14.2 Denoising Autoencoders
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

AN279: Estimating Period Jitter from Phase Noise
AN279 ESTIMATING PERIOD JITTER FROM PHASE NOISE 1. Introduction This application note reviews how RMS period jitter may be estimated from phase noise data. This approach is useful for estimating period jitter when sufficiently accurate time domain instruments, such as jitter measuring oscilloscopes or Time Interval Analyzers (TIAs), are unavailable. 2. Terminology In this application note, the following definitions apply: Cycle-to-cycle jitter—The short-term variation in clock period between adjacent clock cycles. This jitter measure, abbreviated here as JCC, may be specified as either an RMS or peak-to-peak quantity. Jitter—Short-term variations of the significant instants of a digital signal from their ideal positions in time (Ref: Telcordia GR-499-CORE). In this application note, the digital signal is a clock source or oscillator. Short- term here means phase noise contributions are restricted to frequencies greater than or equal to 10 Hz (Ref: Telcordia GR-1244-CORE). Period jitter—The short-term variation in clock period over all measured clock cycles, compared to the average clock period. This jitter measure, abbreviated here as JPER, may be specified as either an RMS or peak-to-peak quantity. This application note will concentrate on estimating the RMS value of this jitter parameter. The illustration in Figure 1 suggests how one might measure the RMS period jitter in the time domain. The first edge is the reference edge or trigger edge as if we were using an oscilloscope. Clock Period Distribution J PER(RMS) = T = 0 T = TPER Figure 1. RMS Period Jitter Example Phase jitter—The integrated jitter (area under the curve) of a phase noise plot over a particular jitter bandwidth. -

Signal-To-Noise Ratio and Dynamic Range Definitions
Signal-to-noise ratio and dynamic range definitions The Signal-to-Noise Ratio (SNR) and Dynamic Range (DR) are two common parameters used to specify the electrical performance of a spectrometer. This technical note will describe how they are defined and how to measure and calculate them. Figure 1: Definitions of SNR and SR. The signal out of the spectrometer is a digital signal between 0 and 2N-1, where N is the number of bits in the Analogue-to-Digital (A/D) converter on the electronics. Typical numbers for N range from 10 to 16 leading to maximum signal level between 1,023 and 65,535 counts. The Noise is the stochastic variation of the signal around a mean value. In Figure 1 we have shown a spectrum with a single peak in wavelength and time. As indicated on the figure the peak signal level will fluctuate a small amount around the mean value due to the noise of the electronics. Noise is measured by the Root-Mean-Squared (RMS) value of the fluctuations over time. The SNR is defined as the average over time of the peak signal divided by the RMS noise of the peak signal over the same time. In order to get an accurate result for the SNR it is generally required to measure over 25 -50 time samples of the spectrum. It is very important that your input to the spectrometer is constant during SNR measurements. Otherwise, you will be measuring other things like drift of you lamp power or time dependent signal levels from your sample. -

Image Denoising by Autoencoder: Learning Core Representations
Image Denoising by AutoEncoder: Learning Core Representations Zhenyu Zhao College of Engineering and Computer Science, The Australian National University, Australia, [email protected] Abstract. In this paper, we implement an image denoising method which can be generally used in all kinds of noisy images. We achieve denoising process by adding Gaussian noise to raw images and then feed them into AutoEncoder to learn its core representations(raw images itself or high-level representations).We use pre- trained classifier to test the quality of the representations with the classification accuracy. Our result shows that in task-specific classification neuron networks, the performance of the network with noisy input images is far below the preprocessing images that using denoising AutoEncoder. In the meanwhile, our experiments also show that the preprocessed images can achieve compatible result with the noiseless input images. Keywords: Image Denoising, Image Representations, Neuron Networks, Deep Learning, AutoEncoder. 1 Introduction 1.1 Image Denoising Image is the object that stores and reflects visual perception. Images are also important information carriers today. Acquisition channel and artificial editing are the two main ways that corrupt observed images. The goal of image restoration techniques [1] is to restore the original image from a noisy observation of it. Image denoising is common image restoration problems that are useful by to many industrial and scientific applications. Image denoising prob- lems arise when an image is corrupted by additive white Gaussian noise which is common result of many acquisition channels. The white Gaussian noise can be harmful to many image applications. Hence, it is of great importance to remove Gaussian noise from images. -

Active Noise Control Over Space: a Subspace Method for Performance Analysis
applied sciences Article Active Noise Control over Space: A Subspace Method for Performance Analysis Jihui Zhang 1,* , Thushara D. Abhayapala 1 , Wen Zhang 1,2 and Prasanga N. Samarasinghe 1 1 Audio & Acoustic Signal Processing Group, College of Engineering and Computer Science, Australian National University, Canberra 2601, Australia; [email protected] (T.D.A.); [email protected] (W.Z.); [email protected] (P.N.S.) 2 Center of Intelligent Acoustics and Immersive Communications, School of Marine Science and Technology, Northwestern Polytechnical University, Xi0an 710072, China * Correspondence: [email protected] Received: 28 February 2019; Accepted: 20 March 2019; Published: 25 March 2019 Abstract: In this paper, we investigate the maximum active noise control performance over a three-dimensional (3-D) spatial space, for a given set of secondary sources in a particular environment. We first formulate the spatial active noise control (ANC) problem in a 3-D room. Then we discuss a wave-domain least squares method by matching the secondary noise field to the primary noise field in the wave domain. Furthermore, we extract the subspace from wave-domain coefficients of the secondary paths and propose a subspace method by matching the secondary noise field to the projection of primary noise field in the subspace. Simulation results demonstrate the effectiveness of the proposed algorithms by comparison between the wave-domain least squares method and the subspace method, more specifically the energy of the loudspeaker driving signals, noise reduction inside the region, and residual noise field outside the region. We also investigate the ANC performance under different loudspeaker configurations and noise source positions. -

Noise Reduction Through Active Noise Control Using Stereophonic Sound for Increasing Quite Zone
Noise reduction through active noise control using stereophonic sound for increasing quite zone Dongki Min1; Junjong Kim2; Sangwon Nam3; Junhong Park4 1,2,3,4 Hanyang University, Korea ABSTRACT The low frequency impact noise generated during machine operation is difficult to control by conventional active noise control. The Active Noise Control (ANC) is a destructive interference technic of noise source and control sound by generating anti-phase control sound. Its efficiency is limited to small space near the error microphones. At different locations, the noise level may increase due to control sounds. In this study, the ANC method using stereophonic sound was investigated to reduce interior low frequency noise and increase the quite zone. The Distance Based Amplitude Panning (DBAP) algorithm based on the distance between the virtual sound source and the speaker was used to create a virtual sound source by adjusting the volume proportions of multi speakers respectively. The 3-Dimensional sound ANC system was able to change the position of virtual control source using DBAP algorithm. The quiet zone was formed using fixed multi speaker system for various locations of noise sources. Keywords: Active noise control, stereophonic sound I-INCE Classification of Subjects Number(s): 38.2 1. INTRODUCTION The noise reduction is a main issue according to improvement of living condition. There are passive and active control methods for noise reduction. The passive noise control uses sound absorption material which has efficiency about high frequency. The Active Noise Control (ANC) which is the method for generating anti phase control sound is able to reduce low frequency. -

AN-839 RMS Phase Jitter
RMS Phase Jitter AN-839 APPLICATION NOTE Introduction In order to discuss RMS Phase Jitter, some basics phase noise theory must be understood. Phase noise is often considered an important measurement of spectral purity which is the inherent stability of a timing signal. Phase noise is the frequency domain representation of random fluctuations in the phase of a waveform caused by time domain instabilities called jitter. An ideal sinusoidal oscillator, with perfect spectral purity, has a single line in the frequency spectrum. Such perfect spectral purity is not achievable in a practical oscillator where there are phase and frequency fluctuations. Phase noise is a way of describing the phase and frequency fluctuation or jitter of a timing signal in the frequency domain as compared to a perfect reference signal. Generating Phase Noise and Frequency Spectrum Plots Phase noise data is typically generated from a frequency spectrum plot which can represent a time domain signal in the frequency domain. A frequency spectrum plot is generated via a Fourier transform of the signal, and the resulting values are plotted with power versus frequency. This is normally done using a spectrum analyzer. A frequency spectrum plot is used to define the spectral purity of a signal. The noise power in a band at a specific offset (FO) from the carrier frequency (FC) compared to the power of the carrier frequency is called the dBc Phase Noise. Power Level of a 1Hz band at an offset (F ) dBc Phase Noise = O Power Level of the carrier Frequency (FC) A Phase Noise plot is generated using data from the frequency spectrum plot. -

Noise Element
10 NOISE ELEMENT A. Introduction Noise is defined as a sound or series of sounds that are considered to be inva- sive, irritating, objectionable, and/or disruptive to the quality of daily life. Noise varies in range and volume and can originate from individual incidents such as construction equipment, sporadic disturbances, such as car horns or train whistles, or more constant irritants, such as traffic along major arterials. Section 65302(f) of the California Government Code requires that General Plans contain a Noise Element that can be used as a guide for establishing a pattern of land uses that minimizes the exposure of community residents to excessive noise. Local governments are required to analyze and quantify noise levels and the extent of noise exposure through field measurements or noise modeling, and implement measures and possible solutions to existing and foreseeable noise problems. This section describes the existing noise environment in Los Gatos and is di- vided into the following sections: ♦ Introduction: A description of the scope, requirements, and contents of the Noise Element. ♦ Noise Background and Terminology: A description of noise issues, stan- dards, and terminology used to describe noise. ♦ Noise Standards: A summary of outdoor noise limits established by Los Gatos. ♦ Sources of Existing Noise: A summary of the sources of noise, including stationary, non-stationary, and construction noise sources. ♦ Future Noise Contours: A description of projected noise conditions in Los Gatos at General Plan buildout. ♦ Goals, Policies, and Actions: A list of goal, policy, and action statements that are intended to mitigate and reduce noise impacts in Los Gatos. -
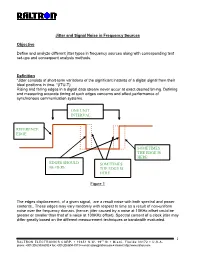
Jitter and Signal Noise in Frequency Sources
Jitter and Signal Noise in Frequency Sources Objective Define and analyze different jitter types in frequency sources along with corresponding test set-ups and consequent analysis methods. Definition “Jitter consists of short-term variations of the significant instants of a digital signal from their ideal positions in time. “(ITU-T) Rising and falling edges in a digital data stream never occur at exact desired timing. Defining and measuring accurate timing of such edges concerns and affect performance of synchronous communication systems. ONE UNIT INTERVAL REFERENCE EDGE SOMETIMES THE EDGE IS HERE EDGES SHOULD SOMETIMES BE HERE THE EDGE IS HERE Figure 1 The edges displacement, of a given signal, are a result noise with both spectral and power contents.. These edges may vary randomly with respect to time as a result of non-uniform noise over the frequency domain. (hence; jitter caused by a noise at 10KHz offset could be greater or smaller than that of a noise at 100KHz offset). Spectral content of a clock jitter may differ greatly based on the different measurement techniques or bandwidth evaluated. 1 RALTRON ELECTRONICS CORP. ! 10651 N.W. 19th St ! Miami, Florida 33172 ! U.S.A. phone: +001(305) 593-6033 ! fax: +001(305)594-3973 ! e-mail: [email protected] ! internet: http://www.raltron.com System Disruptions caused by Jitter Clock recovery mechanisms, in network elements, are used to sample the digital signal using the recovered bit clock. If the digital signal and the clock have identical jitter, the constant jitter error will not affect the sampling instant and therefore no bit errors will arise. -

USP Signal-To-Noise in Empower 2
TECN10123052 Rev. 01 Page 1 of 8 USP Signal-to-Noise in Empower 2 This Technical Note explains Waters’ interpretation of the new USP signal-to-noise (S/N) calculation and presents a choice of implementations using custom field calculations. It contains the following topics: • Discussion of USP Signal-to-Noise Definition • Differences between USP Signal-to-Noise and European Pharmacopeia Signal-to-Noise • Using a Custom Field to determine USP Signal-to-Noise by Making a Blank Injection (the preferred approach) • Using a Custom Field to determine USP Signal-to-Noise Within one Chromatogram • Generic Signal-to-Noise Determination in Empower 2 Discussion of USP Signal-to-Noise Definition Until recently, the USP had not formalized their definition of Signal-to-Noise (S/N). Effective December 2009, the USP 32 standard defines it as follows: S/N = 2H/h where: H = Height of the peak corresponding to the component concerned. h = Difference between the largest and smallest noise values observed over a distance equal to at least five times the width at the half-height of the peak and, if possible, situated equally around the peak of interest. Effective in 2011 with the USP 34 standard, USP added a diagram (Figure 1) to their S/N definition. Figure 1 –USP Signal-to-Noise Determination TECN10123052 Rev. 01 Page 2 of 8 The USP definition states that noise is “the difference between the largest and smallest noise values…” While this measurement as described is simple, it does not compensate for local systematic drift. It is assumed that the noise measurement should account for drift. -

Ultra-Broadband Local Active Noise Control with Remote Acoustic Sensing
www.nature.com/scientificreports OPEN Ultra‑broadband local active noise control with remote acoustic sensing Tong Xiao *, Xiaojun Qiu & Benjamin Halkon One enduring challenge for controlling high frequency sound in local active noise control (ANC) systems is to obtain the acoustic signal at the specifc location to be controlled. In some applications such as in ANC headrest systems, it is not practical to install error microphones in a person’s ears to provide the user a quiet or optimally acoustically controlled environment. Many virtual error sensing approaches have been proposed to estimate the acoustic signal remotely with the current state‑ of‑the‑art method using an array of four microphones and a head tracking system to yield sound reduction up to 1 kHz for a single sound source. In the work reported in this paper, a novel approach of incorporating remote acoustic sensing using a laser Doppler vibrometer into an ANC headrest system is investigated. In this “virtual ANC headphone” system, a lightweight retro‑refective membrane pick‑up is mounted in each synthetic ear of a head and torso simulator to determine the sound in the ear in real‑time with minimal invasiveness. The membrane design and the efects of its location on the system performance are explored, the noise spectra in the ears without and with ANC for a variety of relevant primary sound felds are reported, and the performance of the system during head movements is demonstrated. The test results show that at least 10 dB sound attenuation can be realised in the ears over an extended frequency range (from 500 Hz to 6 kHz) under a complex sound feld and for several common types of synthesised environmental noise, even in the presence of head motion. -

Don't Replace Your Windows. . .Soundproof Them. Reduce Noise
Don’t replace your windows. .Soundproof them. Reduce Noise Levels by 75% to 95%. Create REAL peace and quiet. What is it? A soundproof window is a second window placed behind your existing window that opens and closes just like your existing window. We do not remove or replace your existing window. Acoustically engineered to stop sound, it offers most of the benefits of dual-paned replacement windows and several benefits not available with replacement windows. o Absolutely Stops the Noise Reduces noise levels by 75% and more - much more than any dual-paned replacement window. You will be amazed how dramatic the improvement is!! oThe Best Insulation Available Our two window system provides better insulation than any one window system. Our windows insulate better than ANY dual-paned window. Simply the best insulating windows available - period! o Removes 99.9% of color-fading UV light Museum-quality protection for the harmful effects of UV light. Prevents the color-fading caused by ultraviolet light. UV light is often considered to be a health hazard that causes skin cancer and more. o Peace & Quiet - Lowered Stress - Better Health Stay home and enjoy "the peace and quiet of the countryside". Escape to the quiet surroundings of your own home, instead of only on weekend getaways and vacations. Noise causes restless sleep, higher stress levels, and can easily lead to hearing loss and other long-term health risks. More and more is being discovered about the harmful effects of even moderate noise levels in your home and work environment. ©2008 SOUNDPROOF WINDOWS, Inc. -

Active Noise Control System Based on the Improved Equation Error Model
acoustics Article Active Noise Control System Based on the Improved Equation Error Model Jun Yuan 1, Jun Li 1, Anfu Zhang 2, Xiangdong Zhang 2,* and Jia Ran 3,* 1 Department of Microelectronics Engineering, Chongqing University of Posts and Telecommunications, Chongqing 400065, China; [email protected] (J.Y.); [email protected] (J.L.) 2 Wuhan Second Ship Design and Research Institute, Wuhan 430064, China; [email protected] 3 Department of Electromagnetic Field and Wireless, Chongqing University of Posts and Telecommunications, Chongqing 400065, China * Correspondence: [email protected] (X.Z.); [email protected] (J.R.) Abstract: This paper presents an algorithm structure for an active noise control (ANC) system based on an improved equation error (EE) model that employs the offline secondary path modeling method. The noise of a compressor in a gas station is taken as an example to verify the performance of the proposed ANC system. The results show that the proposed ANC system improves the noise reduction performance and convergence speed compared with other typical ANC systems. In particular, it achieves 28 dBA noise attenuation at a frequency of about 250 Hz and a mean square error (MSE) of about −20 dB. Keywords: active noise control; improved equation error; mean square error 1. Introduction Citation: Yuan, J.; Li, J.; Zhang, A.; Zhang, X.; Ran, J. Active Noise In order to reduce acoustic noise in workplaces and living environments, passive Control System Based on the and active approaches [1] have been employed. For passive approaches, the energy of the Improved Equation Error Model. noise is absorbed by dampers, barriers, mufflers, or sonic crystals [1–4].