Scoutfs Whitepaper
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Technical Standard
Technical Standard X/Open Curses, Issue 7 The Open Group ©November 2009, The Open Group All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without the prior permission of the copyright owners. Technical Standard X/Open Curses, Issue 7 ISBN: 1-931624-83-6 Document Number: C094 Published in the U.K. by The Open Group, November 2009. This standardhas been prepared by The Open Group Base Working Group. Feedback relating to the material contained within this standardmay be submitted by using the web site at http://austingroupbugs.net with the Project field set to "Xcurses Issue 7". ii Technical Standard 2009 Contents Chapter 1 Introduction........................................................................................... 1 1.1 This Document ........................................................................................ 1 1.1.1 Relationship to Previous Issues ......................................................... 1 1.1.2 Features Introduced in Issue 7 ........................................................... 2 1.1.3 Features Withdrawn in Issue 7........................................................... 2 1.1.4 Features Introduced in Issue 4 ........................................................... 2 1.2 Conformance............................................................................................ 3 1.2.1 Base Curses Conformance ................................................................. -

Synchronizing Threads with POSIX Semaphores
3/17/2016 POSIX Semaphores Synchronizing Threads with POSIX Semaphores 1. Why semaphores? 2. Posix semaphores are easy to use sem_init sem_wait sem_post sem_getvalue sem_destroy 3. Activities 1 2 Now it is time to take a look at some code that does something a little unexpected. The program badcnt.c creates two new threads, both of which increment a global variable called cnt exactly NITER, with NITER = 1,000,000. But the program produces unexpected results. Activity 1. Create a directory called posixsem in your class Unix directory. Download in this directory the code badcnt.c and compile it using gcc badcnt.c -o badcnt -lpthread Run the executable badcnt and observe the ouput. Try it on both tanner and felix. Quite unexpected! Since cnt starts at 0, and both threads increment it NITER times, we should see cnt equal to 2*NITER at the end of the program. What happens? Threads can greatly simplify writing elegant and efficient programs. However, there are problems when multiple threads share a common address space, like the variable cnt in our earlier example. To understand what might happen, let us analyze this simple piece of code: THREAD 1 THREAD 2 a = data; b = data; a++; b--; data = a; data = b; Now if this code is executed serially (for instance, THREAD 1 first and then THREAD 2), there are no problems. However threads execute in an arbitrary order, so consider the following situation: Thread 1 Thread 2 data a = data; --- 0 a = a+1; --- 0 --- b = data; // 0 0 --- b = b + 1; 0 data = a; // 1 --- 1 --- data = b; // 1 1 So data could end up +1, 0, -1, and there is NO WAY to know which value! It is completely non- deterministic! http://www.csc.villanova.edu/~mdamian/threads/posixsem.html 1/4 3/17/2016 POSIX Semaphores The solution to this is to provide functions that will block a thread if another thread is accessing data that it is using. -

Openextensions POSIX Conformance Document
z/VM Version 7 Release 1 OpenExtensions POSIX Conformance Document IBM GC24-6298-00 Note: Before you use this information and the product it supports, read the information in “Notices” on page 73. This edition applies to version 7, release 1, modification 0 of IBM z/VM (product number 5741-A09) and to all subsequent releases and modifications until otherwise indicated in new editions. Last updated: 2018-09-12 © Copyright International Business Machines Corporation 1993, 2018. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents List of Tables........................................................................................................ ix About This Document............................................................................................xi Intended Audience......................................................................................................................................xi Conventions Used in This Document.......................................................................................................... xi Where to Find More Information.................................................................................................................xi Links to Other Documents and Websites.............................................................................................. xi How to Send Your Comments to IBM....................................................................xiii Summary of Changes for z/VM -
![So You Think You Know C? [Pdf]](https://docslib.b-cdn.net/cover/6575/so-you-think-you-know-c-pdf-666575.webp)
So You Think You Know C? [Pdf]
So You Think You Know C? And Ten More Short Essays on Programming Languages by Oleksandr Kaleniuk Published in 2020 This is being published under the Creative Commons Zero license. I have dedicated this work to the public domain by waiving all of my rights to the work worldwide under copyright law, including all related and neighboring rights, to the extent allowed by law. You can copy, modify, distribute and perform the work, even for commercial purposes, all without asking permission. Table of Contents Introduction......................................................................................................... 4 So you think you know C?..................................................................................6 APL deserves its renaissance too.......................................................................13 Going beyond the idiomatic Python..................................................................30 Why Erlang is the only true computer language................................................39 The invisible Prolog in C++..............................................................................43 One reason you probably shouldn’t bet your whole career on JavaScript.........54 You don't have to learn assembly to read disassembly......................................57 Fortran is still a thing........................................................................................64 Learn you a Lisp in 0 minutes...........................................................................68 Blood, sweat, -

Software Engineering Standards Introduction
6/21/2008 Software Engineering Standards Introduction 1028 9126 730 12207 9000 CMM 15288 CMMI J-016 1679 Outline 1. Definitions 2. Sources of Standards 3. Why Use Standards ? 4. ISO and Software Engineering Standards 5. IEEE Software Engineering Collection Sources: IEEE Standards, Software Engineering, Volume Three: Product Standards, Introduction to the1999 Edition, pages i to xxiii. Horch, J., ‘Practical Guide to Software Quality management’, Artech House, 1996, chap 2. Wells, J., ‘An Introduction to IEEE/EIA 12207’, US DoD, SEPO, 1999. Moore, J., ‘Selecting Software Engineering Standards’, QAI Conference, 1998. Moore, J., ‘The Road Map to Software Engineering: A Standards-Based Guide’, Wiley-IEEE Computer Society Press, 2006. Moore, J.,’An Integrated Collection of Software Engineering Standards’, IEEE Software, Nov 1999. Gray, L., ‘Guidebook to IEEE/EIA 12207 Standard for Information Technology, Software Life Cycle Processes’, Abelia Corporation, Fairfax, Virginia, 2000. Coallier, F.; International Standardization in Software and Systems Engineering, Crosstalk, February 2003, pp. 18-22. 6/21/2008 2 1 6/21/2008 Exemple d’un système complexe Système de transport aérien Système de transport Système de Transport Aérien terrestre Système de Système de gestion du trafic réservation aérien Système Système aéroportuaire de distribution du kérosène SystèmeSystème avionique avion Système de Système de gestion de la Structure vie à bord SystèmeSystème de de équipage propulsionpropulsion Système SystèmeNavigation de de SystèmeVisualisation Système de navigationsystem de visualisation contrôle de vol SystèmeSystème de de réception réception Système de GPSGPS transport terrestremaritime 6/21/2008 3 Toward a Software Engineering Profession • What does it take ? 1. Body of Knowledge (e.g. SWEBOK) 2. -

JTC1 and SC22 - Terminology
JTC1 AD Hoc Terminology, August 2005 1 JTC1 and SC22 - Terminology Background Following my offer to collect together the definitions from SC22 standards, SC22 accepted my offer and appointed me as its terminology representative (I was later also asked to represent UK and BSI) on the JTC1 ad hoc group on terminology. These notes summarise the results of collecting the SC22 definitions, and my impressions of the JTC1 ad hoc group. Roger Scowen August 2005 A collection of definitions from SC22 standards SC22 asked me to prepare a collected terminology for SC22 containing the definitions from standards for which SC22 is responsible, and asked the project editors to send me the definitions in text form. Many, but not all, project editors did so. However there are sufficient for SC22 to judge whether to complete the list or abandon it as an interesting but unprofitable exercise. Adding definitions to the database The project editor of a standard typically sends the definitions from the standard as a Word file, but it may be plain text or in Latex or nroff format. These definitions are transformed into a uniform format by a series of global ‘find & replace’ operations to produce a Word file where each definition is represented as a row of a table with three columns: the term, its definition, and any notes and/or examples. It is often easier to check this has been accomplished by copying and pasting successive attempts into Excel than examining the Word file itself. Sometimes there are special cases such as exotic characters (for example Greek or mathematical characters), special fonts, illustrations, diagrams, or tables. -

File Systems: Semantics & Structure What Is a File
5/15/2017 File Systems: Semantics & Structure What is a File 11A. File Semantics • a file is a named collection of information 11B. Namespace Semantics • primary roles of file system: 11C. File Representation – to store and retrieve data – to manage the media/space where data is stored 11D. Free Space Representation • typical operations: 11E. Namespace Representation – where is the first block of this file 11L. Disk Partitioning – where is the next block of this file 11F. File System Integration – where is block 35 of this file – allocate a new block to the end of this file – free all blocks associated with this file File Systems Semantics and Structure 1 File Systems Semantics and Structure 2 Data and Metadata Sequential Byte Stream Access • File systems deal with two kinds of information int infd = open(“abc”, O_RDONLY); int outfd = open(“xyz”, O_WRONLY+O_CREATE, 0666); • Data – the contents of the file if (infd >= 0 && outfd >= 0) { – e.g. instructions of the program, words in the letter int count = read(infd, buf, sizeof buf); Metadata – Information about the file • while( count > 0 ) { e.g. how many bytes are there, when was it created – write(outfd, buf, count); sometimes called attributes – count = read(infd, inbuf, BUFSIZE); • both must be persisted and protected } – stored and connected by the file system close(infd); close(outfd); } File Systems Semantics and Structure 3 File Systems Semantics and Structure 4 Random Access Consistency Model void *readSection(int fd, struct hdr *index, int section) { struct hdr *head = &hdr[section]; -

Comparative Analysis of Distributed and Parallel File Systems' Internal Techniques
Comparative Analysis of Distributed and Parallel File Systems’ Internal Techniques Viacheslav Dubeyko Content 1 TERMINOLOGY AND ABBREVIATIONS ................................................................................ 4 2 INTRODUCTION......................................................................................................................... 5 3 COMPARATIVE ANALYSIS METHODOLOGY ....................................................................... 5 4 FILE SYSTEM FEATURES CLASSIFICATION ........................................................................ 5 4.1 Distributed File Systems ............................................................................................................................ 6 4.1.1 HDFS ..................................................................................................................................................... 6 4.1.2 GFS (Google File System) ....................................................................................................................... 7 4.1.3 InterMezzo ............................................................................................................................................ 9 4.1.4 CodA .................................................................................................................................................... 10 4.1.5 Ceph.................................................................................................................................................... 12 4.1.6 DDFS .................................................................................................................................................. -

OSE/RM Model Specification on a Basis the Reference Models of the Internet of Things
OSE/RM model specification on a basis the reference models of the Internet of things A.V. Boichenko PhD, Plekhanov Russian Academy of Economics, tel +7 916 624 267, [email protected],[email protected] V.A. Kazakov PhD, Plekhanov Russian Academy of Economics, tel. 8-903-148-10-44 [email protected] O.V. Lukinova, Doctor of Engineering, Trapeznikov Institute of control sciences of Russian Academy of Sciences, tel. 916-707-13-90 [email protected] Abstract. In work the specification in projects the Internet of Things standard- ized reference model of the environment of the open systems OSE/RM (Open System Environment/Reference Model) on a basis the reference models of the Internet of things is considered. Also use of the OSE/RM model in integration projects of the Internet of things on the basis of the European interoperability framework EIF (European Interoperability Framework) is considered. Keywords: Internet of things, reference models of the Internet of things, refer- ence model of the environment of the open OSE/RM systems, integration Inter- net of things, European interoperability framework of EIF. Within the last several decades in world practice of system and program engineer- ing at design of information systems the referensy model of the environment of open systems was widely used (in the Russian practice, unfortunately, significantly more rare) OSE/RM (Open System Environment / Reference Model). This model describes basic functionality of any information system. The main maintenance of this model is described in the document ISO/IEC TR 14252:1996 Information technology – Guide to the POSIX Open System Environment (OSE) [1]. -

The POSIX Family of Standards
★ ★ ★ SUPPORTING ARTICLE ★ The POSIX Family of Standards Stephen R. Walli OSIX is a family of IEEE standards that SRW SOFTWARE, KITCHENER, ONT. supports portable programming. There are actually more than 20 standards and ■ draft documents under the POSIX umbrel- The IEEE POSIX family of standards la, at different stages in the standards de- has been developing since 1988, when velopment process. In this article each the original base system interface stan- piece of work will be referred to as “POSIX.n,” with “n” denoting the docu- dard was ratified. Having been at the ment or its working group, and enough core of a number of vendor-based con- other context will be given to identify the work being discussed. If the document is sortia specifications, largely due to U.S. a completed formal standard, its official government support in purchasing, it is number will be cited. Official numbers widely implemented. P look like “IEEE Std 1003.n-yyyy,” where 1003 is the IEEE POSIX project, “n” de- Despite its history, POSIX still suffers notes the document, and “yyyy” is the from a misunderstood scope, bad press, and an year the standard was completed or last amended. The term “POSIX” is really quite vague, which apparent lack of use. However, when POSIX is probably contributes to the confusion surrounding viewed as a programmer’s specification and simple the standards. To some it’s the POSIX.1 system inter- explanations for using specific POSIX standards are face standard; to others it’s the POSIX.1 standard plus the POSIX.2 shell and utilities standard. -

Code Generation for the MPEG Reconfigurable Video Coding
Code generation for the MPEG Reconfigurable Video Coding framework: From CAL actions to C functions Matthieu Wipliez, Ghislain Roquier, Mickael Raulet, Jean François Nezan, Olivier Déforges To cite this version: Matthieu Wipliez, Ghislain Roquier, Mickael Raulet, Jean François Nezan, Olivier Déforges. Code generation for the MPEG Reconfigurable Video Coding framework: From CAL actions to Cfunc- tions. Multimedia and Expo, (ICME) 2008 IEEE International Conference on, Jun 2008, Hannover, Germany. pp.1049 - 1052, 10.1109/ICME.2008.4607618. hal-00336487 HAL Id: hal-00336487 https://hal.archives-ouvertes.fr/hal-00336487 Submitted on 4 Nov 2008 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. CODE GENERATION FOR THE MPEG RECONFIGURABLE VIDEO CODING FRAMEWORK: FROM CAL ACTIONS TO C FUNCTIONS Matthieu Wipliez, Ghislain Roquier, Mickael¨ Raulet, Jean-Franc¸ois Nezan, Olivier Deforges´ IETR laboratory, UMR CNRS 6164, Image and Remote Sensing Group INSA de Rennes, 20 Avenue des Buttes de Coesmes,¨ 35043 RENNES Cedex, FRANCE Contacts: fmwipliez, groquier, mraulet, jnezan, [email protected] ABSTRACT algorithms, features that are necessary to be exploited for The MPEG Reconfigurable Video Coding (RVC) framework efficient implementations. In the meanwhile the growth of aims to provide a unified specification of all video technol- video coding technologies leads to solutions that are increas- ogy. -
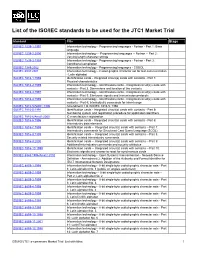
List of the ISO/IEC Standards to Be Used for the JTC1 Market Trial
List of the ISO/IEC standards to be used for the JTC1 Market Trial Standard Title Stage ISO/IEC 1539-1:1997 Information technology - Programming languages - Fortran - Part 1: Base language ISO/IEC 1539-2:2000 Information technology -- Programming languages -- Fortran -- Part 2: Varying length character strings ISO/IEC 1539-3:1999 Information technology - Programming languages - Fortran - Part 3: Conditional compilation ISO/IEC 1989:2002 Information technology - Programming languages - COBOL ISO/IEC 6937:2001 Information technology - Coded graphic character set for text communication - Latin alphabet ISO/IEC 7816-1:1998 Identification cards - Integrated circuit(s) cards with contacts - Part 1: Physical characteristics ISO/IEC 7816-2:1999 Information technology - Identification cards - Integrated circuit(s) cards with contacts - Part 2: Dimensions and location of the contacts ISO/IEC 7816-3:1997 Information technology - Identification cards - Integrated circuit(s) cards with contacts - Part 3: Electronic signals and transmission protocols ISO/IEC 7816-4:1995 Information technology - Identification cards - Integrated circuit(s) cards with contacts - Part 4: Interindustry commands for interchange ISO/IEC 7816-5/AMD1:1996 Amendment 1 to ISO/IEC 7816-5: 1994 ISO/IEC 7816-5:1994 Identification cards - Integrated circuit(s) cards with contacts - Part 5: Numbering system and registration procedure for application identifiers ISO/IEC 7816-6/Amd1:2000 IC manufacturer registration ISO/IEC 7816-6:1996 Identification cards - Integrated circuit(s) cards