PEGASUS: Pre-Training with Extracted Gap-Sentences for Abstractive Summarization
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
MLS Game Guide
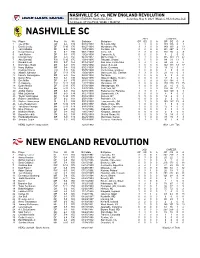
NASHVILLE SC vs. NEW ENGLAND REVOLUTION NISSAN STADIUM, Nashville, Tenn. Saturday, May 8, 2021 (Week 4, MLS Game #44) 12:30 p.m. CT (MyTV30; WSBK / MyRITV) NASHVILLE SC 2021 CAREER No. Player Pos Ht Wt Birthdate Birthplace GP GS G A GP GS G A 1 Joe Willis GK 6-5 189 08/10/1988 St. Louis, MO 3 3 0 0 139 136 0 1 2 Daniel Lovitz DF 5-10 170 08/27/1991 Wyndmoor, PA 3 3 0 0 149 113 2 13 3 Jalil Anibaba DF 6-0 185 10/19/1988 Fontana, CA 0 0 0 0 231 207 6 14 4 David Romney DF 6-2 190 06/12/1993 Irvine, CA 3 3 0 0 110 95 4 8 5 Jack Maher DF 6-3 175 10/28/1999 Caseyville, IL 0 0 0 0 3 2 0 0 6 Dax McCarty MF 5-9 150 04/30/1987 Winter Park, FL 3 3 0 0 385 353 21 62 7 Abu Danladi FW 5-10 170 10/18/1995 Takoradi, Ghana 0 0 0 0 84 31 13 7 8 Randall Leal FW 5-7 163 01/14/1997 San Jose, Costa Rica 3 3 1 2 24 22 4 6 9 Dominique Badji MF 6-0 170 10/16/1992 Dakar, Senegal 1 0 0 0 142 113 33 17 10 Hany Mukhtar MF 5-8 159 03/21/1995 Berlin, Germany 3 3 1 0 18 16 5 4 11 Rodrigo Pineiro FW 5-9 146 05/05/1999 Montevideo, Uruguay 1 0 0 0 1 0 0 0 12 Alistair Johnston DF 5-11 170 10/08/1998 Vancouver, BC, Canada 3 3 0 0 21 18 0 1 13 Irakoze Donasiyano MF 5-9 155 02/03/1998 Tanzania 0 0 0 0 0 0 0 0 14 Daniel Rios FW 6-1 185 02/22/1995 Miguel Hidalgo, Mexico 0 0 0 0 18 8 4 0 15 Eric Miller DF 6-1 175 01/15/1993 Woodbury, MN 0 0 0 0 121 104 0 3 17 CJ Sapong FW 5-11 185 12/27/1988 Manassas, VA 3 0 0 0 279 210 71 25 18 Dylan Nealis DF 5-11 175 07/30/1998 Massapequa, NY 1 0 0 0 20 10 0 0 19 Alex Muyl MF 5-11 175 09/30/1995 New York, NY 3 2 0 0 134 86 11 20 20 Anibal -

Uefa Euro 2020 Final Tournament Draw Press Kit
UEFA EURO 2020 FINAL TOURNAMENT DRAW PRESS KIT Romexpo, Bucharest, Romania Saturday 30 November 2019 | 19:00 local (18:00 CET) #EURO2020 UEFA EURO 2020 Final Tournament Draw | Press Kit 1 CONTENTS HOW THE DRAW WILL WORK ................................................ 3 - 9 HOW TO FOLLOW THE DRAW ................................................ 10 EURO 2020 AMBASSADORS .................................................. 11 - 17 EURO 2020 CITIES AND VENUES .......................................... 18 - 26 MATCH SCHEDULE ................................................................. 27 TEAM PROFILES ..................................................................... 28 - 107 POT 1 POT 2 POT 3 POT 4 BELGIUM FRANCE PORTUGAL WALES ITALY POLAND TURKEY FINLAND ENGLAND SWITZERLAND DENMARK GERMANY CROATIA AUSTRIA SPAIN NETHERLANDS SWEDEN UKRAINE RUSSIA CZECH REPUBLIC EUROPEAN QUALIFIERS 2018-20 - PLAY-OFFS ................... 108 EURO 2020 QUALIFYING RESULTS ....................................... 109 - 128 UEFA EURO 2016 RESULTS ................................................... 129 - 135 ALL UEFA EURO FINALS ........................................................ 136 - 142 2 UEFA EURO 2020 Final Tournament Draw | Press Kit HOW THE DRAW WILL WORK How will the draw work? The draw will involve the two-top finishers in the ten qualifying groups (completed in November) and the eventual four play-off winners (decided in March 2020, and identified as play-off winners 1 to 4 for the purposes of the draw). The draw will spilt the 24 qualifiers -

Sports Back 20-13-6-2016 Layout 1
Posey gets walkoff US reaches Copa single in 10th lifts quarters with win Giants past Dodgers over Paraguay MONDAY, JUNE 13, 2016 16 17 Workmanlike mentality gives Italy hope against Belgium Page 19 STADE DE NICE: Northern Ireland’s midfielder Oliver Norwood (L) and Northern Ireland’s defender Jonny Evans (foreground R) vie ithw Poland’s midfielder Jakub Blaszczykowski (C) during the Euro 2016 group C football match between Poland and Northern Ireland at the Stade de Nice in Nice yesterday. — AFP Poland’s Milik breaks N Ireland hearts NICE: Ajax striker Arkadiusz Milik broke Northern strike early in the second half coming after several misfiring on several occasions, it was a frustrating open- utes into the second period Milik made no mistake Ireland hearts yesterday after rifling home the only goal missed chances in the first. ing period for Poland. Top scorers in qualifying for Euro when firing through the legs of Craig Cathcart after in their Euro 2016 Group C opener in Nice. For Michael O’Neill’s side, it was a disappointing end 2016, they managed just two shots on target in the first Jakub Blaszczykowski found him unmarked on the edge Poland had never won a game before at the to their first ever European Championship match, and period. The first was on the half-hour when a left-footed of the area. Blaszczykowski had his own chance to add European Championship, with three draws and three first major tournament appearance since the 1986 drive by Milik from outside the box was easily parried by to Poland’s tally on 68 minutes but steered wide after losses over two appearances in 2008 and 2012 — the World Cup. -

Mps up in Arms Over Death of 2 Cadets at Military Academy Top Military Officers Suspended; Reports Show Cadets Died of Dehydration
THULHIJJA 23, 1439 AH MONDAY, SEPTEMBER 3, 2018 Max 45º 32 Pages Min 28º 150 Fils Established 1961 ISSUE NO: 17622 The First Daily in the Arabian Gulf www.kuwaittimes.net Kuwait’s Health Minister Migrant crisis continues Iraqi amputees take the Mobot, Olympic dreams 47sets prices of medicines to haunt European Union 24 plunge to forget horrors 28 as Asian Games ends MPs up in arms over death of 2 cadets at military academy Top military officers suspended; Reports show cadets died of dehydration By B Izzak KUWAIT: Lawmakers yesterday expressed outrage at Amir to meet Trump what they described a “murder” of two cadets at the military academy during training and called for strict CAIRO: Kuwait’s ruler will travel to Washington today punishments to those who were directly responsible. and hold talks with US President Donald Trump, the Opposition Islamist MP Mohammad Hayef said that two state news agency KUNA announced yesterday. It was cadets were “killed” in what he described as a “mas- not immediately clear what the leaders would discuss, sacre” at the academy when they were forced to stand but HH Sheikh Sabah Al-Ahmad Al-Jaber Al-Sabah has under the scorching heat of the sun for hours while car- led mediation efforts to resolve a year-long dispute rying heavy weights during training. between Gulf Arab neighbors after Saudi Arabia, the He said several other cadets were suffering of injuries United Arab Emirates, Bahrain and Egypt cut diplomat- and one of them in a grave condition as the senior officers ic, trade and transport ties with Qatar. -

20 17 20 18 Men's Soccer Records Book
Men’s Soccer Records Book 20 20 17 18 Men’s Soccer TABLE OF CONTENTS All-time Ivy Champions .........................................1 Ivy Standings .....................................................2-6 Individual Records ................................................7 Team Records .......................................................8 Ivy League Teams in NCAA play ......................9-10 Ivy League Weekly Award Winners................11-13 Ivy League Players & Rookies of the Year...........14 All-Ivy Teams ................................................15-23 All-Americans .................................................24-26 Academic All-Americans .....................................26 In the MLS Drafts ................................................27 * - Last updated on June 2017. If you have updates or possible edits to the men’s soccer records book, please email [email protected] 17 1 18 Ivy League Records Book MEN’S SOCCER All-Time Champions YEAR CHAMPION(S) IVY CHAMPIONS 1955 Harvard 1995 Cornell Total Outright First Last Penn Brown Champs Champs Champ Champ 1956 Yale 1996 Harvard Brown 20 12 1963 2011 1957 Princeton 1997 Brown Columbia 10 7 1978 2016 Cornell 4 2 1975 2012 1958 Harvard 1998 Brown Dartmouth 12 4 1964 2016 1959 Harvard 1999 Princeton Harvard 13 9 1955 2009 1960 Princeton 2000 Brown Penn 8 3 1955 2013 Princeton 8 4 1957 2014 1961 Harvard 2001 Brown Yale 5 4 1956 2005 1962 Penn Princeton Harvard 2002 Penn 1963 Brown Dartmouth Harvard 2003 Brown 1964 Brown 2004 Dartmouth Dartmouth 2005 Brown 1965 -

Silva: Polished Diamond
CITY v BURNLEY | OFFICIAL MATCHDAY PROGRAMME | 02.01.2017 | £3.00 PROGRAMME | 02.01.2017 BURNLEY | OFFICIAL MATCHDAY SILVA: POLISHED DIAMOND 38008EYEU_UK_TA_MCFC MatDay_210x148w_Jan17_EN_P_Inc_#150.indd 1 21/12/16 8:03 pm CONTENTS 4 The Big Picture 52 Fans: Your Shout 6 Pep Guardiola 54 Fans: Supporters 8 David Silva Club 17 The Chaplain 56 Fans: Junior 19 In Memoriam Cityzens 22 Buzzword 58 Social Wrap 24 Sequences 62 Teams: EDS 28 Showcase 64 Teams: Under-18s 30 Access All Areas 68 Teams: Burnley 36 Short Stay: 74 Stats: Match Tommy Hutchison Details 40 Marc Riley 76 Stats: Roll Call 42 My Turf: 77 Stats: Table Fernando 78 Stats: Fixture List 44 Kevin Cummins 82 Teams: Squads 48 City in the and Offi cials Community Etihad Stadium, Etihad Campus, Manchester M11 3FF Telephone 0161 444 1894 | Website www.mancity.com | Facebook www.facebook.com/mcfcoffi cial | Twitter @mancity Chairman Khaldoon Al Mubarak | Chief Executive Offi cer Ferran Soriano | Board of Directors Martin Edelman, Alberto Galassi, John MacBeath, Mohamed Mazrouei, Simon Pearce | Honorary Presidents Eric Alexander, Sir Howard Bernstein, Tony Book, Raymond Donn, Ian Niven MBE, Tudor Thomas | Life President Bernard Halford Manager Pep Guardiola | Assistants Rodolfo Borrell, Manel Estiarte Club Ambassador | Mike Summerbee | Head of Football Administration Andrew Hardman Premier League/Football League (First Tier) Champions 1936/37, 1967/68, 2011/12, 2013/14 HONOURS Runners-up 1903/04, 1920/21, 1976/77, 2012/13, 2014/15 | Division One/Two (Second Tier) Champions 1898/99, 1902/03, 1909/10, 1927/28, 1946/47, 1965/66, 2001/02 Runners-up 1895/96, 1950/51, 1988/89, 1999/00 | Division Two (Third Tier) Play-Off Winners 1998/99 | European Cup-Winners’ Cup Winners 1970 | FA Cup Winners 1904, 1934, 1956, 1969, 2011 Runners-up 1926, 1933, 1955, 1981, 2013 | League Cup Winners 1970, 1976, 2014, 2016 Runners-up 1974 | FA Charity/Community Shield Winners 1937, 1968, 1972, 2012 | FA Youth Cup Winners 1986, 2008 3 THE BIG PICTURE Celebrating what proved to be the winning goal against Arsenal, scored by Raheem Sterling. -

Made on Merseyside
Made on Merseyside Feature Films: 2010’s: Across the Universe (2006) Little Joe (2019) Beyond Friendship Ip Man 4 (2018) Yesterday (2018) (2005) Tolkien (2017) X (2005) Triple Word Score (2017) Dead Man’s Cards Pulang (2016) (2005) Fated (2004) Film Stars Don’t Die in Liverpool (2016) Alfie (2003) Fantastic Beasts and Where to Find Them Digital (2003) (2015) Millions (2003) Florence Foster Jenkins (2015) The Virgin of Liverpool Genius (2014) (2002) The Boy with a Thorn in His Side (2014) Shooters (2001) Big Society the Musical (2014) Boomtown (2001) 71 (2013) Revenger’s Tragedy Christina Noble (2013) (2001) Fast and Furious 6 John Lennon-In His Life (2012) (2000) Jack Ryan: Shadow Recruit Parole Officer (2000) (2012) The 51st State (2000) Blood (2012) My Kingdom Kelly and Victor (2011) (2000) Captain America: The First Avenger Al’s Lads (2010) (2000) Liam (2000) 2000’s: Route Irish (2009) Harry Potter and the Deathly Hallows (2009) Nowhere Fast (2009) Powder (2009) Nowhere Boy (2009) Sherlock Holmes (2008) Salvage (2008) Kicks (2008) Of Time in the City (2008) Act of Grace (2008) Charlie Noads RIP (2007) The Pool (2007) Three and Out (2007) Awaydays (2007) Mr. Bhatti on Holiday (2007) Outlaws (2007) Grow Your Own (2006) Under the Mud (2006) Sparkle (2006) Appuntamento a Liverpool (1987) No Surrender (1986) Letter to Brezhnev (1985) Dreamchild (1985) Yentl (1983) Champion (1983) Chariots of Fire (1981) 1990’s: 1970’s: Goin’ Off Big Time (1999) Yank (1979) Dockers (1999) Gumshoe (1971) Heart (1998) Life for a Life (1998) 1960’s: Everyone -

Sample Download
Prostate Cancer UK is a registered charity in England and Wales (1005541) and in Scotland (SC039332). Registered company 02653887. RUNNING REPAIRS Foreword – The Athlete 7 Foreword – The Coach 9 Introduction 12 1. Wealth, Health and Sport 15 2 Sport and the Surgeon 20 3. The Call of the Changing Room 27 4 Do Athletes Help Themselves and Their Doctors? 39 5. A Surgeon for All Seasons: The Sporting Calendar 58 6 Shrinking Violets? 67 7. The Young 82 8 The Young at Heart 97 9. Oh, the Games People Play! 112 10. Saturday … or Any Night … Is Alright for Fighting! 119 11. Monkey Glands, Metatarsals and the Medic Manager 127 12 What a Load of Cobblers 135 13. The Healing Powers of the Placenta 143 14. The Wisdom of Teeth 148 15. The Feudalism of Football … and Most Other Sports! 152 16. Chasing the Egg 169 17. Scrambling the Egg 187 18. Bloodgate and the Mighty Quins 203 19. When Is a Broken Leg Not a Broken Leg? 209 20 The Fields Are Green, the Skies Are Blue … 212 21. The Skies Are Grey? 222 22 Big Hearts and Big Bottoms 240 23. Schumi and I: 11 July 1999 250 24 Best Foot Forward – a Dance Odyssey 257 25. Golden Girls and Leaping Lords 269 26 The History of Sports Medicine in Britain and Beyond 281 27. The Chrysalis Becomes the Butterfly 288 28. You’re Simply the Best! 296 29. ‘Sister! Boil Me Up a Solicitor’ 308 30 Publish and be Damned! 319 31. What Goes on Tour Comes Back from Tour 328 32. -

Erarchical Observation, Normalisation, Examination, and the Panoptic Arrangement of Working Football, Docile Football Players Are Produced
University of Alberta The End of the Road?: Discipline and Retirement in British Professional and Semi-Professional Football by Luke Keith Jones A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment of the requirements for the degree of Doctor of Philosophy Faculty of Physical Education and Recreation © Luke Keith Jones Fall 2013 Edmonton, Alberta Permission is hereby granted to the University of Alberta Libraries to reproduce single copies of this thesis and to lend or sell such copies for private, scholarly or scientific research purposes only. Where the thesis is converted to, or otherwise made available in digital form, the University of Alberta will advise potential users of the thesis of these terms. The author reserves all other publication and other rights in association with the copyright in the thesis and, except as herein before provided, neither the thesis nor any substantial portion thereof may be printed or otherwise reproduced in any material form whatsoever without the author's prior written permission. Abstract Overman (2009) has noted that there is no single representative experience of retirement in sport; however, it is clear that retirement from sport is challenging (Sparkes, 1998). Despite over sixty years of sports retirement research, problems continue to be reported amongst retiring athletes (Wylleman, Alfermann, & Lavallee, 2004) and specifically British footballers (Drawer & Fuller, 2002). Roderick (2006) suggested that knowledge of football retirement is limited. This study uses a post-structural understanding of power to discover how young men negotiate the challenges of enforced retirement. Data was gathered during in- depth interviews with 25 former players between the ages of 21-34. -
Not Surprising That the Method Begins to Break Down at This Point
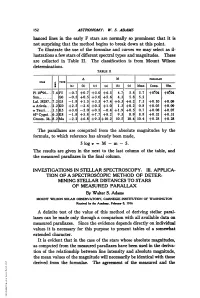
152 ASTRONOMY: W. S. ADAMS hanced lines in the early F stars are normally so prominent that it is not surprising that the method begins to break down at this point. To illustrate the use of the formulae and curves we may select as il- lustrations a few stars of different spectral types and magnitudes. These are collected in Table II. The classification is from Mount Wilson determinations. TABLE H ~A M PARAIuAX srTATYP_________________ (a) I(b) (C) (a) (b) c) Mean Comp. Ob. Pi 10U96.... 7.6F5 -0.7 +0.7 +3.0 +6.5 4.7 5.8 5.7 +0#04 +0.04 Sun........ GO -0.5 +0.5 +3.0 +5.6 4.3 5.8 5.2 Lal. 38287.. 7.2 G5 -1.8 +1.5 +3.5 +7.4 +6.3 +6.2 7.3 +0.10 +0.09 a Arietis... 2.2K0O +2.5 -2.4 +0.2 +1.0 1.3 +0.2 0.8 +0.05 +0.09 aTauri.... 1.1K5 +3.0 -2.0 +0.5 -0.4 +1.9 +0.5 0.7 +0.08 +0.07 61' Cygni...6.3K8 -1.8 +5.8 +7.7 +8.2 9.3 8.9 8.8 +0.32 +0.31 Groom. 34..8.2 Ma -2.2 +6.8 +9.2 +10.2 10.5 10.4 10.4 +0.28 +0.28 The parallaxes are computed from the absolute magnitudes by the formula, to which reference has already been made, 5 logr = M - m - 5. The results are given in the next to the last column of the table, and the measured parallaxes in the final column. -

Binocular Double Star Logbook
Astronomical League Binocular Double Star Club Logbook 1 Table of Contents Alpha Cassiopeiae 3 14 Canis Minoris Sh 251 (Oph) Psi 1 Piscium* F Hydrae Psi 1 & 2 Draconis* 37 Ceti Iota Cancri* 10 Σ2273 (Dra) Phi Cassiopeiae 27 Hydrae 40 & 41 Draconis* 93 (Rho) & 94 Piscium Tau 1 Hydrae 67 Ophiuchi 17 Chi Ceti 35 & 36 (Zeta) Leonis 39 Draconis 56 Andromedae 4 42 Leonis Minoris Epsilon 1 & 2 Lyrae* (U) 14 Arietis Σ1474 (Hya) Zeta 1 & 2 Lyrae* 59 Andromedae Alpha Ursae Majoris 11 Beta Lyrae* 15 Trianguli Delta Leonis Delta 1 & 2 Lyrae 33 Arietis 83 Leonis Theta Serpentis* 18 19 Tauri Tau Leonis 15 Aquilae 21 & 22 Tauri 5 93 Leonis OΣΣ178 (Aql) Eta Tauri 65 Ursae Majoris 28 Aquilae Phi Tauri 67 Ursae Majoris 12 6 (Alpha) & 8 Vul 62 Tauri 12 Comae Berenices Beta Cygni* Kappa 1 & 2 Tauri 17 Comae Berenices Epsilon Sagittae 19 Theta 1 & 2 Tauri 5 (Kappa) & 6 Draconis 54 Sagittarii 57 Persei 6 32 Camelopardalis* 16 Cygni 88 Tauri Σ1740 (Vir) 57 Aquilae Sigma 1 & 2 Tauri 79 (Zeta) & 80 Ursae Maj* 13 15 Sagittae Tau Tauri 70 Virginis Theta Sagittae 62 Eridani Iota Bootis* O1 (30 & 31) Cyg* 20 Beta Camelopardalis Σ1850 (Boo) 29 Cygni 11 & 12 Camelopardalis 7 Alpha Librae* Alpha 1 & 2 Capricorni* Delta Orionis* Delta Bootis* Beta 1 & 2 Capricorni* 42 & 45 Orionis Mu 1 & 2 Bootis* 14 75 Draconis Theta 2 Orionis* Omega 1 & 2 Scorpii Rho Capricorni Gamma Leporis* Kappa Herculis Omicron Capricorni 21 35 Camelopardalis ?? Nu Scorpii S 752 (Delphinus) 5 Lyncis 8 Nu 1 & 2 Coronae Borealis 48 Cygni Nu Geminorum Rho Ophiuchi 61 Cygni* 20 Geminorum 16 & 17 Draconis* 15 5 (Gamma) & 6 Equulei Zeta Geminorum 36 & 37 Herculis 79 Cygni h 3945 (CMa) Mu 1 & 2 Scorpii Mu Cygni 22 19 Lyncis* Zeta 1 & 2 Scorpii Epsilon Pegasi* Eta Canis Majoris 9 Σ133 (Her) Pi 1 & 2 Pegasi Δ 47 (CMa) 36 Ophiuchi* 33 Pegasi 64 & 65 Geminorum Nu 1 & 2 Draconis* 16 35 Pegasi Knt 4 (Pup) 53 Ophiuchi Delta Cephei* (U) The 28 stars with asterisks are also required for the regular AL Double Star Club. -

The Lockdown to Contain the Coronavirus Outbreak Has Disrupted Supply Chains
JOURNALISM OF COURAGE SINCE 1932 The lockdown to contain the coronavirus outbreak has disrupted supply chains. One crucial chain is delivery of information and insight — news and analysis that is fair and accurate and reliably reported from across a nation in quarantine. A voice you can trust amid the clanging of alarm bells. Vajiram & Ravi and The Indian Express are proud to deliver the electronic version of this morning’s edition of The Indian Express to your Inbox. You may follow The Indian Express’s news and analysis through the day on indianexpress.com eye THE SUNDAY EXPRESSMAGAZINE ServesAll,With a NEWDELHI,LATECITY Side of Chutney NOVEMBER1,2020 Idli is one of India’smost 18PAGES,`6.00 consumed breakfast. What (`8BIHAR&RAIPUR,`12SRINAGAR) accounts forits popularity? DAILY FROM: AHMEDABAD, CHANDIGARH, DELHI,JAIPUR, KOLKATA, LUCKNOW, MUMBAI,NAGPUR,PUNE, VADODARA WWW.INDIANEXPRESS.COM PAGES 14, 15, 16 THE WORLD EXPRESSINVESTIGATION PART ONE RASHTRIYAEKTA DIWAS ADDRESS Direct Benefit Transfer is direct PakadmitstoPulwama… siphoning of school scholarship timeworldunitestostamp SEAN CONNERY, THE In severaldistrictsofJharkhand,minority studentsare being dupedofa FIRSTJAMES BOND, outterror,itsbackers:PM DIES AT 90 Centrallyfundedscholarship by anexus of bank staff, middlemen, school PAGE 12 and govt employees, an investigation by The IndianExpress has found ‘Admission of attacktruth in PakistanHouse exposes real face of Oppositionhere, their distasteful statements’ Yogiwarning: Tribal boy is EXPRESSNEWSSERVICE Endlove jihad, shown as VADODARA,OCTOBER31 Parsi, woman PRIME MINISTER Narendra or get ready Modi said SaturdaythatPakistan told money had admitted to the “truth” that for Ram naam it wasbehind the Pulwama ter- rorattackin2019. satya hai from Saudi He said this admissioninthe Pakistanparliament —“wahan ki sansad meisatyasweekaragaya EXPRESSNEWSSERVICE ABHISHEKANGAD hai”—also exposed“the real LUCKNOW,OCTOBER31 RANCHI,DHANBAD,LATEHAR, face” of the Opposition parties at RAMGARH,LOHARDAGA, home.