Role of Open Access, Open Standards and Open Sources in Libraries : a Study
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Comparison of Researcher's Reference Management Software
Journal of Economics and Behavioral Studies Vol. 6, No. 7, pp. 561-568, July 2014 (ISSN: 2220-6140) A Comparison of Researcher’s Reference Management Software: Refworks, Mendeley, and EndNote Sujit Kumar Basak Durban University of Technology, South Africa [email protected] Abstract: This paper aimed to present a comparison of researcher’s reference management software such as RefWorks, Mendeley, and EndNote. This aim was achieved by comparing three software. The main results of this paper were concluded by comparing three software based on the experiment. The novelty of this paper is the comparison of researcher’s reference management software and it has showed that Mendeley reference management software can import more data from the Google Scholar for researchers. This finding could help to know researchers to use the reference management software. Keywords: Reference management software, comparison and researchers 1. Introduction Reference management software maintains a database to references and creates bibliographies and the reference lists for the written works. It makes easy to read and to record the elements for the reference comprises such as the author’s name, year of publication, and the title of an article, etc. (Reiss & Reiss, 2002). Reference Management Software is usually used by researchers, technologists, scientists, and authors, etc. to keep their records and utilize the bibliographic citations; hence it is one of the most complicated aspects among researchers. Formatting references as a matter of fact depends on a variety of citation styles which have been made the citation manager very essential for researchers at all levels (Gilmour & Cobus-Kuo, 2011). Reference management software is popularly known as bibliographic software, citation management software or personal bibliographic file managers (Nashelsky & Earley, 1991). -
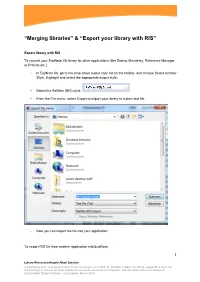
“Merging Libraries” & “Export Your Library with RIS”
“Merging libraries” & “Export your library with RIS” Export library with RIS To convert your EndNote X6 library for other applications (like Zotero, Mendeley, Reference Manager or ProCite etc.): - In EndNote X6, go to the drop-down output style list on the toolbar, and choose Select Another Style. Highlight and select the appropriate output style: - Select the RefMan (RIS) style. - From the File menu, select Export to export your library to a plain text file. - Now you can import the file into your application To import RIS file from another application into EndNote: 1 Library Wissenschaftspark Albert Einstein A joint library of the German Research Centre for Geosciences GFZ, the Potsdam Institute for Climate Impact Research, the Alfred Wegener Institute for Polar and Marine Research, Research Unit Potsdam, and the IASS Institute for Advanced Sustainability Studies Potsdam (Last update: March 2013) - Got to “File” and “Import” - Choose your file in RIS format - Use the RIS import option. - Set your preferences - Import the references 2 Library Wissenschaftspark Albert Einstein A joint library of the German Research Centre for Geosciences GFZ, the Potsdam Institute for Climate Impact Research, the Alfred Wegener Institute for Polar and Marine Research, Research Unit Potsdam, and the IASS Institute for Advanced Sustainability Studies Potsdam (Last update: March 2013) Merging libraries There are three ways to merge libraries: import one library into another, copy references from one library to another, or drag-and-drop. - (Optional) If you want to import only a subset of references from a library, first open that library and show only the references you wish to copy. -

Exportación a Otros Pgb
EXPORTACIÓN A OTROS PGB CÓMO EXPORTAR DE ZOTERO A ENDNOTE En Zotero una colección concreta -> botón derecho del ratón , exportar y guardar en formato RIS o Refer/BibIX En EndNote: File -> Import -> Reference Manager (RIS) o Refer/BibIX ENDNOTEWEB En Zotero guardar como .RIS En EndNoteweb importar con el filtro RefMan (RIS) PROCITE En Zotero guardar en formato RIS En Procite, Tools -> Import Text file -> Open Import file -> Nombre: Mi biblioteca.ris. Tipo ->All files REFERENCE MANAGER En Zotero guardar Mi biblioteca como .ris En Reference Manager- en File New Database u Open Database -> En File -> Import Text file->el que queremos “Mi biblioteca.ris”->Filter RIS REFWORK En Zotero guardar como .ris En RefWorks-> Importar-> Filtro RIS UTF-8 CÓMO EXPORTAR DE ENDNOTE A ZOTERO En EndNote -> File -> Export -> My EndNote Library -> en .txt. Output Style - > RefMan (RIS) En Zotero -> importar -> Tipo RIS ENDNOTEWEB En EndNote -> Tools-> Connect EndNote Web PROCITE En Procite Tools -> Convert file->elegir el archivo de EndNote y guardar con otro nombre REFERENCE MANAGER En EndNote File Export filtro refinan (RIS) export, como archivo .txt En Reference Manager, File Import Text file REFWORK De EndNote v.8 o superior exportación directa. Si falla en otras versiones ver Ayuda de RefWorks CÓMO EXPORTAR DE ENDNOTEWEB A ENDNOTE ZOTERO PROCITE REFERENCE MANAGER REFWORK Elegir exportar como RIS y seleccionar esta opción al importar a los progrmas CÓMO EXPORTAR DE PROCITE A ENDNOTE En Procite guardar cualquier archivo en Procite. En EndNote File -> Open library elegir el archivo de Procite-> File of type -> Procite ZOTERO En Procite, si no tenemos el filtro EndNote-RIS importarlo de www.procite.com . -

Convert Ris To
Convert ris to Continue This website uses its own and third-party cookies to develop statistical information, to personalize your experience, and to view user ads through viewing analysis, sharing it with our partners. Using Online-Convert, you agree to use cookies. RefWorks has a feature that allows you to download the EndNote library for versions 8 to 10 directly to RefWorks. For all other versions, export records from EndNote and import them to RefWorks (see instructions at the end of this section). Go to RefWorks and from the Links menu select Imports. Expand the From EndNote database section. Browse and select EndNote (.enl). Only the EndNote 8 version and the higher databases can be imported. There is a 25MB import limit the size of your EndNote library. Make sure the .enl file isn't open on your computer. Additionally, specify the folder you want to import your records into. Click Import at the bottom of the import window. Progress is measured for each imported handbook. RefWorks will notify you when the import is complete. Your entries should automatically appear in the Last Import folder. It is recommended that you import no more than 2,500 records (or 3MB files) at a time. In EndNote, under the Edit menu, choose weekend styles. From the release style list, select RefMan (RIS) Export. If you can't see this format, open Style Manager and check the RefMan (RIS) export format. Close the style manager and repeat the steps 1 and 2. Choose the links you want to export. In the Help menu, select Show Selected (or show everything if you want to export the entire database). -

Análisis Comparativo De Los Gestores Bibliográficos Sociales Zotero, Docear Y Mendeley: Características Y Prestaciones
Análisis comparativo de los gestores bibliográficos sociales Zotero, Docear y Mendeley: características y prestaciones. Comparative analysis of social bibliographic management software Zotero , Docear and Mendeley: fea- tures and benefits. Montserrat López Carreño Universidad de [email protected] Resumen Abstract Se realiza una aproximación al origen y evolu- A comparative analysis between the free biblio- ción de la gestión bibliográfica personal, esta- graphic reference management software. These bleciendo una cronología de la aparición de los bibliographic reference managers offer to the gestores bibliográficos más populares, resaltan- users the ability to retrieve, store, edit and dis- do sus características y evidenciando su utilidad seminate bibliographic information. An approach en el ámbito académico-científico. Para ello, hay is made to the origin and evolution of these sys- que tratar de analizar conceptos y procesos di- tems, establishing a chronology since the ap- rectamente relacionados con los gestores bi- pearance of the most popular bibliographic bliográficos personales, productos objeto de management software, highlighting their fea- estudio, tales como fuentes de información bi- tures and usefulness in academic research. We bliográfica y la normalización bibliográfica y, have analyzed concepts and processes directly fundamentalmente del ámbito científico, donde related to personal bibliographic management son productos esenciales en la formalización de applications under study, such as the sources of la su producción para su posterior difusión. Para bibliographic information and the set of biblio- ello se realiza un análisis comparativo entre los graphic standards employed by them, essential gestores de referencia bibliográficos gratuitos aspects of the scientific field, where these prod- Zotero, Docear y Mendeley, habiendo consegui- ucts have a great importance in the formalization do identificar algunas diferencias significativas of the scientific production for later broadcast . -

Bibliographic Related Software and Standards Information
Bibliographic Related Software and Standards Information Last Modified A printer friendly PDF version of this page is available 2006-January-9 biblio-sw.pdf (120 Kb) Table of Contents Open Standards Open Standards Information Citproc Bibliophile MODS Z39.50 and SRW Other Links to Bibliographic Software Information Overview of Personal Bibliographic Software Java B3 JabRef Perl, Python Pbib RISImport.py MS Windows Scholars Aid Nota Bene EndNote ProCite Reference Manager Biblioscape Citit! Bibliographix Windows, Linux, Other Bibutils Bibus LaTeX / BibTeX Linux Bookcase BibTeXML BibML BibX ISDN Search YAZ Zoom RefDB Sixpack bp 1 gBib Pybliographer Kaspaliste The Jurabib package refbase MAC OS X BibDesk Open Standards Information Check this web site on Open Standards and software for bibliographies and cataloging. This site provides a quick overview of the landscape of open-source bibliographic software; both where is has been, but more importantly, where it may yet go, and may be better than this page. http://wwwsearch.sourceforge.net/bib/openbib.html A good source on open standards in regards to XML, is the OASIS site http://xml.coverpages.org, and of course www.w3.org - home of the internet. CitProc The Openoffice Bibliographic project is proposing to use Bibliographic citation and table generation via XSLT style-sheets using a new process called CiteProc. CiteProc style-sheets provide, for the first time, the opportunity for the creation and distribution of opensource bibliographic style definitions that are not specific to a particular word-processor or bibliographic package. Also see BiblioX for technical discusion of this approach. We now have working examples. Bibliophile Bibliophile is an initiative to align the development of bibliographic databases for the web. -
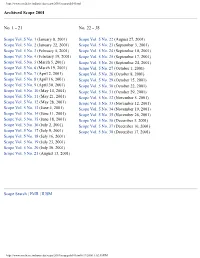
Archived Scope 2001 No. 1
http://www.medicine.indiana.edu/scope/2001/scopepub01.html Archived Scope 2001 No. 1 - 21 No. 22 - 38 Scope Vol. 5 No. 1 (January 8, 2001) Scope Vol. 5 No. 22 (August 27, 2001) Scope Vol. 5 No. 2 (January 22, 2001) Scope Vol. 5 No. 23 (September 3, 2001) Scope Vol. 5 No. 3 (February 5, 2001) Scope Vol. 5 No. 24 (September 10, 2001) Scope Vol. 5 No. 4 (February 19, 2001) Scope Vol. 5 No. 25 (September 17, 2001) Scope Vol. 5 No. 5 (March 5, 2001) Scope Vol. 5 No. 26 (September 24, 2001) Scope Vol. 5 No. 6 (March 19, 2001) Scope Vol. 5 No. 27 (October 1, 2001) Scope Vol. 5 No. 7 (April 2, 2001) Scope Vol. 5 No. 28 (October 8, 2001) Scope Vol. 5 No. 8 (April 16, 2001) Scope Vol. 5 No. 29 (October 15, 2001) Scope Vol. 5 No. 9 (April 30, 2001) Scope Vol. 5 No. 30 (October 22, 2001) Scope Vol. 5 No. 10 (May 14, 2001) Scope Vol. 5 No. 31 (October 29, 2001) Scope Vol. 5 No. 11 (May 21, 2001) Scope Vol. 5 No. 32 (November 5, 2001) Scope Vol. 5 No. 12 (May 28, 2001) Scope Vol. 5 No. 33 (November 12, 2001) Scope Vol. 5 No. 13 (June 4, 2001) Scope Vol. 5 No. 34 (November 19, 2001) Scope Vol. 5 No. 14 (June 11, 2001) Scope Vol. 5 No. 35 (November 26, 2001) Scope Vol. 5 No. 15 (June 18, 2001) Scope Vol. 5 No. 36 (December 3, 2001) Scope Vol. -

313180000001189 636875 7.Pdf
STATE OF MICHIGAN PROCUREMENT Department of Education 608 W. Allegan, Lansing, MI 48933 P.O. Box 30008, Lansing, MI 48909 CONTRACT CHANGE NOTICE Change Notice Number 180000001189 . to Contract Number 1. EBSCO Publishing, Inc. dba EBSCO Shannon White MDE/LOM Information Services 10 Estes Street 517-335-1507 Program Manager Ipswich, MA 01938 [email protected] Marc Donnelly Carol Munroe MDE/OFM STATE 800-653-2726 ext. 2742 517-241-3329 Contract CONTRACTOR [email protected] Administrator [email protected] CXXXX1771 CONTRACT SUMMARY Content/Database Subscriptions for Library of Michigan INITIAL AVAILABLE EXPIRATION DATE BEFORE INITIAL EFFECTIVE DATE INITIAL EXPIRATION DATE OPTIONS CHANGE(S) NOTED BELOW 09/01/2018 09/30/2021 Five; 1-year 09/30/2021 PAYMENT TERMS DELIVERY TIMEFRAME Net 45 Days Subscription/Access to resources to begin October 1, 2018 ALTERNATE PAYMENT OPTIONS EXTENDED PURCHASING ☐ P-card ☐ Payment Request (PRC) ☐ Other ☐ Yes ☒ No MINIMUM DELIVERY REQUIREMENTS NA DESCRIPTION OF CHANGE NOTICE LENGTH OF OPTION LENGTH OF OPTION EXTENSION REVISED EXP. DATE EXTENSION ☒ 2; 1-year ☐ 09/30/2023 CURRENT VALUE VALUE OF CHANGE NOTICE ESTIMATED AGGREGATE CONTRACT VALUE $3,365,658.00 $2,371,877.00 $5,737,535.00 Effective August 1, 2021 the following changes are made to this Contract: 1. State Contract Administrator is changed to Carol Munroe 2. State Program Manager is changed to Shannon White 3. 1st and 2nd of five available option years is exercised extending contract term to September 30, 2023 4. Value increase of $2,371,877.00 - $1,172,745.00 for FY22 and $1,199,132.00 for FY23 All other terms, conditions, specifications, and pricing remain the same. -

Initial Steps in Writing and Submitting a Research Paper
CLINICAL RESEARCH AND METHODOLOGY Cortesy of Cláudio Florido Rodrigues M.D. INITIAL STEPS IN WRITING AND SUBMITTING A RESEARCH PAPER Passos iniciais na elaboração e submissão de um manuscrito Denise Pinheiro Falcãoa, Anthony Terrence O’Brienb, Rivadávio Fernandes Batista de Amorimb, Heitor Morenob, Felipe Fregnib, Maria Regina Chalitaa BACKGROUND: This article is part of a special series designed to help authors in the process of scientific writing.OBJECTIVE: To address the steps that should precede the writing and submission of a research paper in order to optimize the process. METHOD: The authors discussed among them some strategies that should be adopted before properly starting the manuscript writing. RESULTS: Key strategies were organized into five thematic groups, namely: 1) How to prepare yourself for writing, 2) How to organize and prepare the writing tools, 3) How to elaborate a draft, 4) How to choose a journal, and 5) Who should be an author. CONCLUSION: Key strategies should be adopted before writing and submitting a research paper. Such strategies might ABSTRACT improve the author’s performance, optimize the time spent, and promote a high-quality communication writing, more pleasantly. KEYWORDS: scientific writing; manuscript; authorship; education; publications. INTRODUÇÃO: Este artigo é parte de uma série especial que foi desenvolvida para auxiliar autores no processo da redação científica. OBJETIVO: Abordar as etapas que devem preceder a redação e a submissão de artigos científicos com o intuito de aprimorar o processo. MÉTODOS: Os autores discutiram entre si algumas estratégias que cada um costumava adotar antes de iniciar propriamente a redação de um manuscrito. RESULTADOS: Foram estabelecidas cinco etapas estratégicas relativas ao preparo prévio à redação de um manuscrito, a saber: 1) Como se preparar para a escrita, 2) Como organizar e preparar as ferramentas de escrita, 3) Como elaborar um esboço, 4) Como escolher um periódico e 5) Quem deve ser um autor. -

Endnote: Transferring Citations from Searchusa There Are Many Ways
EndNote: Transferring Citations from SearchUSA There are many ways to add citations to your EndNote Library. Many of the library’s resources provide simple solutions for transferring citations directly into Endnote. 1) Run a search in SearchUSA, then choose an article from the results list. On the article’s item record page (below), under TOOLS, click on EXPORT to add citations to your EndNote Library. 2) Export Manager: Select Direct Export in RIS Format (e.g. CITAVI, EasyBib, EndNote, ProCite, Reference Manager, Zotero), then click SAVE. 3) Browsers: a. Internet Explorer users will be prompted to OPEN a ‘delivery.ris’. file. b. For Firefox users, select ‘Open with’, but make sure to open the file with “ResearchSoft Direct Export Helper”. c. Google Chrome users, once the file appears at the bottom of your browser, click on the file or click on the arrow and choose OPEN. 4) Once the file has been opened, the reference should appear in your EndNote library. But what if you have multiple citations to transfer? 1) Click on the FILE FOLDER icon beside each article entry. 2) Click on the corresponding FILE FOLDER icon at the top of the page. *The content in this folder will be deleted if you close out of SearchUSA. If you would like to save it, you will need to create a “My EBSCOhost” account. My EBSCOhost accounts are free and an excellent way to keep track of your research. 3) Select the articles you would like to transfer to EndNote. Click EXPORT. 4) Export Manager: Export Manager: Select Direct Export in RIS Format (e.g. -

Frequently Asked Questions
Ready Reference Guide Frequently Asked Questions August 2005 Frequently Asked Questions Table of Contents About RefWorks – Page 5 Q. What is RefWorks? Q. How can I find out more about RefWorks? Accessing RefWorks – Page 6 Q. How do I access RefWorks? Q. I keep getting error messages when I try to log in. Help! Q. I’ve forgotten my login name and password. How can I get them? Q. How do I change my user name and password? Q. How do I open two accounts in RefWorks at the same time? Q. When I open two accounts at the same time they always end up being the same. Why? Q. I'm using Mozilla FireFox and having problems accessing. Is there a solution? Sharing Your RefWorks Database – Page 9 Q. I am working on a group project. Can we share a RefWorks account? Q. Can more that one person access my account at a time? Getting Information Into your RefWorks Database – Page 9 Q. How can I import results of searches into RefWorks? Q. Where are my references stored? Q. Can I export references directly from online databases to my RefWorks account? Page 2 of 22 ©2005 Refworks LLC Getting Information Into your RefWorks Database – Page 9 (Cont’d) Q. If an import filter does not exist for the database I work in, who should I contact to see if one can be built? Q. When I try to export references from an online database with a RefWorks option, nothing happens. What do I do? Q. I imported some records from an online database and the information didn’t import correctly. -

SAO/NASA ADS Help Pages
SAO/NASA ADS Help Pages ADS Team May 12, 2017 Contents 1 Overview 4 1.1 What is the ADS? . 4 1.1.1 Use of the ADS . 4 1.1.2 User Privacy . 5 1.2 About the Data in the ADS . 6 1.2.1 Origin . 6 1.2.2 Coverage . 7 1.2.3 Bibliographic Identifiers . 7 1.3 Updates . 9 1.4 Acknowledgments . 10 2 How to Search 12 2.1 Basic Query Form . 12 2.1.1 General Search Hints . 12 2.1.2 Year Range Searching . 13 2.1.3 Author Search . 13 2.1.4 Phrase Search . 14 2.1.5 Identifier Search . 14 2.1.6 Basic Search Plugin . 14 2.2 Abstract Query Form . 14 2.2.1 Introduction . 15 2.2.2 Search Fields . 16 2.2.3 Filters . 19 2.2.4 Sorting . 23 2.2.5 Settings . 24 2.2.6 Saving Queries . 26 2.2.7 Query Logic . 26 2.3 The Experimental Topic Search Interface . 27 2.3.1 Keyword Searches . 27 2.3.2 Subject Area Searches . 28 2.4 Searching by Reference Information . 29 2.4.1 Searching by Journal/Volume/Page . 29 2.4.2 Searching by Reference . 29 2.4.3 Searching by Bibcode . 30 1 2.5 Current/Unread Journals . 30 2.5.1 Current Journals . 30 2.5.2 Unread Journals . 30 2.6 Searching for Scanned Journals/Proceedings . 31 2.7 Searching Lists of Terms and Authors . 31 2.7.1 Exact Author Query Form . 31 2.7.2 Abstract Service List Query .