Bibliography Tools in the Context of WWW and LATEX
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Comparison of Researcher's Reference Management Software
Journal of Economics and Behavioral Studies Vol. 6, No. 7, pp. 561-568, July 2014 (ISSN: 2220-6140) A Comparison of Researcher’s Reference Management Software: Refworks, Mendeley, and EndNote Sujit Kumar Basak Durban University of Technology, South Africa [email protected] Abstract: This paper aimed to present a comparison of researcher’s reference management software such as RefWorks, Mendeley, and EndNote. This aim was achieved by comparing three software. The main results of this paper were concluded by comparing three software based on the experiment. The novelty of this paper is the comparison of researcher’s reference management software and it has showed that Mendeley reference management software can import more data from the Google Scholar for researchers. This finding could help to know researchers to use the reference management software. Keywords: Reference management software, comparison and researchers 1. Introduction Reference management software maintains a database to references and creates bibliographies and the reference lists for the written works. It makes easy to read and to record the elements for the reference comprises such as the author’s name, year of publication, and the title of an article, etc. (Reiss & Reiss, 2002). Reference Management Software is usually used by researchers, technologists, scientists, and authors, etc. to keep their records and utilize the bibliographic citations; hence it is one of the most complicated aspects among researchers. Formatting references as a matter of fact depends on a variety of citation styles which have been made the citation manager very essential for researchers at all levels (Gilmour & Cobus-Kuo, 2011). Reference management software is popularly known as bibliographic software, citation management software or personal bibliographic file managers (Nashelsky & Earley, 1991). -

A Publication of the Science Fiction Research Association in This Issue
292 Spring 2010 Editors Karen Hellekson SFRA 16 Rolling Rdg. A publication of the Science Fiction Research Association Jay, ME 04239 Review [email protected] [email protected] In This Issue Craig Jacobsen SFRA Review Business English Department Counting Down 2 Mesa Community College 1833 West Southern Ave. SFRA Business Mesa, AZ 85202 Statement in Response to the Arizona Immigration Bill 2 [email protected] Ask not what you can do for SFRA… 2 [email protected] SFRA Award Winners 3 Call for Executive Committee Candidates 4 Managing Editor Feature Janice M. Bogstad McIntyre Library-CD Scholarly Research and Writing 101 4 University of Wisconsin-Eau Claire Nonfiction Reviews 105 Garfield Ave. Classics and Contemporaries 8 Eau Claire, WI 54702-5010 [email protected] The Universe of Oz 9 The Unknown Lovecraft 10 Nonfiction Editor War of the Words: The Utopian Vision of H. G. Wells 11 Ed McKnight Fiction Reviews 113 Cannon Lane Deceiver 12 Taylors, SC 29687 [email protected] The Casebook of Victor Frankenstein: A Novel 12 Ares Express 14 Fiction Editor Nebula Awards Showcase 2010 15 Edward Carmien Brain Thief 16 29 Sterling Rd. Transition 17 Princeton, NJ 08540 Media Reviews [email protected] Avatar 18 Media Editor Pumzi 20 Ritch Calvin The Imaginarium of Doctor Parnassus 22 16A Erland Rd. Southern Portable Panic: Federico Álvarez’s Ataque de Pánico! 23 Stony Brook, NY 11790-1114 District B13 (Banlieue 13) 24 [email protected] Small Steps for Ants, a Giant Leap for Mankind: The SFRA Review (ISSN 1068- 395X) is published four times a year by Saul Bass’s Phase IV 24 the Science Fiction Research Association Pushing the Wrong Buttons 25 (SFRA), and distributed to SFRA members. -

Indesign CC 2015 and Earlier
Adobe InDesign Help Legal notices Legal notices For legal notices, see http://help.adobe.com/en_US/legalnotices/index.html. Last updated 11/4/2019 iii Contents Chapter 1: Introduction to InDesign What's new in InDesign . .1 InDesign manual (PDF) . .7 InDesign system requirements . .7 What's New in InDesign . 10 Chapter 2: Workspace and workflow GPU Performance . 18 Properties panel . 20 Import PDF comments . 24 Sync Settings using Adobe Creative Cloud . 27 Default keyboard shortcuts . 31 Set preferences . 45 Create new documents | InDesign CC 2015 and earlier . 47 Touch workspace . 50 Convert QuarkXPress and PageMaker documents . 53 Work with files and templates . 57 Understand a basic managed-file workflow . 63 Toolbox . 69 Share content . 75 Customize menus and keyboard shortcuts . 81 Recovery and undo . 84 PageMaker menu commands . 85 Assignment packages . 91 Adjust your workflow . 94 Work with managed files . 97 View the workspace . 102 Save documents . 106 Chapter 3: Layout and design Create a table of contents . 112 Layout adjustment . 118 Create book files . 121 Add basic page numbering . 127 Generate QR codes . 128 Create text and text frames . 131 About pages and spreads . 137 Create new documents (Chinese, Japanese, and Korean only) . 140 Create an index . 144 Create documents . 156 Text variables . 159 Create type on a path . .. -

Altmetric.Com and Plumx
This is a preprint of an article published in Scientometrics. The final authenticated version is available online at: https://doi.org/10.1007/s11192-021-03941-y A large-scale comparison of coverage and mentions captured by the two altmetric aggregators- Altmetric.com and PlumX Mousumi Karmakara, Sumit Kumar Banshalb, Vivek Kumar Singha,1 1Department of Computer Science, Banaras Hindu University, Varanasi-221005, India 2Department of Computer Science, South Asian University, New Delhi-110021, India. Abstract: The increased social media attention to scholarly articles has resulted in creation of platforms & services to track the social media transactions around them. Altmetric.com and PlumX are two such popular altmetric aggregators. Scholarly articles get mentions in different social platforms (such as Twitter, Blog, Facebook) and academic social networks (such as Mendeley, Academia and ResearchGate). The aggregators track activity and events in social media and academic social networks and provide the coverage and transaction data to researchers for various purposes. Some previous studies have compared different altmetric aggregators and found differences in the coverage and mentions captured by them. This paper attempts to revisit the question by doing a large-scale analysis of altmetric mentions captured by the two aggregators, for a set 1,785,149 publication records from Web of Science. Results obtained show that PlumX tracks more altmetric sources and captures altmetric events for a larger number of articles as compared to Altmetric.com. However, the coverage and average mentions of the two aggregators, for the same set of articles, vary across different platforms, with Altmetric.com recording higher mentions in Twitter and Blog, and PlumX recording higher mentions in Facebook and Mendeley. -

Studies and Analysis of Reference Management Software: a Literature Review
Studies and analysis of reference management software: a literature review Jesús Tramullas Ana Sánchez-Casabón {jesus,asanchez}@unizar.es Dept .of Library & Information Science, University of Zaragoza Piedad Garrido-Picazo [email protected] Dept. of Computer and Software Engineering, University of Zaragoza Abstract: Reference management software is a well-known tool for scientific research work. Since the 1980s, it has been the subject of reviews and evaluations in library and information science literature. This paper presents a systematic review of published studies that evaluate reference management software with a comparative approach. The objective is to identify the types, models, and evaluation criteria that authors have adopted, in order to determine whether the methods used provide adequate methodological rigor and useful contributions to the field of study. Keywords: reference management software, evaluation methods, bibliography. 1. Introduction and background Reference management software has been a useful tool for researchers since the 1980s. In those early years, tools were made ad-hoc, and some were based on the dBase II/III database management system (Bertrand and Bader, 1980; Kunin, 1985). In a short period of time a market was created and commercial products were developed to provide support to this type of information resources. The need of researchers to systematize scientific literature in both group and personal contexts, and to integrate mechanisms into scientific production environments in order to facilitate and expedite the process of writing and publishing research results, requires that these types of applications receive almost constant attention in specialized library and information science literature. The result of this interest is reflected, in bibliographical terms, in the publication of numerous articles almost exclusively devoted to describing, analyzing, and comparing the characteristics of several reference management software products (Norman, 2010). -
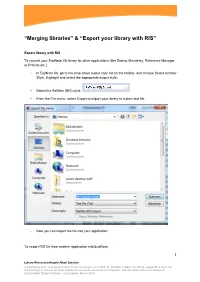
“Merging Libraries” & “Export Your Library with RIS”
“Merging libraries” & “Export your library with RIS” Export library with RIS To convert your EndNote X6 library for other applications (like Zotero, Mendeley, Reference Manager or ProCite etc.): - In EndNote X6, go to the drop-down output style list on the toolbar, and choose Select Another Style. Highlight and select the appropriate output style: - Select the RefMan (RIS) style. - From the File menu, select Export to export your library to a plain text file. - Now you can import the file into your application To import RIS file from another application into EndNote: 1 Library Wissenschaftspark Albert Einstein A joint library of the German Research Centre for Geosciences GFZ, the Potsdam Institute for Climate Impact Research, the Alfred Wegener Institute for Polar and Marine Research, Research Unit Potsdam, and the IASS Institute for Advanced Sustainability Studies Potsdam (Last update: March 2013) - Got to “File” and “Import” - Choose your file in RIS format - Use the RIS import option. - Set your preferences - Import the references 2 Library Wissenschaftspark Albert Einstein A joint library of the German Research Centre for Geosciences GFZ, the Potsdam Institute for Climate Impact Research, the Alfred Wegener Institute for Polar and Marine Research, Research Unit Potsdam, and the IASS Institute for Advanced Sustainability Studies Potsdam (Last update: March 2013) Merging libraries There are three ways to merge libraries: import one library into another, copy references from one library to another, or drag-and-drop. - (Optional) If you want to import only a subset of references from a library, first open that library and show only the references you wish to copy. -

Tool Support for the Search Process of Systematic Literature Reviews
Institute of Architecture of Application Systems University of Stuttgart Universitätsstraße 38 D–70569 Stuttgart Bachelorarbeit Tool Support for the Search Process of Systematic Literature Reviews Dominik Voigt Course of Study: Informatik Examiner: Prof. Dr. Dr. h. c. Frank Leymann Supervisor: Karoline Wild, M.Sc. Commenced: May 4, 2020 Completed: November 4, 2020 Abstract Systematic Literature Review (SLR) is a popular research method with adoption across different research domains that is used to draw generalizations, compose multiple existing concepts into a new one, or identify conflicts and gaps in existing research. Within the Information Technology domain, researchers face multiple challenges during the search step of an SLR which are caused by the use of different query languages by digital libraries. This thesis proposes tool support that provides cross-library search by using a common query language across digital libraries. For this the existing digital library APIs and query languages have been analyzed and a new cross-library query language and transformation was developed that allows the formulation of cross-library queries that can be transformed into existing query languages. These concepts have been integrated within an existing reference management tool to provide integrated and automated cross-library search and result management to address the challenges faced by Information Technology researchers during the search step. 3 Contents 1 Introduction 13 2 Background and Fundamentals 15 2.1 Systematic Literature Review Process ....................... 15 2.2 Metadata Formats for Literature Reference Management ............. 20 2.3 Queries on Digital Libraries ............................ 21 2.4 Challenges during the Search Process ....................... 24 3 Related Work 29 3.1 Existing Approaches ............................... -

Getting Started with Vetsrev
Getting started with VetSRev Authors: Douglas Grindlay, Rachel Dean & Marnie Brennan, 21 August 2013 VetSRev (www.nottingham.ac.uk/cevm/vetsrev) is a database of veterinary systematic reviews. VetSrev is produced using Refbase, an open source database for managing scientific literature & citations. This introductory guide, Getting started with VetSRev, provides a brief overview of the functions of the database to help new users. For more information about VetSRev, please see About VetSRev. Detailed instructions for using Refbase (not specific to VetSRev) can be found in the online Refbase documentation—see in particular the section on “Usage”: http://www.refbase.net/index.php/Documentation If you have any queries about using VetSRev that are not answered by this guide, please contact us at [email protected]. Contents: Page 1. The VetSRev Home Page 2 2. How do I view all the records in the database? 3 3. How do I do a quick search? 3 4. How do I view records in the results display? 4 5. How do I change the results display to a different view? 5 6. How do I view the original publication for a citation? 5 7. How do I view an individual record for a citation? 6 8. How does the database perform a search? 7 9. How do I search for citations on a specific animal species? 7 10. How do I search for citations on a specific topic? 7 11. What does the Simple Search do? 8 12. How do I use the Advanced Search? 8 13. How do I combine search terms? 9 14. -

On Publication Usage in a Social Bookmarking System
On Publication Usage in a Social Bookmarking System Daniel Zoller Stephan Doerfel Robert Jäschke Data Mining and Information ∗ L3S Research Center Retrieval Group ITeG, Knowledge and Data [email protected] University of Würzburg Engineering (KDE) Group [email protected] University of Kassel wuerzburg.de [email protected] Gerd Stumme Andreas Hotho ITeG, Knowledge and Data Data Mining and Information Engineering Group (KDE) Retrieval Group University of Kassel University of Würzburg [email protected] [email protected] kassel.de wuerzburg.de ABSTRACT The creation of impact measures from such data has been Scholarly success is traditionally measured in terms of cita- subsumed under the umbrella term altmetrics (alternative tions to publications. With the advent of publication man- metrics). According to the Altmetrics Manifesto [4] the agement and digital libraries on the web, scholarly usage goals of this initiative are to complement traditional bib- data has become a target of investigation and new impact liometric measures, to introduce diversity in measuring im- metrics computed on such usage data have been proposed pact, and to supplement peer-review. The manifesto also { so called altmetrics. In scholarly social bookmarking sys- appeals: \Work should correlate between altmetrics and ex- tems, scientists collect and manage publication meta data isting measures, predict citations from altmetrics and com- and thus reveal their interest in these publications. In this pare altmetrics with expert evaluation." In that spirit, we work, we investigate connections between usage metrics and analyze the usage metrics that can be computed in the social citations, and find posts, exports, and page views of publi- web system BibSonomy,1 a bookmarking tool for publica- cations to be correlated to citations. -

Why Your Company Needs a Reference Management Tool and Four Factors to Consider When Selecting One
Why your company needs a reference management tool And four factors to consider when selecting one Does the following scenario sound familiar to you? Your company needs to keep on top of the latest research findings to stay competitive. Team members will find and locate PDF articles and save them on their own computers. In another workgroup, the same paper might be found, purchased, and analyzed as well. One year later, the paper might be needed for another project, but since no one could find it on the net- work, it’s then located, purchased, and analyzed again. All of this extra work means wasted time and money for your compa- ny. What’s more, this problem could have been avoided if the PDF and its notes had simply been saved in a place where other team members could find them. Reference management software can help with this challenge, since it provides a central place for saving external literature and making it easy to find again. Originally developed for the university environmvent, reference management programs have been increasingly adopted by knowledge-oriented companies over the past decade. 1/11 Three challenges – finding, saving, and protecting information Reference management software helps with three main challenges that knowledge-oriented companies face: • Being able to pick out useful sources and ideas from the multitude of information that is published and then later find it again. • Working together in a team to create a knowledge repository, thus making each team member’s information and insights available to everyone else in the group. • Protecting this hard-won knowledge from loss or access by third parties. -

Aigaion: a Web-Based Open Source Software for Managing the Bibliographic References
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by E-LIS repository Aigaion: A Web-based Open Source Software for Managing the Bibliographic References Sanjo Jose ([email protected]) Francis Jayakanth ([email protected]) National Centre for Science Information, Indian Institute of Science, Bangalore – 560 012 Abstract Publishing research papers is an integral part of a researcher's professional life. Every research article will invariably provide large number of citations/bibliographic references of the papers that are being cited in that article. All such citations are to be rendered in the citation style specified by a publisher and they should be accurate. Researchers, over a period of time, accumulate a large number of bibliographic references that are relevant to their research and cite relevant references in their own publications. Efficient management of bibliographic references is therefore an important task for every researcher and it will save considerable amount of researchers' time in locating the required citations and in the correct rendering of citation details. In this paper, we are reporting the features of Aigaion, a web-based, open-source software for reference management. 1. Introduction A citation or bibliographic citation is a reference to a book, article, web page, or any other published item. The reference will contain adequate details to facilitate the readers to locate the publication. Different citation systems and styles are being used in different disciplines like science, social science, humanities, etc. Referencing is also a standardised method of acknowledging the original source of information or idea. -

What's in Extras
What’s In Extras 2021/09/20 1 The Extras Folder The Extras folder contains several sub-folders with: • duplicates of several GUI programs installed by the MacTEX installer for those who already have a TEX distribution; • alternates to the GUI applications installed by the MacTEX installer; and • additional software that aE T Xer might find useful. The following sub-sections describe the software contained within them. Table (1), on the next page, contains a complete list of the enclosed software, versions, supported macOS versions, licenses and URLs. Note: for 2020 MacTEX supports High Sierra, Mojave and Catalina although some software also supports earlier versions of macOS. Earlier versions of applications are no longer supplied in the Extras folder but you may find them at the supplied URL. 1.1 Bibliography Bibliography programs for building and maintaining BibTEX databases. 1.2 Browsers A program to browse symbols used with LATEX. 1.3 Editors & Front Ends Alternative Editors, Typesetters and Previewers for TEX. These range from “WYSIWYM (What You See Is What You Mean)” to a Programmer’s Editor with strong LATEX support. 1.4 Equation Editors These allow the user to create beautiful equations, etc., that may be exported for use in other appli- cations; e.g., editors, illustration and presentation software. 1.5 Previewers Separate DVI and PDF previewers for use as external viewers with other editors. 1.6 Scripts Files to integrate some external programmer’s editors with the TEX system. 1.7 Spell Checkers Alternate TEX, LATEX and ConTEXt aware spell checkers. 1.8 Utilities Utilities for managing your MacTEX distribution.