Log-Linear Analysis of Contingency Tables: an Introduction for Historians with an Application to Thernstrom on The" Floating Proletariat"
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Art. Music. Games. Life. 16 09
ART. MUSIC. GAMES. LIFE. 16 09 03 Editor’s Letter 27 04 Disposed Media Gaming 06 Wishlist 07 BigLime 08 Freeware 09 Sonic Retrospective 10 Alexander Brandon 12 Deus Ex: Invisible War 20 14 Game Reviews Music 16 Kylie Showgirl Tour 18 Kylie Retrospective 20 Varsity Drag 22 Good/Bad: Radio 1 23 Doormat 25 Music Reviews Film & TV 32 27 Dexter 29 Film Reviews Comics 31 Death Of Captain Marvel 32 Blankets 34 Comic Reviews Gallery 36 Andrew Campbell 37 Matthew Plater 38 Laura Copeland 39 Next Issue… Publisher/Production Editor Tim Cheesman Editor Dan Thornton Deputy Editor Ian Moreno-Melgar Art Editor Andrew Campbell Sub Editor/Designer Rachel Wild Contributors Keith Andrew/Dan Gassis/Adam Parker/James Hamilton/Paul Blakeley/Andrew Revell Illustrators James Downing/Laura Copeland Cover Art Matthew Plater [© Disposable Media 2007. // All images and characters are retained by original company holding.] dm6/editor’s letter as some bloke once mumbled. “The times, they are You may have spotted a new name at the bottom of this a-changing” column, as I’ve stepped into the hefty shoes and legacy of former Editor Andrew Revell. But luckily, fans of ‘Rev’ will be happy to know he’s still contributing his prosaic genius, and now he actually gets time to sleep in between issues. If my undeserved promotion wasn’t enough, we’re also happy to announce a new bi-monthly schedule for DM. Natural disasters and Acts of God not withstanding. And if that isn’t enough to rock you to the very foundations of your soul, we’re also putting the finishing touches to a newDisposable Media website. -
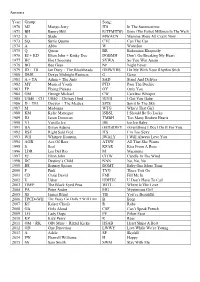
Answers Year: Group: Song: 1970 MJ Mungo Jerry ITS in The
Answers Year: Group: Song: 1970 MJ Mungo Jerry ITS In The Summertime 1971 BH Benny Hill E(TFMITW) Ernie (The Fastest Milkman In The West) 1972 S Slade MWACN Mamma Were All Crazy Now 1973 SQ Suzie Quatro CTC Can The Can 1974 A Abba W Waterloo 1975 Q Queen BR Bohemian Rhapsody 1976 EJ + KD Elton John + Kinky Dee DGBMH Don’t Go Breaking My Heart 1977 HC Hot Chocolate SYWA So You Win Again 1978 BG Bee Gees NF Night Fever 1979 ID + TB Ian Dury + The Blockheads HMWYRS Hit Me With Your Rhythm Stick 1980 DMR Dexys Midnight Runners G Geno 1981 A + TA Adam + The Ants SAD Stand And Deliver 1982 MY Musical Youth PTD Pass The Duchie 1983 FP Flying Pickets OY Only You 1984 GM George Michael CW Careless Whisper 1985 UB40 + CH UB40 + Chrissy Hind IGYB I Got You Babe 1986 D + TM Docyor + The Medics SITS Spirit In The Sky 1987 M Madonna WTG Who’s That Girl 1988 KM Kylie Mynogue ISBSL I Should Be So Lucky 1989 JD Jason Donovan TMBH Too Many Broken Hearts 1990 VI Vanilla Ice IIB Ice Ice Baby 1991 BA Bryan Adams (EID)IDIFY (Everything I Do) I Do It For You 1992 RSF Right Said Fred ITS I’m Too Sexy 1993 WH Whitney Houston IWALY I Will Always Love You 1994 AOB Ace Of Base ATSW All That She Wants 1995 S Seal KFAR Kiss From A Rose 1996 LDR Los Del Rio M Macerena 1997 EJ Elton John CITW Candle In The Wind 1998 DC Destiny’s Child NNN No, No, No 1999 BS Britney Spears BOMT Baby One More Time 2000 P Pink TYG There You Go 2001 CD Craig David FMI Fill Me In 2002 U Usher UDHTC U Don’t Have To Call 2003 TBEP The Black Eyed Peas WITL Where Is The Love 2004 PA Peter Andre -

Chinese Cinderella: the True Story of an Unwanted Daughter
After a while I said, “When did my mama die?” “Your mama came down with a high fever three days after you were born. She died when you were two weeks old. …” Though I was only four years old, I understood I should not ask Aunt Baba too many questions about my dead mama. Big Sister once told me, “Aunt Baba and Mama used to be best friends. A long time ago, they worked together in a bank in Shanghai owned by our grandaunt, the youngest sister of Grandfather Ye Ye. But then Mama died giving birth to you. If you had not been born, Mama would still be alive. She died because of you. You are bad luck.” ALSO AVAILABLE IN LAUREL-LEAF BOOKS: THE HERMIT THRUSH SINGS, Susan Butler BURNING UP, Caroline B. Cooney ONE THOUSAND PAPER CRANES, Takayuki Ishii WHO ARE YOU?, Joan Lowery Nixon HALINKA, Mirjam Pressler TIME ENOUGH FOR DRUMS, Ann Rinaldi CHECKERS, John Marsden NOBODY ELSE HAS TO KNOW, In- grid Tomey TIES THAT BIND, TIES THAT BREAK, Lensey Namioka CONDITIONS OF LOVE, Ruth Pennebaker I have always cherished this dream of creating something unique and imper- ishable, so that the past should not fade away forever. I know one day I shall die and vanish into the void, but hope to preserve my memories through my writing. Perhaps others who were also unwanted children may see them a hundred years from now, and be encouraged. I imagine them opening the pages of my book and meeting me (as a ten-year-old) in Shanghai, without actually having left 6/424 their own homes in Sydney, Tokyo, London, Hong Kong or Los Angeles. -

Topindie[Distribution
TOPINDIE[DISTRIBUTION TRUE FAITH , THE MERCY SEAT 1 1 4 THE ONLY WAYIS UP 17 26 54 35 32 Yazz & Plastic Population Big Life BLR4(T) (I/RT) New Order Factory FAC 183/7 (12''- FAC 183) (P) Nick Cave & The Bad SeedsMute (12)MUTE52 (I/RT/SP) 2 22 THE LOCO -MOTION 18 , THE ONE GAME 36 252 DOUBLESHOT (OF M'( BABY'S LOVE) Kylie Minogue PWL PWL(T)14 (P) Saylon Dola Fly EAGLE 3 (P) Highliners ABC ABCS017(T) (P) SUPERFLY GUY 19 145 HARD TO THECORE 37 484 TELL IT LIKE IT IS 3 3 4 Charly CYZ7124 (CH) S -Express Rhythm King/Mute LEFT28(T) (I/RT) London Rhyme Syndicate Abstract (12)LRS001 (P) Aaron Neville WHAT DIFFERENCE DOES IT MAKE 4 44 DEFCON ONE 20 ED HIJACK THE BEAT 38 36 5 Pop Will Eat Itself Chapter 22 PWEI(12)001 (I/NM) Groove Submission-(SUBX05) (I) The Smiths Rough Trade RT(T)146 (I/RT) 7 PUSH THE BEAT 2 I'VE GOT A FEELING 03 DANCE TO THE RHYTHM 39 22 5 5 Debut DEBT(X)350 (A) De luxe Unyque UNQ3(T) (SP) Base Team Hot Melt (12)TCT16 (P) Mirage LOCK, STOCK & BARREL PEEL SESSIONS VOLUME 2 18 THEME FROMS -EXPRESS 11 4 40 283 THE 6 , 22 Strange Fruit-SFPS033 (P) S -Express Rhythm King/Mute LEFT21(T) (I/RT) Star Turn on 45 Pints Pacific DRINK2 (T) (PAC) Joy Division REALLY NOTHING 3 STAY AWAY 7 914 GOTTO BE CERTAIN 23 5 WILLIAM, IT WAS 41 33 Kylie Minoque PWL PWL(T)12 (P1 The Smiths Rough Trade RT(T)166 (I/RT) Hotline Rhythm King/Mute LEFT24 (T) (I/RT) 8 42 BLUE MONDAY 1988 24 tam DOCTORIN' THE HOUSE Cold Cut featuring 4283 TANGIERS New Order Factory FAC737 (12-FAC 73R) (P) Yazz & Plastic Pop...Ahead Of Our Time CCUT27 (I/Rt) Screaming Trees Native -

KYLIE MINOGUE - the ABBEY ROAD SESSIONS - Release: 29
2012-09-06 14:09 CEST KYLIE MINOGUE - THE ABBEY ROAD SESSIONS - Release: 29. oktober Kylie Minogue fortsætter fejringen af sit 25-års jubilæum med ”The Abbey Road Sessions” “The Abbey Road Sessions” indeholder Kylie Minogues største hits i nye arrangementer, mange med fuldt orkester. Albummet indeholder desuden det ikke-før udgivede nummer ”Flowers”. Kylie Minogue udgiver sit nye album ”The Abbey Road Sessions” på Parlaphone Records den 29. oktober. Albummet indeholder 16 sange, alle radikalt omarrangeret, der spænder over Kylie’s fantastiske 25 årige karriere. Albummet er optaget i det legendariske Abbey Road Studio med Kylie’s band og et fuldt orkester. Nick Cave har geninspillet sin vokal til den berømte duet ”Where The Wild Roses Grow” specielt til dette album. Af andre højdepunkter kan nævnes den fantastisk gribende ”Better The Devil You Know”, den altid fængende ”Confide In Me”, en dampende version af ”On A Night Like This”, en glad ”All The Lovers”, den smukke ”Finer Feelings” og en udgave af ”The Locomotion” der svinger som var vi tilbage i 50’erne. I takt med at man kommer igennem de 16 sange står en ting lysende klart, uden sine popproduktioner står følelserne i Kylie’s sange helt tydeligt frem, det samme gør hendes fantastiske stemme. Trackliste: 1. All The Lovers 2. On A Night Like This 3. Better The Devil You Know 4. Hand On Your Heart 5. I Believe In You 6. Come Into My World 7. Finer Feelings 8. Confide In Me 9. Slow 10. The Locomotion 11. Can’t Get You Out Of My Head 12. -

Največkrat Predvajane Skladbe V Letu 2020 Na Radiu 94
Največkrat predvajane skladbe v letu 2020 na Radiu 94 Mesto Predv. Izvajalec in skladba 1 311 REGARD - RIDE IT 2 259 MAROON 5 - MEMORIES 3 240 ONE REPUBLIC - BETTER DAYS 4 239 TONES AND I - DANCE MONKEY 5 232 ZMELKOOW & JANEZ DOWČ - KAJ NAM FALI(2020) 6 227 TABU - NA KONICAH PRSTOV 7 215 MEDUZA & BECKY HILL & GOODBOYS - LOSE CONTROL 8 212 BILLIE EILISH - BAD GUY 9 205 SAM SMITH & NORMANI - DANCING WITH A STRANGER 10 204 ROLLING STONES - LIVING IN A GHOST TOWN 11 201 LEA SIRK - V DVOJE 12 199 THEORY OF A DEADMAN - SAY NOTHING 13 196 KYGO & WHITNEY HOUSTON - HIGHER LOVE 14 194 LEWIS CAPALDI - BRUISES 15 193 HARRY STYLES - ADORE YOU 16 193 FED HORSES - ZAHODNO DEKLE 17 188 LEVANTE - SIRENE 18 188 TOM WALKER - JUST YOU AND I 19 188 LEA SIRK - PO SVOJE 20 187 BISERI - ZA NJO 21 185 LENNON STELLA & CHARLIE PUTH - SUMMER FEELINGS 22 185 VITAVOX - RAVNO OBRATNO 23 182 NINA PUŠLAR - VČERAJ IN ZA ZMERAJ 24 181 TINKARA KOVAČ - BODI Z MANO DO KONCA 25 181 MARY ROSE - KO TAKO OBJAME 26 177 SOPRANOS - NIMAM SKRBI 27 173 ŠANK ROCK - DVIGNI POGLED 28 168 AVICII & ALOE BLAC - SOS 29 167 GROMEE - LIGHT ME UP 30 165 TOPIC feat. & A7S - BREAKING ME 31 165 MATIC MARENTIČ & V. DIMENZIJA - IZBRIŠI ME S SEZNAMA 32 163 EME & ZEEBA - SAY GOODBYE 33 162 LADY GAGA - STUPID LOVE 34 159 JAN PLESTENJAK - ČLOVEK BREZ IMENA 35 155 VITAVOX - TRIK 36 154 I.C.E. - LAHKO BI BILO LEPO 37 154 AVA MAX - SO AM I 38 151 ROBIN SCHULZ & WES - ALANE 39 150 SCORPIONS - SING OF HOPE 40 148 LOST FREQUENCIES & ZONDERLING - CRAZY 41 147 WEEKND - BLINDING LIGHTS 42 146 JONAS BROTHERS -

TOP HITS of the EIGHTIES by YEAR 1980’S Top 100 Tracks Page 2 of 31
1980’S Top 100 Tracks Page 1 of 31 TOP HITS OF THE EIGHTIES BY YEAR 1980’S Top 100 Tracks Page 2 of 31 1980 01 Frankie Goes To Hollywood Relax 02 Frankie Goes To Hollywood Two Tribes 03 Stevie Wonder I Just Called To Say I Love You 04 Black Box Ride On Time 05 Jennifer Rush The Power Of Love 06 Band Aid Do They Know It's Christmas? 07 Culture Club Karma Chameleon 08 Jive Bunny & The Mastermixers Swing The Mood 09 Rick Astley Never Gonna Give You Up 10 Ray Parker Jr Ghostbusters 11 Lionel Richie Hello 12 George Michael Careless Whisper 13 Kylie Minogue I Should Be So Lucky 14 Starship Nothing's Gonna Stop Us Now 15 Elaine Paige & Barbara Dickson I Know Him So Well 16 Kylie & Jason Especially For You 17 Dexy's Midnight Runners Come On Eileen 18 Billy Joel Uptown Girl 19 Sister Sledge Frankie 20 Survivor Eye Of The Tiger 21 T'Pau China In Your Hand 22 Yazz & The Plastic Population The Only Way Is Up 23 Soft Cell Tainted Love 24 The Human League Don't You Want Me 25 The Communards Don't Leave Me This Way 26 Jackie Wilson Reet Petite 27 Paul Hardcastle 19 28 Irene Cara Fame 29 Berlin Take My Breath Away 30 Madonna Into The Groove 31 The Bangles Eternal Flame 32 Renee & Renato Save Your Love 33 Black Lace Agadoo 34 Chaka Khan I Feel For You 35 Diana Ross Chain Reaction 36 Shakin' Stevens This Ole House 37 Adam & The Ants Stand And Deliver 38 UB40 Red Red Wine 1980’S Top 100 Tracks Page 3 of 31 39 Boris Gardiner I Want To Wake Up With You 40 Soul II Soul Back To Life 41 Whitney Houston Saving All My Love For You 42 Billy Ocean When The Going -

Jay Bectenstein Ja Y and 1Py Ro 6Yray on Tour This Summer! EYE Cofltag
POP ROCK R & B RAP DANCE COUNTRY LATIN USIC CLASSICAL JAll PRO AUDIO Minogue Travels `Light Years' On EMI Love leaps From Major Label Globe - Trotting Artist Returns To DancelPop Sound To Rounder's Zoë For `14 Days' BY LARRY FLICK Loco-Motion," "I Should Be So Lucky," BBC Radio 1 and Radio 2 since pro- BY JIM BESSMAN es,' " she continues. "But they went NEW YORK-With the June 19 and "Better The Devil You Know" mos of the track were shipped May 14. NEW YORK-Where other artists ahead and put it out, even while release of her hotly touted new EMI/ "My writing was all from the gut, The commercial pressing of the might regret losing a major -label heads were rolling around [during Parlophone U.K. single, "Spinning very stream -of- consciousness," she single will feature the non -album cuts deal, Seattle singer/songwriter the Universal restructuring], and Around," Kylie Minogue ends a brief adds of "Impossible Princess." "I "Cover Me With Kisses" and "Paper Laura Love, who was signed to Mer- three months later they let us go. I modern -rock flirtation and revisits think I've gotten stronger and more Dolls." "It's a single that fans are cury Records after winning a loyal think they felt like they were giving the infectious dance/pop sound of her focused since that album." truly clamoring for," says Rob Glen- fan base with her self- described us a soft landing -when I don't give '80s heyday. Although the label is still confirm- dale, manager of Blue, an indie retail- "Afro- Celtic" self-released albums, a shit." Produced by up-and -coming Vien- ing the track listing for "Light Years," er in London. -

The Seven Ages of Kylie Minogue: Postmodernism, Identity, and Performative Mimicry
Northumbria Research Link Citation: Barron, Lee (2008) The seven ages of Kylie Minogue: postmodernism, identity, and performative mimicry. Nebula, 5 (4). pp. 46-63. ISSN 1449-7751 Published by: Nebula URL: This version was downloaded from Northumbria Research Link: http://nrl.northumbria.ac.uk/id/eprint/2463/ Northumbria University has developed Northumbria Research Link (NRL) to enable users to access the University’s research output. Copyright © and moral rights for items on NRL are retained by the individual author(s) and/or other copyright owners. Single copies of full items can be reproduced, displayed or performed, and given to third parties in any format or medium for personal research or study, educational, or not-for-profit purposes without prior permission or charge, provided the authors, title and full bibliographic details are given, as well as a hyperlink and/or URL to the original metadata page. The content must not be changed in any way. Full items must not be sold commercially in any format or medium without formal permission of the copyright holder. The full policy is available online: http://nrl.northumbria.ac.uk/policies.html This document may differ from the final, published version of the research and has been made available online in accordance with publisher policies. To read and/or cite from the published version of the research, please visit the publisher’s website (a subscription may be required.) Nebula 5.4 , December 2008 The Seven Ages of Kylie Minogue: Postmodernism, Identity, and Performative Mimicry. By Lee Barron God’s in his heaven, Kylie’s at number one, surely nothing really bad can happen (Bryan Appleyard, the Sunday Times , cited in Smith 187). -

1 Nr Artiest Titel
NR ARTIEST TITEL 1 PRINCE & THE REVOLUTION PURPLE RAIN 2 MICHAEL JACKSON THRILLER 3 QUEEN & DAVID BOWIE UNDER PRESSURE 4 TOTO AFRICA 5 GUNS N' ROSES SWEET CHILD OF MINE 6 A-HA TAKE ON ME 7 U2 SUNDAY BLOODY SUNDAY 8 PHIL COLLINS IN THE AIR TONIGHT 9 JOURNEY DON'T STOP BELIEVIN' 10 DURAN DURAN THE REFLEX 11 BRUCE SPRINGSTEEN BORN IN THE USA 12 QUEEN A KIND OF MAGIC 13 GUNS N' ROSES PARADISE CITY 14 ALAN PARSONS PROJECT OLD AND WISE 15 THE CURE A FOREST 16 EUROPE THE FINAL COUNTDOWN 17 BON JOVI LIVIN' ON A PRAYER 18 ANDRÉ HAZES ZIJ GELOOFT IN MIJ 19 QUEEN RADIO GA GA 20 MADONNA LIKE A PRAYER 21 PINK FLOYD ANOTHER BRICK IN THE WALL 22 ABBA THE WINNER TAKES IT ALL 23 MICHAEL JACKSON BILLIE JEAN 24 ALICE COOPER POISON 25 PAUL SIMON YOU CAN CALL ME AL 26 QUEEN I WANT TO BREAK FREE 27 U2 WITH OR WITHOUT YOU 28 ACDC BACK IN BLACK 29 THE POLICE EVERY LITTLE THING SHE DOES IS MAGIC 30 DIRE STRAITS BROTHERS IN ARMS 31 ROLLING STONES START ME UP 32 TALK TALK SUCH A SHAME 33 GEORGE MICHAEL FAITH 1 NR ARTIEST TITEL 34 VANDENBERG BURNING HEART 35 DOE MAAR 32 JAAR (SINDS EEN DAG OF 2) 36 AEROSMITH LOVE IN AN ELEVATOR 37 ANITA MEYER WHY TELL ME WHY 38 SIMPLE MINDS DON'T YOU (FORGET ABOUT ME) 39 BILLY OCEAN WHEN THE GOING GETS TOUGH, THE TOUGH GETS GOING 40 VAN HALEN JUMP 41 U2 PRIDE (IN THE NAME OF LOVE) 42 ABC THE LOOK OF LOVE 43 SURVIVOR EYE OF THE TIGER 44 TOTO STOP LOVING YOU 45 SALT-N-PEPA PUSH IT 46 KLEIN ORKEST OVER DE MUUR 47 ZZ TOP GIMME ALL YOUR LOVIN' 48 MICHAEL JACKSON SMOOTH CRIMINAL 49 DIRE STRAITS PRIVATE INVESTIGATIONS 50 PAT BENATAR LOVE -

Mud, Yurts and Music: It Must Be Glastonbury!
Did you know? Mud, yurts and music: It must be Glastonbury! For the last 45 years on the last weekend in June, dairy farmer Michael Eavis has hosted what is now the world’s biggest pop festival on Worthy farm in Somerset. The cows are moved to other quarters, the multiple stages are erected and the thronging crowds are welcomed. Most of the biggest names in pop music have played at Glastonbury at some point over its 45-year history, from David Bowie to Dolly Parton and Paul MacCartney to Beyoncé. The Rolling Stones, U2, Coldplay, Jay Z, Dizzee Rascal – even the heavy metal band Metallica has headlined. Last year there were 2,200 performers on over 100 stages. There was live music (in all its infinite variety); there were DJ’s, political speakers, circus acts, magicians, philosophers, children’s entertainers, poets, stand-up comedians, healers, dancers, storytellers and puppeteers - a veritable cornucopia of artists. The Worthy farm site is located at Pilton about seven miles from the town of Glastonbury and not far from the famous Tor. The festival site is set across 1,200 acres in the mystical Vale of Avalon, so trying to cross the site when the thousands of festival-goers are in attendance can take hours. Weather can also hinder progress around the site. It seems that most years there is a downfall which creates the now familiar pictures of water-logged fields and campsites and festival-goers trying to remain cheerful while wading through muddy bogs in Wellingtons. The Glastonbury music festival has changed beyond all recognition from its inception in 1970, when tickets cost just £1 (including free milk from Eavis’s cows) and just 1,500 people attended. -

Demon Music Group Karaoke Song Book
Demon Music Group Karaoke Songs by Artist Karaoke Shack Song Books Title DiscID Title DiscID 10cc ABBA Deadlock Holiday DMG100052-01 Summer Night City DMG100148-4- -06 14 Dreadlock Holiday DMG100062-03 Take A Chance On Me DMG100148-1- -14 01 Dreadlock Holiday DMG100072-04 Take A Chance On Me DMG100150-1- -04 15 Dreadlock Holiday DMG100150-5- Thank You For The Music DMG100149-1- 06 20 2 Unlimited Voulez Vous DMG100148-2- No Limit DMG100070-03 10 -16 Waterloo DMG100044-03 2Pac & Elton John -04 Ghetto Gospel DMG100073-05 Waterloo DMG100148-4- -06 18 50 Cent AC-DC In Da Club DMG100073-05 Highway To Hell DMG100042-02 -05 -04 A1 Highway To Hell DMG100148-5- Take On Me DMG100074-03 01 -13 Whole Lotta Rosie DMG100151-5- ABBA 19 Chiquitita DMG100148-2- Ace Of Base 19 All That She Wants DMG100043-05 Dancing Queen DMG100022-05 -10 -11 All That She Wants DMG100070-05 Dancing Queen DMG100043-02 -01 -10 All That She Wants DMG100150-4- Dancing Queen DMG100052-04 13 -05 Always Have, Always Will DMG100152-2- Dancing Queen DMG100075-03 14 -18 Adam & The Ants Dancing Queen DMG100150-1- Stand And Deliver DMG100041-02 20 -05 Fernando DMG100150-4- Stand And Deliver DMG100074-03 16 -12 Gimme Gimme Gimme (A Man After Midnight) DMG100043-04 Adele -01 Chasing Pavements DMG100043-01 Knowing Me Knowing You DMG100148-2- -07 14 Chasing Pavements DMG100071-05 Knowing Me Knowing You DMG100150-5- -12 17 Aerosmith Lay All Your Love On Me DMG100149-2- I Don't Want To Miss A Thing DMG100022-04 13 -19 Mamma Mia DMG100044-01 I Don't Want To Miss A Thing DMG100042-05 -02 -01