January 2019
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Geographical Study of Trends in Sex Ratio of Gondia District of Maharashtra State
Volume 5, Issue 5, May – 2020 International Journal of Innovative Science and Research Technology ISSN No:-2456-2165 A Geographical Study of Trends in Sex Ratio of Gondia District of Maharashtra State Ankitkumar N. Jaiswal Rajani A. Chaturvedi Research Student, Head and Associate Professor R.T.M. Nagpur University, P.G. Department of Geography, N.M.D. College, Gondia, Nagpur, India Maharashtra, India Abstract:- In assessing the quality of life and levels of decades. Also, lot of variation was observed in rural and development of a particular region sex ratio plays pivotal urban sex ratio in Gondia District. role. It also influences the other population characteristics such as migration, occupation structure, Number of females per 1000 males in the age group 0- volume and nature of social need and employment. In 6 years is termed as Child Sex ratio. In India there has been the present study, the spatio-temporal variations in the a decreasing trend of the Child sex ratio after independence. sex ratio of Gondia District of Maharashtra State were The main reason behind this disturbing fact is due to the son analyzed using secondary sources of data. Also, light was preference in the society. Although the child sex ratio of shed on child sex ratio. The sex ratio of Gondia district Gondia district showed decrease but it was at lower rate. was always higher than that of the Maharashtra state from year 1901 to 2011 whereas child sex ratio turned II. OBJECTIVES out to be very low. Gondia is among those districts which show the trend of higher sex ratio over decades. -

Action Plan for Development of Fisheries and Aquaculture
Action Plan Funded by Vidarbha Development Board, Nagpur Development of Fisheries and Aquaculture in Vidarbha Funded by Vidarbha Development Board, Nagpur Submitted by College of Fishery Science, Nagpur (Maharashtra Animal and Fishery Sciences University) Funding Agency : Vidarbha Development Board, Nagpur Project Team Principal Investigator : Shri. Sachin W. Belsare Assistant Professor, College of Fishery Science, Nagpur Co-Principal Investigator : Dr. Prashant A. Telvekar Dr. Satyajit S. Belsare Shri. Shamkant T. Shelke Dr. J.G.K. Pathan Shri Rajiv H. Rathod Shri. Sagar A. Joshi Shri. Shailendra S. Relekar Shri. Umesh A. Suryawanshi Assistance by : Shri. Swapnil S. Ghatge Assistant Professor, College of Fishery Science, Udgir Shri. Durgesh R. Kende and Shri. Vitthal S. Potre Technical Assistant, VDB Scheme, College of Fishery Science, Nagpur Technical help : Maharashtra Remote Sensing Application Centre (MRSAC), VNIT Campus, South Ambazari Road, VNIT Campus, Nagpur, Maharashtra 440011 Support : Hon’ble Divisional Commissioner, Civil Lines, Nagpur Vidarbha Development Board, South Ambazari Road, Nagpur The Commissioner of Fisheries, Mumbai, Maharashtra & Regional Deputy Commissioner of Fisheries, Nagpur & Amravati Division Maharashtra Fisheries Development Corporation Ltd. Mumbai & MFDC, Regional Office, Nagpur District Fisheries Federation, Nagpur & Amravati Division Fisheries Co-operative Societies, Nagpur & Amravati Division OFFICE OF THE DIVISIONAL COMMISSIONER, NAGPUR Old Secretariat Building, Civil Lines, Nagpur 440001 Tel. : 0712-2562132, E-mail : [email protected] Fax : 2532043 Message Government of Maharashtra has adopted the Blue Revolution policy of GOI. The Key objective of Blue revolution is to achieve an additional production of 5 million tonnes of fish production by the end of 2020, by enhancing the fish production from the fresh waters. -

Gondia District at a Glance 1
GONDIA DISTRICT AT A GLANCE 1. GENERAL INFORMATION Geographical Area 5858.95 sq. km. Administrative Divisions Taluka- 8, Gondia, Goregaon, (As on 31/03/20011) Tiroda, Arjuni Moregaon, Deori, Amgaon, Salekasa, Sadak Arjuni Villages 994 Population (2011) 1,32,2331 Normal Annual Rainfall 1300 to 1500 mm 2. GEOMORPHOLOGY Major Physiographic unit Two: Structural units like hills and ridges, denudational units like pediments and fluvial units Major Drainage One: Wainganga River and its tributaries like Bagh, Chulbandh, Panghodi Suz, Gadhavi, Chandan, Bavanthadi 3. LAND USE (2010-11) Forest Area 2151.15 sq.km Cultivable Area 2967.47 sq.km Net Area Sown 1608.09 sq.km 4. SOIL TYPE The main types of soils are Kali, Kankar, Morand, Khardi, Sihar and Bardi 5. PRINCIPAL CROPS (2010-11) (Net area sown) Rice 1726.30 sq.km Total Pulses 932.20 sq.km Total Oil Seeds 67.26 sq.km Wheat 38.16 sq.km 6. IRRIGA TION BY DIFFERENT SOURCES (2006-07) (Nosl Potential Created in ha) Dugwells 9480/13480 Borewells 308/485 Tanks & Ponds 2505/67146 Other Minor Surface Sources 491/2835 Area under Surface water irrigation 67049 Area under Ground water irrigation 31511 7. GROUND WATER MONITORING WELLS (May 2011) Dugwells 26 Piezometers 2 8. GEOLOGY Recent Alluvium and Laterite Proterozoic (Vindhyan, Dongargarh, Quartzite and Shale, Andesite, Sausar and Sakoli Super Group) Sandstone, Granite, Rhyolite; Mu scovite-b iotite-sch ist, Granite, Tirodi Gneiss; Schist, Phyllites, Quartzite. i Archeans (Amgaon Super Group) Granite & Gneisses. 9. HYDROGEOLOGY Water Bearing Formation Weathered Granite & Gneisses Pre-monsoon Depth to Water Level 0.55 to 12.60 m bgl (May-2011) (May - 2011) Post-monsoon Depth to Water Level 0.60 to 7.70 m bgl (Nov-2011) (November - 2011) Pre-monsoon Water Level Trend Rise: 0.0186 to 0.6656 m/year (2001-2010) Fall: 0.0038 to 0.9321 m/year Post-monsoon water level trend Rise: 0.0028 to 0.1814 m/year (2001-2010) Fall: 0.0015 to 0.1842 m/year 10. -

Gondia District Maharashtra
1795/DBR/2010 भारत सरकार जल संसाधन मंत्रालय कᴂ द्रीय भूजल बो셍ड GOVT OF INDIA MINISTRY OF WATER RESOURCES CENTRAL GROUND WATER BOARD महाराष्ट्र रा煍य के अंत셍डत 셍ⴂदिया जजले की भूजल विज्ञान जानकारी GROUND WATER INFORMATION GONDIA DISTRICT MAHARASHTRA By 饍िारा M.R.K. REDDY एम. आर. के . रे蕍डी Scientist-B वैज्ञानिक – ख म鵍य क्षेत्र, ना셍परु CENTRAL REGION NAGPUR 2013 GONDIA DISTRICT AT A GLANCE 1. GENERAL INFORMATION Geographical Area 5858.95 sq. km. Administrative Divisions Taluka- 8, Gondia, Goregaon, (As on 31/03/20011) Tiroda, Arjuni Moregaon, Deori, Amgaon, Salekasa, Sadak Arjuni Villages 994 Population (2011) 1,32,2331 Normal Annual Rainfall 1300 to 1500 mm 2. GEOMORPHOLOGY Major Physiographic unit Two: Structural units like hills and ridges, denudational units like pediments and fluvial units Major Drainage One: Wainganga River and its tributaries like Bagh, Chulbandh, Panghodi Suz, Gadhavi, Chandan, Bavanthadi 3. LAND USE (2010-11) Forest Area 2151.15 sq.km Cultivable Area 2967.47 sq.km Net Area Sown 1608.09 sq.km 4. SOIL TYPE The main types of soils are Kali, Kankar, Morand, Khardi, Sihar and Bardi 5. PRINCIPAL CROPS (2010-11) (Net area sown) Rice 1726.30 sq.km Total Pulses 932.20 sq.km Total Oil Seeds 67.26 sq.km Wheat 38.16 sq.km 6. IRRIGA TION BY DIFFERENT SOURCES (2006-07) (Nosl Potential Created in ha) Dugwells 9480/13480 Borewells 308/485 Tanks & Ponds 2505/67146 Other Minor Surface Sources 491/2835 Area under Surface water irrigation 67049 Area under Ground water irrigation 31511 7. -

Egap DISTRICT-CENTRIC 161-193 AUDIT
CHAPTER-IV Page DISTRICT-CENTRIC 161-193 AUDIT 4.1 District-centric Audit of Gondia CHAPTER IV Planning Department 4.1 District centric audit of Gondia Highlights Recognising the importance accorded by the Planning Commission, Government of India for a district-centric approach to devolution of finances for integrated local area development, a district-centric audit of Gondia district was carried out to assess the status and impact of implementation of various socio-economic developmental activities in the district during 2006-11. The review covered key social sector programmes relating to health, education, water supply, social welfare and economic sector programs relating to creation of roads, employment generation and poverty alleviation , provision of basic amenities to the public etc. Some of the significant findings are as follows: The District Planning Committee had not prepared a five year perspective plan or an integrated district plan covering all the activities for overall development of the district (Paragraph 4.1.6) There was lack of facilities and skilled manpower in the health institutions. (Paragraph 4.1.8.1) In the education sector despite huge expenditure on the Mid-Day Meal scheme the objective of increasing enrolment in primary and upper primary schools could not be achieved and the drop-out increased. (Paragraph 4.1.8.2) Water supply schemes were not put to use as Gram Panchayats did not take them over. (Paragraph 4.1.8.3) The housing sector served by Indira Awas Yojana suffered due to non-completion of work. (Paragraph 4.1.8.4) There was short-utilization of foodgrains under the Public Distribution System. -

Research Bulletin
www.icmai.in Peer - Reviewed Quarterly Journal RESEARCH BULLETIN THE INSTITUTE OF COST ACCOUNTANTS OF INDIA Statutory Body under an Act of Parliament ISSN 2230 9241 Volume 44 No. IV January 2019 The CMA professionals would ethically drive enterprises tatement globally by creating value to stakeholders in the socio- economic context through competencies drawn from the integration of strategy, Mission S management and accounting. The Institute of Cost Accountants of India would be the preferred source of resources and professionals for the financial leadership of enterprises globally. tatement Vision S Behind Every Successful Business Decision, there is always a CMA www.icmai.in RESEARCH BULLETIN THE INSTITUTE OF COST ACCOUNTANTS OF INDIA Statutory Body under an Act of Parliament ISSN 2230 9241 Volume 44 No. IV January 2019 Disclaimer The Instute assumes no responsibility for any act of copying or reproducon, whether fully or parally, of any write up/esearch paper which is not the original work of the author. The write up/research papers published in good faith on the basis of declaraon furnished by the authors. All rights reserved. No part of this publicaon may be used or reproduced in any manner whatsoever without permission in wring from The Instute of Cost Accountants of India. Price of Single Copy : ` 400.00 only Annual Subscripon (for four volumes) : ` 1200.00 p.a. Courier Charges : ` 200.00 p.a. for four volumes Month of Publicaon : January, 2019 © 2019 The Instute of Cost Accountants of India Printed and Published by CMA Amit Anand Apte President The Instute of Cost Accountants of India 12 Sudder Street, Kolkata - 700016 Foreword ndia has a diversified financial sector undergoing rapid expansion, both in terms of strong growth of existing financial services firms and new entities entering I the market. -

S.No Office / Location of Commissionerate Name & Address of the Appellate Authority S/Shri Name & Address of the CPIO S
OFFICE OF THE CHIEF COMMISSIONER, CUSTOMS & CENTRAL EXCISE, NAGPUR ZONE, NAGPUR Post Box No. 81, Telengkhedi Road, Civil Lines, Nagpur. Ph.No 0712- 2561887 Fax No 0712- 2561795 E-mail: [email protected] , [email protected] S.No Office / Location of Commissionerate Name & address of the Appellate Name & address of the CPIO Jurisdiction Authority S/Shri S/Shri. 1 Office of the Chief Commissioner of Customs & Shri.S.P.Mishra, Additional Commissioner, Shri.H.S. Mahajan, Assistant Matter relating to Central Excise, Central Excise , Nagpur Zone, Chief Commissioner Unit, Nagpur Zone, Commissioner, Chief Commissioner Customs and Service tax jurisdiction Post Box.No.81, Telengkhedi Road, Civil Lines, Telengkhedi Road, Civil Lines, Unit, Nagpur Zone, Telengkhedi of Nagpur , Nasik and Aurangabad Nagpur- 440 001 Nagpur- 440 001 Road, Civil Lines, Commissionerate Phone No.0712-2561571 Nagpur- 440 001 Email [email protected] Phone No.0712-2557103 Email [email protected] 2 Office of the Commissioner (Appeal) of Customs & Shri S.P.Mishra, AdditionalCommissioner, Shri.M.P. Jadhav, Assistant Matters relating to Central Excise , Telengkhedi Road, Civil Lines, Central Excise Hqrs., Telengkhedi Road, Civil Commissioner, Commissioner (Appeals),Nagpur Nagpur- 440 001 Lines, C.Excise,Hars,Telengkhedi Road, Nagpur-440 001 Civil Lines, Phone No.0712-2561571 Nagpur- 440 001 Email : [email protected] Phone No.0712-2557103 Email [email protected] 3. Office of the Commissioner (Appeal) of Customs & Shri C.M. Choudhary Shri S.K.Bhate Matters relating to Commissioner Central Excise , Kendriya Rajaswa Bhawan, Gadkari Additional Commissioner, Assistant Commissioner and Ms. (Appeals), Nasik Chowk, Central Excise & Customs , U.A. -

District Survey Report for Sand Mining Or River Bed Mining
Draft DSR Report for Gondia DISTRICT SURVEY REPORT FOR SAND MINING OR RIVER BED MINING Prepared by District Mining Officer Collector Office, Gondia Prepared Under A] Appendix –X Of MoEFCC, GoI. Notification S.O. 141(E) Dated 15.1.2016 B] Sustainable Sand Mining Guidelines C] MoEFCC, GoI. Notification S.O. 3611(E) Dated 25.07.2018 DISTRICT-GONDIA MAHARASHTRA PREFACE With reference to the gazette notification dated 15th January 2016, ministry of Environment, Forest and Climate Change, the State environment Impact Assessment Authority (SEIAA) and State Environment Assessment Committee (SEAC) are to be constituted by the divisional commissioner for prior environmental clearance of quarry for minor minerals. The SEIAA and SEAC will scrutinize and recommend the prior environmental clearance of ministry of minor minerals on the basis of district survey report. The main purpose of preparation of District Survey Report is to identify the mineral resources and mining activities along with other relevant data of district. This report contains details of Lease, Sand mining and Revenue which comes from minerals in the district. This report is prepared on the basis of data collected from different concern departments. A survey is carried out by the members of DEIAA with the assistance of Geology Department or Irrigation Department or Forest Department or Public Works Department or Ground Water Boards or Remote Sensing Department or Mining Department etc. in the district. Minerals are classified into two groups, namely (i) Major minerals and (ii) Minor minerals. Amongst these two groups minor mineral have been defined under section 3(e) of Mines and Minerals (Regulation and development) Act, 1957. -

Isolation and Identification of Soil Mycoflora in Agricultural Field of Sadak Arjuni of Gondia District (Ms)
I J R B A T, Issue (VI), Vol. III, 2018: 132-138 e-ISSN 2347 – 517X INTERNATIONAL JOURNAL OF RESEARCHES IN BIOSCIENCES, AGRICULTURE AND TECHNOLOGY © VISHWASHANTI MULTIPURPOSE SOCIETY (Global Peace Multipurpose Society) R. No. MH-659/13(N) www.ijrbat.in ISOLATION AND IDENTIFICATION OF SOIL MYCOFLORA IN AGRICULTURAL FIELD OF SADAK ARJUNI OF GONDIA DISTRICT (MS) Sunil M. Akare Department of Botany, Manoharbhai Patel College, SadakArjuni, Dist. Gondia (MS) – 441807 E-mail: [email protected] ABSTRACT: Soil samples were collected from different locations of Sadak Arjuni of Gondia District during the months of February 2014 to January 2015 in three intervals. The samples collected in two zones viz. rhizoplane and rhizosphere. The collected samples were inoculated in Potato Dextrose Agar (PDA) and CzapekDox Agar (CDA) medium supplemented by antibiotics such as penicillin and Streptomycin by using Serial dilution method and soil plate method. A total of 230 colonies were isolated. About 19 species belonging to 7 genera of fungi were isolated and identified while 21 strains were unidentified. Identification and characterization of the soil mycoflora were made with the help of authentic manuals of soil fungi. Maximum number of fungal colonies belonged to Ascomycotina and Deutero mycotina (191) and few to zygomycotina (18). Among the isolates Aspergillus flavus, A. fumigatus, A. nidulans, A.niger, A.terreus, Fusarium oxysporum, Penicillium chrysogenum, Rhizopusstolonifer and Trichoderma viridae were predominant. The percentile contribution of the mycoflora was graphically and statistically analyzed. Keywords: Microfungi, Culture Media, Isolation, Fungal Diversity. INTRODUCTION: environment. Unfortunately their degradative ability Soils are extremely complex structures with also results in the undesirable growth of fungi that many constituents playing diverse functions mainly destroy useful materials (Aina et al., 2011). -

Brief Industrial Profile of Gondia District
Government of India Ministry of MSME Brief Industrial Profile of Gondia District Carried out by MSME- Development Institute (Ministry of MSME, Govt. of India,) CGO Complex, Block ‘C’, Seminary Hills, Nagpur-440006 Phone: 0712-2510046, 2510352 Fax: 0712- 2511985 e-mail:[email protected] Web- msmedinagpur.gov.in 1 Contents S. Topic Page No. No. 1. General Characteristics of the District 5 1.1 Location & Geographical Area 5 1.2 Topography 5-7 1.3 Availability of Minerals. 7 1.4 Forest 8 1.5 Administrative set up 8 2. District at a glance 8-10 2.1 Existing Status of Industrial Area in the District Gondia 11 3. Industrial Scenario Of Gondia 12 3.1 Industry at a Glance 12 3.2 Year Wise Trend Of Units Registered 12-13 3.3 Details Of Existing Micro & Small Enterprises & Artisan Units In 14-17 The District 3.4 Large Scale Industries / Public Sector undertakings 17 3.5 Major Exportable Item 17 3.6 Growth Trend 18-20 3.7 Vendorisation / Ancillarisation of the Industry 20 3.8 Medium Scale Enterprises 20 3.8.1 List of the units in Gondia & nearby Area 20 3.8.2 Major Exportable Item 20 3.9 Service Enterprises 20 3.9.2 Potentials areas for service industry 20 2 3.10 Potential for new MSMEs 21 4. Existing Clusters of Micro & Small Enterprise 21 5. General issues raised by industry association during the course of 22 meeting 6 Steps to set up MSMEs 22 7. Additional Information if any 23 3 4 Brief Industrial Profile of Gondia District 1. -

Rashtrasant Tukadoji Maharaj Nagpur University
a Ccc RASHTRASANT TUKADOJI MAHARAJ NAGPUR UNIVERSITY “(Established by Government of Central Provinces Education Department by Notification No.513 dated the 1st of August, 1923 & presently a State University governed by Maharashtra Universities Act, 1994.)” : NOTIFICATION : No.: RTMNU/Ph.D. (Cell)/1/2077 Dated : 06 November, 2015 It is notified for general information that the following candidates are hereby declared eligible for the award of Ph.D./M.E. By Research Degree in the faculty mentioned against their respective names: Sr. Name and Address of Candidate Date of Date of Degree Faculty Subject Title of Thesis Name and Address of No. Registration Thesis/ Supervisor Treatise Submission 1. 2. 3. 4. 5. 6. 7. 8. 1. Shri Laxmikant Niranjan Barde 06.01.2008 10.08.2012 Ph.D. Medicine Pharmaceutical “Development of Molecular Dr. V.B. Mathur Ram Nagar Sciences Imprinted Polymers as Novel Drug Sharad Pawar College of Balaji Society Delivery System and Usage for Pharmacy Yavatmal Removal of Certain Unwanted Wanadongri Hingna Road Materials in Animals” Nagpur 2. Shri Kuldeep Pundlik Waidya 15.07.2008 08.08.2012 Ph.D. Medicine Pharmaceutical “Development of Sustained Dr. N.J. Gaikwad At Post – Kosamtondi Sciences Release Beads by Ionotropic Dept. of Pharmaceutical Tal. – Sadak Arjuni Gelation Technique and its Sciences Dist. – Gondia Evaluation” Rashtrasant Tukadoji Maharaj Nagpur University Nagpur Page 1 of 20 3. Smt. Archana Ratkanthiwar Re. 17.10.2014 Ph.D. Home Human “Intelligence, Problem Solving Dr. Nilima Sinha 61-A, Satya Sai Niwas 16.10.2009 Science Development and Reasoning Ability as a Dept. of Home Science Ramna Maroti Nagar Function of Personality Type” Vasantrao Naik Institute of Near Nandanvan Arts & Social Sciences Nagpur Nagpur 4. -
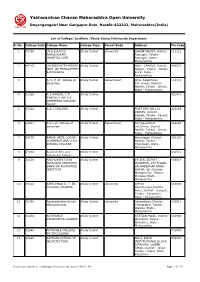
Yashwantrao Chavan Maharashtra Open University
Yashwantrao Chavan Maharashtra Open University Dnyangangotri Near Gangapur Dam, Nashik-422222, Maharashtra(India) List of College/ Institute /Study Center/University Department Sr.No. College Code College Name College Type Parent Body Address Pin Code 1 7375A (M.E.S.A.M.'S) Study Center University GHANE KHUNT, District - 111111 PARASHURAM Ratnagiri, Taluka - HOSPITAL LOTE Ratnagiri, State - Maharashtra 2 44210 (NYSSE)DATTA MEGHE Study Center POLY. CAMPUS, District - 440022 INST. OF MANAGEMENT Nagpur, Taluka - Nagpur & RESEARCH Rural, State - Maharashtra 3 A. V. E. W. College of Study Center Government At/p- Agaskhind, 111111 Education Tal- sinnar, District - Nashik, Taluka - Sinnar, State - Maharashtra 4 5502A A.S MANDAL C/O Study Center 425416 SANCHLIT ARTS & COMMERCE COLLEGE TRUST 5 3202A A.S.C.COLLEGE, Study Center POST BOX NO.124 410206 PANVEL, District - Raigad, Taluka - Panvel, State - Maharashtra 6 54297 A.V.E.W. College of Study Center Government A/P-Agaskhind 422502 Education Tal-Sinnar, District - Nashik, Taluka - Sinnar, State - Maharashtra 7 54179 AABAD ARTS, LODHA Study Center Neminagar, District - 423101 COMMERCE AND S.P.D. Nashik, Taluka - SURANA COLLEGE Chandwad, State - Maharashtra 8 8703A Aadarsh Arts and Study Center 431513 Commerce College 9 31128 AADHUNEEK DYAN Study Center 19-206, SIDHAT 400014 PRASARAK SHIKSHAN MANSHAN, 1ST FLOOR, SANSTHA ADDROTISE DR.AMBEDKAR ROAD, INSTITUTE DADAR (W), District - Mumbai City, Taluka - Mumbai, State - Maharashtra 10 65124 AAHILYABAI D. T. ED. Study Center University A/P 68 413006