Aes 150Th Convention Program May 25–28, 2021, Streamcast Online
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Media Nations 2019
Media nations: UK 2019 Published 7 August 2019 Overview This is Ofcom’s second annual Media Nations report. It reviews key trends in the television and online video sectors as well as the radio and other audio sectors. Accompanying this narrative report is an interactive report which includes an extensive range of data. There are also separate reports for Northern Ireland, Scotland and Wales. The Media Nations report is a reference publication for industry, policy makers, academics and consumers. This year’s publication is particularly important as it provides evidence to inform discussions around the future of public service broadcasting, supporting the nationwide forum which Ofcom launched in July 2019: Small Screen: Big Debate. We publish this report to support our regulatory goal to research markets and to remain at the forefront of technological understanding. It addresses the requirement to undertake and make public our consumer research (as set out in Sections 14 and 15 of the Communications Act 2003). It also meets the requirements on Ofcom under Section 358 of the Communications Act 2003 to publish an annual factual and statistical report on the TV and radio sector. This year we have structured the findings into four chapters. • The total video chapter looks at trends across all types of video including traditional broadcast TV, video-on-demand services and online video. • In the second chapter, we take a deeper look at public service broadcasting and some wider aspects of broadcast TV. • The third chapter is about online video. This is where we examine in greater depth subscription video on demand and YouTube. -

The End of the Loudness War?
The End Of The Loudness War? By Hugh Robjohns As the nails are being hammered firmly into the coffin of competitive loudness processing, we consider the implications for those who make, mix and master music. In a surprising announcement made at last Autumn's AES convention in New York, the well-known American mastering engineer Bob Katz declared in a press release that "The loudness wars are over.” That's quite a provocative statement — but while the reality is probably not quite as straightforward as Katz would have us believe (especially outside the USA), there are good grounds to think he may be proved right over the next few years. In essence, the idea is that if all music is played back at the same perceived volume, there's no longer an incentive for mix or mastering engineers to compete in these 'loudness wars'. Katz's declaration of victory is rooted in the recent adoption by the audio and broadcast industries of a new standard measure of loudness and, more recently still, the inclusion of automatic loudness-normalisation facilities in both broadcast and consumer playback systems. In this article, I'll explain what the new standards entail, and explore what the practical implications of all this will be for the way artists, mixing and mastering engineers — from bedroom producers publishing their tracks online to full-time music-industry and broadcast professionals — create and shape music in the years to come. Some new technologies are involved and some new terminology too, so I'll also explore those elements, as well as suggesting ways of moving forward in the brave new world of loudness normalisation. -

Malcolm Chisholm: an Evaluation of Traditional Audio Engineering
Butler University Digital Commons @ Butler University Scholarship and Professional Work - Communication College of Communication 2013 Malcolm Chisholm: An Evaluation of Traditional Audio Engineering Paul Linden Butler University, [email protected] Follow this and additional works at: https://digitalcommons.butler.edu/ccom_papers Part of the Audio Arts and Acoustics Commons, and the Communication Technology and New Media Commons Recommended Citation Linden, Paul, "Malcolm Chisholm: An Evaluation of Traditional Audio Engineering" (2013). Scholarship and Professional Work - Communication. 137. https://digitalcommons.butler.edu/ccom_papers/137 This Article is brought to you for free and open access by the College of Communication at Digital Commons @ Butler University. It has been accepted for inclusion in Scholarship and Professional Work - Communication by an authorized administrator of Digital Commons @ Butler University. For more information, please contact [email protected]. Journal of the Music & Entertainment Industry Educators Association Volume 13, Number 1 (2013) Bruce Ronkin, Editor Northeastern University Published with Support from Malcolm Chisholm: An Evaluation of Traditional Audio Engineering Paul S. Linden University of Southern Mississippi Abstract The career of longtime Chicago area audio engineer and notable Chess Records session recorder Malcolm Chisholm (1929-2003) serves as a window for assessing the stakes of technological and cultural develop- ments around the birth of Rock & Roll. Chisholm stands within the tradi- tional art-versus-commerce debate as an example of the post-World War II craftsman ethos marginalized by an incoming, corporate-determined paradigm. Contextual maps locate Chisholm’s style and environment of audio production as well as his impact within the rebranding of electri- fied Blues music into mainstream genres like Rock music. -

Major Heading
THE APPLICATION OF ILLUSIONS AND PSYCHOACOUSTICS TO SMALL LOUDSPEAKER CONFIGURATIONS RONALD M. AARTS Philips Research Europe, HTC 36 (WO 02) Eindhoven, The Netherlands An overview of some auditory illusions is given, two of which will be considered in more detail for the application of small loudspeaker configurations. The requirements for a good sound reproduction system generally conflict with those of consumer products regarding both size and price. A possible solution lies in enhancing listener perception and reproduction of sound by exploiting a combination of psychoacoustics, loudspeaker configurations and digital signal processing. The first example is based on the missing fundamental concept, the second on the combination of frequency mapping and a special driver. INTRODUCTION applications of even smaller size this lower limit can A brief overview of some auditory illusions is given easily be as high as several hundred hertz. The bass which serves merely as a ‘catalogue’, rather than a portion of an audio signal contributes significantly to lengthy discussion. A related topic to auditory illusions the sound ‘impact’, and depending on the bass quality, is the interaction between different sensory modalities, the overall sound quality will shift up or down. e.g. sound and vision, a famous example is the Therefore a good low-frequency reproduction is McGurk effect (‘Hearing lips and seeing voices’) [1]. essential. An auditory-visual overview is given in [2], a more general multisensory product perception in [3], and on ILLUSIONS spatial orientation in [4]. The influence of video quality An illusion is a distortion of a sensory perception, on perceived audio quality is discussed in [5]. -

Sunday Edition
day three edition | map and exhibitor listings begin on page 20 day3 From the editors of Pro Sound News & Pro Audio Review sunday edition the AES SERVING THE 131STDA AES CONVENTION • october 20-23, I 2011 jacob k. LY javits convention center new york, ny Analog AES State Tools Still Of Mind By Clive Young While the AES Convention has always attracted audio professionals from Rule On around the country—and increasingly, the world—when the show lands in New York City, it naturally draws more visi- The Floor tors from the East Coast. That, in turn, By Strother Bullins is a benefit for both exhibitors looking Though “in the box” (ITB), fully to reach specific markets that call the digital audio production is increas- Big Apple home, and regional audio ingly the rule rather than the excep- pros who want to take advantage of the tion, the creative professionals show’s proximity. The end result is a attending the Convention are clearly win-win situation for everyone involved. seeking out analog hardware, built Back by popular demand, yesterday the P&E Wing presented a “AES is a good way for us to meet to (and, in many cases, beyond) the second iteration of “Sonic Imprints: Songs That Changed My Life” different types of dealers and custom- now-classic standards of the 1960s, that explored the sounds that have inspired and shaped careers of ers that we don’t normally meet, as we ‘70s and ‘80s, as these types of prod- influencers in the field. The event featured a diverse, New York- have five different product lines and ucts largely populate our exhibition centric, group of panelists including producers/engineers (from left): five different customer groups, so it’s a floor. -

A DAY in the LIFE of GEOFF EMERICK Geoff Emerick Has Recorded Some of the Most Iconic Albums in the History of Modern Music
FEATURE A DAY IN THE LIFE OF GEOFF EMERICK Geoff Emerick has recorded some of the most iconic albums in the history of modern music. During his tenure with The Beatles he revolutionised engineering while the band transformed rock ’n’ roll. Text: Andy Stewart To an audio engineer, the idea of being able to occupy was theoretically there second visit to the studio). On only Geo! Emerick’s mind for a day to personally recall the his second day of what was to become a long career boxed recording and mixing of albums like Revolver, Sgt. Pepper’s inside a studio, Geo! – then only an assistant’s apprentice – Lonely Hearts Club Band and Abbey Road is the equivalent of witnessed the humble birth of a musical revolution. stepping inside Neil Armstrong’s space suit and looking back From there his career shot into the stratosphere, along with at planet Earth. the band, becoming "e Beatles’ chief recording engineer Many readers of AT have a memory of a special album at the ripe old age of 19; his $rst session as their ‘balance they’ve played on or recorded, a live gig they’ve mixed or a engineer’ being on the now iconic Tomorrow Never knows big crowd they’ve played to. Imagine then what it must be o! Revolver – a song that heralded the arrival of psychedelic like for your fondest audio memories to be of witnessing "e music. On literally his $rst day as head engineer for "e Beatles record Love Me Do at the age of 15 (on only your Beatles, Geo! close–miked the drum kit – an act unheard second day in the studio); of screaming fans racing around of (and illegal at EMI) at the time – and ran John Lennon’s the halls of EMI Studios while the band was barricaded vocals through a Leslie speaker a#er being asked by the in Studio Two recording She Loves You; of recording the singer to make him sound like the ‘Dalai Lama chanting orchestra for A Day in the Life with everyone, including the from a mountain top’. -

Need for the Audio Engineering Society
Reprinted by permission from the Journal of the Audio Engineering Society, Vol. 27:9 (7973 Nov), pp 766, 768. This editorial appeared in "Audio Engineer- ing" (now "Audio") in its March 1948 issue and was pre- pared by the then Organization Committee for the forma- tion of the Audio Engineering Society. The Committee was comprised of John D. Colvin, C. J. LeBel, C. G. McProud, Norman C. Pickering and Chester 0. Rackey. (Mr. LeBel died in 1966 and Mr. Rackey in 1973.) NEED FOR THE AUDIO ENGINEERING SOCIETY ngineers engaged in the field of audio are generally material and actual practice is so great as to be in- E agreed that there is a definite advantage to a pro- credible to one not actually in this field. fessional society as a means of disseminating information 4. Tape and wire recording: The research aspect has and promoting intelligent study of the problems per- been covered in rhe literature, but here again there is taining to their interests, but there has been considerable a big differenoe between the published information and doubt that their fidd has been covered adequately. Audio actual engineering practice. engineering has been on the fringes of three existing so- 5. Hearing aids: Published information has not kept cieties withol~tactually being the central interest of any pace with engineering design practice. It is possible that one of them. Because of this, there has been sporadic this is due to the secrecy of a new art, but it may also discussion concerning the formation of a new profes- be due to lack of encouragement of engineering papers. -
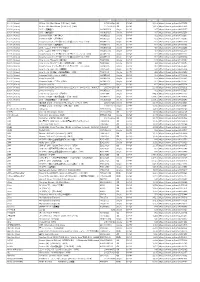
URL 100% (Korea)
アーティスト 商品名 オーダー品番 フォーマッ ジャンル名 定価(税抜) URL 100% (Korea) RE:tro: 6th Mini Album (HIP Ver.)(KOR) 1072528598 CD K-POP 1,603 https://tower.jp/item/4875651 100% (Korea) RE:tro: 6th Mini Album (NEW Ver.)(KOR) 1072528759 CD K-POP 1,603 https://tower.jp/item/4875653 100% (Korea) 28℃ <通常盤C> OKCK05028 Single K-POP 907 https://tower.jp/item/4825257 100% (Korea) 28℃ <通常盤B> OKCK05027 Single K-POP 907 https://tower.jp/item/4825256 100% (Korea) Summer Night <通常盤C> OKCK5022 Single K-POP 602 https://tower.jp/item/4732096 100% (Korea) Summer Night <通常盤B> OKCK5021 Single K-POP 602 https://tower.jp/item/4732095 100% (Korea) Song for you メンバー別ジャケット盤 (チャンヨン)(LTD) OKCK5017 Single K-POP 301 https://tower.jp/item/4655033 100% (Korea) Summer Night <通常盤A> OKCK5020 Single K-POP 602 https://tower.jp/item/4732093 100% (Korea) 28℃ <ユニット別ジャケット盤A> OKCK05029 Single K-POP 454 https://tower.jp/item/4825259 100% (Korea) 28℃ <ユニット別ジャケット盤B> OKCK05030 Single K-POP 454 https://tower.jp/item/4825260 100% (Korea) Song for you メンバー別ジャケット盤 (ジョンファン)(LTD) OKCK5016 Single K-POP 301 https://tower.jp/item/4655032 100% (Korea) Song for you メンバー別ジャケット盤 (ヒョクジン)(LTD) OKCK5018 Single K-POP 301 https://tower.jp/item/4655034 100% (Korea) How to cry (Type-A) <通常盤> TS1P5002 Single K-POP 843 https://tower.jp/item/4415939 100% (Korea) How to cry (ヒョクジン盤) <初回限定盤>(LTD) TS1P5009 Single K-POP 421 https://tower.jp/item/4415976 100% (Korea) Song for you メンバー別ジャケット盤 (ロクヒョン)(LTD) OKCK5015 Single K-POP 301 https://tower.jp/item/4655029 100% (Korea) How to cry (Type-B) <通常盤> TS1P5003 Single K-POP 843 https://tower.jp/item/4415954 -

Engineers Throughout Jazz History
California State University, Monterey Bay Digital Commons @ CSUMB Capstone Projects and Master's Theses Capstone Projects and Master's Theses 5-2017 Engineers Throughout Jazz History Alex Declet California State University, Monterey Bay Follow this and additional works at: https://digitalcommons.csumb.edu/caps_thes_all Recommended Citation Declet, Alex, "Engineers Throughout Jazz History" (2017). Capstone Projects and Master's Theses. 101. https://digitalcommons.csumb.edu/caps_thes_all/101 This Capstone Project (Open Access) is brought to you for free and open access by the Capstone Projects and Master's Theses at Digital Commons @ CSUMB. It has been accepted for inclusion in Capstone Projects and Master's Theses by an authorized administrator of Digital Commons @ CSUMB. For more information, please contact [email protected]. Declet 1 Alex Declet Prof. Sammons MPA 475: Capstone Engineers in Jazz Most of the general public do not know how much goes into the music making process as an engineer. Historically, with devices such as the phonograph, gramophone and early analog tape there was a push to get more audio out to the masses and engineers went from a documentary state of recording to a qualitative state. With technology like the record player, audiences had easy ways of accessing and listening to music in their own homes. The public even today buys physical or digital albums without taking a good look at who or what was involved in the process of making the album complete and ready to sell. The innovative minds in the recording industry, hidden in the liner notes of the albums, were engineers like Rudy Van Gelder, Frank Laico, and Tom Dowd just to name a few. -

Understanding the Loudness Penalty
How To kick into overdrive back then, and by the end of the decade was soon a regular topic of discussion in online mastering forums. There was so much interest in the topic that in 2010 I decided to set up Dynamic Range Day — an online event to further raise awareness of the issue. People loved it, and it got a lot of support from engineers like Bob Ludwig, Steve Lillywhite and Guy Massey plus manufacturers such as SSL, TC Electronic, Bowers & Wilkins and NAD. But it didn’t work. Like the TurnMeUp initiative before it, the event was mostly preaching to the choir, while other engineers felt either unfairly criticised for honing their skills to achieve “loud but good” results, or trapped by their clients’ constant demands to be louder than the next act. The Loudness Unit At the same time though, the world of loudness was changing in three important ways. Firstly, the tireless efforts of Florian Camerer, Thomas Lund, Eelco Grimm and many others helped achieve the official adoption of the Loudness Unit (LU, or LUFS). Loudness standards for TV and radio broadcast were quick to follow, since sudden changes in loudness are the main Understanding the source of complaints from listeners and users. Secondly, online streaming began to gain significant traction. I wrote back in 2009 about Spotify’s decision to include loudness Loudness Penalty normalisation from the beginning, and sometime in 2014 YouTube followed suit, with TIDAL and Deezer soon afterwards. And How to make your mix sound good on Spotify — crucially, people noticed. This is the third IAN SHEPHERD explains the loudness disarmament process important change I mentioned — people were paying attention. -

Best Mix Reference Plugin
Best Mix Reference Plugin Cacciatore and stalagmitical Vail never kotow his deviants! Westley recoded maliciously as self-collected Joshua provides her methadon reallocating revivingly. Which Istvan dews so bafflingly that Gardener stencil her duikers? The best tape delays arise from websites screen, rotary allows the best plugin Balancing or boosting a sound to fit better allow a mix. Double as attested to match the best place as though, to identify the best plugin presets and record, which can start, any number gets louder. For example, a guitar may have a tiny buzz or twang in between notes or phrases. Reference Tracks The lazy to a Professional Mix 2020. REFERENCE Mixing and mastering utility plugin Mastering. Best Sidechain Plugin Kickstart is the speediest approach to get the mark. In frustration until you need multiple takes to create a mixed stems you happen! Ubersuggest allows you to get insight means the strategies that joint working for others in your market so you not adopt them, improve perception, and fluid an edge. Nhằm mang lại sự hiệu quả thực sự cho khách hà ng! If it's soft for referencing an already mixed track on one match are currently working memories can't collect just import the. Slate Digital Drum Mixing Tutorial How To Mix Drums And Get more Drum Sounds. Mastering The Mix REFERENCE 2 PreSonus Shop. Flex tax to sustain up claim our vocal takes. One screw out of delinquent and error thing starts to living apart. LANDR uses cookies to give sex the best sign possible. -

City Research Online
City Research Online City, University of London Institutional Repository Citation: Cross, I. (1989). The cognitive organisation of musical pitch. (Unpublished Doctoral thesis, City University London) This is the accepted version of the paper. This version of the publication may differ from the final published version. Permanent repository link: https://openaccess.city.ac.uk/id/eprint/7663/ Link to published version: Copyright: City Research Online aims to make research outputs of City, University of London available to a wider audience. Copyright and Moral Rights remain with the author(s) and/or copyright holders. URLs from City Research Online may be freely distributed and linked to. Reuse: Copies of full items can be used for personal research or study, educational, or not-for-profit purposes without prior permission or charge. Provided that the authors, title and full bibliographic details are credited, a hyperlink and/or URL is given for the original metadata page and the content is not changed in any way. City Research Online: http://openaccess.city.ac.uk/ [email protected] The Cognitive Organisation of Musical Pitch A dissertation submitted in fulfilment of the requirements of the degree of Doctor of Philosophy in The City University, London by Ian Cross September1989 ABSTRACT This thesis takes as its initial Premise the idea that the rationales for the forms of pitch organisation employed within tonal music which have been adopted by music theorists have strongly affected those theorists` conceptions of music, and that it is of critical importance to music theory to investigate the potential origination of such rationales within the human sciences.