Dbpedia Abstracts: a Large-Scale, Open, Multilingual NLP Training Corpus
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Survey of Orthographic Information in Machine Translation 3
Machine Translation Journal manuscript No. (will be inserted by the editor) A Survey of Orthographic Information in Machine Translation Bharathi Raja Chakravarthi1 ⋅ Priya Rani 1 ⋅ Mihael Arcan2 ⋅ John P. McCrae 1 the date of receipt and acceptance should be inserted later Abstract Machine translation is one of the applications of natural language process- ing which has been explored in different languages. Recently researchers started pay- ing attention towards machine translation for resource-poor languages and closely related languages. A widespread and underlying problem for these machine transla- tion systems is the variation in orthographic conventions which causes many issues to traditional approaches. Two languages written in two different orthographies are not easily comparable, but orthographic information can also be used to improve the machine translation system. This article offers a survey of research regarding orthog- raphy’s influence on machine translation of under-resourced languages. It introduces under-resourced languages in terms of machine translation and how orthographic in- formation can be utilised to improve machine translation. We describe previous work in this area, discussing what underlying assumptions were made, and showing how orthographic knowledge improves the performance of machine translation of under- resourced languages. We discuss different types of machine translation and demon- strate a recent trend that seeks to link orthographic information with well-established machine translation methods. Considerable attention is given to current efforts of cog- nates information at different levels of machine translation and the lessons that can Bharathi Raja Chakravarthi [email protected] Priya Rani [email protected] Mihael Arcan [email protected] John P. -

Position Description Addenda
POSITION DESCRIPTION January 2014 Wikimedia Foundation Executive Director - Addenda The Wikimedia Foundation is a radically transparent organization, and much information can be found at www.wikimediafoundation.org . That said, certain information might be particularly useful to nominators and prospective candidates, including: Announcements pertaining to the Wikimedia Foundation Executive Director Search Kicking off the search for our next Executive Director by Former Wikimedia Foundation Board Chair Kat Walsh An announcement from Wikimedia Foundation ED Sue Gardner by Wikimedia Executive Director Sue Gardner Video Interviews on the Wikimedia Community and Foundation and Its History Some of the values and experiences of the Wikimedia Community are best described directly by those who have been intimately involved in the organization’s dramatic expansion. The following interviews are available for viewing though mOppenheim.TV . • 2013 Interview with Former Wikimedia Board Chair Kat Walsh • 2013 Interview with Wikimedia Executive Director Sue Gardner • 2009 Interview with Wikimedia Executive Director Sue Gardner Guiding Principles of the Wikimedia Foundation and the Wikimedia Community The following article by Sue Gardner, the current Executive Director of the Wikimedia Foundation, has received broad distribution and summarizes some of the core cultural values shared by Wikimedia’s staff, board and community. Topics covered include: • Freedom and open source • Serving every human being • Transparency • Accountability • Stewardship • Shared power • Internationalism • Free speech • Independence More information can be found at: https://meta.wikimedia.org/wiki/User:Sue_Gardner/Wikimedia_Foundation_Guiding_Principles Wikimedia Policies The Wikimedia Foundation has an extensive list of policies and procedures available online at: http://wikimediafoundation.org/wiki/Policies Wikimedia Projects All major projects of the Wikimedia Foundation are collaboratively developed by users around the world using the MediaWiki software. -

Wikimedia Conferentie Nederland 2012 Conferentieboek
http://www.wikimediaconferentie.nl WCN 2012 Conferentieboek CC-BY-SA 9:30–9:40 Opening 9:45–10:30 Lydia Pintscher: Introduction to Wikidata — the next big thing for Wikipedia and the world Wikipedia in het onderwijs Technische kant van wiki’s Wiki-gemeenschappen 10:45–11:30 Jos Punie Ralf Lämmel Sarah Morassi & Ziko van Dijk Het gebruik van Wikimedia Commons en Wikibooks in Community and ontology support for the Wikimedia Nederland, wat is dat precies? interactieve onderwijsvormen voor het secundaire onderwijs 101wiki 11:45–12:30 Tim Ruijters Sandra Fauconnier Een passie voor leren, de Nederlandse wikiversiteit Projecten van Wikimedia Nederland in 2012 en verder Bliksemsessie …+discussie …+vragensessie Lunch 13:15–14:15 Jimmy Wales 14:30–14:50 Wim Muskee Amit Bronner Lotte Belice Baltussen Wikipedia in Edurep Bridging the Gap of Multilingual Diversity Open Cultuur Data: Een bottom-up initiatief vanuit de erfgoedsector 14:55–15:15 Teun Lucassen Gerard Kuys Finne Boonen Scholieren op Wikipedia Onderwerpen vinden met DBpedia Blijf je of ga je weg? 15:30–15:50 Laura van Broekhoven & Jan Auke Brink Jeroen De Dauw Jan-Bart de Vreede 15:55–16:15 Wetenschappelijke stagiairs vertalen onderzoek naar Structured Data in MediaWiki Wikiwijs in vergelijking tot Wikiversity en Wikibooks Wikipedia–lemma 16:20–17:15 Prijsuitreiking van Wiki Loves Monuments Nederland 17:20–17:30 Afsluiting 17:30–18:30 Borrel Inhoudsopgave Organisatie 2 Voorwoord 3 09:45{10:30: Lydia Pintscher 4 13:15{14:15: Jimmy Wales 4 Wikipedia in het onderwijs 5 11:00{11:45: Jos Punie -

Word Representation Or Word Embedding in Persian Texts Siamak Sarmady Erfan Rahmani
1 Word representation or word embedding in Persian texts Siamak Sarmady Erfan Rahmani (Abstract) Text processing is one of the sub-branches of natural language processing. Recently, the use of machine learning and neural networks methods has been given greater consideration. For this reason, the representation of words has become very important. This article is about word representation or converting words into vectors in Persian text. In this research GloVe, CBOW and skip-gram methods are updated to produce embedded vectors for Persian words. In order to train a neural networks, Bijankhan corpus, Hamshahri corpus and UPEC corpus have been compound and used. Finally, we have 342,362 words that obtained vectors in all three models for this words. These vectors have many usage for Persian natural language processing. and a bit set in the word index. One-hot vector method 1. INTRODUCTION misses the similarity between strings that are specified by their characters [3]. The Persian language is a Hindi-European language The second method is distributed vectors. The words where the ordering of the words in the sentence is in the same context (neighboring words) may have subject, object, verb (SOV). According to various similar meanings (For example, lift and elevator both structures in Persian language, there are challenges that seem to be accompanied by locks such as up, down, cannot be found in languages such as English [1]. buildings, floors, and stairs). This idea influences the Morphologically the Persian is one of the hardest representation of words using their context. Suppose that languages for the purposes of processing and each word is represented by a v dimensional vector. -

A Topic-Aligned Multilingual Corpus of Wikipedia Articles for Studying Information Asymmetry in Low Resource Languages
Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020), pages 2373–2380 Marseille, 11–16 May 2020 c European Language Resources Association (ELRA), licensed under CC-BY-NC A Topic-Aligned Multilingual Corpus of Wikipedia Articles for Studying Information Asymmetry in Low Resource Languages Dwaipayan Roy, Sumit Bhatia, Prateek Jain GESIS - Cologne, IBM Research - Delhi, IIIT - Delhi [email protected], [email protected], [email protected] Abstract Wikipedia is the largest web-based open encyclopedia covering more than three hundred languages. However, different language editions of Wikipedia differ significantly in terms of their information coverage. We present a systematic comparison of information coverage in English Wikipedia (most exhaustive) and Wikipedias in eight other widely spoken languages (Arabic, German, Hindi, Korean, Portuguese, Russian, Spanish and Turkish). We analyze the content present in the respective Wikipedias in terms of the coverage of topics as well as the depth of coverage of topics included in these Wikipedias. Our analysis quantifies and provides useful insights about the information gap that exists between different language editions of Wikipedia and offers a roadmap for the Information Retrieval (IR) community to bridge this gap. Keywords: Wikipedia, Knowledge base, Information gap 1. Introduction other with respect to the coverage of topics as well as Wikipedia is the largest web-based encyclopedia covering the amount of information about overlapping topics. -

Wikibase Knowledge Graphs for Data Management & Data Science
Business and Economics Research Data Center https://www.berd-bw.de Baden-Württemberg Wikibase knowledge graphs for data management & data science Dr. Renat Shigapov 23.06.2021 @shigapov @_shigapov DATA Motivation MANAGEMENT 1. people DATA SCIENCE knowledg! 2. processes information linking 3. technology data things KNOWLEDGE GRAPHS 2 DATA Flow MANAGEMENT Definitions DATA Wikidata & Tools SCIENCE Local Wikibase Wikibase Ecosystem Summary KNOWLEDGE GRAPHS 29.10.2012 2030 2021 3 DATA Example: Named Entity Linking SCIENCE https://commons.wikimedia.org/wiki/File:Entity_Linking_-_Short_Example.png Rule#$as!d problems Machine Learning De!' Learning Learn data science at https://www.kaggle.com 4 https://commons.wikimedia.org/wiki/File:Data_visualization_process_v1.png DATA Example: general MANAGEMENT research data silos data fabric data mesh data space data marketplace data lake data swamp Research data lifecycle https://www.reading.ac.uk/research-services/research-data-management/ 5 https://www.dama.org/cpages/body-of-knowledge about-research-data-management/the-research-data-lifecycle KNOWLEDGE ONTOLOG( + GRAPH = + THINGS https://www.mediawiki.org https://www.wikiba.se ✔ “Things, not strings” by Google, 2012 + ✔ A knowledge graph links things in different datasets https://mariadb.org https://blazegraph.com ✔ A knowledge graph can link people & relational database graph database processes and enhance technologies The main example: “THE KNOWLEDGE GRAPH COOKBOOK RECIPES THAT WORK” by ANDREAS BLUMAUER & HELMUT NAGY, 2020. https://www.wikidata.org -

Wiki-Reliability: a Large Scale Dataset for Content Reliability on Wikipedia
Wiki-Reliability: A Large Scale Dataset for Content Reliability on Wikipedia KayYen Wong∗ Miriam Redi Diego Saez-Trumper Outreachy Wikimedia Foundation Wikimedia Foundation Kuala Lumpur, Malaysia London, United Kingdom Barcelona, Spain [email protected] [email protected] [email protected] ABSTRACT Wikipedia is the largest online encyclopedia, used by algorithms and web users as a central hub of reliable information on the web. The quality and reliability of Wikipedia content is maintained by a community of volunteer editors. Machine learning and information retrieval algorithms could help scale up editors’ manual efforts around Wikipedia content reliability. However, there is a lack of large-scale data to support the development of such research. To fill this gap, in this paper, we propose Wiki-Reliability, the first dataset of English Wikipedia articles annotated with a wide set of content reliability issues. To build this dataset, we rely on Wikipedia “templates”. Tem- plates are tags used by expert Wikipedia editors to indicate con- Figure 1: Example of an English Wikipedia page with several tent issues, such as the presence of “non-neutral point of view” template messages describing reliability issues. or “contradictory articles”, and serve as a strong signal for detect- ing reliability issues in a revision. We select the 10 most popular 1 INTRODUCTION reliability-related templates on Wikipedia, and propose an effective method to label almost 1M samples of Wikipedia article revisions Wikipedia is one the largest and most widely used knowledge as positive or negative with respect to each template. Each posi- repositories in the world. People use Wikipedia for studying, fact tive/negative example in the dataset comes with the full article checking and a wide set of different information needs [11]. -

Omnipedia: Bridging the Wikipedia Language
Omnipedia: Bridging the Wikipedia Language Gap Patti Bao*†, Brent Hecht†, Samuel Carton†, Mahmood Quaderi†, Michael Horn†§, Darren Gergle*† *Communication Studies, †Electrical Engineering & Computer Science, §Learning Sciences Northwestern University {patti,brent,sam.carton,quaderi}@u.northwestern.edu, {michael-horn,dgergle}@northwestern.edu ABSTRACT language edition contains its own cultural viewpoints on a We present Omnipedia, a system that allows Wikipedia large number of topics [7, 14, 15, 27]. On the other hand, readers to gain insight from up to 25 language editions of the language barrier serves to silo knowledge [2, 4, 33], Wikipedia simultaneously. Omnipedia highlights the slowing the transfer of less culturally imbued information similarities and differences that exist among Wikipedia between language editions and preventing Wikipedia’s 422 language editions, and makes salient information that is million monthly visitors [12] from accessing most of the unique to each language as well as that which is shared information on the site. more widely. We detail solutions to numerous front-end and algorithmic challenges inherent to providing users with In this paper, we present Omnipedia, a system that attempts a multilingual Wikipedia experience. These include to remedy this situation at a large scale. It reduces the silo visualizing content in a language-neutral way and aligning effect by providing users with structured access in their data in the face of diverse information organization native language to over 7.5 million concepts from up to 25 strategies. We present a study of Omnipedia that language editions of Wikipedia. At the same time, it characterizes how people interact with information using a highlights similarities and differences between each of the multilingual lens. -

Towards a Korean Dbpedia and an Approach for Complementing the Korean Wikipedia Based on Dbpedia
Towards a Korean DBpedia and an Approach for Complementing the Korean Wikipedia based on DBpedia Eun-kyung Kim1, Matthias Weidl2, Key-Sun Choi1, S¨orenAuer2 1 Semantic Web Research Center, CS Department, KAIST, Korea, 305-701 2 Universit¨at Leipzig, Department of Computer Science, Johannisgasse 26, D-04103 Leipzig, Germany [email protected], [email protected] [email protected], [email protected] Abstract. In the first part of this paper we report about experiences when applying the DBpedia extraction framework to the Korean Wikipedia. We improved the extraction of non-Latin characters and extended the framework with pluggable internationalization components in order to fa- cilitate the extraction of localized information. With these improvements we almost doubled the amount of extracted triples. We also will present the results of the extraction for Korean. In the second part, we present a conceptual study aimed at understanding the impact of international resource synchronization in DBpedia. In the absence of any informa- tion synchronization, each country would construct its own datasets and manage it from its users. Moreover the cooperation across the various countries is adversely affected. Keywords: Synchronization, Wikipedia, DBpedia, Multi-lingual 1 Introduction Wikipedia is the largest encyclopedia of mankind and is written collaboratively by people all around the world. Everybody can access this knowledge as well as add and edit articles. Right now Wikipedia is available in 260 languages and the quality of the articles reached a high level [1]. However, Wikipedia only offers full-text search for this textual information. For that reason, different projects have been started to convert this information into structured knowledge, which can be used by Semantic Web technologies to ask sophisticated queries against Wikipedia. -
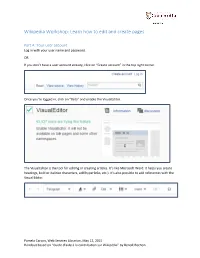
Wikipedia Workshop: Learn How to Edit and Create Pages
Wikipedia Workshop: Learn how to edit and create pages Part A: Your user account Log in with your user name and password. OR If you don’t have a user account already, click on “Create account” in the top right corner. Once you’re logged in, click on “Beta” and enable the VisualEditor. The VisualEditor is the tool for editing or creating articles. It’s like Microsoft Word: it helps you create headings, bold or italicize characters, add hyperlinks, etc.). It’s also possible to add references with the Visual Editor. Pamela Carson, Web Services Librarian, May 12, 2015 Handout based on “Guide d’aide à la contribution sur Wikipédia” by Benoît Rochon. Part B: Write a sentence or two about yourself Click on your username. This will lead you to your user page. The URL will be: https://en.wikipedia.org/wiki/User:[your user name] Exercise: Click on “Edit source” and write about yourself, then enter a description of your change in the “Edit summary” box and click “Save page”. Pamela Carson, Web Services Librarian, May 12, 2015 Handout based on “Guide d’aide à la contribution sur Wikipédia” by Benoît Rochon. Part C: Edit an existing article To edit a Wikipedia article, click on the tab “Edit” or “Edit source” (for more advanced users) available at the top of any page. These tabs are also available beside any section title within an article. Editing an entire page Editing just a section Need help? https://en.wikipedia.org/wiki/Wikipedia:Tutorial/Editing Exercise: Go to http://www.statcan.gc.ca/ and find a statistic that interests you. -

Language Resource Management System for Asian Wordnet Collaboration and Its Web Service Application
Language Resource Management System for Asian WordNet Collaboration and Its Web Service Application Virach Sornlertlamvanich1,2, Thatsanee Charoenporn1,2, Hitoshi Isahara3 1Thai Computational Linguistics Laboratory, NICT Asia Research Center, Thailand 2National Electronics and Computer Technology Center, Pathumthani, Thailand 3National Institute of Information and Communications Technology, Japan E-mail: [email protected], [email protected], [email protected] Abstract This paper presents the language resource management system for the development and dissemination of Asian WordNet (AWN) and its web service application. We develop the platform to establish a network for the cross language WordNet development. Each node of the network is designed for maintaining the WordNet for a language. Via the table that maps between each language WordNet and the Princeton WordNet (PWN), the Asian WordNet is realized to visualize the cross language WordNet between the Asian languages. We propose a language resource management system, called WordNet Management System (WNMS), as a distributed management system that allows the server to perform the cross language WordNet retrieval, including the fundamental web service applications for editing, visualizing and language processing. The WNMS is implemented on a web service protocol therefore each node can be independently maintained, and the service of each language WordNet can be called directly through the web service API. In case of cross language implementation, the synset ID (or synset offset) defined by PWN is used to determined the linkage between the languages. English PWN. Therefore, the original structural 1. Introduction information is inherited to the target WordNet through its sense translation and sense ID. The AWN finally Language resource becomes crucial in the recent needs for cross cultural information exchange. -

An Analysis of Contributions to Wikipedia from Tor
Are anonymity-seekers just like everybody else? An analysis of contributions to Wikipedia from Tor Chau Tran Kaylea Champion Andrea Forte Department of Computer Science & Engineering Department of Communication College of Computing & Informatics New York University University of Washington Drexel University New York, USA Seatle, USA Philadelphia, USA [email protected] [email protected] [email protected] Benjamin Mako Hill Rachel Greenstadt Department of Communication Department of Computer Science & Engineering University of Washington New York University Seatle, USA New York, USA [email protected] [email protected] Abstract—User-generated content sites routinely block contri- butions from users of privacy-enhancing proxies like Tor because of a perception that proxies are a source of vandalism, spam, and abuse. Although these blocks might be effective, collateral damage in the form of unrealized valuable contributions from anonymity seekers is invisible. One of the largest and most important user-generated content sites, Wikipedia, has attempted to block contributions from Tor users since as early as 2005. We demonstrate that these blocks have been imperfect and that thousands of attempts to edit on Wikipedia through Tor have been successful. We draw upon several data sources and analytical techniques to measure and describe the history of Tor editing on Wikipedia over time and to compare contributions from Tor users to those from other groups of Wikipedia users. Fig. 1. Screenshot of the page a user is shown when they attempt to edit the Our analysis suggests that although Tor users who slip through Wikipedia article on “Privacy” while using Tor. Wikipedia’s ban contribute content that is more likely to be reverted and to revert others, their contributions are otherwise similar in quality to those from other unregistered participants and to the initial contributions of registered users.