OMG: Open Molecule Generator
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Postulated Physiological Roles of the Seven-Carbon Sugars, Mannoheptulose, and Perseitol in Avocado
J. AMER. SOC. HORT. SCI. 127(1):108–114. 2002. Postulated Physiological Roles of the Seven-carbon Sugars, Mannoheptulose, and Perseitol in Avocado Xuan Liu,1 James Sievert, Mary Lu Arpaia, and Monica A. Madore2 Department of Botany and Plant Sciences, University of California, Riverside, CA 92521 ADDITIONAL INDEX WORDS. ‘Hass’ avocado on ‘Duke 7’ rootstock, phloem transport, ripening, Lauraceae ABSTRACT. Avocado (Persea americana Mill.) tissues contain high levels of the seven-carbon (C7) ketosugar mannoheptulose and its polyol form, perseitol. Radiolabeling of intact leaves of ‘Hass’ avocado on ‘Duke 7’ rootstock indicated that both perseitol and mannoheptulose are not only primary products of photosynthetic CO2 fixation but are also exported in the phloem. In cell-free extracts from mature source leaves, formation of the C7 backbone occurred by condensation of a three-carbon metabolite (dihydroxyacetone-P) with a four-carbon metabolite (erythrose-4-P) to form sedoheptulose-1,7- bis-P, followed by isomerization to a phosphorylated D-mannoheptulose derivative. A transketolase reaction was also observed which converted five-carbon metabolites (ribose-5-P and xylulose-5-P) to form the C7 metabolite, sedoheptu- lose-7-P, but this compound was not metabolized further to mannoheptulose. This suggests that C7 sugars are formed from the Calvin Cycle, not oxidative pentose phosphate pathway, reactions in avocado leaves. In avocado fruit, C7 sugars were present in substantial quantities and the normal ripening processes (fruit softening, ethylene production, and climacteric respiration rise), which occurs several days after the fruit is picked, did not occur until levels of C7 sugars dropped below an apparent threshold concentration of ≈20 mg·g–1 fresh weight. -

PENTOSE PHOSPHATE PATHWAY — Restricted for Students Enrolled in MCB102, UC Berkeley, Spring 2008 ONLY
Metabolism Lecture 5 — PENTOSE PHOSPHATE PATHWAY — Restricted for students enrolled in MCB102, UC Berkeley, Spring 2008 ONLY Bryan Krantz: University of California, Berkeley MCB 102, Spring 2008, Metabolism Lecture 5 Reading: Ch. 14 of Principles of Biochemistry, “Glycolysis, Gluconeogenesis, & Pentose Phosphate Pathway.” PENTOSE PHOSPHATE PATHWAY This pathway produces ribose from glucose, and it also generates 2 NADPH. Two Phases: [1] Oxidative Phase & [2] Non-oxidative Phase + + Glucose 6-Phosphate + 2 NADP + H2O Ribose 5-Phosphate + 2 NADPH + CO2 + 2H ● What are pentoses? Why do we need them? ◦ DNA & RNA ◦ Cofactors in enzymes ● Where do we get them? Diet and from glucose (and other sugars) via the Pentose Phosphate Pathway. ● Is the Pentose Phosphate Pathway just about making ribose sugars from glucose? (1) Important for biosynthetic pathways using NADPH, and (2) a high cytosolic reducing potential from NADPH is sometimes required to advert oxidative damage by radicals, e.g., ● - ● O2 and H—O Metabolism Lecture 5 — PENTOSE PHOSPHATE PATHWAY — Restricted for students enrolled in MCB102, UC Berkeley, Spring 2008 ONLY Two Phases of the Pentose Pathway Metabolism Lecture 5 — PENTOSE PHOSPHATE PATHWAY — Restricted for students enrolled in MCB102, UC Berkeley, Spring 2008 ONLY NADPH vs. NADH Metabolism Lecture 5 — PENTOSE PHOSPHATE PATHWAY — Restricted for students enrolled in MCB102, UC Berkeley, Spring 2008 ONLY Oxidative Phase: Glucose-6-P Ribose-5-P Glucose 6-phosphate dehydrogenase. First enzymatic step in oxidative phase, converting NADP+ to NADPH. Glucose 6-phosphate + NADP+ 6-Phosphoglucono-δ-lactone + NADPH + H+ Mechanism. Oxidation reaction of C1 position. Hydride transfer to the NADP+, forming a lactone, which is an intra-molecular ester. -

Sedoheptulose in Photosynthesis by Plants
TWO-WEEK LOAN COPY This is a Library Circulating Copy which may be borrowed for two weeks. For a personal retention copy, call Tech. Info. Division, Ext. 5545 UCRW.268 Unclassified - Biology Distribution UNIVERSITY OF CALIFOmIA Radiation Laboratory Contract No. W-7405-eng-48 SEDOHEPT[JLOSE IN PHOTOSYNTHESIS BY PLANTS A. A. Benson, J. A. Bassham, and Me Calvin May 1, 1951 Berkeley, California A. A. Benson, 6. A, Bassham, and M, Calvin Radiation Laboratory and Department of Ohemistry University of Calif omia, Berkeley May 1, 1951 Although its function has not been ascertained, the general 1 occurrence of sedohep~ulose, D-altroheptuLose, in the succulent plants is well established. This sugar has not been identified in the majority of the members of the plat lringdom, but it now appears possibae that its phosphate esters may perform a vital function during photosynthesis. We haw isolated labeled sedoheptulose monopho sphate in cl% 2 photosynthesis products of all the plants thus far studied in this laboratory (~lorelh,Scenedesmus, Rhodospfr5.llyn rubn~,and the leaves of barley seedlings, soy bean, alf~lfa,sugar beet, spinach and geranium). It is invariably found as monophosphate esters. At least two such esters have been observed in radiograms of C1'-labeled Scenedesmus. The mjor one is associated with fructose monophosphztte while the minor one is inseparable, as yet, from glucose monophosphate. Sedoheptulose may be liberated e~zymticallyfrom its phosphates during the lrilling of the plan-i;,'but it has not been observed to accwnulate In amounts exceeding tbe steady state concentrations of -these phosphates. .--LL- * This work was sponsored bp the United States Atomic Energy Cormnission, -- This suggests its participation only as a phosphate in most plznts. -
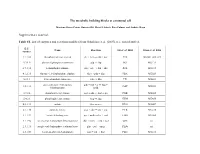
The Metabolic Building Blocks of a Minimal Cell Supplementary
The metabolic building blocks of a minimal cell Mariana Reyes-Prieto, Rosario Gil, Mercè Llabrés, Pere Palmer and Andrés Moya Supplementary material. Table S1. List of enzymes and reactions modified from Gabaldon et. al. (2007). n.i.: non identified. E.C. Name Reaction Gil et. al. 2004 Glass et. al. 2006 number 2.7.1.69 phosphotransferase system glc + pep → g6p + pyr PTS MG041, 069, 429 5.3.1.9 glucose-6-phosphate isomerase g6p ↔ f6p PGI MG111 2.7.1.11 6-phosphofructokinase f6p + atp → fbp + adp PFK MG215 4.1.2.13 fructose-1,6-bisphosphate aldolase fbp ↔ gdp + dhp FBA MG023 5.3.1.1 triose-phosphate isomerase gdp ↔ dhp TPI MG431 glyceraldehyde-3-phosphate gdp + nad + p ↔ bpg + 1.2.1.12 GAP MG301 dehydrogenase nadh 2.7.2.3 phosphoglycerate kinase bpg + adp ↔ 3pg + atp PGK MG300 5.4.2.1 phosphoglycerate mutase 3pg ↔ 2pg GPM MG430 4.2.1.11 enolase 2pg ↔ pep ENO MG407 2.7.1.40 pyruvate kinase pep + adp → pyr + atp PYK MG216 1.1.1.27 lactate dehydrogenase pyr + nadh ↔ lac + nad LDH MG460 1.1.1.94 sn-glycerol-3-phosphate dehydrogenase dhp + nadh → g3p + nad GPS n.i. 2.3.1.15 sn-glycerol-3-phosphate acyltransferase g3p + pal → mag PLSb n.i. 2.3.1.51 1-acyl-sn-glycerol-3-phosphate mag + pal → dag PLSc MG212 acyltransferase 2.7.7.41 phosphatidate cytidyltransferase dag + ctp → cdp-dag + pp CDS MG437 cdp-dag + ser → pser + 2.7.8.8 phosphatidylserine synthase PSS n.i. cmp 4.1.1.65 phosphatidylserine decarboxylase pser → peta PSD n.i. -

Nucleotide Sugars in Chemistry and Biology
molecules Review Nucleotide Sugars in Chemistry and Biology Satu Mikkola Department of Chemistry, University of Turku, 20014 Turku, Finland; satu.mikkola@utu.fi Academic Editor: David R. W. Hodgson Received: 15 November 2020; Accepted: 4 December 2020; Published: 6 December 2020 Abstract: Nucleotide sugars have essential roles in every living creature. They are the building blocks of the biosynthesis of carbohydrates and their conjugates. They are involved in processes that are targets for drug development, and their analogs are potential inhibitors of these processes. Drug development requires efficient methods for the synthesis of oligosaccharides and nucleotide sugar building blocks as well as of modified structures as potential inhibitors. It requires also understanding the details of biological and chemical processes as well as the reactivity and reactions under different conditions. This article addresses all these issues by giving a broad overview on nucleotide sugars in biological and chemical reactions. As the background for the topic, glycosylation reactions in mammalian and bacterial cells are briefly discussed. In the following sections, structures and biosynthetic routes for nucleotide sugars, as well as the mechanisms of action of nucleotide sugar-utilizing enzymes, are discussed. Chemical topics include the reactivity and chemical synthesis methods. Finally, the enzymatic in vitro synthesis of nucleotide sugars and the utilization of enzyme cascades in the synthesis of nucleotide sugars and oligosaccharides are briefly discussed. Keywords: nucleotide sugar; glycosylation; glycoconjugate; mechanism; reactivity; synthesis; chemoenzymatic synthesis 1. Introduction Nucleotide sugars consist of a monosaccharide and a nucleoside mono- or diphosphate moiety. The term often refers specifically to structures where the nucleotide is attached to the anomeric carbon of the sugar component. -

A Genetically Adaptable Strategy for Ribose Scavenging in a Human Gut Symbiont Plays a 4 Diet-Dependent Role in Colon Colonization 5 6 7 8 Robert W
1 2 3 A genetically adaptable strategy for ribose scavenging in a human gut symbiont plays a 4 diet-dependent role in colon colonization 5 6 7 8 Robert W. P. Glowacki1, Nicholas A. Pudlo1, Yunus Tuncil2,3, Ana S. Luis1, Anton I. Terekhov2, 9 Bruce R. Hamaker2 and Eric C. Martens1,# 10 11 12 13 1Department of Microbiology and Immunology, University of Michigan Medical School, Ann 14 Arbor, MI 48109 15 16 2Department of Food Science and Whistler Center for Carbohydrate Research, Purdue 17 University, West Lafayette, IN 47907 18 19 3Current location: Department of Food Engineering, Ordu University, Ordu, Turkey 20 21 22 23 Correspondence to: [email protected] 24 #Lead contact 25 26 Running Title: Bacteroides ribose utilization 27 28 29 30 31 32 33 34 35 36 37 38 Summary 39 40 Efficient nutrient acquisition in the competitive human gut is essential for microbial 41 persistence. While polysaccharides have been well-studied nutrients for the gut microbiome, 42 other resources such as co-factors and nucleic acids have been less examined. We describe a 43 series of ribose utilization systems (RUSs) that are broadly represented in Bacteroidetes and 44 appear to have diversified to allow access to ribose from a variety of substrates. One Bacteroides 45 thetaiotaomicron RUS variant is critical for competitive gut colonization in a diet-specific 46 fashion. Using molecular genetics, we probed the nature of the ribose source underlying this diet- 47 specific phenotype, revealing that hydrolytic functions in RUS (e.g., to cleave ribonucleosides) 48 are present but dispensable. Instead, ribokinases that are activated in vivo and participate in 49 cellular ribose-phosphate metabolism are essential. -

Sugar Bearing Crops - M
CULTIVATED PLANTS, PRIMARILY AS FOOD SOURCES – Vol. II – Sugar Bearing Crops - M. Hajós-Novák SUGAR BEARING CROPS M. Hajós-Novák Department of Genetics and Plant Breeding, Faculty of Agricultural and Environmental Sciences, Szent István University, Gödöllő, Hungary Keywords: carbohydrates, sugars, energy, sugar beet, sugar cane, sweet sorghum, jerusalem artichoke, syrup, ethanol, molasses, fuel Contents 1. The present status of carbohydrate consumption 1.1. The role of carbohydrates in nutrition and feed 1.2. Definition and classification of carbohydrates 1.3. Properties and derivatives of sugars 2. Sugar crops 2.1. Sugar Beet 2.1.1. Origin and history 2.1.2. The sugar beet plant 2.1.3. Cultivation and uses 2.2. Sugar Cane 2.2.1. Origin and history 2.2.2. The sugar cane plant 2.2.3. Culture and uses 2.3. Sweet Sorghum 2.3.1. Cultivation and uses 2.4.Jerusalem Artichoke 3. Sugar crops as source of ethyl alcohol and fuel Glossary Bibliography Biographical Sketch Summary Sugars and starch both belong to the carbohydrate group. Carbohydrates are the single most important source of food energy in the world. They may be classified according to their degreeUNESCO of polymerization and may –be di videdEOLSS initially into three principal groups, namely sugars, oligosacharides, and polysaccharides. There are sugar crops, like sugar cane, sugar beet,SAMPLE sweet sorghum and Jerusale CHAPTERSm Arthichoke that are cultivated for the production of sugar and some by-products such as alcohol, glyceria, citric acid etc. Of them sugar cane, sugar beet and sweet sorghum are multipurpose crops, because from the same piece of land food, fuel and fodder can be produced. -
![United States Patent 1191 [11] Patent Number: 5,071,976 Stirling [45] Date of Patent: Dec](https://docslib.b-cdn.net/cover/5005/united-states-patent-1191-11-patent-number-5-071-976-stirling-45-date-of-patent-dec-3585005.webp)
United States Patent 1191 [11] Patent Number: 5,071,976 Stirling [45] Date of Patent: Dec
United States Patent 1191 [11] Patent Number: 5,071,976 Stirling [45] Date of Patent: Dec. 10, 1991 [ 54 1 No VEL H ETEROPOLYSACCHARIDE FOREIGN PATENT DOCUMENTS Inventor: David I. Stirling, Fanwood, 1589865 5/1981 United Kingdom _ [73] Assignee: Celgene Corporation, Warren, NJ. OTHER PUBLICATIONS [211 App}_ NOJ 270,404 Huq et al., Aust. J. BioL, 1978, vol. 31, pp. 311-316. Bergey’s Manual, 8th ed., 1979, Williams & Wilkins (p. [22] Filed: Nov. 7, 1988 268). Colby et al., Ann. Rev. Microbiol, 1979, vol. 33, pp. Related US. A lication Data 481-517 _ _ pp Byrom, D. in Microbial Growth on C1 Compounds, H. [63] Contmuauon o_f Ser. No. 820,535, Feb. 6, 1986, aban- Dalton ed.’ 1931’ pp. 278489. doned, wh1ch 1s a continuation of Ser. No. 700,564, Hackh’?’ 8 chemical Dictionary 4th Edition Feb. 11, 1985, abandoned. McGraw_Hin’ 1972. [51] Int. Cl.5 ..................... .. C08B 37/00; CllP 19/04; Prima'y Examiner__D_ w_ Robinson c1 1N 1/20 Assistant Examiner-Irene Marx [52] U5. Cl. .................................. .. 536/123; 435/ 101; Attorney, Agent, or Fl‘rm_-Mathews’ WOOdbI-idge’ & 435/2511 Collins [58] Field of Search ........................... .. 435/101, 252.1; 536/123 [57] ABSTRACT _ This invention provides a fermentation process which [56] References C'ted involves aerobically cultivating a strain of Methyle U.S. PATENT DOCUMENTS philus viscogenes under growth conditions to produce an 3 346 463 10/1967 Goren ............................... .. 435/101 accumula‘ed quantity Ofa novel type of exopolysaccha' 3,932,218 1/1976 Finn et al. , 435/101 ride’ Such as hetempdysacchafide Poly 54 4,514,563 4/1985 Fujiyama ... -

Chemistry of a Pseudomonas Glycopetide Demonstrating Rh₀ (D
This dissertation has been 64—1274 microfilmed exactly as received LAZEN, Alvin Gordon, 1935- CHEMISTRY OF A PSEUDOMONAS GLYCOPEPTIDE DEMONSTRATING Rh0(D) SPECIFICITY. The Ohio State University, Ph.D., 1963 Bacteriology University Microfilms, Inc., Ann Arbor, Michigan CHEMISTRY OF A PSEUDOMONAS GLYCOPEPTIDE DEMONSTRATING Rh0(D) SPECIFICITY DISSERTATION Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Alvin Gordon Lazen, B.S. ****** The Ohio State University 1963 Approved by C r - Adviser Department of Microbiology ACKNOWLEDGMENTS Science is only a part of life. A step forward in science— Just as a step forward in life— depends upon the help, encouragement, and understanding of many people. To those persons who have helped and encouraged me I wish to express my deep-felt gratitude: Dr. C. I. Randles for his patience and restraint in permitting me to find my own way, while being always willing to help; Dr. M. S. Rheins for his interest and encouragement; Drs. M. C. Dodd, N. J. Bigley, J. M. Blrkeland and other faculty members who helped me in many ways; George Hrubant who began this study; and to the many graduate students who shared this part of life with me. Financial support from the Ohio State Research Foundation and especially from the Muellhaupt Fellowship of the Graduate School was indispensable and appreciated aid during the course of my research. I am most grateful to my wife Lyla, who has provided all— help, encouragement, understanding, patience, support, and faith. ii TABLE OF CONTENTS Page Acknowledgments.................................... -

Enhancing Photosynthesis with Sugar Signals
Opinion TRENDS in Plant Science Vol.6 No.5 May 2001 197 to sophisticated fine control mechanisms represented Enhancing the best targets because they exerted the most control on flux. In the Calvin cycle, through which carbon enters the reactions of photosynthesis and photosynthesis with metabolism, there are four key irreversible enzymes: Rubisco, in the carboxylation phase of the cycle, and fructose-1,6-bisphosphatase (FBPase), sugar signals sedoheptulose-1,7-bisphosphatase (SBPase) and phosphoribulokinase (PRK), in the regenerative phase (Fig. 1). In experiments on transgenic tobacco and Matthew Paul, Till Pellny and Oscar Goddijn potato expressing antisense cDNA to each of these enzymes, a decrease of 50% maximum catalytic enzyme activity had minimal impact on the rate of Photosynthesis has long been a target in the quest to maximize crop photosynthesis under standard growth-room productivity to feed burgeoning populations. Recent evidence suggests that conditions1–4. The most extreme of these is PRK, 85% improved photosynthetic performance can be most easily achieved by of whose maximum catalytic activity can be removed modifying sugar-signalling mechanisms that control the expression of genes before there is any effect on photosynthesis4. This is for whole pathways and processes that determine photosynthetic capacity and because sophisticated fine control of PRK can source–sink balance, rather than by directly targeting individual ‘key’ enzymes. overcome a large genetic decrease in PRK protein4,5. Here, we highlight recent progress and support for the hypothesis that genetic The full story of control of Calvin cycle flux comes from modification of trehalose metabolism through its interaction with sugar- analysis under a range of conditions that plants are signalling pathways can enhance photosynthetic capacity. -

F R U C T O S E M B T Я N S C
FRUCTOSE MbTÿnSc U S M T N HI CHER PLANTS THESIS submitted for the degree of Master of Philosophy in Biochemistry by Leonard John Morgan Royal Holloway College, University of London August 1984 ProQuest Number: 10096522 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a complete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. uest. ProQuest 10096522 Published by ProQuest LLC(2016). Copyright of the Dissertation is held by the Author. All rights reserved. This work is protected against unauthorized copying under Title 17, United States Code. Microform Edition © ProQuest LLC. ProQuest LLC 789 East Eisenhower Parkway P.O. Box 1346 Ann Arbor, Ml 48106-1346 - 2 - Abstract Fructose 1-phosphate, an important intermediate in the metabolism of fructose in animals and micro-organisms, has only been tentatively identified as a component of higher plant tissues and nothing was known concerning its formation or metabolism in plants. In the present study, examination of tissue extracts from a number of different plant species by ion-exchange chromatography did not confirm the presence of endogenous fructose 1-phosphate. However, injection 14 of [U- C]fructose into developing Jerusalem artichoke tubers resulted in the rapid formation of labelled glucose 6-phosphate, fructose 6-phosphate, fructose-1,6-bisphosphate, and probably glucose 1-phosphate, followed by the appearance of fructose 1-phosphate which was identified by ion-exchange chromatography and hydrolysis. -

Preparative Scale Enzymatic Synthesis of D-Sedoheptulose-7-Phosphate From
Preparative scale enzymatic synthesis of D-sedoheptulose-7-phosphate from β-hydroxypyruvate and D-ribose-5-phosphate Franck Charmantray, Virgil Hélaine, Bertrand Legeret, Laurence Hecquet To cite this version: Franck Charmantray, Virgil Hélaine, Bertrand Legeret, Laurence Hecquet. Preparative scale enzy- matic synthesis of D-sedoheptulose-7-phosphate from β-hydroxypyruvate and D-ribose-5-phosphate. Journal of Molecular Catalysis B: Enzymatic, Elsevier, 2009, 57, pp.6-9. hal-00366191 HAL Id: hal-00366191 https://hal.archives-ouvertes.fr/hal-00366191 Submitted on 6 Mar 2009 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Preparative scale enzymatic synthesis of d-sedoheptulose-7-phosphate from β- hydroxypyruvate and d-ribose-5-phosphate Franck Charmantraya, Virgil Hélainea, Bertrand Legereta and Laurence Hecquet a, aUniversité Blaise Pascal, laboratoire de Synthèse et Etude de Systèmes à Intérêt Biologique, UMR CNRS 6504, 63177 Aubière Cedex, France Abstract An enzymatic method for ready access to D-sedoheptulose-7-phosphate on a preparative scale was developed, based on the irreversible transketolase-catalyzed reaction: β-hydroxypyruvate + D-ribose-5- phosphate → D-sedoheptulose-7-phosphate. D-Sedoheptulose-7-phosphate disodium salt was obtained in 81% overall yield determined using a standard curve obtained by LC/MS/MS.