Magma Cryptosystems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Classical Encryption Techniques
CPE 542: CRYPTOGRAPHY & NETWORK SECURITY Chapter 2: Classical Encryption Techniques Dr. Lo’ai Tawalbeh Computer Engineering Department Jordan University of Science and Technology Jordan Dr. Lo’ai Tawalbeh Fall 2005 Introduction Basic Terminology • plaintext - the original message • ciphertext - the coded message • key - information used in encryption/decryption, and known only to sender/receiver • encipher (encrypt) - converting plaintext to ciphertext using key • decipher (decrypt) - recovering ciphertext from plaintext using key • cryptography - study of encryption principles/methods/designs • cryptanalysis (code breaking) - the study of principles/ methods of deciphering ciphertext Dr. Lo’ai Tawalbeh Fall 2005 1 Cryptographic Systems Cryptographic Systems are categorized according to: 1. The operation used in transferring plaintext to ciphertext: • Substitution: each element in the plaintext is mapped into another element • Transposition: the elements in the plaintext are re-arranged. 2. The number of keys used: • Symmetric (private- key) : both the sender and receiver use the same key • Asymmetric (public-key) : sender and receiver use different key 3. The way the plaintext is processed : • Block cipher : inputs are processed one block at a time, producing a corresponding output block. • Stream cipher: inputs are processed continuously, producing one element at a time (bit, Dr. Lo’ai Tawalbeh Fall 2005 Cryptographic Systems Symmetric Encryption Model Dr. Lo’ai Tawalbeh Fall 2005 2 Cryptographic Systems Requirements • two requirements for secure use of symmetric encryption: 1. a strong encryption algorithm 2. a secret key known only to sender / receiver •Y = Ek(X), where X: the plaintext, Y: the ciphertext •X = Dk(Y) • assume encryption algorithm is known •implies a secure channel to distribute key Dr. -

What Is a Cryptosystem?
Cryptography What is a Cryptosystem? • K = {0, 1}l • P = {0, 1}m • C′ = {0, 1}n,C ⊆ C′ • E : P × K → C • D : C × K → P • ∀p ∈ P, k ∈ K : D(E(p, k), k) = p • It is infeasible to find F : P × C → K Let’s start again, in English. Steven M. Bellovin September 13, 2006 1 Cryptography What is a Cryptosystem? A cryptosystem is pair of algorithms that take a key and convert plaintext to ciphertext and back. Plaintext is what you want to protect; ciphertext should appear to be random gibberish. The design and analysis of today’s cryptographic algorithms is highly mathematical. Do not try to design your own algorithms. Steven M. Bellovin September 13, 2006 2 Cryptography A Tiny Bit of History • Encryption goes back thousands of years • Classical ciphers encrypted letters (and perhaps digits), and yielded all sorts of bizarre outputs. • The advent of military telegraphy led to ciphers that produced only letters. Steven M. Bellovin September 13, 2006 3 Cryptography Codes vs. Ciphers • Ciphers operate syntactically, on letters or groups of letters: A → D, B → E, etc. • Codes operate semantically, on words, phrases, or sentences, per this 1910 codebook Steven M. Bellovin September 13, 2006 4 Cryptography A 1910 Commercial Codebook Steven M. Bellovin September 13, 2006 5 Cryptography Commercial Telegraph Codes • Most were aimed at economy • Secrecy from casual snoopers was a useful side-effect, but not the primary motivation • That said, a few such codes were intended for secrecy; I have some in my collection, including one intended for union use Steven M. -

A Covert Encryption Method for Applications in Electronic Data Interchange
Technological University Dublin ARROW@TU Dublin Articles School of Electrical and Electronic Engineering 2009-01-01 A Covert Encryption Method for Applications in Electronic Data Interchange Jonathan Blackledge Technological University Dublin, [email protected] Dmitry Dubovitskiy Oxford Recognition Limited, [email protected] Follow this and additional works at: https://arrow.tudublin.ie/engscheleart2 Part of the Digital Communications and Networking Commons, Numerical Analysis and Computation Commons, and the Software Engineering Commons Recommended Citation Blackledge, J., Dubovitskiy, D.: A Covert Encryption Method for Applications in Electronic Data Interchange. ISAST Journal on Electronics and Signal Processing, vol: 4, issue: 1, pages: 107 -128, 2009. doi:10.21427/D7RS67 This Article is brought to you for free and open access by the School of Electrical and Electronic Engineering at ARROW@TU Dublin. It has been accepted for inclusion in Articles by an authorized administrator of ARROW@TU Dublin. For more information, please contact [email protected], [email protected]. This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 4.0 License A Covert Encryption Method for Applications in Electronic Data Interchange Jonathan M Blackledge, Fellow, IET, Fellow, BCS and Dmitry A Dubovitskiy, Member IET Abstract— A principal weakness of all encryption systems is to make sure that the ciphertext is relatively strong (but not that the output data can be ‘seen’ to be encrypted. In other too strong!) and that the information extracted is of good words, encrypted data provides a ‘flag’ on the potential value quality in terms of providing the attacker with ‘intelligence’ of the information that has been encrypted. -

A New Cryptosystem for Ciphers Using Transposition Techniques
Published by : International Journal of Engineering Research & Technology (IJERT) http://www.ijert.org ISSN: 2278-0181 Vol. 8 Issue 04, April-2019 A New Cryptosystem for Ciphers using Transposition Techniques U. Thirupalu Dr. E. Kesavulu Reddy FCSRC (USA) Research Scholar Assistant Professor, Dept. of Computer Science Dept. of Computer Science S V U CM&CS – Tirupati S V U CM&CS - Tirupati India – 517502 India – 517502 Abstract:- Data Encryption techniques is used to avoid the performs the decryption. Cryptographic algorithms are unauthorized access original content of a data in broadly classified as Symmetric key cryptography and communication between two parties, but the data can be Asymmetric key cryptography. recovered only through using a key known as decryption process. The objective of the encryption is to secure or save data from unauthorized access in term of inspecting or A. Symmetric Cryptography adapting the data. Encryption can be implemented occurs by In the symmetric key encryption, same key is used for both using some substitute technique, shifting technique, or encryption and decryption process. Symmetric algorithms mathematical operations. By adapting these techniques we more advantageous with low consuming with more can generate a different form of that data which can be computing power and it works with high speed in encrypt difficult to understand by any person. The original data is them. The symmetric key encryption takes place in two referred to as the plaintext and the encrypted data as the modes either as the block ciphers or as the stream ciphers. cipher text. Several symmetric key base algorithms have been The block cipher mode provides, whole data is divided into developed in the past year. -

Caesar's Cipher Is a Monoalphabetic
Mathematical summer in Paris - Cryptography Exercise 1 (Caesar’s cipher ?) Caesar’s cipher is a monoalphabetic encryption method where all letters in the alphabet are shifted by a certain constant d. For example, with d = 3, we obtain A ! D; B ! E;:::; Y ! B; Z ! C: 1. Translate the encryption function f in algebraic terms. What is the decryption function g? 2. What is the key in Caesar’s cipher? How many keys are possible? 3. Decrypt the ciphertext LIPPSASVPH. Exercise 2 (Affine encryption ?) We now want to study a more general kind of encryption method, called affine encryption. We represent each letter in the latin alphabet by its position in the alphabet, starting with 0, i.e. A ! 0; B ! 1; C ! 2;:::; Z ! 25; and we consider the map f : x ! ax + b mod 26; where a and b are fixed integers between 0 and 25. We want to use the map f to encrypt each letter in the plaintext. 1. What happens if we choose a = 1? We now choose a = 10 and b = 3. def 2. Let 0 ≤ y ≤ 25 such that y = f(x) = 10x + 3 mod 26. Prove that there exists k 2 Z such that y = 10x + 26k + 3. 3. Prove that y is always odd. 4. What can we say about this encryption method? We now choose a = 9 and b = 4. 5. Find an integer u 2 Z such that 9u = 1 mod 26. 6. Explain why the equation y = 9x + 4 mod 26, with 0 ≤ y ≤ 25, always has a solution. -

The Mathemathics of Secrets.Pdf
THE MATHEMATICS OF SECRETS THE MATHEMATICS OF SECRETS CRYPTOGRAPHY FROM CAESAR CIPHERS TO DIGITAL ENCRYPTION JOSHUA HOLDEN PRINCETON UNIVERSITY PRESS PRINCETON AND OXFORD Copyright c 2017 by Princeton University Press Published by Princeton University Press, 41 William Street, Princeton, New Jersey 08540 In the United Kingdom: Princeton University Press, 6 Oxford Street, Woodstock, Oxfordshire OX20 1TR press.princeton.edu Jacket image courtesy of Shutterstock; design by Lorraine Betz Doneker All Rights Reserved Library of Congress Cataloging-in-Publication Data Names: Holden, Joshua, 1970– author. Title: The mathematics of secrets : cryptography from Caesar ciphers to digital encryption / Joshua Holden. Description: Princeton : Princeton University Press, [2017] | Includes bibliographical references and index. Identifiers: LCCN 2016014840 | ISBN 9780691141756 (hardcover : alk. paper) Subjects: LCSH: Cryptography—Mathematics. | Ciphers. | Computer security. Classification: LCC Z103 .H664 2017 | DDC 005.8/2—dc23 LC record available at https://lccn.loc.gov/2016014840 British Library Cataloging-in-Publication Data is available This book has been composed in Linux Libertine Printed on acid-free paper. ∞ Printed in the United States of America 13579108642 To Lana and Richard for their love and support CONTENTS Preface xi Acknowledgments xiii Introduction to Ciphers and Substitution 1 1.1 Alice and Bob and Carl and Julius: Terminology and Caesar Cipher 1 1.2 The Key to the Matter: Generalizing the Caesar Cipher 4 1.3 Multiplicative Ciphers 6 -

A Secure Variant of the Hill Cipher
† A Secure Variant of the Hill Cipher Mohsen Toorani ‡ Abolfazl Falahati Abstract the corresponding key of each block but it has several security problems [7]. The Hill cipher is a classical symmetric encryption In this paper, a secure cryptosystem is introduced that algorithm that succumbs to the know-plaintext attack. overcomes all the security drawbacks of the Hill cipher. Although its vulnerability to cryptanalysis has rendered it The proposed scheme includes an encryption algorithm unusable in practice, it still serves an important that is a variant of the Affine Hill cipher for which a pedagogical role in cryptology and linear algebra. In this secure cryptographic protocol is introduced. The paper, a variant of the Hill cipher is introduced that encryption core of the proposed scheme has the same makes the Hill cipher secure while it retains the structure of the Affine Hill cipher but its internal efficiency. The proposed scheme includes a ciphering manipulations are different from the previously proposed core for which a cryptographic protocol is introduced. cryptosystems. The rest of this paper is organized as follows. Section 2 briefly introduces the Hill cipher. Our 1. Introduction proposed scheme is introduced and its computational costs are evaluated in Section 3, and Section 4 concludes The Hill cipher was invented by L.S. Hill in 1929 [1]. It is the paper. a famous polygram and a classical symmetric cipher based on matrix transformation but it succumbs to the 2. The Hill Cipher known-plaintext attack [2]. Although its vulnerability to cryptanalysis has rendered it unusable in practice, it still In the Hill cipher, the ciphertext is obtained from the serves an important pedagogical role in both cryptology plaintext by means of a linear transformation. -

Index-Of-Coincidence.Pdf
The Index of Coincidence William F. Friedman in the 1930s developed the index of coincidence. For a given text X, where X is the sequence of letters x1x2…xn, the index of coincidence IC(X) is defined to be the probability that two randomly selected letters in the ciphertext represent, the same plaintext symbol. For a given ciphertext of length n, let n0, n1, …, n25 be the respective letter counts of A, B, C, . , Z in the ciphertext. Then, the index of coincidence can be computed as 25 ni (ni −1) IC = ∑ i=0 n(n −1) We can also calculate this index for any language source. For some source of letters, let p be the probability of occurrence of the letter a, p be the probability of occurrence of a € b the letter b, and so on. Then the index of coincidence for this source is 25 2 Isource = pa pa + pb pb +…+ pz pz = ∑ pi i=0 We can interpret the index of coincidence as the probability of randomly selecting two identical letters from the source. To see why the index of coincidence gives us useful information, first€ note that the empirical probability of randomly selecting two identical letters from a large English plaintext is approximately 0.065. This implies that an (English) ciphertext having an index of coincidence I of approximately 0.065 is probably associated with a mono-alphabetic substitution cipher, since this statistic will not change if the letters are simply relabeled (which is the effect of encrypting with a simple substitution). The longer and more random a Vigenere cipher keyword is, the more evenly the letters are distributed throughout the ciphertext. -

A Hybrid Cryptosystem Based on Vigenère Cipher and Columnar Transposition Cipher
International Journal of Advanced Technology & Engineering Research (IJATER) www.ijater.com A HYBRID CRYPTOSYSTEM BASED ON VIGENÈRE CIPHER AND COLUMNAR TRANSPOSITION CIPHER Quist-Aphetsi Kester, MIEEE, Lecturer Faculty of Informatics, Ghana Technology University College, PMB 100 Accra North, Ghana Phone Contact +233 209822141 Email: [email protected] / [email protected] graphy that use the same cryptographic keys for both en- Abstract cryption of plaintext and decryption of cipher text. The keys may be identical or there may be a simple transformation to Privacy is one of the key issues addressed by information go between the two keys. The keys, in practice, represent a Security. Through cryptographic encryption methods, one shared secret between two or more parties that can be used can prevent a third party from understanding transmitted raw to maintain a private information link [5]. This requirement data over unsecured channel during signal transmission. The that both parties have access to the secret key is one of the cryptographic methods for enhancing the security of digital main drawbacks of symmetric key encryption, in compari- contents have gained high significance in the current era. son to public-key encryption. Typical examples symmetric Breach of security and misuse of confidential information algorithms are Advanced Encryption Standard (AES), Blow- that has been intercepted by unauthorized parties are key fish, Tripple Data Encryption Standard (3DES) and Serpent problems that information security tries to solve. [6]. This paper sets out to contribute to the general body of Asymmetric or Public key encryption on the other hand is an knowledge in the area of classical cryptography by develop- encryption method where a message encrypted with a reci- ing a new hybrid way of encryption of plaintext. -

Automating the Development of Chosen Ciphertext Attacks
Automating the Development of Chosen Ciphertext Attacks Gabrielle Beck∗ Maximilian Zinkus∗ Matthew Green Johns Hopkins University Johns Hopkins University Johns Hopkins University [email protected] [email protected] [email protected] Abstract In this work we consider a specific class of vulner- ability: the continued use of unauthenticated symmet- In this work we investigate the problem of automating the ric encryption in many cryptographic systems. While development of adaptive chosen ciphertext attacks on sys- the research community has long noted the threat of tems that contain vulnerable format oracles. Unlike pre- adaptive-chosen ciphertext attacks on malleable en- vious attempts, which simply automate the execution of cryption schemes [17, 18, 56], these concerns gained known attacks, we consider a more challenging problem: practical salience with the discovery of padding ora- to programmatically derive a novel attack strategy, given cle attacks on a number of standard encryption pro- only a machine-readable description of the plaintext veri- tocols [6,7, 13, 22, 30, 40, 51, 52, 73]. Despite repeated fication function and the malleability characteristics of warnings to industry, variants of these attacks continue to the encryption scheme. We present a new set of algo- plague modern systems, including TLS 1.2’s CBC-mode rithms that use SAT and SMT solvers to reason deeply ciphersuite [5,7, 48] and hardware key management to- over the design of the system, producing an automated kens [10, 13]. A generalized variant, the format oracle attack strategy that can entirely decrypt protected mes- attack can be constructed when a decryption oracle leaks sages. -
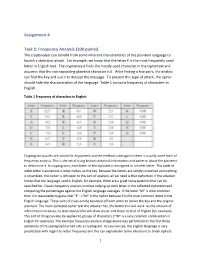
Assignment 4 Task 1: Frequency Analysis (100 Points)
Assignment 4 Task 1: Frequency Analysis (100 points) The cryptanalyst can benefit from some inherent characteristics of the plaintext language to launch a statistical attack. For example, we know that the letter E is the most frequently used letter in English text. The cryptanalyst finds the mostly-used character in the ciphertext and assumes that the corresponding plaintext character is E. After finding a few pairs, the analyst can find the key and use it to decrypt the message. To prevent this type of attack, the cipher should hide the characteristics of the language. Table 1 contains frequency of characters in English. Table 1 Frequency of characters in English Cryptogram puzzles are solved for enjoyment and the method used against them is usually some form of frequency analysis. This is the act of using known statistical information and patterns about the plaintext to determine it. In cryptograms, each letter of the alphabet is encrypted to another letter. This table of letter-letter translations is what makes up the key. Because the letters are simply converted and nothing is scrambled, the cipher is left open to this sort of analysis; all we need is that ciphertext. If the attacker knows that the language used is English, for example, there are a great many patterns that can be searched for. Classic frequency analysis involves tallying up each letter in the collected ciphertext and comparing the percentages against the English language averages. If the letter "M" is most common then it is reasonable to guess that "E"-->"M" in the cipher because E is the most common letter in the English language. -

Chap 2. Basic Encryption and Decryption
Chap 2. Basic Encryption and Decryption H. Lee Kwang Department of Electrical Engineering & Computer Science, KAIST Objectives • Concepts of encryption • Cryptanalysis: how encryption systems are “broken” 2.1 Terminology and Background • Notations – S: sender – R: receiver – T: transmission medium – O: outsider, interceptor, intruder, attacker, or, adversary • S wants to send a message to R – S entrusts the message to T who will deliver it to R – Possible actions of O • block(interrupt), intercept, modify, fabricate • Chapter 1 2.1.1 Terminology • Encryption and Decryption – encryption: a process of encoding a message so that its meaning is not obvious – decryption: the reverse process • encode(encipher) vs. decode(decipher) – encoding: the process of translating entire words or phrases to other words or phrases – enciphering: translating letters or symbols individually – encryption: the group term that covers both encoding and enciphering 2.1.1 Terminology • Plaintext vs. Ciphertext – P(plaintext): the original form of a message – C(ciphertext): the encrypted form • Basic operations – plaintext to ciphertext: encryption: C = E(P) – ciphertext to plaintext: decryption: P = D(C) – requirement: P = D(E(P)) 2.1.1 Terminology • Encryption with key If the encryption algorithm should fall into the interceptor’s – encryption key: KE – decryption key: K hands, future messages can still D be kept secret because the – C = E(K , P) E interceptor will not know the – P = D(KD, E(KE, P)) key value • Keyless Cipher – a cipher that does not require the