Analysis of Peer-To-Peer Protocols Performance for Establishing a Decentralized Desktop Grid Middleware
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mdns/Dns-Sd Tutorial
MDNS/DNS-SD TUTORIAL In this tutorial, we will describe how to use mDNS/DNS-SD on Raspberry Pi. mDNS/DNS-SD is a protocol for service discovery in a local area network. It is standardized under RFCs 6762 [1] and 6763[2]. The protocol is also known by the Bonjour trademark by Apple, or Zeroconf. On Linux, it is implemented in the avahi package. [1] http://tools.ietf.org/html/rfc6762 [2] http://tools.ietf.org/html/rfc6763 About mDNS/DNS-SD There are several freely available implementations of mDNS/DNS-SD: 1. avahi – Linux implementation (http://www.avahi.org/) 2. jmDNS – Java implementation (http://jmdns.sourceforge.net/) 3. Bonjour – MAC OS (installed by default) 4. Bonjour – Windows (https://support.apple.com/kb/DL999?locale=en_US) During this course, we will use only avahi. However, any of the aforementioned implementations are compatible. Avahi installation avahi is available as a package for Raspbian. Install it with: sudo apt-get install avahi-deamon avahi-utils Avahi usage avahi-daemon is the main process that takes care of proper operation of the protocol. It takes care of any configuration of the interfaces and network messaging. A user can control the deamon with command line utilities, or via D-Bus. In this document, we will describe the former option. For the latter one, please see http://www.avahi.org/wiki/Bindings. Publishing services avahi-publish-service is the command for publishing services. The syntax is: avahi-publish-service SERVICE-NAME _APPLICATION- PROTOCOL._TRANPOSRT-PROTOCOL PORT “DESCRIPTION” --sub SUBPROTOCOL For instance, the command: avahi-publish-service light _coap._udp 5683 “/mylight” --sub _floor1._sub._coap._udp will publish a service named ‘light’, which uses the CoAP protocol over UDP on port 5683. -

State of Linux Audio in 2009 Linux Plumbers Conference 2009
State of Linux Audio in 2009 Linux Plumbers Conference 2009 Lennart Poettering [email protected] September 2009 Lennart Poettering State of Linux Audio in 2009 Who Am I? Software Engineer at Red Hat, Inc. Developer of PulseAudio, Avahi and a few other Free Software projects http://0pointer.de/lennart/ [email protected] IRC: mezcalero Lennart Poettering State of Linux Audio in 2009 Perspective Lennart Poettering State of Linux Audio in 2009 So, what happened since last LPC? Lennart Poettering State of Linux Audio in 2009 RIP: EsounD is officially gone. Lennart Poettering State of Linux Audio in 2009 (at least on Fedora) RIP: OSS is officially gone. Lennart Poettering State of Linux Audio in 2009 RIP: OSS is officially gone. (at least on Fedora) Lennart Poettering State of Linux Audio in 2009 Audio API Guide http://0pointer.de/blog/projects/guide-to-sound-apis Lennart Poettering State of Linux Audio in 2009 We also make use of high-resolution timers on the desktop by default. We now use realtime scheduling on the desktop by default. Lennart Poettering State of Linux Audio in 2009 We now use realtime scheduling on the desktop by default. We also make use of high-resolution timers on the desktop by default. Lennart Poettering State of Linux Audio in 2009 2s Buffers Lennart Poettering State of Linux Audio in 2009 Mixer abstraction? Due to user-friendliness, i18n, meta data (icons, ...) We moved a couple of things into the audio server: Timer-based audio scheduling; mixing; flat volume/volume range and granularity extension; integration of volume sliders; mixer abstraction; monitoring Lennart Poettering State of Linux Audio in 2009 We moved a couple of things into the audio server: Timer-based audio scheduling; mixing; flat volume/volume range and granularity extension; integration of volume sliders; mixer abstraction; monitoring Mixer abstraction? Due to user-friendliness, i18n, meta data (icons, ...) Lennart Poettering State of Linux Audio in 2009 udev integration: meta data, by-path/by-id/.. -

VNC User Guide 7 About This Guide
VNC® User Guide Version 5.3 December 2015 Trademarks RealVNC, VNC and RFB are trademarks of RealVNC Limited and are protected by trademark registrations and/or pending trademark applications in the European Union, United States of America and other jursidictions. Other trademarks are the property of their respective owners. Protected by UK patent 2481870; US patent 8760366 Copyright Copyright © RealVNC Limited, 2002-2015. All rights reserved. No part of this documentation may be reproduced in any form or by any means or be used to make any derivative work (including translation, transformation or adaptation) without explicit written consent of RealVNC. Confidentiality All information contained in this document is provided in commercial confidence for the sole purpose of use by an authorized user in conjunction with RealVNC products. The pages of this document shall not be copied, published, or disclosed wholly or in part to any party without RealVNC’s prior permission in writing, and shall be held in safe custody. These obligations shall not apply to information which is published or becomes known legitimately from some source other than RealVNC. Contact RealVNC Limited Betjeman House 104 Hills Road Cambridge CB2 1LQ United Kingdom www.realvnc.com Contents About This Guide 7 Chapter 1: Introduction 9 Principles of VNC remote control 10 Getting two computers ready to use 11 Connectivity and feature matrix 13 What to read next 17 Chapter 2: Getting Connected 19 Step 1: Ensure VNC Server is running on the host computer 20 Step 2: Start VNC -
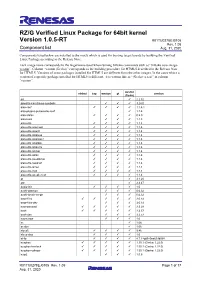
RZ/G Verified Linux Package for 64Bit Kernel Version 1.0.5-RT R01TU0278EJ0105 Rev
RZ/G Verified Linux Package for 64bit kernel Version 1.0.5-RT R01TU0278EJ0105 Rev. 1.05 Component list Aug. 31, 2020 Components listed below are installed to the rootfs which is used for booting target boards by building the Verified Linux Package according to the Release Note. Each image name corresponds to the target name used when running bitbake commands such as “bitbake core-image- weston”. Column “weston (Gecko)” corresponds to the building procedure for HTML5 described in the Release Note for HTML5. Versions of some packages installed for HTML5 are different from the other images. In the cases where a version of a specific package installed for HTML5 is different, it is written like as “(Gecko: x.x.x)” in column “version”. weston minimal bsp weston qt version (Gecko) acl ✓ 2.2.52 adwaita-icon-theme-symbolic ✓ ✓ ✓ 3.24.0 alsa-conf ✓ ✓ ✓ ✓ 1.1.4.1 alsa-plugins-pulseaudio-conf ✓ 1.1.4 alsa-states ✓ ✓ ✓ ✓ 0.2.0 alsa-tools ✓ ✓ ✓ 1.1.3 alsa-utils ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-aconnect ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-alsactl ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-alsaloop ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-alsamixer ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-alsatplg ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-alsaucm ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-amixer ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-aplay ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-aseqdump ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-aseqnet ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-iecset ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-midi ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-speakertest ✓ ✓ ✓ ✓ 1.1.4 at ✓ 3.1.20 attr ✓ 2.4.47 audio-init ✓ ✓ ✓ ✓ 1.0 avahi-daemon ✓ ✓ ✓ 0.6.32 avahi-locale-en-gb ✓ ✓ ✓ 0.6.32 base-files ✓ ✓ ✓ ✓ ✓ 3.0.14 base-files-dev ✓ ✓ ✓ 3.0.14 base-passwd ✓ ✓ ✓ ✓ ✓ 3.5.29 bash ✓ ✓ ✓ ✓ ✓ 3.2.57 bash-dev ✓ ✓ ✓ 3.2.57 bayer2raw ✓ ✓ ✓ 1.0 bc ✓ 1.06 bc-dev ✓ 1.06 bluez5 ✓ ✓ ✓ ✓ 5.46 bluez-alsa ✓ ✓ ✓ ✓ 1.0 bt-fw ✓ ✓ ✓ ✓ 8.7.1+git0+0ee619b598 busybox ✓ ✓ ✓ ✓ ✓ 1.30.1 (Gecko: 1.22.0) busybox-hwclock ✓ ✓ ✓ ✓ ✓ 1.30.1 (Gecko: 1.22.0) busybox-udhcpc ✓ ✓ ✓ ✓ ✓ 1.30.1 (Gecko: 1.22.0) bzip2 ✓ ✓ ✓ 1.0.6 R01TU0278EJ0105 Rev. -

Oracle® Linux 7 Release Notes for Oracle Linux 7
Oracle® Linux 7 Release Notes for Oracle Linux 7 E53499-20 March 2021 Oracle Legal Notices Copyright © 2011,2021 Oracle and/or its affiliates. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial computer software" or "commercial computer software documentation" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, reproduction, duplication, release, display, disclosure, modification, preparation of derivative works, and/or adaptation of i) Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs), ii) Oracle computer documentation and/or iii) other Oracle data, is subject to the rights and limitations specified in the license contained in the applicable contract. -

The Pulseaudio Sound Server Linux.Conf.Au 2007
Introduction What is PulseAudio? Usage Internals Recipes Outlook The PulseAudio Sound Server linux.conf.au 2007 Lennart Poettering [email protected] Universit¨atHamburg, Department Informatik University of Hamburg, Department of Informatics Hamburg, Germany January 17th, 2007 Lennart Poettering The PulseAudio Sound Server 2 What is PulseAudio? 3 Usage 4 Internals 5 Recipes 6 Outlook Introduction What is PulseAudio? Usage Internals Recipes Outlook Contents 1 Introduction Lennart Poettering The PulseAudio Sound Server 3 Usage 4 Internals 5 Recipes 6 Outlook Introduction What is PulseAudio? Usage Internals Recipes Outlook Contents 1 Introduction 2 What is PulseAudio? Lennart Poettering The PulseAudio Sound Server 4 Internals 5 Recipes 6 Outlook Introduction What is PulseAudio? Usage Internals Recipes Outlook Contents 1 Introduction 2 What is PulseAudio? 3 Usage Lennart Poettering The PulseAudio Sound Server 5 Recipes 6 Outlook Introduction What is PulseAudio? Usage Internals Recipes Outlook Contents 1 Introduction 2 What is PulseAudio? 3 Usage 4 Internals Lennart Poettering The PulseAudio Sound Server 6 Outlook Introduction What is PulseAudio? Usage Internals Recipes Outlook Contents 1 Introduction 2 What is PulseAudio? 3 Usage 4 Internals 5 Recipes Lennart Poettering The PulseAudio Sound Server Introduction What is PulseAudio? Usage Internals Recipes Outlook Contents 1 Introduction 2 What is PulseAudio? 3 Usage 4 Internals 5 Recipes 6 Outlook Lennart Poettering The PulseAudio Sound Server Introduction What is PulseAudio? Usage Internals Recipes Outlook Who Am I? Student (Computer Science) from Hamburg, Germany Core Developer of PulseAudio, Avahi and a few other Free Software projects http://0pointer.de/lennart/ [email protected] IRC: mezcalero Lennart Poettering The PulseAudio Sound Server Introduction What is PulseAudio? Usage Internals Recipes Outlook Introduction Lennart Poettering The PulseAudio Sound Server It’s a mess! There are just too many widely adopted but competing and incompatible sound systems. -

Open Printing Project Updates-2019
Open Printing Project Updates - 2019 Joint PWG/Open Printing Meeting - Lexington, KY Apr 16, 2019 Aveek Basu Till Kamppeter GSoC 2018 Projects ● Conversion of bannertopdf to QPDF: To make all filters in cups-filters which use Poppler only use the standard API of Poppler and no unstable, unofficial APIs. ● Enhancements for ipptool: Write additional ipptool scripts for coverage of operations and attributes that are required by IPP Everywhere, but not yet tested in IPP Everywhere Self-Certification process. ● PWG Raster "ippdoclint" program: To have a tool that can take an input PWG Raster document file and check it’s structure and report any errors / warnings / issues with the document's structure or content. ● Content-oriented printer auto-selection: Cluster arbitrary collection of printers (all available printers) into one queue with merged PPD with all options of all printers available. Depending on the document and which options the user sets the printer where the job gets printed is selected automatically. ● *Common Print Dialog Backends project: D-Bus interface to separate the print dialog GUI from the communication with the actual printing system (CUPS, Google Cloud Print, …) having each printing system being supported with a backend and these GUI-independent backends working with all print dialogs (GTK/GNOME, Qt/KDE, LibreOffice, …). (This project is partly complete) GSoC Project List for 2019 Upcoming Projects: ● Generic Framework to turn legacy drivers consisting of CUPS filters and PPDs into Printer Applications: Printer Applications are simple daemons which emulate a driverless IPP network printer on localhost, do the conversion of the print jobs into the printer's format, and send the job off to the printer. -
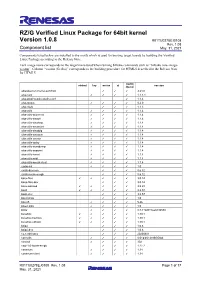
RZ/G Verified Linux Package for 64Bit Kernel Version 1.0.8 Component List
RZ/G Verified Linux Package for 64bit kernel Version 1.0.8 R01TU0278EJ0108 Rev. 1.08 Component list May. 31, 2021 Components listed below are installed to the rootfs which is used for booting target boards by building the Verified Linux Package according to the Release Note. Each image name corresponds to the target name used when running bitbake commands such as “bitbake core-image- weston”. Column “weston (Gecko)” corresponds to the building procedure for HTML5 described in the Release Note for HTML5. weston minimal bsp weston qt version (Gecko) adwaita-icon-theme-symbolic ✓ ✓ ✓ 3.24.0 alsa-conf ✓ ✓ ✓ ✓ 1.1.4.1 alsa-plugins-pulseaudio-conf ✓ 1.1.4 alsa-states ✓ ✓ ✓ ✓ 0.2.0 alsa-tools ✓ ✓ ✓ 1.1.3 alsa-utils ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-aconnect ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-alsactl ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-alsaloop ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-alsamixer ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-alsatplg ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-alsaucm ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-amixer ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-aplay ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-aseqdump ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-aseqnet ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-iecset ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-midi ✓ ✓ ✓ ✓ 1.1.4 alsa-utils-speakertest ✓ ✓ ✓ ✓ 1.1.4 audio-init ✓ ✓ ✓ ✓ 1.0 avahi-daemon ✓ ✓ ✓ 0.6.32 avahi-locale-en-gb ✓ ✓ ✓ 0.6.32 base-files ✓ ✓ ✓ ✓ ✓ 3.0.14 base-files-dev ✓ ✓ ✓ 3.0.14 base-passwd ✓ ✓ ✓ ✓ ✓ 3.5.29 bash ✓ ✓ ✓ ✓ ✓ 3.2.57 bash-dev ✓ ✓ ✓ 3.2.57 bayer2raw ✓ ✓ ✓ 1.0 bluez5 ✓ ✓ ✓ ✓ 5.46 bluez-alsa ✓ ✓ ✓ ✓ 1.0 bt-fw ✓ ✓ ✓ ✓ 8.7.1+git0+0ee619b598 busybox ✓ ✓ ✓ ✓ ✓ 1.30.1 busybox-hwclock ✓ ✓ ✓ ✓ ✓ 1.30.1 busybox-udhcpc ✓ ✓ ✓ ✓ ✓ 1.30.1 bzip2 ✓ ✓ ✓ 1.0.6 bzip2-dev ✓ ✓ ✓ 1.0.6 ca-certificates ✓ ✓ ✓ 20200601 can-utils ✓ ✓ ✓ ✓ 0.0+gitr0+4c8fb05cb4 ckermit ✓ ✓ ✓ ✓ 302 cogl-1.0-locale-en-gb ✓ ✓ ✓ 1.22.2 connman ✓ ✓ ✓ ✓ 1.34 connman-client ✓ ✓ ✓ ✓ 1.34 R01TU0278EJ0108 Rev. -
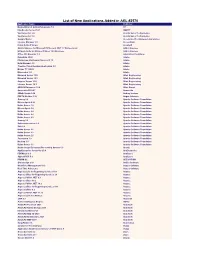
List of New Applications Added in ARL #2570
List of New Applications Added in ARL #2570 Application Name Publisher Nomad Branch Admin Extensions 7.0 1E FineReader Server 14.1 ABBYY VoxConverter 2.0 Acarda Sales Technologies VoxConverter 3.0 Acarda Sales Technologies Sample Master Accelerated Technology Laboratories License Manager 3.5 AccessData Prizm ActiveX Viewer AccuSoft Add-in Express for Microsoft Office and .NET 7.7 Professional Add-in Express Ultimate Suite for Microsoft Excel 18.5 Business Add-in Express Office 365 Reporter 3.5 AdminDroid Solutions RoboHelp 2020 Adobe Photoshop Lightroom Classic CC 10 Adobe Help Manager 4.0 Adobe Creative Cloud Desktop Application 5.3 Adobe Bridge CC (2021) Adobe Dimension 3.4 Adobe Monarch Server 15.0 Altair Engineering Monarch Server 15.3 Altair Engineering Angoss Server 10.4 Altair Engineering License Server 14.1 Altair Engineering ARGUS Enterprise 12.0 Altus Group Anaconda 2020.07 Anaconda SMath Studio 0.98 Andrey Ivashov PDFTK Builder 3.10 Angus Johnson Groovy 2.6 Apache Software Foundation Mesos Agent 0.28 Apache Software Foundation Kafka Server 1.0 Apache Software Foundation Mesos Agent 1.8 Apache Software Foundation Kafka Server 2.4 Apache Software Foundation Kafka Server 2.6 Apache Software Foundation Kafka Server 2.3 Apache Software Foundation Groovy 2.5 Apache Software Foundation Subversion server 1.9 Apache Software Foundation Solr 2.0 Apache Software Foundation Kafka Server 2.1 Apache Software Foundation Kafka Server 2.2 Apache Software Foundation Kafka Server 2.5 Apache Software Foundation Cassandra 3.9 Apache Software Foundation -

Operating System Requirements for Red Hat Enterprise Linux CONFIDENTIAL INFORMATION the Information Herein Is the Property of Ex Libris Ltd
Operating System Requirements for Red Hat Enterprise Linux CONFIDENTIAL INFORMATION The information herein is the property of Ex Libris Ltd. or its affiliates and any misuse or abuse will result in economic loss. DO NOT COPY UNLESS YOU HAVE BEEN GIVEN SPECIFIC WRITTEN AUTHORIZATION FROM EX LIBRIS LTD. This document is provided for limited and restricted purposes in accordance with a binding contract with Ex Libris Ltd. or an affiliate. The information herein includes trade secrets and is confidential. DISCLAIMER The information in this document will be subject to periodic change and updating. Please confirm that you have the most current documentation. There are no warranties of any kind, express or implied, provided in this documentation, other than those expressly agreed upon in the applicable Ex Libris contract. This information is provided AS IS. Unless otherwise agreed, Ex Libris shall not be liable for any damages for use of this document, including, without limitation, consequential, punitive, indirect or direct damages. Any references in this document to third‐party material (including third‐party Web sites) are provided for convenience only and do not in any manner serve as an endorsement of that third‐ party material or those Web sites. The third‐party materials are not part of the materials for this Ex Libris product and Ex Libris has no liability for such materials. TRADEMARKS Ex Libris, the Ex Libris logo, Alma, campusM, Esploro, Leganto, Primo, Rosetta, Summon, ALEPH 500, SFX, SFXIT, MetaLib, MetaSearch, MetaIndex and other Ex Libris products and services referenced herein are trademarks of Ex Libris, and may be registered in certain jurisdictions. -

Red Hat Enterprise Linux 7 7.9 Release Notes
Red Hat Enterprise Linux 7 7.9 Release Notes Release Notes for Red Hat Enterprise Linux 7.9 Last Updated: 2021-08-17 Red Hat Enterprise Linux 7 7.9 Release Notes Release Notes for Red Hat Enterprise Linux 7.9 Legal Notice Copyright © 2021 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. Red Hat is not formally related to or endorsed by the official Joyent Node.js open source or commercial project. -

Open Source Licenses
Threat Protection System v5.1.0 Open Source Licenses The TippingPoint Threat Protection System (TPS) devices use open source components. Many open source license agreements require user documentation to contain notification that the open source software is included in the product. For inquiries about acquiring license code, contact support. The following agreements are for software that this product includes or may include: • "BIND License Agreement" on page 9 • "boost License Agreement" on page 10 • "coreutils License Agreement regarding coreutils & libmspack" on page 11 • "corosync License Agreement" on page 20 • "cpputest License Agreement" on page 21 • "License Agreement regarding dbus; ecryptfs-utils; gdb; glibc; gptfdisk; ipset; keyutils; libcgi; libnih; libstatgrab; linux; lm-sensors; lttng; mxml; net-tools; open-vm-tools; pam-tacplus; rng-tools; RRDTool; syslog-ng; upstart & util-linux" on page 22 • "gSoap License Agreement" on page 26 • "host-sflow License Agreement" on page 33 • "ipmitool License Agreement" on page 38 • "jitterentropy-rngd License Agreement" on page 39 • "libpcap License Agreement" on page 40 • "libxml License Agreement" on page 41 • "NTP License Agreement" on page 42 • "OpenSSH License Agreement" on page 43 • "License Agreement regarding OpenSSL & openssl-fips" on page 49 • "qDecoder License Agreement" on page 52 • "shadow License Agreement" on page 53 • "tcpdump License Agreement" on page 55 TippingPoint acknowledges that the following open source components may be used in this product: • Adaptive Public License