Multi-Label Playlist Classification Using Convolutional Neural Network
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Everything Subject to Change. SXSW Showcasing Artists Current As of March 8, 2017
424 (San José COSTA RICA) Lydia Ainsworth (Toronto ON) ANoyd (Bloomfield CT) !!! (Chk Chk Chk) (Brooklyn NY) Airways (Peterborough UK-ENGLAND) AOE (Los Angeles CA) [istandard] Producer Experience (Brooklyn NY) Aj Dávila (San Juan PR) Apache (VEN) (Cara VENEZUELA) #HOODFAME GO YAYO (Fort Worth TX) Jeff Akoh (Abuja NIGERIA) Apache (San Francisco CA) 070 Shake (North Bergen NJ) Federico Albanese (Berlin GERMANY) Ape Drums (Houston TX) 14KT (Ypsilanti MI) Latasha Alcindor (Brooklyn NY) Ben Aqua (Austin TX) 24HRS (Atlanta GA) AlcolirykoZ (Medellín COLOMBIA) Aquilo (London UK-ENGLAND) 2 Chainz (Atlanta GA) Alexandre (Austin TX) Sudan Archives (Los Angeles CA) 3rdCoastMOB (San Antonio TX) Alex Napping (Austin TX) Arco (Granada SPAIN) The 4onthefloor (Minneapolis MN) ALI AKA MIND (Bogotá COLOMBIA) Ariana and the Rose (New York NY) 4x4 (Bogotá COLOMBIA) Alikiba (Dar Es Salaam TANZANIA) Arise Roots (Los Angeles CA) 5FINGERPOSSE (Philadelphia PA) All in the Golden Afternoon (Austin TX) Arkansas Dave (Austin TX) 5ive (Earth TX) Allison Crutchfield and the Fizz (Philadelphia Brad Armstrong (Rhinebeck NY) PA) 808INK (London UK-ENGLAND) Ash Koosha (Iran / London UK-ENGLAND) All Our Exes Live In Texas (Newtown NSW) 9th Wonder (Winston-Salem NC) Ask Carol (Oslo NORWAY) Al Lover (San Francisco CA) A-Town GetDown (Austin TX) Astro 8000 (Philadelphia PA) Annabel Allum (Guildford UK-ENGLAND) A$AP FERG (Harlem NY) A Thousand Horses (Nashville TN) August Alsina (New Orleans LA) A$AP Twelvyy (New York NY) Nicole Atkins (Nashville TN) Altre di B (Bologna ITALY) -

KMGC Productions KMGC Song List
KMGC Productions KMGC Song List Title Title Title (We Are) Nexus 2 Faced Funks 2Drunk2Funk One More Shot (2015) (Cutmore Club Powerbass (2 Faced Funks Club Mix) I Can't Wait To Party (2020) (Original Mix) Powerbass (Original Club Mix) Club Mix) One More Shot (2015) (Cutmore Radio 2 In A Room Something About Your Love (2019) Mix) El Trago (The Drink) 2015 (Davide (Original Club Mix) One More Shot (2015) (Jose Nunez Svezza Club Mix) 2elements Club Mix) Menealo (2019) (AIM Wiggle Mix) You Don't Stop (Original Club Mix) They'll Never Stop Me (2015) (Bimbo 2 Sides Of Soul 2nd Room Jones Club Mix) Strong (2020) (Original Club Mix) Set Me Free (Original Club Mix) They'll Never Stop Me (2015) (Bimbo 2Sher Jones Radio Mix) 2 Tyme F. K13 Make It Happ3n (Original Club Mix) They'll Never Stop Me (2015) (Jose Dance Flow (Jamie Wright Club Mix) Nunez Radio Mix) Dance Flow (Original Club Mix) 3 Are Legend, Justin Prime & Sandro Silva They'll Never Stop Me (2015) (Sean 2 Unlimited Finn Club Mix) Get Ready For This 2020 (2020) (Colin Raver Dome (2020) (Original Club Mix) They'll Never Stop Me (2015) (Sean Jay Club Mix) 3LAU & Nom De Strip F. Estelle Finn Radio Mix) Get Ready For This 2020 (2020) (Stay The Night (AK9 Club Mix) 10Digits F. Simone Denny True Club Mix) The Night (Hunter Siegel Club Mix) Calling Your Name (2016) (Olav No Limit 2015 (Cassey Doreen Club The Night (Original Club Mix) Basoski Club Mix) Mix) The Night (Original Radio Mix) Calling Your Name (Olav Basoski Club 20 Fingers F. -

L.A. Reid's Fall from Grace
• ¡••• DIDN'T WANT TO DO IT!' Céline Dion on the weird, wondrous history of 'My Heart Will Go On' L.A. REID'S FALL FROM ateletZt-elrffleigk GRACE 2017 BILLBOARD MUSIC AWARDS At 71, this year's Icon honore' is having the time ofher life, as she rage-tweets about Trump and (finally comes to terms with her legacy: I ' 111y ge- is Imake peoplefeel good' May 27,2017 billboard.conn WorldRadioHistory ALL YOU NEED IS LOVE WorldRadioHistory The long and winding road finally led them here. The band's one and only official channel. THE EAILES CHANNEL Ch 18 Only on SiriusX111))) Inc. Radio Turned on and free for anyone with an unsubscribed satellite radio XM now through May 30 Sirius 2017 siriusxnn.conn/thebeatles CD WorldRadioHistory WorldRadioHistory • Fonsi (left) an td Daddy Yankee eachi score their first Hot 100 No. 1with "Despacito.:, • > . fI 0 ' . •••.: • • 1p••• 1 61. 4 TitleCERTIFICATION Artist iE PRODUCER [SONGWRITER) IMPRINT/PROMOTION LABEL Despacito Luis Fonsi &Daddy Yankee Feat. Justin Bieber 1 17 RACIWLGEringeegeaSIL"AL' BRAUN/SUCVOEMMALCOM That's What ILike A Bruno Mars 1 17 E) H.eBTIWON7EYÁU8N'çFIERRLÓSTII5eT,drigeNLY8.12/EMP,IkUMIUSEIL II) ATLANTIC rm The One Di Khaled Fee. Justin Bieber, Quavo, Chance The Rapper &Lil Wayne 1 2 MOSTLY SPANISH SONG "Despacito" crowns the Streaming e..Y.EREi-Págniediee,eadil EViCkCYarHALL wETHE KS/DEE lam/EPIC is No. 1. Language isn't a Songs chart with 54.3 million U.S. factor," says abeaming streams (up 14 percent), according 2 5 Shape Of You A Ed Sheeran 1 18 Luis Fonsi. -
Los Angeles April 24–27, 2018
A PR I L 24–27, 2018 1 NORDIC MUSIC TRADE MISSION / NORDIC SOUNDS APRIL 24–27 LOS ANGELES LOS ANGELES NORDIC WRITERS 2 NORDIC MUSIC TRADE MISSION / NORDIC SOUNDS APRIL 24–27 LOS ANGELES Lxandra Ida Paul Celine Svänback TOPLINER / ARTIST TOPLINER / ARTIST TOPLINER FINLAND FINLAND DENMARK Lxandra is a 21 year-old singer/songwriter from a Ida Paul is a Finnish-American songwriter signed Celine is a new, 22 year-old songwriter from Co- small island called, Suomenlinna, outside of Helsinki, to HMC Publishing (publishing company owned by penhagen, whose discography includes placements Finland. She is currently working on her forthcoming Warner Music Finland) as a songwriter, and Warner with Danish artists such as Stine Bramsen (Copenha- debut album, due out in 2018 on Island Records. Her Records Finland as an artist. She released her de- gen Recs), Noah (Copenhagen Recs), Anya (Sony), first single was “Flicker“, released in 2017. Follow-up but single, “Laukauksia pimeään” in 2016, which Faustix (WB), and Page Four (Sony). Recent collabo- singles included “Hush Hush Baby“ and “Dig Deep”. certified platinum. She has since joined forces with rations include those with Morten Breum (PRMD/Dim popular Finnish artist, Kalle Lindroth, and together Mak/WB), Cisilia (Nexus/Uni), Gulddreng (Uni), and COMPANY they have released three platinum-certified singles Ericka Jane (Uni). Celine is currently collaborating MAG Music/Island Records (“Kupla”, “Hakuammuntaa”, and “Parvekkeella”). with new artists such as Imani Williams (RCA UK), Anna Goller The duo was recently nominated as “Newcomer Jaded (Sony UK), KLOE (Kobalt UK), Polina (Warner Of The Year” for the 2018 Emma Awards (Finn- UK), Leon Arcade (RCA UK), Lionmann (Sony Swe- LINK ish Grammy’s). -
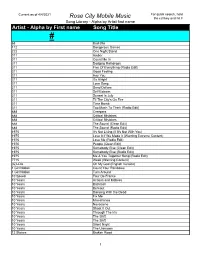
Alpha by First Name Song Title
Current as of 4/4/2021 For quick search, hold Rose City Mobile Music the ctrl key and hit F Song Library - Alpha by Artist first name Artist - Alpha by First name Song Title # 68 Bad Bite 112 Dangerous Games 222 One Night Stand 311 Amber 311 Count Me In 311 Dodging Raindrops 311 Five Of Everything (Radio Edit) 311 Good Feeling 311 Hey You 311 It's Alright 311 Love Song 311 Sand Dollars 311 Self Esteem 311 Sunset In July 311 Til The City's On Fire 311 Time Bomb 311 Too Much To Think (Radio Edit) 888 Creepers 888 Critical Mistakes 888 Critical Mistakes 888 The Sound (Clean Edit) 888 The Sound (Radio Edit) 1975 It's Not Living (If It's Not With You) 1975 Love It If We Made It (Warning Extreme Content) 1975 Love Me (Radio Edit) 1975 People (Clean Edit) 1975 Somebody Else (Clean Edit) 1975 Somebody Else (Radio Edit) 1975 Me & You Together Song (Radio Edit) 7715 Week (Warning Content) (G)I-Dle Oh My God (English Version) 1 Girl Nation Count Your Rainbows 1 Girl Nation Turn Around 10 Speed Tour De France 10 Years Actions and Motives 10 Years Backlash 10 Years Burnout 10 Years Dancing With the Dead 10 Years Fix Me 10 Years Miscellanea 10 Years Novacaine 10 Years Shoot It Out 10 Years Through The Iris 10 Years The Shift 10 Years The Shift 10 Years Silent Night 10 Years The Unknown 12 Stones Broken Road 1 Current as of 4/4/2021 For quick search, hold Rose City Mobile Music the ctrl key and hit F Song Library - Alpha by Artist first name Artist - Alpha by First name Song Title 12 Stones Bulletproof 12 Stones Psycho 12 Stones We Are One 16 Frames Back Again 16 Second Stare Ballad of Billy Rose 16 Second Stare Bonnie and Clyde 16 Second Stare Gasoline 16 Second Stare The Grinch (Radio Edit ) 1975. -
2018 Official Schedule the World’S Largest Music Festival® Milwaukee, Wisconsin
2018 OFFICIAL SCHEDULE THE WORLD’S LARGEST MUSIC FESTIVAL® MILWAUKEE, WISCONSIN For updates on talent, tickets, and more visit SUMMERFEST.COM ALL PERFORMERS, DATES AND TIMES ARE SUBJECT TO CHANGE WITHOUT NOTICE. There’s not a bad seat in the house. With a 25-foot LED screen, you’ll be up-close and personal with your favorite artists at the new high-tech U.S. Cellular® Connection Stage — plus enjoy lakefront views. Other attractions include: • Lakefront seating area with charging ports • Interactive games at our Connected Tiny Home • Fun videoboard activities Official Wireless Provider of Summerfest Things we want you to know: Official rules apply. See an Associate for details. Trademarks and trade names are the property of their respective owners. 0077_0218 2 0077_0218_Ad_2018 Summerfest Brochure.indd 1 3/28/18 2:44 PM YOUR SAVINGS IS IN OUR NAME... FREE SummerfestWITH Ticket 2 12 pack 16oz Cans Miller Lite or Miller Draft or 2 12 pack bottles any variety Leinenkugel Craft Beer STOCK UP & INSTANTLY on any $50 purchase of these$5 brandssave at Discount Liquor Coupon Valid 5/21/18 – 7/8/18 A FAMILY TRADITION keeping you in good spirits since 1960 Visit us on Facebook/Twitter or at WWW.DISCOUNTLIQUORINC.COM MILWAUKEE WAUKESHA 5031 W. Oklahoma Ave. 919 N. Barstow Ave. (414) 545-2175 (262) 547-7525 3 Presented by DOWNLOAD THE SUMMERFEST APP! Fueled by PEPSI_H1_NB_SM_4C (FOR USE .25” 1.5" ) FESTIVAL HOURS CMYK Noon – midnight, daily. BOX OFFICE HOURS Before Summerfest 10:00 am – 6:00 pm, Monday – Friday. PEPSI_H1_NB_MEDIUM_4C (FOR USE 1.5" TO 4") 10:00 am – 1:00 pm, Saturdays through Summerfest.CMYK During Summerfest 10:00 am – 10:00 pm SPECIAL TICKETING INFORMATION PEPSI_H1_NB_LARGE_4C (4" AND LARGER) American Family Insurance Amphitheater CMYK All reserved tickets for American Family Insurance Amphitheater concerts during Summerfest include admission to the festival. -

ENERGY MASTERMIX – Playlists Vom 08.03.2019
ENERGY MASTERMIX – Playlists vom 08.03.2019 HELMO 1. Gaullin – Moonlight 2. Kygo ft Conrad – Firestone 3. David Guetta ft. Brooks & Loote – Better When You’re Gone 4. Panic! At The Disco – High Hopes (White Panda/Don Diablo Remix) 5. Jax Jones ft. Years & Years – Play 6. Macklemore & Ryan Lewis – Can’t Hold Us 7. Alan Walker – Lost Control 8. The Prince Karma – Later Bitches 9. Mark Ronson ft Bruno Mars – Uptown Funk 10. The Chainsmokers & 5 Seconds Of Summer -Who Do You Love 11. Alle Farben ft. Ilira – Fading 12. Loud Luxury ft. Brando – Body 13. Martin Jensen & James Arthur – Nobody 14. Klangkarussell – Sonnentanz 15. Hugel ft Amber Van Day – WTF 16. Fisher – Losing It 17. Triplo Max – Shadow 18. DJ Snake ft. Justin Bieber – Let Me Love You 19. Calvin Harris & Rag’n’Bone Man – Giant 20. Shawn Mendes & Zedd – Lost in Japan (Remix) 21. Ava Max – Sweet But Psycho (Morgan Page Remix) 22. Sam Feldt ft Kimberly Anne – Show Me Love (EDX Remix) 23. Alvaro Soler – Loca 24. Rita Ora – Let Me Love You 25. Sam Smith ft Normani – Dancing With A Stranger 26. Sean Paul ft Keyshia Cole – (When You Gonna) Give It Up To Me 27. Decco & Alex Clare – Crazy To Love You 28. Ariana Grande – 7 Rings (Remix) 29. Justin Timberlake – Can’t Stop The Feeling! 30. Gesaffelstein & The Weeknd – Lost In The Fire 31. Ellie Goulding & Diplo ft Swae Lee – Close To Me 32. Calvin Harris & Sam Smith – Promises 33. Hayden James – Better Together (Remix) 34. Flo Rida – Whistle 35. NOTD & Felix Jaehn – So Close 36. -
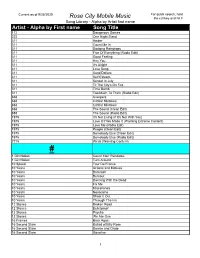
Alpha by First Name Song Title
Current as of 9/26/2020 For quick search, hold Rose City Mobile Music the ctrl key and hit F Song Library - Alpha by Artist first name Artist - Alpha by First name Song Title 112 Dangerous Games 222 One Night Stand 311 Amber 311 Count Me In 311 Dodging Raindrops 311 Five Of Everything (Radio Edit) 311 Good Feeling 311 Hey You 311 It's Alright 311 Love Song 311 Sand Dollars 311 Self Esteem 311 Sunset In July 311 Til The City's On Fire 311 Time Bomb 311 Too Much To Think (Radio Edit) 888 Creepers 888 Critical Mistakes 888 Critical Mistakes 888 The Sound (Clean Edit) 888 The Sound (Radio Edit) 1975 It's Not Living (If It's Not With You) 1975 Love It If We Made It (Warning Extreme Content) 1975 Love Me (Radio Edit) 1975 People (Clean Edit) 1975 Somebody Else (Clean Edit) 1975 Somebody Else (Radio Edit) 7715 Week (Warning Content) # 1 Girl Nation Count Your Rainbows 1 Girl Nation Turn Around 10 Speed Tour De France 10 Years Actions and Motives 10 Years Backlash 10 Years Burnout 10 Years Dancing With the Dead 10 Years Fix Me 10 Years Miscellanea 10 Years Novacaine 10 Years Shoot It Out 10 Years Through The Iris 12 Stones Broken Road 12 Stones Bulletproof 12 Stones Psycho 12 Stones We Are One 16 Frames Back Again 16 Second Stare Ballad of Billy Rose 16 Second Stare Bonnie and Clyde 16 Second Stare Gasoline 1 Current as of 9/26/2020 For quick search, hold Rose City Mobile Music the ctrl key and hit F Song Library - Alpha by Artist first name Artist - Alpha by First name Song Title 16 Second Stare The Grinch (Radio Edit ) 1975. -

Billboard Magazine
02.15.2014 billboard.com billboard.biz ; Country's Ii Woman Woes What's behind Kacey Musgraves' radio struggle 8 New Hot Acts Of 2014 PLUS Spring's most wanted albums From left: Tonight's booker Jonathan Cohen, Fallon and Questlove How Fallon & Co. became the hottest stop in music: as the host reveals his ASCAPCONGRATULATIONS ON YOUR WorldMags.netWorldMags.net WorldMags.net valuing music since 1939. Photo by Danny Clinch WorldMags.net THIS WEEK 15 Volume 126 FEB No. 5 2014 FEATURES CONTENTSPhotographer 24 Jimmy Fallon Andrew 30 New Artists Hetherington 36 Giorgio Moroder at Billboard’s Feb. 4 photo 38 Spring Preview shoot with Jonathan SPECIAL FEATURE Cohen, Jimmy Fallon and 43 ASCAP Questlove. Below: Giorgio TOPLINE Moroder 6 Country radio’s photographed by David Black girl problem. on Dec. 20 in 14 Questions Los Angeles. Answered Iñigo Zabala, Warner Music Latin America & Iberia 16 The Deal Romeo Santos partners with Dr Pepper. 18 Think Tank With the Brand, Latin Notas 19 My Day Sarah Trahern, Country Music Assn. BACKBEAT 20 Parties Super Bowl XLVIII, Howard Stern’s FEATURE 60th birthday 23 New York Fall Fashion Week FEATURE P.24 “No one at NBC tells MUSIC me to do anything—they JIMMY 67 Happening Now GIORGIO Beyoncé, Pete see what we’ve done with Seeger MORODER our show.” FALLON CHARTS 69 Over the Counter P.36 “Until Grammy glows on COUNTRY the Billboard 200. recently I was 70 Charts 92 Coda Elton John’s mostly playing P.6 “Kacey Musgraves is a challenge for “Your Song” gets MIKE a revival by Aloe a lot of golf— DUNGAN country radio, but new music should be Blacc. -

ENERGY MASTERMIX – Playlists Vom 17.05.2019 MORGAN NAGOYA
ENERGY MASTERMIX – Playlists vom 17.05.2019 MORGAN NAGOYA Keine Playlist vorhanden ROBIN SCHULZ 1. Wanna Know You – Burak Yeter 2. Mirai – Madison Mars 3. Come With Me – Third Party 4. Jumpin – Trizzoh 5. Emoji – Galantis 6. LaLaLand – Green Velvet ( COTW ) 7. Gorilla – Oscar House 8. 1000 Years – Bingo Players 9. All This Love – Robin Schulz feat Harlœ 10. Robo – Sagan 11. Escape – Dante Klein 12. My Phone – Felguk 13. I Got You – Mike Williams 14. Work – Moti 15. Breathe – Camel Phat 16. Rhythm – TV Noise 17. Lonely – Eddie Thoneick & Kurd Maverick HARDWELL Keine Playlist vorhanden OLIVER HELDENS 1 Axwell - Nobody Else (A-Trak Remix) 2 Rivas (BR) - Fly With You 3 La Fuente - So Fat 4 Bart B More - Hamsterdam 5 SKIY - Who Got The Keys 6 Gaullin - Moonlight 7 Lost Frequencies feat. Flynn - Recognize (Damien N-Drix Remix) 8 Le Youth - Selfish [HELDEEP COOLDOWN] 9 Rrotik x Lothief - Vida Loka (feat. MC Rodolfinho) 10 Oliver Heldens & Lenno - This Groove (Codeko Remix) 11 Dannic & Promise Land - Over (Zonderling Edit) 12 Swanky Tunes - U Got Me Burning 13 Latroit - Four on the Floor 14 Tiësto & Justin Caruso - Feels So Good (feat. Kelli-Leigh) 15 Matroda - Bang (feat. Dances With White Girls) 16 Oliver Heldens & MOGUAI - Cucumba 17 The Shapeshifters - Helter Skelter PAUL VAN DYK 1 Aerotek - Dystopia Is My Utopia 2 Ferry Corsten presents Gouryella – Surga 3 Oto Kapanadze – The Force 4 Alex Di Stefano - Into The Flames 5 M.I.K.E. Push vs Robert Nickson - Lunar Lander 6 Les Hemstock - Angel Chorus 7 Paul van Dyk & Alex M.O.R.P.H.