Analytical and Other Software on the Secure Research Environment
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Installing R
Installing R Russell Almond August 29, 2020 Objectives When you finish this lesson, you will be able to 1) Start and Stop R and R Studio 2) Download, install and run the tidyverse package. 3) Get help on R functions. What you need to Download R is a programming language for statistics. Generally, the way that you will work with R code is you will write scripts—small programs—that do the analysis you want to do. You will also need a development environment which will allow you to edit and run the scripts. I recommend RStudio, which is pretty easy to learn. In general, you will need three things for an analysis job: • R itself. R can be downloaded from https://cloud.r-project.org. If you use a package manager on your computer, R is likely available there. The most common package managers are homebrew on Mac OS, apt-get on Debian Linux, yum on Red hat Linux, or chocolatey on Windows. You may need to search for ‘cran’ to find the name of the right package. For Debian Linux, it is called r-base. • R Studio development environment. R Studio https://rstudio.com/products/rstudio/download/. The free version is fine for what we are doing. 1 There are other choices for development environments. I use Emacs and ESS, Emacs Speaks Statistics, but that is mostly because I’ve been using Emacs for 20 years. • A number of R packages for specific analyses. These can be downloaded from the Comprehensive R Archive Network, or CRAN. Go to https://cloud.r-project.org and click on the ‘Packages’ tab. -
A Comprehensive Embedding Approach for Determining Repository Similarity
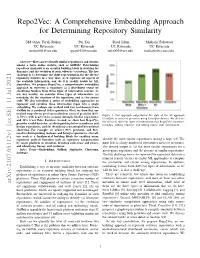
Repo2Vec: A Comprehensive Embedding Approach for Determining Repository Similarity Md Omar Faruk Rokon Pei Yan Risul Islam Michalis Faloutsos UC Riverside UC Riverside UC Riverside UC Riverside [email protected] [email protected] [email protected] [email protected] Abstract—How can we identify similar repositories and clusters among a large online archive, such as GitHub? Determining repository similarity is an essential building block in studying the dynamics and the evolution of such software ecosystems. The key challenge is to determine the right representation for the diverse repository features in a way that: (a) it captures all aspects of the available information, and (b) it is readily usable by ML algorithms. We propose Repo2Vec, a comprehensive embedding approach to represent a repository as a distributed vector by combining features from three types of information sources. As our key novelty, we consider three types of information: (a) metadata, (b) the structure of the repository, and (c) the source code. We also introduce a series of embedding approaches to represent and combine these information types into a single embedding. We evaluate our method with two real datasets from GitHub for a combined 1013 repositories. First, we show that our method outperforms previous methods in terms of precision (93% Figure 1: Our approach outperforms the state of the art approach vs 78%), with nearly twice as many Strongly Similar repositories CrossSim in terms of precision using CrossSim dataset. We also see and 30% fewer False Positives. Second, we show how Repo2Vec the effect of different types of information that Repo2Vec considers: provides a solid basis for: (a) distinguishing between malware and metadata, adding structure, and adding source code information. -

A Tensor Compiler for Unified Machine Learning Prediction Serving
A Tensor Compiler for Unified Machine Learning Prediction Serving Supun Nakandala, UC San Diego; Karla Saur, Microsoft; Gyeong-In Yu, Seoul National University; Konstantinos Karanasos, Carlo Curino, Markus Weimer, and Matteo Interlandi, Microsoft https://www.usenix.org/conference/osdi20/presentation/nakandala This paper is included in the Proceedings of the 14th USENIX Symposium on Operating Systems Design and Implementation November 4–6, 2020 978-1-939133-19-9 Open access to the Proceedings of the 14th USENIX Symposium on Operating Systems Design and Implementation is sponsored by USENIX A Tensor Compiler for Unified Machine Learning Prediction Serving Supun Nakandalac,∗, Karla Saurm, Gyeong-In Yus,∗, Konstantinos Karanasosm, Carlo Curinom, Markus Weimerm, Matteo Interlandim mMicrosoft, cUC San Diego, sSeoul National University {<name>.<surname>}@microsoft.com,[email protected], [email protected] Abstract TensorFlow [13] combined, and growing faster than both. Machine Learning (ML) adoption in the enterprise requires Acknowledging this trend, traditional ML capabilities have simpler and more efficient software infrastructure—the be- been recently added to DNN frameworks, such as the ONNX- spoke solutions typical in large web companies are simply ML [4] flavor in ONNX [25] and TensorFlow’s TFX [39]. untenable. Model scoring, the process of obtaining predic- When it comes to owning and operating ML solutions, en- tions from a trained model over new data, is a primary con- terprises differ from early adopters in their focus on long-term tributor to infrastructure complexity and cost as models are costs of ownership and amortized return on investments [68]. trained once but used many times. In this paper we propose As such, enterprises are highly sensitive to: (1) complexity, HUMMINGBIRD, a novel approach to model scoring, which (2) performance, and (3) overall operational efficiency of their compiles featurization operators and traditional ML models software infrastructure [14]. -

Naiad: a Timely Dataflow System
Naiad: A Timely Dataflow System Derek G. Murray Frank McSherry Rebecca Isaacs Michael Isard Paul Barham Mart´ın Abadi Microsoft Research Silicon Valley {derekmur,mcsherry,risaacs,misard,pbar,abadi}@microsoft.com Abstract User queries Low-latency query are received responses are delivered Naiad is a distributed system for executing data parallel, cyclic dataflow programs. It offers the high throughput Queries are of batch processors, the low latency of stream proces- joined with sors, and the ability to perform iterative and incremental processed data computations. Although existing systems offer some of Complex processing these features, applications that require all three have re- incrementally re- lied on multiple platforms, at the expense of efficiency, Updates to executes to reflect maintainability, and simplicity. Naiad resolves the com- data arrive changed data plexities of combining these features in one framework. A new computational model, timely dataflow, under- Figure 1: A Naiad application that supports real- lies Naiad and captures opportunities for parallelism time queries on continually updated data. The across a wide class of algorithms. This model enriches dashed rectangle represents iterative processing that dataflow computation with timestamps that represent incrementally updates as new data arrive. logical points in the computation and provide the basis for an efficient, lightweight coordination mechanism. requirements: the application performs iterative process- We show that many powerful high-level programming ing on a real-time data stream, and supports interac- models can be built on Naiad’s low-level primitives, en- tive queries on a fresh, consistent view of the results. abling such diverse tasks as streaming data analysis, it- However, no existing system satisfies all three require- erative machine learning, and interactive graph mining. -

Practice with Python
CSI4108-01 ARTIFICIAL INTELLIGENCE 1 Word Embedding / Text Processing Practice with Python 2018. 5. 11. Lee, Gyeongbok Practice with Python 2 Contents • Word Embedding – Libraries: gensim, fastText – Embedding alignment (with two languages) • Text/Language Processing – POS Tagging with NLTK/koNLPy – Text similarity (jellyfish) Practice with Python 3 Gensim • Open-source vector space modeling and topic modeling toolkit implemented in Python – designed to handle large text collections, using data streaming and efficient incremental algorithms – Usually used to make word vector from corpus • Tutorial is available here: – https://github.com/RaRe-Technologies/gensim/blob/develop/tutorials.md#tutorials – https://rare-technologies.com/word2vec-tutorial/ • Install – pip install gensim Practice with Python 4 Gensim for Word Embedding • Logging • Input Data: list of word’s list – Example: I have a car , I like the cat → – For list of the sentences, you can make this by: Practice with Python 5 Gensim for Word Embedding • If your data is already preprocessed… – One sentence per line, separated by whitespace → LineSentence (just load the file) – Try with this: • http://an.yonsei.ac.kr/corpus/example_corpus.txt From https://radimrehurek.com/gensim/models/word2vec.html Practice with Python 6 Gensim for Word Embedding • If the input is in multiple files or file size is large: – Use custom iterator and yield From https://rare-technologies.com/word2vec-tutorial/ Practice with Python 7 Gensim for Word Embedding • gensim.models.Word2Vec Parameters – min_count: -

Gensim Is Robust in Nature and Has Been in Use in Various Systems by Various People As Well As Organisations for Over 4 Years
Gensim i Gensim About the Tutorial Gensim = “Generate Similar” is a popular open source natural language processing library used for unsupervised topic modeling. It uses top academic models and modern statistical machine learning to perform various complex tasks such as Building document or word vectors, Corpora, performing topic identification, performing document comparison (retrieving semantically similar documents), analysing plain-text documents for semantic structure. Audience This tutorial will be useful for graduates, post-graduates, and research students who either have an interest in Natural Language Processing (NLP), Topic Modeling or have these subjects as a part of their curriculum. The reader can be a beginner or an advanced learner. Prerequisites The reader must have basic knowledge about NLP and should also be aware of Python programming concepts. Copyright & Disclaimer Copyright 2020 by Tutorials Point (I) Pvt. Ltd. All the content and graphics published in this e-book are the property of Tutorials Point (I) Pvt. Ltd. The user of this e-book is prohibited to reuse, retain, copy, distribute or republish any contents or a part of contents of this e-book in any manner without written consent of the publisher. We strive to update the contents of our website and tutorials as timely and as precisely as possible, however, the contents may contain inaccuracies or errors. Tutorials Point (I) Pvt. Ltd. provides no guarantee regarding the accuracy, timeliness or completeness of our website or its contents including this tutorial. If you discover any errors on our website or in this tutorial, please notify us at [email protected] ii Gensim Table of Contents About the Tutorial .......................................................................................................................................... -

Software Framework for Topic Modelling with Large
Software Framework for Topic Modelling Radim Řehůřek and Petr Sojka NLP Centre, Faculty of Informatics, Masaryk University, Brno, Czech Republic {xrehurek,sojka}@fi.muni.cz http://nlp.fi.muni.cz/projekty/gensim/ the available RAM, in accordance with While an intuitive interface is impor- Although evaluation of the quality of NLP Framework for VSM the current trends in NLP (see e.g. [3]). tant for software adoption, it is of course the obtained similarities is not the subject rather trivial and useless in itself. We have of this paper, it is of course of utmost Large corpora are ubiquitous in today’s Intuitive API. We wish to minimise the therefore implemented some of the popular practical importance. Here we note that it world and memory quickly becomes the lim- number of method names and interfaces VSM methods, Latent Semantic Analysis, is notoriously hard to evaluate the quality, iting factor in practical applications of the that need to be memorised in order to LSA and Latent Dirichlet Allocation, LDA. as even the preferences of different types Vector Space Model (VSM). In this paper, use the package. The terminology is The framework is heavily documented of similarity are subjective (match of main we identify a gap in existing implementa- NLP-centric. and is available from http://nlp.fi. topic, or subdomain, or specific wording/- tions of many of the popular algorithms, Easy deployment. The package should muni.cz/projekty/gensim/. This plagiarism) and depends on the motivation which is their scalability and ease of use. work out-of-the-box on all major plat- website contains sections which describe of the reader. -

Lightgbm Release 3.2.1.99
LightGBM Release 3.2.1.99 Microsoft Corporation Sep 26, 2021 CONTENTS: 1 Installation Guide 3 2 Quick Start 21 3 Python-package Introduction 23 4 Features 29 5 Experiments 37 6 Parameters 43 7 Parameters Tuning 65 8 C API 71 9 Python API 99 10 Distributed Learning Guide 175 11 LightGBM GPU Tutorial 185 12 Advanced Topics 189 13 LightGBM FAQ 191 14 Development Guide 199 15 GPU Tuning Guide and Performance Comparison 201 16 GPU SDK Correspondence and Device Targeting Table 205 17 GPU Windows Compilation 209 18 Recommendations When Using gcc 229 19 Documentation 231 20 Indices and Tables 233 Index 235 i ii LightGBM, Release 3.2.1.99 LightGBM is a gradient boosting framework that uses tree based learning algorithms. It is designed to be distributed and efficient with the following advantages: • Faster training speed and higher efficiency. • Lower memory usage. • Better accuracy. • Support of parallel, distributed, and GPU learning. • Capable of handling large-scale data. For more details, please refer to Features. CONTENTS: 1 LightGBM, Release 3.2.1.99 2 CONTENTS: CHAPTER ONE INSTALLATION GUIDE This is a guide for building the LightGBM Command Line Interface (CLI). If you want to build the Python-package or R-package please refer to Python-package and R-package folders respectively. All instructions below are aimed at compiling the 64-bit version of LightGBM. It is worth compiling the 32-bit version only in very rare special cases involving environmental limitations. The 32-bit version is slow and untested, so use it at your own risk and don’t forget to adjust some of the commands below when installing. -

Word2vec and Beyond Presented by Eleni Triantafillou
Word2vec and beyond presented by Eleni Triantafillou March 1, 2016 The Big Picture There is a long history of word representations I Techniques from information retrieval: Latent Semantic Analysis (LSA) I Self-Organizing Maps (SOM) I Distributional count-based methods I Neural Language Models Important take-aways: 1. Don't need deep models to get good embeddings 2. Count-based models and neural net predictive models are not qualitatively different source: http://gavagai.se/blog/2015/09/30/a-brief-history-of-word-embeddings/ Continuous Word Representations I Contrast with simple n-gram models (words as atomic units) I Simple models have the potential to perform very well... I ... if we had enough data I Need more complicated models I Continuous representations take better advantage of data by modelling the similarity between the words Continuous Representations source: http://www.codeproject.com/Tips/788739/Visualization-of- High-Dimensional-Data-using-t-SNE Skip Gram I Learn to predict surrounding words I Use a large training corpus to maximize: T 1 X X log p(w jw ) T t+j t t=1 −c≤j≤c; j6=0 where: I T: training set size I c: context size I wj : vector representation of the jth word Skip Gram: Think of it as a Neural Network Learn W and W' in order to maximize previous objective Output layer y1,j W'N×V Input layer Hidden layer y2,j xk WV×N hi W'N×V N-dim V-dim W'N×V yC,j C×V-dim source: "word2vec parameter learning explained." ([4]) CBOW Input layer x1k WV×N Output layer Hidden layer x W W' 2k V×N hi N×V yj N-dim V-dim WV×N xCk C×V-dim source: -

Read.Csv("Titanic.Csv", As.Is = "Name") Factors - Categorical Variables
Introduction to R by Debby Kermer George Mason University Library Data Services Group http://dataservices.gmu.edu [email protected] http://dataservices.gmu.edu/workshop/r 1. Create a folder with your name on the S: Drive 2. Copy titanic.csv from R Workshop Files to that folder History R ≈ S ≈ S-Plus Open Source, Free www.r-project.org Comprehensive R Archive Network Download R from: cran.rstudio.com RStudio: www.rstudio.com R Console Console See… > prompt for new command + waiting for rest of command R "guesses" whether you are done considering () and symbols Type… ↑[Up] to get previous command Type in everything in font: Courier New 3+2 3- 2 Objects Objects nine <- 9 Historical Conventions nine Use <- to assign values Use . to separate names three <- nine / 3 three Current Capabilities my.school <- "gmu" = is okay now in most cases is okay now in most cases my.school _ RStudio: Press Alt - (minus) to insert "assignment operator" Global Environment Script Files Vectors & Lists numbers <- c(101,102,103,104,105) the same numbers <- 101:105 numbers <- c(101:104,105) numbers[ 2 ] numbers[ c(2,4,5)] Vector Variable numbers[-c(2,4,5)] numbers[ numbers > 102 ] RStudio: Press Ctrl-Enter to run the current line or press the button: Files & Functions Files Pane 2. Choose the "S" Drive 1. Browse Drives 3. Choose your folder Working Directory Functions read.table( datafile, header=TRUE, sep = ",") Function Positional Named Named Argument Argument Argument Reading Files Thus, these would be identical: titanic <- read.table( datafile, header=TRUE, -

ML Cheatsheet Documentation
ML Cheatsheet Documentation Team Sep 02, 2021 Basics 1 Linear Regression 3 2 Gradient Descent 21 3 Logistic Regression 25 4 Glossary 39 5 Calculus 45 6 Linear Algebra 57 7 Probability 67 8 Statistics 69 9 Notation 71 10 Concepts 75 11 Forwardpropagation 81 12 Backpropagation 91 13 Activation Functions 97 14 Layers 105 15 Loss Functions 117 16 Optimizers 121 17 Regularization 127 18 Architectures 137 19 Classification Algorithms 151 20 Clustering Algorithms 157 i 21 Regression Algorithms 159 22 Reinforcement Learning 161 23 Datasets 165 24 Libraries 181 25 Papers 211 26 Other Content 217 27 Contribute 223 ii ML Cheatsheet Documentation Brief visual explanations of machine learning concepts with diagrams, code examples and links to resources for learning more. Warning: This document is under early stage development. If you find errors, please raise an issue or contribute a better definition! Basics 1 ML Cheatsheet Documentation 2 Basics CHAPTER 1 Linear Regression • Introduction • Simple regression – Making predictions – Cost function – Gradient descent – Training – Model evaluation – Summary • Multivariable regression – Growing complexity – Normalization – Making predictions – Initialize weights – Cost function – Gradient descent – Simplifying with matrices – Bias term – Model evaluation 3 ML Cheatsheet Documentation 1.1 Introduction Linear Regression is a supervised machine learning algorithm where the predicted output is continuous and has a constant slope. It’s used to predict values within a continuous range, (e.g. sales, price) rather than trying to classify them into categories (e.g. cat, dog). There are two main types: Simple regression Simple linear regression uses traditional slope-intercept form, where m and b are the variables our algorithm will try to “learn” to produce the most accurate predictions. -
1.2 Le Zhang, Microsoft
Objective • “Taking recommendation technology to the masses” • Helping researchers and developers to quickly select, prototype, demonstrate, and productionize a recommender system • Accelerating enterprise-grade development and deployment of a recommender system into production • Key takeaways of the talk • Systematic overview of the recommendation technology from a pragmatic perspective • Best practices (with example codes) in developing recommender systems • State-of-the-art academic research in recommendation algorithms Outline • Recommendation system in modern business (10min) • Recommendation algorithms and implementations (20min) • End to end example of building a scalable recommender (10min) • Q & A (5min) Recommendation system in modern business “35% of what consumers purchase on Amazon and 75% of what they watch on Netflix come from recommendations algorithms” McKinsey & Co Challenges Limited resource Fragmented solutions Fast-growing area New algorithms sprout There is limited reference every day – not many Packages/tools/modules off- and guidance to build a people have such the-shelf are very recommender system on expertise to implement fragmented, not scalable, scale to support and deploy a and not well compatible with enterprise-grade recommender by using each other scenarios the state-of-the-arts algorithms Microsoft/Recommenders • Microsoft/Recommenders • Collaborative development efforts of Microsoft Cloud & AI data scientists, Microsoft Research researchers, academia researchers, etc. • Github url: https://github.com/Microsoft/Recommenders • Contents • Utilities: modular functions for model creation, data manipulation, evaluation, etc. • Algorithms: SVD, SAR, ALS, NCF, Wide&Deep, xDeepFM, DKN, etc. • Notebooks: HOW-TO examples for end to end recommender building. • Highlights • 3700+ stars on GitHub • Featured in YC Hacker News, O’Reily Data Newsletter, GitHub weekly trending list, etc.