233.000 hablantes. Sin embargo, para dicho país, Knapp (1987) avanza una cifra de 836.000 hablantes como mínimo y 1.360.107 como máximo], (3) Bolivia [1.594.000 hablantes. Según Albó (1995), serían sin embargo 2.500.000 hablantes, el 37.1% de la población total del país], (4) Argentina [120.000 hablantes. En la literatura, se cita también un estimado de 850.000 hablantes para este país], (5) Colombia [4.402 hablantes. Otras fuentes dan 16.000 hablantes], (6) Chile [número desconocido, pero probablemente muy bajo, de hablantes nativos, y un número más elevado, aunque igualmente desconocido, de trabajadores migrantes], (7) Brasil [700-800 hablantes] (cifras basadas principalmente en Cerrón-Palomino 1987). Según Torero (1984), una primera separación entre el quechua I y el quechua II habría ocurrido a principios de nuestra era. Para dicha época, el proto-quechua estuvo centrado en la sierra y costa central del Perú, zona que corresponde al territorio de los hablantes actuales de las variedades del quechua I, más la zona costeña aledaña. Durante una segunda expansión, el ancestro de las variedades del quechua II empezó a propagarse hacial el norte y hacia el sur. En la zona meridional, fue desplazando a los hablantes del proto jaqi (aru), algunos de éstos volviéndose quechuahablantes. -

Bayesian Models for Multilingual Word Alignment
Bayesian Models for Multilingual Word Alignment Robert Östling Academic dissertation for the Degree of Doctor of Philosophy in Linguistics at Stockholm University to be publicly defended on Friday 22 May 2015 at 13.00 in hörsal 5, hus B, Universitetsvägen 10 B. Abstract In this thesis I explore Bayesian models for word alignment, how they can be improved through joint annotation transfer, and how they can be extended to parallel texts in more than two languages. In addition to these general methodological developments, I apply the algorithms to problems from sign language research and linguistic typology. In the first part of the thesis, I show how Bayesian alignment models estimated with Gibbs sampling are more accurate than previous methods for a range of different languages, particularly for languages with few digital resources available —which is unfortunately the state of the vast majority of languages today. Furthermore, I explore how different variations to the models and learning algorithms affect alignment accuracy. Then, I show how part-of-speech annotation transfer can be performed jointly with word alignment to improve word alignment accuracy. I apply these models to help annotate the Swedish Sign Language Corpus (SSLC) with part-of-speech tags, and to investigate patterns of polysemy across the languages of the world. Finally, I present a model for multilingual word alignment which learns an intermediate representation of the text. This model is then used with a massively parallel corpus containing translations of the New Testament, to explore word order features in 1001 languages. Keywords: word alignment, parallel text, Bayesian models, MCMC, linguistic typology, sign language, annotation transfer, transfer learning. -

Code Alpha-3 Pour Un Traitement Exhaustif Des Langues
PROJET DE NORME INTERNATIONALE ISO/DIS 639-3 ISO/TC 37/SC 2 Secrétariat: SCC Début de vote: Vote clos le: 2005-02-04 2005-07-04 INTERNATIONAL ORGANIZATION FOR STANDARDIZATION • МЕЖДУНАРОДНАЯ ОРГАНИЗАЦИЯ ПО СТАНДАРТИЗАЦИИ • ORGANISATION INTERNATIONALE DE NORMALISATION Codes pour la représentation des noms de langues — Partie 3: Code alpha-3 pour un traitement exhaustif des langues Codes for the representation of names of languages — Part 3: Alpha-3 code for comprehensive coverage of languages ICS 01.140.20 Pour accélérer la distribution, le présent document est distribué tel qu'il est parvenu du secrétariat du comité. Le travail de rédaction et de composition de texte sera effectué au Secrétariat central de l'ISO au stade de publication. To expedite distribution, this document is circulated as received from the committee secretariat. ISO Central Secretariat work of editing and text composition will be undertaken at publication stage. CE DOCUMENT EST UN PROJET DIFFUSÉ POUR OBSERVATIONS ET APPROBATION. IL EST DONC SUSCEPTIBLE DE MODIFICATION ET NE PEUT ÊTRE CITÉ COMME NORME INTERNATIONALE AVANT SA PUBLICATION EN TANT QUE TELLE. OUTRE LE FAIT D'ÊTRE EXAMINÉS POUR ÉTABLIR S'ILS SONT ACCEPTABLES À DES FINS INDUSTRIELLES, TECHNOLOGIQUES ET COMMERCIALES, AINSI QUE DU POINT DE VUE DES UTILISATEURS, LES PROJETS DE NORMES INTERNATIONALES DOIVENT PARFOIS ÊTRE CONSIDÉRÉS DU POINT DE VUE DE LEUR POSSIBILITÉ DE DEVENIR DES NORMES POUVANT SERVIR DE RÉFÉRENCE DANS LA RÉGLEMENTATION NATIONALE. © Organisation internationale de normalisation, 2005 ISO/DIS 639-3 PDF — Exonération de responsabilité Le présent fichier PDF peut contenir des polices de caractères intégrées. Conformément aux conditions de licence d'Adobe, ce fichier peut être imprimé ou visualisé, mais ne doit pas être modifié à moins que l'ordinateur employé à cet effet ne bénéficie d'une licence autorisant l'utilisation de ces polices et que celles-ci y soient installées. -

Diccionario Etnolingüístico Y Guía Bibliográfica De Los Pueblos Indígenas Sudamericanos
Alain Fabre 2005- Diccionario etnolingüístico y guía bibliográfica de los pueblos indígenas sudamericanos. 1 QUECHUA [Última modificación: 10/10/20] QUECHUA Se considera que, hacia mediados de la década del 80, algunas 12.500.000 personas en total manejaban una variedad del quechua como lengua principal: (1) Perú [4.402.023 hablantes, el 24.09% de la población total del país], (2) Ecuador [2.233.000 hablantes. Sin embargo, para dicho país, Knapp (1987) avanza una cifra de 836.000 hablantes como mínimo y 1.360.107 como máximo], (3) Bolivia [1.594.000 hablantes. Según Albó (1995), serían sin embargo 2.500.000 hablantes, el 37.1% de la población total del país], (4) Argentina [120.000 hablantes. En la literatura, se cita también un estimado de 850.000 hablantes para este país], (5) Colombia [4.402 hablantes. Otras fuentes dan 16.000 hablantes], (6) Chile [número desconocido, pero probablemente muy bajo, de hablantes nativos, y un número más elevado, aunque igualmente desconocido, de trabajadores migrantes], (7) Brasil [700-800 hablantes] (cifras basadas principalmente en Cerrón-Palomino 1987). Según Torero (1984), una primera separación entre el quechua I y el quechua II habría ocurrido a principios de nuestra era. Para dicha época, el proto-quechua estuvo centrado en la sierra y costa central del Perú, zona que corresponde al territorio de los hablantes actuales de las variedades del quechua I, más la zona costeña aledaña. Durante una segunda expansión, el ancestro de las variedades del quechua II empezó a propagarse hacial el norte y hacia el sur. En la zona meridional, fue desplazando a los hablantes del proto jaqi (aru), algunos de éstos volviéndose quechuahablantes. -

Crossing Aspectual Frontiers Emergence, Evolution, and Interwoven Semantic Domains in South Conchucos Quechua Discourse
Crossing Aspectual Frontiers Emergence, Evolution, and Interwoven Semantic Domains in South Conchucos Quechua Discourse Crossing Aspectual Frontiers Emergence, Evolution, and Interwoven Semantic Domains in South Conchucos Quechua Discourse Daniel J. Hintz University of California Press Berkeley • Los Angeles • London UNIVERSITY OF CALIFORNIA PUBLICATIONS IN LINGUISTICS Editorial Board: Judith Aissen, Andrew Garrett, Larry M. Hyman, Marianne Mithun, Pamela Munro, Maria Polinsky Volume 146 University of California Press, one of the most distinguished university presses in the United States, enriches lives around the world by advancing scholarship in the humani- ties, social sciences, and natural sciences. Its activities are supported by the UC Press Foundation and philanthropic contributions from individuals and institutions. For more information, visit www.ucpress.edu University of California Press Berkeley and Los Angeles, California University of California Press, Ltd. London, England © 2011 by The Regents of the University of California Library of Congress Control Number: 2011929998 ISBN 978-0-520-09885-5 (pbk. : alk. paper) Manufactured in the United States of America 10 9 8 7 6 5 4 3 2 1 The paper used in this publication meets the minimum requirements of ANSI/NISO Z39.48-1992 (R 1997) (Permanence of Paper). To the memory of Mavis sister, encourager, friend Cay pachacta ñócanchic runa caccóna cauçanganchícpac, tianganchícpac, rurapuárcanchic. ‘He made this world so that we human beings could live and dwell with him.’ —Domingo de Santo -
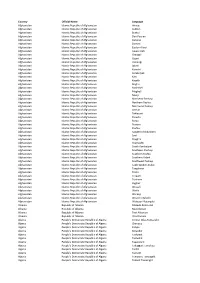
Missing Languages
Country Official Name Language Afghanistan Islamic Republic of Afghanistan Aimaq Afghanistan Islamic Republic of Afghanistan Ashkun Afghanistan Islamic Republic of Afghanistan Brahui Afghanistan Islamic Republic of Afghanistan Dari Persian Afghanistan Islamic Republic of Afghanistan Darwazi Afghanistan Islamic Republic of Afghanistan Domari Afghanistan Islamic Republic of Afghanistan Eastern Farsi Afghanistan Islamic Republic of Afghanistan Gawar-Bati Afghanistan Islamic Republic of Afghanistan Grangali Afghanistan Islamic Republic of Afghanistan Gujari Afghanistan Islamic Republic of Afghanistan Hazaragi Afghanistan Islamic Republic of Afghanistan Jakati Afghanistan Islamic Republic of Afghanistan Kamviri Afghanistan Islamic Republic of Afghanistan Karakalpak Afghanistan Islamic Republic of Afghanistan Kati Afghanistan Islamic Republic of Afghanistan Kazakh Afghanistan Islamic Republic of Afghanistan Kirghiz Afghanistan Islamic Republic of Afghanistan Malakhel Afghanistan Islamic Republic of Afghanistan Mogholi Afghanistan Islamic Republic of Afghanistan Munji Afghanistan Islamic Republic of Afghanistan Northeast Pashayi Afghanistan Islamic Republic of Afghanistan Northern Pashto Afghanistan Islamic Republic of Afghanistan Northwest Pashayi Afghanistan Islamic Republic of Afghanistan Ormuri Afghanistan Islamic Republic of Afghanistan Pahlavani Afghanistan Islamic Republic of Afghanistan Parachi Afghanistan Islamic Republic of Afghanistan Parya Afghanistan Islamic Republic of Afghanistan Prasuni Afghanistan Islamic Republic of Afghanistan