A Qualitative Analysis of the Factors Influencing Findability of the Websites of Slovak Libraries
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

User-Generated Metadata in Social Software: an Analysis of Findability in Content Tagging and Recommender Systems
Barnes – i Presented to the Interdisciplinary Studies Program: Applied Information Management and the Graduate School of the University of Oregon in partial fulfillment of the requirement for the degree of Master of Science User-Generated Metadata in Social CAPSTONE REPORT Software: An Analysis of Findability in Content Tagging and Recommender Systems Michael Barnes Manager, User Experience Design University of Oregon VeriSign, Inc. Applied Information Management Program March, 2007 722 SW Second Avenue Suite 230 Portland, OR 97204 (800) 824-2714 Barnes ii - Barnes – iii Approved by __________________________________________ Dr. Linda F. Ettinger Academic Director, AIM Program Barnes iv - Barnes v - Abstract for User-Generated Metadata in Social Software: An Analysis of Findability in Content Tagging and Recommender Systems This study describes how user-generated metadata may be leveraged to enhance findability in web-based social software applications (Morville, 2005). Two interaction design systems, content tagging (Golder & Huberman, 2005) and recommender systems (Resnick & Varian, 1997), are examined to identify strengths and weaknesses along three findability factors: information classification, information retrieval and information discovery. Greater overall findability strength may be found in content tagging systems than in recommender systems. Barnes vi - Barnes vii - TABLE OF CONTENTS FIGURES AND TABLES........................................................................................................ vii CHAPTER I. PURPOSE -

Inclusive Design Considerations for User Experience Designers
Designing Mobile Applications for Older Adults with Cognitive Decline: Inclusive Design Considerations for User Experience Designers by Tomasz Pokinko Submitted to OCAD University in partial fulfillment of the requirements for the degree of Master of Design in Inclusive Design Toronto, Ontario, Canada, April 2015 Tomasz Pokinko, 2015 This work is licensed under the Creative Commons Attribution-Non Commercial 4.0 International License. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc/4.0/ or write to Creative Commons, 171, Second Street, Suite 300, San Francisco, California 94105, USA. i ii Copyright Notice This document is licensed under the Creative Commons Attribution-Non Commercial Works 4.0 License http://creativecommons.org/licenses/by-nc/4.0/ca/ You are free to: • Share — copy and redistribute the material in any medium or format • Adapt — remix, transform, and build upon the material Under the following conditions: • Attribution—You must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use. • Non-Commercial—You may not use this work for commercial purposes. Notice: • You do not have to comply with the license for elements of the material in the public domain or where your use is permitted by an applicable exception or limitation. • No warranties are given. The license may not give you all of the permissions necessary for your intended use. For example, other rights such as publicity, privacy, or moral rights may limit how you use the material. -

O'reilly Animal Book That Tells You How to Build a Unix Firewall Machine from a Box of Toothpicks and an Old Coffee Maker
Information Architecture on the World Wide Web Peter Morville First Edition, February 1998 ISBN: 1-56592-282-4 Learn how to merge aesthetics and mechanics to design Web sites that "work." This book shows how to apply principles of architecture and library science to design cohesive Web sites and intranets that are easy to use, manage, and expand. Covers building complex sites, hierarchy design and organization, and techniques to make your site easier to search. For Webmasters, designers, and administrators. Release Team[oR] 2001 Preface 1 Our Perspective Who This Book Is For How To Use This Book Text Conventions Other (Really Important) Conventions We'd Like to Hear from You Acknowledgments 1 What Makes a Web Site Work 8 1.1 Consumer Sensitivity Boot Camp 1.2 If You Don't Like to Exercise... 2 Introduction to Information Architecture 13 2.1 The Role of the Information Architect 2.2 Who Should Be the Information Architect? 2.3 Collaboration and Communication 3 Organizing Information 20 3.1 Organizational Challenges 3.2 Organizing Web Sites and Intranets 3.3 Creating Cohesive Organization Systems 4 Designing Navigation Systems 42 4.1 Browser Navigation Features 4.2 Building Context 4.3 Improving Flexibility 4.4 Types of Navigation Systems 4.5 Integrated Navigation Elements 4.6 Remote Navigation Elements 4.7 Designing Elegant Navigation Systems 5 Labeling Systems 61 5.1 Why You Should Care About Labeling 5.2 Labeling Systems, Not Labels 5.3 Types of Labeling Systems 5.4 Creating Effective Labeling Systems 5.5 Fine-Tuning the Labeling System -

Metadata and XML Improving the Findability of Information
www.bogieland.com InfoDesign: Understanding by Design Peter J. Bogaards Metadata and XML Improving the Findability of Information Peter J. Bogaards (BogieLand.com) Information Designer & Information Architect “Sharing knowledge is better than having it.” EIDC 2004 - Wiesbaden 10 november 2004 10 november 2004 Metadata and XML 1 www.bogieland.com InfoDesign: Understanding by Design Peter J. Bogaards Introduction • Background in instructional design. (1987) • Design of (tech) facilities to enhance human learning processes. • Interface, document and information designer. (@Informaat ‘90-‘97). • W3: Electronic documentation and user interface design merger. • Information designer and information architect. (@Razorfish EU 2000-2003). • BogieLand (2003): Information design & information architecture consultancy. • InfoDesign: Understanding by Design (>1997). informationdesign.org 10 november 2004 Metadata and XML 2 www.bogieland.com InfoDesign: Understanding by Design Peter J. Bogaards Agenda • Purpose: To paint the landscape • Findability of information • XML and metadata • Subject-based classification: Controlled vocabularies, Thesaurus, Taxonomy, and Ontology • Faceted classification (XFML) • Technologies: Topic maps and RDF • A vision for the future • ?&! 10 november 2004 Metadata and XML 3 www.bogieland.com InfoDesign: Understanding by Design Peter J. Bogaards Findability of Information Finding anyone or anything from anywhere at anytime 10 november 2004 Metadata and XML 4 www.bogieland.com InfoDesign: Understanding by Design Peter J. Bogaards Findability of information • A wealth of information = a poverty of attention • Structure versus chaos • Information architecture: How to organize information in order to let people find things? • Applying concepts, methods and techniques from Library and Information Science • How to improve information retrieval? • Documents are for humans, data is for machines 10 november 2004 Metadata and XML 5 www.bogieland.com InfoDesign: Understanding by Design Peter J. -

Information Architecture the Design and Integration of Information Spaces
Information Architecture The Design and Integration of Information Spaces Second Edition iii Synthesis Lectures on Information Concepts, Retrieval, and Services Editor Gary Marchionini, University of North Carolina, Chapel Hill Synthesis Lectures on Information Concepts, Retrieval, and Services publishes short books on topics pertaining to information science and applications of technology to information discovery, production, distribution, and management. Potential topics include: data models, indexing theory and algorithms, classification, information architecture, information economics, privacy and iden- tity, scholarly communication, bibliometrics and webometrics, personal information management, human information behavior, digital libraries, archives and preservation, cultural informatics, in- formation retrieval evaluation, data fusion, relevance feedback, recommendation systems, question answering, natural language processing for retrieval, text summarization, multimedia retrieval, multilingual retrieval, and exploratory search. Information Architecture: The Design and Integration of Information Spaces: Second Edition Wei Ding, Xia Lin, and Michael Zarro Fuzzy Information Retrieval Donald Kraft and Erin Colvin Incidental Exposure to Online News Borchuluun Yadamsuren and Sanda Erdelez Web Indicators for Research Evaluation: A Practical Guide Michael Thelwall Trustworthy Policies for Distributed Repositories Hao Xu, Mike Conway, Arcot Rajasekar, Jon Crabtree, Helen Tibbo, and Reagan W. Moore The Notion of Relevance in Information Science: Everybody knows what relevance is. But, what is it really? Tefko Saracevic iv Dynamic Information Retrieval Modeling Grace Hui Yang, Marc Sloan, and Jun Wang Learning from Multiple Social Networks Liqiang Nie, Xuemeng Song, and Tat-Seng Chua Scholarly Collaboration on the Academic Social Web Daqing He and Wei Jeng Scalability Challenges in Web Search Engines B. Barla Cambazoglu and Ricardo Baeza-Yates Social Informatics Evolving Pnina Fichman, Madelyn R. -

Download “Building an Information
JOURNAL OF INFORMATION ARCHITECTURE FALL 2010, VOL 2 ISS 2 — Classified Laura Downey & Sumit Banerjee Building an Information Architecture Checklist Encouraging and Enabling IA from Infrastructure to the User Interface Architecture Abstract Government environments often have prescribed complex processes for obtaining and implementing technology solutions. In order to encourage and enable information architecture (IA) in government systems, it is essential to embed IA within the current processes and to view IA as part of the overall architectural framework. The definition of IA used here is broad and inclusive spanning applications, the Web and the enterprise. A common focus exists aimed at organizing information for findability, manageability and usefulness, but the definition also includes infrastructure to support organization of information. This case study describes the development of an IA checklist in a large United States government agency. The checklist is part of an architectural review process that is applied 1) during assessment of proposed information systems projects and 2) design of solution recommendations before system implementation. Introduction: Defining Information Architecture Defining information architecture is an exercise many researchers and practitioners have performed (Zachman 1987; Wurman 1997; Rosenfeld 2002; Bailey 2002; Dillon 2002; Toms 2002; Evernden & Evernden 2003; Dillon & Turnbull 2005; Rosenfeld & Morville 2006; Stiglich 2007; Hinton 2009). Rosenfeld (2002) noted that a widely accepted definition of IA does not exist. Dillon and Turnbull (2005) report that no formal definition of IA has been agreed upon. That still appears true today. Several definitions in the IA field generally focus on organizing information via mechanisms such as labeling, structuring, chunking, and categorizing in order to support navigation, findability and usefulness. -

A Study That Looks Into a Frame of User Interface Design Requirements For
A study that looks into A frame of user interface design requirements for usability and improved consumer behaviors in social commerce MASTERS THESIS WITHIN: Informatics NUMBER OF CREDITS: 30 PROGRAMME OF STUDY: Information Architecture and Innovation AUTHOR: Julian Sybella Nansamba JÖNKÖPING May 2020 Master Thesis in Informatics Title: The impact of user interface usability on consumer behavior in social commerce- Authors: Julian Sybella Nansamba Tutor: Daniela Mihailescu Date: 2020-05-26 Key terms: User interfaces, Usability, Consumer behavior, Social commerce. Abstract User interface usability in social commerce is an important theme today because many businesses are evolving with use of social media in order to easily reach larger markets. The study was based on the fact that online shoppers and their purchase success depend to the great extent they can interact with the interface (usability). Therefore, it is important for companies to attend to the users' online consumer purchase behavior. The purpose of the study is to discuss which interface design requirements can enhance usability that improves consumer behavior in social commerce. The methodology of social constructionist paradigm, a deductive research approach with investigation from multiple exploratory cases was used. For extension of knowledge about the topic both secondary and primary data with interviews was followed. The findings show that the social commerce companies are still facing some challenges because they still lack some of the suggested requirements which hinders the usability of their interfaces. Moreover, they believe that some requirements are not be as important as others. The companies can use these findings to apply and harmonize this frame of requirements into their user interfaces in order to achieve usability that promotes consumer behaviors since they can now realize that the few requirement they never attend to limits the usability of their websites. -

Improving Website Ranking Through Search Engine Optimization
IBIMA Publishing Journal of Internet and e-business Studies http://www.ibimapublishing.com/journals/JIEBS/jiebs.html Vol. 2011 (2011), Article ID 969476, 11 pages DOI: 10.5171/2011.969476 Improving Website Ranking through Search Engine Optimization Ali H. Al-Badi 1, Ali O. Al Majeeni 2, Pam J. Mayhew 2 and Abdullah S. Al-Rashdi 3 1Information Systems Department, College of Commerce and Economics, Sultan Qaboos University, Oman 2 School of Computing Sciences, University of East Anglia, Norwich, UK 3Center for Information Systems, Sultan Qaboos University, Oman ________________________________________________________________________________________________________________ Abstract Internet is fast becoming critically important to commerce, industry and individuals. Perhaps the most important single component of this communication network is the Search Engine (SE). Successful Websites rank high in SEs hits, whereas unsuccessful Websites may not rank at all. In an effort to increase the ranking of Sultan Qaboos University (SQU) amongst international universities, it was recommended to apply “Webometrics” measures. Hence, it was necessary to enhance the university's Website ranking. Therefore, the primary aim of this research is to explore the factors and techniques that contribute to a page ranking highly in a Search Engine Results Page (SERP). The research is divided into two parts. The first part is a descriptive/interpretive analysis aiming to provide an outline of the current and relevant literature with regard to Search Engine Optimization (SEO). It covers how SEs work, and explores the guidelines that are available for Web designers to optimize Web pages, thereby increasing their visibility and ranking. Furthermore, it provides a short history of the most important SEs, differentiates between them, and reviews the approaches they use to crawl, index, and display search results. -

Big Data Analytics for Search Engine Optimization
big data and cognitive computing Article Big Data Analytics for Search Engine Optimization Ioannis C. Drivas 1,* , Damianos P. Sakas 2, Georgios A. Giannakopoulos 1 and Daphne Kyriaki-Manessi 1 1 Department of Archival, Library and Information Studies, Lab of Information Management, University of West Attica, Ag. Spyridonos, 12243 Egaleo, Greece; [email protected] (G.A.G.); [email protected] (D.K.-M.) 2 School of Applied Economics and Social Sciences, Agricultural University of Athens, Iera Odos 75, 11855 Athens, Greece; [email protected] * Correspondence: [email protected]; Tel.: +30-69-7401-6823 Received: 8 March 2020; Accepted: 30 March 2020; Published: 2 April 2020 Abstract: In the Big Data era, search engine optimization deals with the encapsulation of datasets that are related to website performance in terms of architecture, content curation, and user behavior, with the purpose to convert them into actionable insights and improve visibility and findability on the Web. In this respect, big data analytics expands the opportunities for developing new methodological frameworks that are composed of valid, reliable, and consistent analytics that are practically useful to develop well-informed strategies for organic traffic optimization. In this paper, a novel methodology is implemented in order to increase organic search engine visits based on the impact of multiple SEO factors. In order to achieve this purpose, the authors examined 171 cultural heritage websites and their retrieved data analytics about their performance and user experience inside them. Massive amounts of Web-based collections are included and presented by cultural heritage organizations through their websites. Subsequently, users interact with these collections, producing behavioral analytics in a variety of different data types that come from multiple devices, with high velocity, in large volumes. -
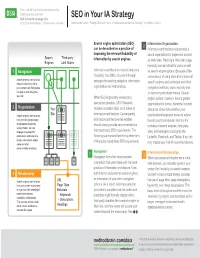
SEO in Your IA Strategy
This is an official illustration produced by DSIA Research Initiative TM SEO in Your IA Strategy SEO in Your IA strategy v1.0 © 2012 Nathaniel Davis | DSIA Research Initiative Based on the article, “Putting SEO in Its Place: An Information Architecture Strategy” - by Nathaniel Davis Search engine optimization (SEO) Information Organization 2 can be described as a practice of Information architecture must provide a improving the relevant findability of sound organization for pages and content Search Third-party information by search engines. on Web sites. Planning a Web site’s page Engines Link Nodes hierarchy can be critical for users as well 1 Navigation Information architecture naturally improves as search engine spiders. Because of the findability, thus SEO, of content through convenience of using internal and external Search engines want to know strategies for enabling navigation, information who and how many link to search engines and contextual and inline your content, and how people organization and relationships. navigation methods, users may rely less navigate to and throughout on taxonomy-structured menus. Search your site While SEO is generally viewed as a engine spiders, however, have a greater specialized practice, DSIA Research appreciation for formal, hierarchal content 2 Organization Your Initiative considers SEO to be native to structures. Determine whether your Search engines want to know Site information architecture. Consequently, organizational approach needs to extend how your site groups pages information architecture deliverables beyond your local domain and into the and organize content by should always provide recommendations domains of search engines, third-party subject matter; text that A displays on a page; the that meet basic SEO requirements. -

On-Site Information Findability
On-site Information findability: towards an integrative view MASTER THESIS WITHIN: Informatics NUMBER OF CREDITS: 30 PROGRAMME OF STUDY: Information Architecture and Innovation AUTHORs: Rients Wiebren Johannes van Blanken, Zdeněk Šrejber JÖNKÖPING May 2020 Master Thesis in Informatics Title: On-site Information findability: towards an integrative view Tutor: Daniela Mihailescu Date: 2020-06-03 Key terms: Findability, Information Architecture, and Social Informatics Abstract A major component of the internet are websites which each have their information architecture, but more importantly, findability. This thesis focusses on the topic of findability, which is defined by Morville as “The quality of being locatable or navigable” (Morville, 2005, p. 4). Findability has become more crucial due to an increasing amount of information and time people spent on searching and gathering information. This motivation has led to the aim of investigating findability through insights into, and a delineation of, two complementary perspectives: information architecture and social informatics. Empirical evidence was collected through semi-structured interviews with design practitioners, and a literature review was conducted to provide an integrated view of findability. The STIN-model and berry-picking model provide a frame of reference which designers can use to improve the findability of their digital platforms. The most predominant suggestions based on the empirical evidence are as follows. Firstly, designers should remember that they are problem solvers and should always use methods appropriate to the problem that needs to be resolved. Secondly, designers should start with problem analysis, which should combine qualitative and quantitative methods to reach the optimal results with regards to user research. Finally, do not reinvent the wheel, make use of already existing tools that incorporate upgradeability and reusability.