Exploring the Long Tail
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Dual Transfer Learning Framework for Improved Long-Tail Item Recommendation
A Model of Two Tales: Dual Transfer Learning Framework for Improved Long-tail Item Recommendation Yin Zhang*, Derek Zhiyuan Cheng, Tiansheng Yao, Xinyang Yi, Lichan Hong, Ed H. Chi [email protected],{zcheng,tyao,xinyang,lichan,edchi}@google.com Google, Inc, USA Texas A&M University, USA ABSTRACT Highly skewed long-tail item distribution is very common in recom- mendation systems. It significantly hurts model performance on tail items. To improve tail-item recommendation, we conduct research to transfer knowledge from head items to tail items, leveraging the rich user feedback in head items and the semantic connec- tions between head and tail items. Specifically, we propose a novel dual transfer learning framework that jointly learns the knowledge transfer from both model-level and item-level: 1. The model-level knowledge transfer builds a generic meta-mapping of model param- eters from few-shot to many-shot model. It captures the implicit data augmentation on the model-level to improve the represen- tation learning of tail items. 2. The item-level transfer connects head and tail items through item-level features, to ensure a smooth transfer of meta-mapping from head items to tail items. The two types of transfers are incorporated to ensure the learned knowledge from head items can be well applied for tail item representation learning in the long-tail distribution settings. Through extensive experiments on two benchmark datasets, results show that our pro- posed dual transfer learning framework significantly outperforms other state-of-the-art methods for tail item recommendation in hit ratio and NDCG. It is also very encouraging that our framework further improves head items and overall performance on top of the gains on tail items. -

Branch and Bramble-Youtube Guide-Download
YOUTUBE SEO A GUIDE Why YouTube SEO? Dos and Don’ts Overall Recommended Steps Keyword Tools & Processes THE GIST Best Prac4ces: Before Uploading Best Prac4ces: Uploading Best Prac4ces: AIer Publica4on YouTube Stories Appendix WHY YOUTUBE SEO? Op4mizing around YouTube SEO is essen4al to the success of a video and is slightly different than tradi4onal SEO. Unlike web pages or digital copy, videos cannot be ”read” by search engines’ algorithms. This significantly reduces discoverability if certain steps are not taken when crea4ng, producing, and uploading project to the plaSorm. YouTube is the 2nd largest YouTube is improving video search engine a4er Google. discovery by offering capon uploading. Videos are not “read” by Titles, descripons, keywords, search engines’ algorithms. hashtags, and metatags are several elements that help increase a video’s searchability. DO THIS: • Include long tail keywords that are more than 3 words long. • Focus on choosing 5-7 keywords. YOUTUBE KEYWORDS • Determine why someone would watch the video. Today’s YouTube SEO focuses on user intent, par4cularly when it comes to language. Since algorithms know language just as well, if not beWer, than we do, choosing keywords based on why individuals are looking for a par4cular video is DON’T DO THIS: paramount. • Do not keyword stuff — write as many There are two different methods for finding keywords and keywords as possible. they should be tailored based on where you’re at in the video process. • Use keywords that are unrelated to the video. • Use the same keyword finding process for new videos vs. already published videos. RECOMMENDED ACTIONS Find 5-7 relevant video keywords based on 1 7 Upload cap4ons for every video. -

Making History Useful: the Long Tail, the Search Economy and the U.S. Latino & Latina World War II Oral History Project Web Site
Making History Useful: The Long Tail, the Search Economy and the U.S. Latino & Latina World War II Oral History Project Web Site BY Dr. J. Richard Stevens Dr. Maggie Rivas-Rodriguez Assistant Professor Associate Professor Division of Journalism School of Journalism Southern Methodist University The University of Texas at Austin P.O. Box 750113 1 University Station A1000 Dallas, TX 75275 Austin, Texas, 78712 214-768-1915 512-471-0405 [email protected] [email protected] Abstract This article presents two cases involving personally relevant searches that led users to the U.S. Latino & Latina World War II Oral History Project Web site. Using the long tail and the search economy paradigms (core components of current Web 2.0 development), the authors argue that the relevant searches were only possible because of the open archives of the site, and that the practice of denying open and free access to content by online news media affects their relevance to Web users. Key Words: Web 2.0, long tail, search economy, archives Making History Useful 1 Introduction Though online journalism remains in its infancy (Foust, 2005), development of its forms and structure are beginning to emerge. All media forms must adapt to their environment or die (Fidler, 1995), and how online journalism adapts to the ways in which Web users create relevancy is a critical issue facing news organizations. Aizu (1997, p. 473) argued that the Internet provides a global arena for “minor culture” that “the mass media and or the mass economy cannot pay attention to.” These observations are consistent with the niche element of the long tail paradigm. -

The Long Tail: Why the Future of Business Is Selling Less of More
J PROD INNOV MANAG 2007;24;274281 © 2007 Product Development & Management Association increases, the impact of the long tail phenomenon increases. Chris Anderson states “Many of our assumptions about popular taste are actually artifacts of poor supplyanddemand matching – a market response to inefficient distribution” (p. 16). For example, fifty years ago a few television network executives controlled the few programs available for viewing on a given evening. Decades ago, viewers were more likely to accept whatever the networks offered. Today, viewing behavior is more diverse and there is more efficient distribution. There are more many The Long Tail: Why the Future of Business more television networks (for example, a science Is Selling Less of More fiction network), more televisions per capita, and Chris Anderson. New York: Hyperion, 2006. 230 + compelling alternatives, so it is unlikely that a given xii pages. US$24.95 network program will be seen by more than 30 percent of potential viewers. Now, it is more likely The Long Tail is an extension of an influential article that consumers will find and view their personal published in Wired Magazine (Anderson, 2004). As a favorites from a choice of hundreds of channels and business concept, the long tail phenomenon is then interact with an online community that shares attractive because “products that are in low demand similar preferences. or have low sales volume can collectively make up a Chapter 4 explores specific supply and demand market share that rivals or exceeds the relatively few conditions necessary for narrowly targeted goods and current bestsellers and blockbusters, if the store or services to be economically attractive. -

How-Relevant-Is-The-Long-Tail.Pdf
How Relevant is the Long Tail? A Relevance Assessment Study on Million Short Philipp Schaer1, Philipp Mayr2, Sebastian S¨unkler3, and Dirk Lewandowski3 1 Cologne University of Applied Sciences, Cologne, Germany 2 GESIS – Leibniz Institute for the Social Sciences, Cologne, Germany 3 Hamburg University of Applied Sciences, Hamburg, Germany Abstract. Users of web search engines are known to mostly focus on the top ranked results of the search engine result page. While many studies support this well known information seeking pattern only few studies concentrate on the question what users are missing by neglecting lower ranked results. To learn more about the relevance distributions in the so-called long tail we conducted a relevance assessment study with the Million Short long-tail web search engine. While we see a clear difference in the content between the head and the tail of the search engine result list we see no statistical significant differences in the binary relevance judgments and weak significant differences when using graded relevance. The tail contains different but still valuable results. We argue that the long tail can be a rich source for the diversification of web search engine result lists but it needs more evaluation to clearly describe the differences. 1 Introduction The ranking algorithms of web search engines try to predict the relevance of web pages to a given search query by a user. By incorporating hundreds of “signals” modern search engines do a great job in bringing a usable order to the vast amounts of web data available. Users are used to rely mostly on the first few results presented in search engine result pages (SERP). -

Music Recommendation and Discovery in the Long Tail
MUSIC RECOMMENDATION AND DISCOVERY IN THE LONG TAIL Oscar` Celma Herrada 2008 c Copyright by Oscar` Celma Herrada 2008 All Rights Reserved ii To Alex and Claudia who bring the whole endeavour into perspective. iii iv Acknowledgements I would like to thank my supervisor, Dr. Xavier Serra, for giving me the opportunity to work on this very fascinating topic at the Music Technology Group (MTG). Also, I want to thank Perfecto Herrera for providing support, countless suggestions, reading all my writings, giving ideas, and devoting much time to me during this long journey. This thesis would not exist if it weren’t for the the help and assistance of many people. At the risk of unfair omission, I want to express my gratitude to them. I would like to thank all the colleagues from MTG that were —directly or indirectly— involved in some bits of this work. Special mention goes to Mohamed Sordo, Koppi, Pedro Cano, Mart´ın Blech, Emilia G´omez, Dmitry Bogdanov, Owen Meyers, Jens Grivolla, Cyril Laurier, Nicolas Wack, Xavier Oliver, Vegar Sandvold, Jos´ePedro Garc´ıa, Nicolas Falquet, David Garc´ıa, Miquel Ram´ırez, and Otto W¨ust. Also, I thank the MTG/IUA Administration Staff (Cristina Garrido, Joana Clotet and Salvador Gurrera), and the sysadmins (Guillem Serrate, Jordi Funollet, Maarten de Boer, Ram´on Loureiro, and Carlos Atance). They provided help, hints and patience when I played around with the machines. During my six months stage at the Center for Computing Research of the National Poly- technic Institute (Mexico City) in 2007, I met a lot of interesting people ranging different disciplines. -

Learning to Model the Tail
Learning to Model the Tail Yu-Xiong Wang Deva Ramanan Martial Hebert Robotics Institute, Carnegie Mellon University {yuxiongw,dramanan,hebert}@cs.cmu.edu Abstract We describe an approach to learning from long-tailed, imbalanced datasets that are prevalent in real-world settings. Here, the challenge is to learn accurate “few- shot” models for classes in the tail of the class distribution, for which little data is available. We cast this problem as transfer learning, where knowledge from the data-rich classes in the head of the distribution is transferred to the data-poor classes in the tail. Our key insights are as follows. First, we propose to transfer meta-knowledge about learning-to-learn from the head classes. This knowledge is encoded with a meta-network that operates on the space of model parameters, that is trained to predict many-shot model parameters from few-shot model parameters. Second, we transfer this meta-knowledge in a progressive manner, from classes in the head to the “body”, and from the “body” to the tail. That is, we transfer knowledge in a gradual fashion, regularizing meta-networks for few-shot regression with those trained with more training data. This allows our final network to capture a notion of model dynamics, that predicts how model parameters are likely to change as more training data is gradually added. We demonstrate results on image classification datasets (SUN, Places, and ImageNet) tuned for the long-tailed setting, that significantly outperform common heuristics, such as data resampling or reweighting. 1 Motivation Deep convolutional neural networks (CNNs) have revolutionized the landscape of visual recognition, through the ability to learn “big models” with hundreds of millions of parameters [1, 2, 3, 4]. -

The Long Tail / Chris Anderson
THE LONG TAIL Why the Future of Business Is Selling Less of More Enter CHRIS ANDERSON To Anne CONTENTS Acknowledgments v Introduction 1 1. The Long Tail 15 2. The Rise and Fall of the Hit 27 3. A Short History of the Long Tail 41 4. The Three Forces of the Long Tail 52 5. The New Producers 58 6. The New Markets 85 7. The New Tastemakers 98 8. Long Tail Economics 125 9. The Short Head 147 iv | CONTENTS 10. The Paradise of Choice 168 11. Niche Culture 177 12. The Infinite Screen 192 13. Beyond Entertainment 201 14. Long Tail Rules 217 15. The Long Tail of Marketing 225 Coda: Tomorrow’s Tail 247 Epilogue 249 Notes on Sources and Further Reading 255 Index 259 About the Author Praise Credits Cover Copyright ACKNOWLEDGMENTS This book has benefited from the help and collaboration of literally thousands of people, thanks to the relatively open process of having it start as a widely read article and continue in public as a blog of work in progress. The result is that there are many people to thank, both here and in the chapter notes at the end of the book. First, the person other than me who worked the hardest, my wife, Anne. No project like this could be done without a strong partner. Anne was all that and more. Her constant support and understanding made this possible, and the price was significant, from all the Sundays taking care of the kids while I worked at Starbucks to the lost evenings, absent vacations, nights out not taken, and other costs of an all-consuming project. -

Lurking? Cyclopaths? a Quantitative Lifecycle Analysis of User Behavior in a Geowiki
Lurking? Cyclopaths? A Quantitative Lifecycle Analysis of User Behavior in a Geowiki Katherine Panciera1, Reid Priedhorsky1, Thomas Erickson2, Loren Terveen1 1GroupLens Research 2IBM T.J. Watson Research Center Department of Computer Science and PO Box 704 Engineering Yorktown Heights, NY 10598 USA University of Minnesota {snowfall}@acm.org Minneapolis, Minnesota, USA {katpa,reid,terveen}@cs.umn.edu ABSTRACT Online communities produce rich behavioral datasets, e.g., Usenet news conversations, Wikipedia edits, and Facebook friend networks. Analysis of such datasets yields important insights (like the “long tail” of user participation) and sug- gests novel design interventions (like targeting users with personalized opportunities and work requests). However, certain key user data typically are unavailable, specifically viewing, pre-registration, and non-logged-in activity. The absence of data makes some questions hard to answer; ac- cess to it can strengthen, extend, or cast doubt on previous results. We report on analysis of user behavior in Cyclopath, a geographic wiki and route-finder for bicyclists. With ac- cess to viewing and non-logged-in activity data, we were able to: (a) replicate and extend prior work on user lifecycles Figure 1. Screenshot of the Cyclopath application. in Wikipedia, (b) bring to light some pre-registration activ- ity, thus testing for the presence of “educational lurking,” and (c) demonstrate the locality of geographic activity and how editing and viewing are geographically correlated. INTRODUCTION The recent explosionof open content systems like Wikipedia, Flickr, and Stack Overflow has led to a new industry of on- Author Keywords line knowledge production and organization, carried out by Wiki, geowiki, open content, geographic volunteer work, distributed volunteers. -

Tailgate: Handling Long-Tail Content with a Little Help from Friends
WWW 2012 – Session: Web Performance April 16–20, 2012, Lyon, France TailGate: Handling Long-Tail Content with a Little Help from Friends Stefano Traverso Kévin Huguenin Ionut Trestian Politecnico di Torino EPFL Northwestern University [email protected] kevin.huguenin@epfl.ch [email protected] Vijay Erramilli Nikolaos Laoutaris Konstantina Papagiannaki Telefonica Research Telefonica Research Telefonica Research [email protected] [email protected] [email protected] ABSTRACT meeting bandwidth and/or QoE constraints for such con- Distributing long-tail content is an inherently difficult task tent. due to the low amortization of bandwidth transfer costs as The problem of delivering such content is further exac- such content has limited number of views. Two recent trends erbated by two recent trends: the increasing popularity of are making this problem harder. First, the increasing pop- user-generated content (UGC), and the rise of online so- ularity of user-generated content (UGC) and online social cial networks (OSNs) as a distribution mechanism that has networks (OSNs) create and reinforce such popularity dis- helped reinforce the long-tailed nature of content. For in- tributions. Second, the recent trend of geo-replicating con- stance, Facebook hosts more images than all other popular tent across multiple PoPs spread around the world, done for photo hosting websites such as Flickr [35], and they now improving quality of experience (QoE) for users and for re- host and serve a large proportion of videos as well [9]. Con- dundancy reasons, can lead to unnecessary bandwidth costs. tent created and shared on social networks is predominantly We build TailGate, a system that exploits social relation- long-tailed with a limited interest group, specially if one ships, regularities in read access patterns, and time-zone dif- considers notions like Dunbar’s number [7]. -

ISOM 1090 Social Media: Collective Intelligence & Creativity
ISOM1090 Social Media: Collective Intelligence & Creativity Winter 2020 Instructor: Dr. Jack Teh ([email protected]) Office: Room 5046 (LSK Business Building) Phone no: 2358-7647 Course Description The ubiquitous presence of social media has reshaped the web from a medium of deliver information to a platform for participation. Web technology is now connecting a diversity of people and idea and encouraging cooperation and collaboration. This course will examine the impact of the open and peer-to-peer collaborations that are the underpinning Web 2.0. In addition to learning Web 2.0 enabling technologies, students will also understand the social and philosophical implications of this phenomenon. This class is open to undergraduates in all disciplines with either technical or non-technical backgrounds. Course work will include lectures, class discussion, homework, lab, and project presentation. Learning Outcomes By the end of this course, you will be able to: Articulate the origin and basic characteristics of Web 2.0 applications Explain long tail and network effect Understand principles of peer production and the Wikinomics model enabled by social media technologies Define crowdsourcing & collective intelligence Explain that social media are both a technology and a social phenomenon. Analyze the issues of open source software This course will provide students with opportunity to develop ability to: Apply a variety of uses of social media tools Participate in social bookmarking, tagging, blogging, podcasting and using wikis Communicate and participate in a written discussion Deliver a professional quality presentation Contribute to the successful and timely completion of a group project Intended Learning Outcomes Approach The learning activities in the course are designed to emphasize the participatory and collaborative nature of Web 2.0. -
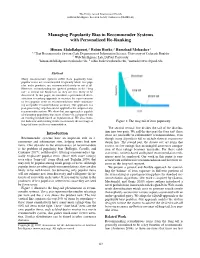
Managing Popularity Bias in Recommender Systems with Personalized Re-Ranking
The Thirty-Second International Florida Artificial Intelligence Research Society Conference (FLAIRS-32) Managing Popularity Bias in Recommender Systems with Personalized Re-Ranking Himan Abdollahpouri,2 Robin Burke,2 Bamshad Mobasher3 1;2That Recommender Systems Lab, Department of Information Science, University of Colorado Boulder 3 Web Intelligence Lab, DePaul University [email protected], 2 [email protected], [email protected] Abstract Many recommender systems suffer from popularity bias: popular items are recommended frequently while less pop- ular, niche products, are recommended rarely or not at all. However, recommending the ignored products in the “long tail” is critical for businesses as they are less likely to be discovered. In this paper, we introduce a personalized diver- sification re-ranking approach to increase the representation of less popular items in recommendations while maintain- ing acceptable recommendation accuracy. Our approach is a post-processing step that can be applied to the output of any recommender system. We show that our approach is capable of managing popularity bias more effectively, compared with an existing method based on regularization. We also exam- ine both new and existing metrics to measure the coverage of Figure 1: The long-tail of item popularity. long-tail items in the recommendation. The second vertical line divides the tail of the distribu- tion into two parts. We call the first part the long tail: these Introduction items are amenable to collaborative recommendation, even Recommender systems have an important role in e- though many algorithms fail to include them in recommen- commerce and information sites, helping users find new dation lists.