Confidentiality of XML Documents by Pool Encryption
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2004/WD-xml-media-types-20041102 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP (formerly of Oracle) Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list and in the section C Change Log [p.11] . A diff-marked version against the previous version of this document is available. -
XML Specifications Growth of the Web
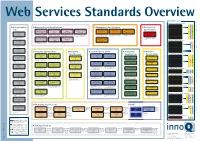
Web Services Standards Overview Dependencies Messaging Specifications SOAP 1.1 SOAP 1.2 Interoperability Business Process Specifications Management Specifications Presentation SOAP Message Transmission Optimization Mechanism WS-Notification the trademarks of their respective owners. of their respective the trademarks Management Using Web Management Of WS-BaseNotification Issues Business Process Execution WS-Choreography Model Web Service Choreography Web Service Choreography WS-Management Specifications Services (WSDM-MUWS) Web Services (WSDM-MOWS) Language for Web Services 1.1 Overview Interface Description Language AMD, Dell, Intel, Microsoft and Sun WS-Topics (BPEL4WS) · 1.1 · BEA Systems, IBM, (WSCI) · 1.0 · W3C 1.0 1.0 1.0 · W3C (CDL4WS) · 1.0 · W3C Microsystems Microsoft, SAP, Sun Microsystems, SAP, BEA Systems WS-BrokeredNotification Working Draft Candidate Recommendation OASIS OASIS Published Specification Web Services for Remote Security Resource Basic Profile Siebel Systems · OASIS-Standard and Intalio · Note OASIS-Standard OASIS-Standard Metadata Portlets (WSRP) WS-Addressing – Core 1.1 ̆ ̆ ̆ ̆ ̆ ̆ ̆ 2.0 WS-I Business Process Execution Language for Web Services WS-Choreography Model Overview defines the format Web Service Choreography Interface (WSCI) describes Web Service Choreography Description Language Web Service Distributed Management: Management Using Web Service Distributed Management: Management Of WS-Management describes a general SOAP-based WS-Addressing – WSDL Binding 1.1(BPEL4WS) provides a language for the formal -

XML Signature/Encryption — the Basis of Web Services Security
Special Issue on Security for Network Society Falsification Prevention and Protection Technologies and Products XML Signature/Encryption — the Basis of Web Services Security By Koji MIYAUCHI* XML is spreading quickly as a format for electronic documents and messages. As a consequence, ABSTRACT greater importance is being placed on the XML security technology. Against this background research and development efforts into XML security are being energetically pursued. This paper discusses the W3C XML Signature and XML Encryption specifications, which represent the fundamental technology of XML security, as well as other related technologies originally developed by NEC. KEYWORDS XML security, XML signature, XML encryption, Distributed signature, Web services security 1. INTRODUCTION 2. XML SIGNATURE XML is an extendible markup language, the speci- 2.1 Overview fication of which has been established by the W3C XML Signature is an electronic signature technol- (WWW Consortium). It is spreading quickly because ogy that is optimized for XML data. The practical of its flexibility and its platform-independent technol- benefits of this technology include Partial Signature, ogy, which freely allows authors to decide on docu- which allows an electronic signature to be written on ment structures. Various XML-based standard for- specific tags contained in XML data, and Multiple mats have been developed including: ebXML and Signature, which enables multiple electronic signa- RosettaNet, which are standard specifications for e- tures to be written. The use of XML Signature can commerce transactions, TravelXML, which is an EDI solve security problems, including falsification, spoof- (Electronic Data Interchange) standard for travel ing, and repudiation. agencies, and NewsML, which is a standard specifica- tion for new distribution formats. -

What Is XML Schema?
72076_FM 3/22/02 10:39 AM Page i XML Schema Essentials R. Allen Wyke Andrew Watt Wiley Computer Publishing John Wiley & Sons, Inc. 72076_AppB 3/22/02 10:47 AM Page 378 72076_FM 3/22/02 10:39 AM Page i XML Schema Essentials R. Allen Wyke Andrew Watt Wiley Computer Publishing John Wiley & Sons, Inc. 72076_FM 3/22/02 10:39 AM Page ii Publisher: Robert Ipsen Editor: Cary Sullivan Developmental Editor: Scott Amerman Associate Managing Editor: Penny Linskey Associate New Media Editor: Brian Snapp Text Design & Composition: D&G Limited, LLC Designations used by companies to distinguish their products are often claimed as trademarks. In all instances where John Wiley & Sons, Inc., is aware of a claim, the product names appear in initial capital or ALL CAPITAL LETTERS. Readers, however, should contact the appropriate companies for more complete information regarding trademarks and registration. This book is printed on acid-free paper. Copyright © 2002 by R. Allen Wyke and Andrew Watt. All rights reserved. Published by John Wiley & Sons, Inc. Published simultaneously in Canada. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copy- right Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 750-4744. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 605 Third Avenue, New York, NY 10158-0012, (212) 850-6011, fax (212) 850- 6008, E-Mail: PERMREQ @ WILEY.COM. -

Command Injection in XML Signatures and Encryption Bradley W
Command Injection in XML Signatures and Encryption Bradley W. Hill Information Security Partners, July 12, 2007 [email protected] Abstract. The XML Digital Signature1 (XMLDSIG) and XML Encryption2 (XMLENC) standards are complex protocols for securing XML and other content. Among its complexities, the XMLDSIG standard specifies various “Transform” algorithms to identify, manipulate and canonicalize signed content and key material. Unfortunately, the defined transforms have not been rigorously constrained to prevent their use as attack vectors, and denial of service or even arbitrary code execution are probable in implementations that have not specifically guarded against such risks. Attacks against the processing application can be embedded in the KeyInfo portion of a signature, making them inherently unauthenticated, or in the SignedInfo block. Although tampering with the SignedInfo should be detectable, a defective implied order of operations in the specification may still allow unauthenticated attacks here. The ability to execute arbitrary code and perform file system operations with a malicious, invalid signature has been confirmed by the researcher in at least two independent XMLDSIG implementations, and other implementations may be similarly vulnerable. This paper describes the vulnerabilities in detail and offers advice for remediation. The most damaging attack is also likely to apply in other contexts where XSLT is accepted as input, and should be considered by all implementers of complex XML processing systems. Categories and Subject Descriptors Primary Classification: K.6.5 Security and Protection Subject: Invasive software Unauthorized access Authentication Additional Classification: D.2.3 Coding Tools and Techniques (REVISED) Subject: Standards D.2.1 Requirements/Specifications (D.3.1) Subject: Languages Tools General Terms: Security, Reliability, Verification, and Design. -

Describing Media Content of Binary Data in XML W3C Working Group Note 4 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 4 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050504 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list. There is no technical difference between this document and the 2 May 2005 version; the acknowledgement section has been updated to thank external contributors. -

XML Information Set
XML Information Set XML Information Set W3C Recommendation 24 October 2001 This version: http://www.w3.org/TR/2001/REC-xml-infoset-20011024 Latest version: http://www.w3.org/TR/xml-infoset Previous version: http://www.w3.org/TR/2001/PR-xml-infoset-20010810 Editors: John Cowan, [email protected] Richard Tobin, [email protected] Copyright ©1999, 2000, 2001 W3C® (MIT, INRIA, Keio), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply. Abstract This specification provides a set of definitions for use in other specifications that need to refer to the information in an XML document. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. The latest status of this document series is maintained at the W3C. This is the W3C Recommendation of the XML Information Set. This document has been reviewed by W3C Members and other interested parties and has been endorsed by the Director as a W3C Recommendation. It is a stable document and may be used as reference material or cited as a normative reference from another document. W3C's role in making the Recommendation is to draw attention to the specification and to promote its widespread deployment. This enhances the functionality and interoperability of the file:///C|/Documents%20and%20Settings/immdca01/Desktop/xml-infoset.html (1 of 16) [8/12/2002 10:38:58 AM] XML Information Set Web. This document has been produced by the W3C XML Core Working Group as part of the XML Activity in the W3C Architecture Domain. -

XML for Java Developers G22.3033-002 Course Roadmap
XML for Java Developers G22.3033-002 Session 1 - Main Theme Markup Language Technologies (Part I) Dr. Jean-Claude Franchitti New York University Computer Science Department Courant Institute of Mathematical Sciences 1 Course Roadmap Consider the Spectrum of Applications Architectures Distributed vs. Decentralized Apps + Thick vs. Thin Clients J2EE for eCommerce vs. J2EE/Web Services, JXTA, etc. Learn Specific XML/Java “Patterns” Used for Data/Content Presentation, Data Exchange, and Application Configuration Cover XML/Java Technologies According to their Use in the Various Phases of the Application Development Lifecycle (i.e., Discovery, Design, Development, Deployment, Administration) e.g., Modeling, Configuration Management, Processing, Rendering, Querying, Secure Messaging, etc. Develop XML Applications as Assemblies of Reusable XML- Based Services (Applications of XML + Java Applications) 2 1 Agenda XML Generics Course Logistics, Structure and Objectives History of Meta-Markup Languages XML Applications: Markup Languages XML Information Modeling Applications XML-Based Architectures XML and Java XML Development Tools Summary Class Project Readings Assignment #1a 3 Part I Introduction 4 2 XML Generics XML means eXtensible Markup Language XML expresses the structure of information (i.e., document content) separately from its presentation XSL style sheets are used to convert documents to a presentation format that can be processed by a target presentation device (e.g., HTML in the case of legacy browsers) Need a -

Introduction to XML
Introduction to XML CS 317/387 Agenda – Introduction to XML 1. What is it? 2. What’s it good for? 3. How does it work? 4. The infrastructure of XML 5. Using XML on the Web 6. Implementation issues & costs 2 1. What is it? Discussion points: First principles: OHCO Example: A simple XML fragment Compare/contrast: SGML, HTML, XHTML A different XML for every community Terminology 3 1 Ordered hierarchies of content objects Premise: A text is the sum of its component parts A <Book> could be defined as containing: <FrontMatter>, <Chapter>s, <BackMatter> <FrontMatter> could contain: <BookTitle> <Author>s <PubInfo> A <Chapter> could contain: <ChapterTitle> <Paragraph>s A <Paragraph> could contain: <Sentence>s or <Table>s or <Figure>s … Components chosen should reflect anticipated use 4 Ordered hierarchies of content objects OHCO is a useful, albeit imperfect, model Exposes an object’s intellectual structure Supports reuse & abstraction of components Better than a bit-mapped page image Better than a model of text as a stream of characters plus formatting instructions Data management system for document-like objects Does not allow overlapping content objects Incomplete; requires infrastructure 5 Content objects in a book Book FrontMatter BookTitle Author(s) PubInfo Chapter(s) ChapterTitle Paragraph(s) BackMatter References Index 6 2 Content objects in a catalog card Card CallNumber MainEntry TitleStatement TitleProper StatementOfResponsibility Imprint SummaryNote AddedEntrySubject(s) Added EntryPersonalName(s) 7 Semistructured Data Another data model, based on trees. Motivation: flexible representation of data. Often, data comes from multiple sources with differences in notation, meaning, etc. Motivation: sharing of documents among systems and databases. -
5241 Index 0939-0964.Qxd 29/08/02 5.30 Pm Page 941
5241_index_0939-0964.qxd 29/08/02 5.30 pm Page 941 INDEX 941 5241_index_0939-0964.qxd 29/08/02 5.30 pm Page 942 Index 942 Regular A Alternatives, 362 Analysis Patterns: Reusable Expression ABSENT value, 67 Object Models, 521 Symbols abstract attribute, 62, 64–66 ancestor (XPath axis), 54 of complexType element, ancestor-or-self (XPath axis), . escape character, 368, 369 247–248, 512, 719 54 . metacharacter, 361 of element element, 148–149 Annotation, 82 ? metacharacter, 361, 375 mapping to object-oriented defined, 390 ( metacharacter, 361 language, 513–514 mapping to object-oriented ) metacharacter, 361 Abstract language, 521 { metacharacter, 361 attribute type, 934 Microsoft use of term, } metacharacter, 361 defined, 58 821–822 + metacharacter, 361, 375 element type, 16, 17, 18, 934 properties of, 411 * metacharacter, 361, 375 object, corresponding to docu- annotation content option ^ metacharacter, 379 ment, 14 for schema element, 115 \ metacharacter, 361 uses of term, 238, 931–932 annotation element, 82, 83, | metacharacter, 361 Abstract character, 67 254, 260, 722, 859 \. escape character, 366 Abstract document attributes of, 118 \? escape character, 366 document information item content options for, 118–119 \( escape character, 367 view of, 62 example of use of, 117 \) escape character, 367 infoset view of, 62 function of, 116, 124, 128 \{ escape character, 367 makeup of, 59 nested, 83–84 \} escape character, 367 properties of, 66 Anonymous component, 82 \+ escape character, 367 Abstract element, 14–15 any element, 859 \- escape character, -

Web API Protocol and Security Analysis Web
EXAMENSARBETE INOM DATATEKNIK, GRUNDNIVÅ, 15 HP STOCKHOLM, SVERIGE 2017 Web API protocol and security analysis Web API protokoll- och säkerhetsanalys CRISTIAN ARAYA MANJINDER SINGH KTH SKOLAN FÖR TEKNIK OCH HÄLSA Web API protocol and security analysis Web API protokoll- och säkerhetsanalys Cristian Araya and Manjinder Singh Degree project in Computer science First level, 15hp Supervisor from KTH: Reine Bergström Examiner: Ibrahim Orhan TRITA-STH 2017:34 KTH The School of Technology and Health 141 52 Flemingsberg, Sweden Abstract There is problem that every company has its own customer portal. This problem can be solved by creating a platform that gathers all customers’ portals in one place. For such platform, it is required a web API protocol that is fast, secure and has capacity for many users. Consequently, a survey of various web API protocols has been made by testing their performance and security. The task was to find out which web API protocol offered high security as well as high performance in terms of response time both at low and high load. This included an investigation of previous work to find out if certain protocols could be ruled out. During the work, the platform’s backend was also developed, which needed to implement chosen web API protocols that would later be tested. The performed tests measured the APIs’ connection time and their response time with and without load. The results were analyzed and showed that the protocols had both pros and cons. Finally, a protocol was chosen that was suitable for the platform because it offered high security and fast connection. -

TU07 XML at The
ApacheCon 2004 November 2004 XML at the ASF Ted Leung [email protected] Copyright © Sauria Associates, LLC 2004 1 ApacheCon 2004 November 2004 Overview xml.apache.org ws.apache.org Xerces XML-RPC Xalan Axis FOP WSIF Batik JaxMe Xindice cocoon.apache.org Forrest XML-Security Cocoon XML-Commons Lenya XMLBeans Copyright © Sauria Associates, LLC ApacheCon 2004 2 There are three major XML focused projects at the ASF. Originally there was one project, xml.apache.org. Earlier this year, the Cocoon and web services projects were formed. Xml.apache.org contains a number of projects that are general purpose XML tools. Most of these tools are based on specifications from the World Wide Web Consortium. This includes XML itself, XSLT, XSL Formatting object, Scalable Vector Graphics, and XML Signature and XML Encryption The web services project, ws.apache.org contains projects that cluster around standards for dealing with Web Services, including SOAP and XML-RPC The Cocoon project is oriented around the Cocoon Web publishing framework which is basd on XML, XSLT, and a number of other XML related technologies. I’m not going to be able to give you any deep technical details regarding all of these projects. Instead, I’m going to try to describe what these projects are, what standards they implement, and talk about situations where you might use them. Unless I say otherwise, I’m going to be covering the Java projects. There are a few projects which have C/C++ versions and I’ll mention that where applicable. Copyright © Sauria Associates,