Attacking Edge Through the Javascript Compiler Bluehatil 2019 and Offensivecon 2019 Bruno Keith Whoami
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Internet Explorer 9 Features
m National Institute of Information Technologies NIIT White Paper On “What is New in Internet Explorer 9” Submitted by: Md. Yusuf Hasan Student ID: S093022200027 Year: 1st Quarter: 2nd Program: M.M.S Date - 08 June 2010 Dhaka - Bangladesh Internet Explorer History Abstract: In the early 90s—the dawn of history as far as the World Wide Web is concerned—relatively few users were communicating across this Internet Explorer 9 (abbreviated as IE9) is the upcoming global network. They used an assortment of shareware and other version of the Internet Explorer web browser from software for Microsoft Windows operating system. In 1995, Microsoft Microsoft. It is currently in development, but developer hosted an Internet Strategy Day and announced its commitment to adding Internet capabilities to all its products. In fulfillment of that previews have been released. announcement, Microsoft Internet Explorer arrived as both a graphical Web browser and the name for a set of technologies. IE9 will have complete or nearly complete support for all 1995: Internet Explorer 1.0: In July 1995, Microsoft released the CSS 3 selectors, border-radius CSS 3 property, faster Windows 95 operating system, which included built-in support for JavaScript and embedded ICC v2 or v4 color profiles dial-up networking and TCP/IP (Transmission Control support via Windows Color System. IE9 will feature Protocol/Internet Protocol), key technologies for connecting to the hardware accelerated graphics rendering using Direct2D, Internet. In response to the growing public interest in the Internet, Microsoft created an add-on to the operating system called Internet hardware accelerated text rendering using Direct Write, Explorer 1.0. -

Your Chakra Is Not Aligned Hunting Bugs in the Microsoft Edge Script Engine About Me
Your Chakra Is Not Aligned Hunting bugs in the Microsoft Edge Script Engine About Me ● Natalie Silvanovich AKA natashenka ● Project Zero member ● Previously did mobile security on Android and BlackBerry ● ECMAScript enthusiast What are Edge and Chakra ● Edge: Windows 10 browser ● Chakra: Edge’s open-source ECMAScript core ○ Regularly updated ○ Accepts external contributions What is ECMAScript ● ECMAScript == Javascript (mostly) ● Javascript engines implement the ECMAScript standard ● ES7 released in June Why newness matters ● Standards don’t specify implementation ● Design decisions are untested ○ Security and performance advantages (and disadvantages) ● Developers and hackers learn from new bugs ● Attacks mature over time ● High contention space Goals ● Find bugs in Chakra ● Understand and improve weak areas ● Find deep, unusual bugs* Approach ● Code review ○ Finds quality bugs ○ Bugs live longer* ○ Easier to fix an entire class of bugs RTFS ● Reading the standard is important ○ Mozilla docs (MDN) is a great start ● Many features are used infrequently but cause bugs ● Features are deeply intertwined Array.species “But what if I subclass an array and slice it, and I want the thing I get back to be a regular Array and not the subclass?” class MyArray extends Array { static get [Symbol.species]() { return Array;} } ● Easily implemented by inserting a call to script into *every single* Array native call Array Conversion ● Arrays can be complicated but most Arrays are simple ○ Most implementations have simple arrays with more complex fallbacks IntegerArray Add a float FloatArray Add a non-numeric value Configure a value (e.g read-only) ES5Array VarArray Array Conversion ● Integer, Float and ES5 arrays are subclasses of Var Array superclass ● vtable swapping (for real) Array Conversion IntSegment IntArray length vtable size length left head next .. -

Time-Travel Debugging for Javascript/Node.Js
Time-Travel Debugging for JavaScript/Node.js Earl T. Barr Mark Marron Ed Maurer University College London, UK Microsoft Research, USA Microsoft, USA [email protected] [email protected] [email protected] Dan Moseley Gaurav Seth Microsoft, USA Microsoft, USA [email protected] [email protected] ABSTRACT Time-traveling in the execution history of a program during de- bugging enables a developer to precisely track and understand the sequence of statements and program values leading to an error. To provide this functionality to real world developers, we embarked on a two year journey to create a production quality time-traveling de- bugger in Microsoft’s open-source ChakraCore JavaScript engine and the popular Node.js application framework. CCS Concepts •Software and its engineering ! Software testing and debug- Figure 1: Visual Studio Code with extra time-travel functional- ging; ity (Step-Back button in top action bar) at a breakpoint. Keywords • Options for both using time-travel during local debugging Time-Travel Debugging, JavaScript, Node.js and for recording a trace in production for postmortem de- bugging or other analysis (Section 2.1). 1. INTRODUCTION • Reverse-Step Local and Dynamic operations (Section 2.2) Modern integrated development environments (IDEs) provide a that allow the developer to step-back in time to the previously range of tools for setting breakpoints, examining program state, and executed statement in the current function or to step-back in manually logging execution. These features enable developers to time to the previously executed statement in any frame in- quickly track down localized bugs, provided all of the relevant val- cluding exception throws or callee returns. -

College Catalog
401 Medical Park Drive Concord, NC 28025 704-403-1555 • Fax: 704-403-2077 Email: [email protected] www.cabarruscollege.edu 2016–2017 CATALOG CONTENTS Greetings from the President .................................................................................................................. 3 Academic Calendars .................................................................................................................................. 4 Accreditation .............................................................................................................................................. 8 Right to Know ........................................................................................................................................... 9 Right to Revise ........................................................................................................................................... 9 History ......................................................................................................................................................... 9 Vision ........................................................................................................................................................ 10 Mission & Goals ...................................................................................................................................... 10 Core Values ............................................................................................................................................. -

Maria Abou Chakra
Maria Abou Chakra University of Toronto, Donnelly Centre, Canada B [email protected] Ï google scholar Positions Held Ï orcid:0000-0002-4895-954X Ï researcherid:K-4735-2013 Current, from July 2016 Ï http://web.evolbio.mpg.de/∼abouchakra Research Associate Ï http://individual.utoronto.ca/abouchakra University of Toronto, Canada Donnelly Centre for Cellular and Biomolecular Research Mathematical modelling of human tissue development as part of the Medicine by Design Project. Modelling intestinal Education development in an organoid. 2006-2010 Doctor of Philosophy Computational Biology Jan 2011-July 2016 Dep. of Biology. McMaster University Post-Doctoral Researcher Thesis: Modelling echinoid skeletal Max Planck Institute, Pl¨on,Germany growth and form Dep. of Evolutionary Theory 2004-2005 M.Sc., Transferred to Ph.D. Using Evolutionary Game theory to understand the emer- 1999-2003 Honors Bachelors of Science gence of complex interactions. General Biology Dep. of Biology. McMaster University 2013-2015 Anthony (5.2013) & Olivia (1.2016) Part-time and Maternity I have worked part-time or taken maternity leave during Computational Experience these years. 1994-present Programming: QBasic, Visual Basic, VBA(Microsoft Office Certified), C, 2002-2010 C++, bash, and awk Research Assistant 2004-present Mathematica McMaster University, Hamilton Certification for Mathematica Advance Dep. of Biology, Dr J. Stone (2004-2010) Level Foundation Studied the morphological disparity in echinoid skeletons. Dep. of Math. and Stats., Dr M. Lovric (2002-2005) Summarized survey results from educational research. Teaching Experience Dep. of Health Science, Dr J. Bain (2002-2004) 2011-2014 Max-Planck Institute Studied the effects of tension on the various cell layers Lecturer: designed and presented a surrounding a nerve fibre. -
Brian Terlson Program Manager on Chakra & Typescript Editor of the Ecmascript Standard
Brian Terlson Program Manager on Chakra & TypeScript Editor of the ECMAScript Standard @bterlson bterlson #msedgesummit JavaScript that Scales with ChakraCore & TypeScript #msedgesummit ChakraCore: An open source, cross platform, blazing fast, standards-compliant JavaScript engine #msedgesummit Chakra & ChakraCore #msedgesummit Node-ChakraCore: Node.js using the ChakraCore engine github.com/nodejs/node-chakracore Easily switch between Node versions & flavors github.com/jasongin/nvs #msedgesummit ChakraCore Engine Architecture #msedgesummit ChakraCore Engine Architecture #msedgesummit Now even faster with minified code! ChakraCore Engine Architecture #msedgesummit ChakraCore Engine Architecture #msedgesummit ChakraCore Engine Architecture #msedgesummit ChakraCore’s Profiling Interpreter • Gathers information used later by the JIT • Low latency execution • Pretty fast, actually! • Just C++, compile on any platform • Useful when JITing is impossible • Hardware constraints (low memory, IoT) • Software constraints (iOS) ChakraCore Engine Architecture #msedgesummit ChakraCore Engine Architecture #msedgesummit ChakraCore Engine Architecture #msedgesummit ChakraCore Engine Architecture #msedgesummit ChakraCore’s Just In Time (JIT) Compiler • Multiple tiers ensure low latency & high throughput • Fully cross-platform, supported on Mac OS X and Linux • Runs out-of-process • Constantly getting smarter and faster! ChakraCore Engine Architecture #msedgesummit ChakraCore Engine Architecture #msedgesummit Lower memory usage with function body redeferral -

Microsoft Edge Memgc Internals
Microsoft Edge MemGC Internals Henry Li,TrendMicro 2015/08/29 Agenda • Background • MemGC Internals • Prevent the UAF'S exploit • Weaknesses of MemGC Notes • Research is based on Windows 10 10041( edgehtml.dll, chakra.dll) • The latest windows versions( windows 10 10240) data structure there are some small changes Who am i? • A security research in TrendMicro CDC zero day discovery team. • Four years of experience in vulnerability & exploit research. • Research interests are browser 0day vulnerability analysis, discovery and exploit. • Twitter/Weibo:zenhumany Background • June 2014 IE introduce ISOLATE HEAP • July 2014 IE introduce DELAY FREE Background • Isolated Heap can bypass • Delay Free – Pointer to the free block remains on the stack for the entire period of time from the free until the reuse, can prevent UAF EXPLOIT – Other situation, can bypass What’s MemGC • Chakra GC use Concurrent Mark-Sweep (CMS) Managing Memory • Edge use the same data structures to mange DOM and DOM’S supporting objects, called MemGC MemGC Internals • Data Structures • Algorithms MemGC Data Structures MemProtectHeap 0x000 m_tlsIndex :int 0x108 m_recycler :Recycler Recycler 0x026c m_HeapBlock32Map HeapBlock32Map 0x42bc m_HeapInfo :HeapInfo HeapInfo 0x4400 m_HeapBucketGroup[ 0x40] :HeapBucketGroup array 0x5544 m_LargeHeapBucket[ 0x20 ] :LargeHeapBucket array 0x5b44 m_lastLargeHeapBucket :LargeHeapBucket HeapBucketGroup HeapBucketGroup 0x154 0x000 m_HeapBucketT<SmallNormalHeapBlock> 0x044 m_HeapBucketT<SmallLeafHeapBlock> 0x080 m_HeapBucketT<SmallFinalizableHeapBlock> -
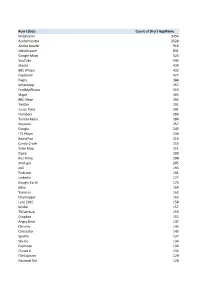
Row Labels Count of Short Appname Mobileiron 3454 Authenticator 2528
Row Labels Count of Short AppName MobileIron 3454 Authenticator 2528 Adobe Reader 916 vWorkspace 831 Google Maps 624 YouTube 543 iBooks 434 BBC iPlayer 432 Facebook 427 Pages 388 WhatsApp 357 FindMyiPhone 313 Skype 303 BBC News 292 Twitter 291 Junos Pulse 291 Numbers 289 TuneIn Radio 284 Keynote 257 Google 243 ITV Player 234 BoardPad 219 Candy Crush 215 Tube Map 211 Zipcar 209 Bus Times 208 mod.gov 205 4oD 193 Podcasts 191 LinkedIn 177 Google Earth 172 eBay 164 Yammer 163 Citymapper 163 Lync 2010 158 Kindle 157 TVCatchup 153 Dropbox 152 Angry Birds 147 Chrome 143 Calculator 143 Spotify 137 Sky Go 136 Evernote 134 iTunes U 132 FileExplorer 129 National Rail 128 iPlayer Radio 127 FasterScan 125 BBC Weather 125 FasterScan HD 124 Gmail 123 Instagram 116 Cleaner Brent 107 Viber 104 Find Friends 98 PDF Expert 95 Solitaire 91 SlideShark 89 Netflix 89 Dictation 89 com.amazon.AmazonUK 88 Flashlight 81 iMovie 79 Temple Run 2 77 Smart Office 2 74 Dictionary 72 UK & ROI 71 Journey Pro 71 iPhoto 70 TripAdvisor 68 Guardian iPad edition 68 Shazam 67 Messenger 65 Bible 64 BBC Sport 63 Rightmove 62 London 62 Sky Sports 61 Subway Surf 60 Temple Run 60 Yahoo Mail 58 thetrainline 58 Minion Rush 58 Demand 5 57 Documents 55 Argos 55 LBC 54 Sky+ 51 MailOnline 51 GarageBand 51 Calc 51 TV Guide 49 Phone Edition 49 Translate 48 Print Portal 48 Standard 48 Word 47 Skitch 47 CloudOn 47 Tablet Edition 46 MyFitnessPal 46 Bus London 46 Snapchat 45 Drive 42 4 Pics 1 Word 41 TED 39 Skyscanner 39 SoundCloud 39 PowerPoint 39 Zoopla 38 Flow Free 38 Excel 38 Radioplayer -

Microsoft Security Bulletin for February 2019 Patches That Fix 79 Security Vulnerabilities
Microsoft Security Bulletin for February 2019 Patches That Fix 79 Security Vulnerabilities Date of Release: Feburary 13, 2019 Overview Microsoft released the January 2019 security patch on Tuesday that fixes 79 vulnerabilities ranging from simple spoofing attacks to remote code execution in various products, including .NET Framework, Adobe Flash Player, Azure, Internet Explorer, Microsoft Browsers, Microsoft Edge, Microsoft Exchange Server, Microsoft Graphics Component, Microsoft JET Database Engine, Microsoft Office, Microsoft Office SharePoint, Microsoft Scripting Engine, Microsoft Windows, Servicing Stack Updates, Team Foundation Server, Visual Studio, Windows DHCP Server, Windows Hyper-V, Windows Kernel, and Windows SMB Server. Details can be found in the following table. Product CVE ID CVE Title Severity Level .NET Framework and Visual .NET Framework CVE-2019-0657 Important Studio Spoofing Vulnerability @绿盟科技 2019 http://www.nsfocus.com .NET Framework and Visual .NET Framework CVE-2019-0613 Studio Remote Code Execution Important Vulnerability February 2019 Adobe Flash Adobe Flash Player ADV190003 Critical Security Update Azure IoT Java SDK Privilege Azure CVE-2019-0729 Important Escalation Vulnerability Azure IoT Java SDK Information Azure CVE-2019-0741 Important Disclosure Vulnerbaility Internet Explorer Memory Internet Explorer CVE-2019-0606 Critical Corruption Vulnerability Internet Explorer Information Internet Explorer CVE-2019-0676 Important Disclosure Vulnerability Microsoft Browser Spoofing Microsoft Browsers CVE-2019-0654 -

FALL 2 017 School Catalog
FALL 2 017 School Catalog Acupuncture Holistic Wellness Massage Therapy Practical & Registered Nursing TRANSFORMING HEALTHCARE HOLISTICALLY We believe your success is our success. 6685 Doubletree Avenue Columbus, Ohio 43229 ph (614) 825.6255 fax (614) 825.6279 [email protected] AIAM.edu Edition: 2017.4 Publish Date: Sept. 2017 This catalog is certified as true and correct in content and policy. At the time of publication, every effort was made to assure that this catalog contains accurate information. Please refer to the catalog addendum for any changes and/or revisions that have occurred since the catalog’s published date. 1489T AIAM’s Mission The American Institute of Alternative Medicine (AIAM) is a private higher education institution whose mission is to empower by promoting a holistic approach to wellness. AIAM models an integrative approach to develop and inspire compassionate professionals, nurture vibrant lives, and foster a healthy community. Vision Transforming Healthcare Holistically Motto Your success is our success. Our Facility The building that houses the American Institute of Alternative Medicine includes several academically-focused spaces consisting of: • 12 lecture rooms • 2 conference rooms • 2 consultation rooms • a nursing lab • clinical spaces with 14 treatment rooms • a quiet library with computers for student use • a kitchen area with seating for students and a courtyard with picnic tables • instructor office spaces • administrative offices • various meeting spaces Contents Welcome ..............................................2 -

Selected Crafts of Andhra Pradesh, Part VII-A (2), Vol-II
PRG. 86.2 (N) 1000 ~ENSUS OF INDIA 1961 VOLUME II ANUHRA PRAUESH PART VII-A (2) SELECTED CRAFTS OF ANDHRA PRADESH K. V. N. GOWD, B. Com. (HONS.) Deputy Superintendent of Census Operations, Andhra Pradesh. Price: Rs. 10·00 or 23 Sh. 4 d.or S 3·60 c. 1961 CENSUS PUBLICATIONS, ANDHRA PRADESH ~ (All the Census Publications of this State will bear Vol. No. II) PART I-A General Report PART I-B Report on Vital Statistics PART 'I-C Subsidiary Tables . PART II-A General Population Tables PART II-B (i) Economic Tables [B-1 to B-IV] PART II-B (iJ Economic Tables [B-V to B-IX] PARt II-C Cultural and Migration Tables PART III Household Economic Tables PART IV-A' Report on Housing and Establishments (with Subsidiary Tables) PART IV-B Housing and Establishment Tables PART V-A Special Tables for Scheduled Castes and Scheduled Tribes PART V-B Ethnographic Notes on Scheduled Castes and Scheduled Tribes PART VI Village Survey Monographs (46) PART VII-A (1) Handicrafts Survey Reports (Selected Crafts) PART VII-A (2) } PART VII-B (1 to 20) Fairs and Festivals (Separate Book for each District) PART VIII-A Administration Report - Enumeration (Not for sale) PART VIII-B Administration Report - Tabulation } PART IX State Atlas PART X Special Report on Hyderabad City District Census Handbooks (Separate Volume for each District) FOREWORD One of the first steps to be taken in the First FIve Year Plan was the establishment of six Boards for the promotion of handicrafts, village and small industries: (1) The Khadi and Village Industries Board; (2) The All.lndia Handicrafts Board; (3) The All·India Handloom Board; (4) The Central Silk Board; (5) The Coir Board; and (6) The Small Industries Board. -

NIC-CERT/2017-11/33 Dated: 15-11-2017 CVE ID: Multiple Severity: Moderate
NIC-CERT/2017-11/33 Dated: 15-11-2017 CVE ID: Multiple Severity: Moderate Advisory for Microsoft November 2017 Security Updates A. Description: Microsoft has released security updates for several products as part of the company's November 2017 Patch Tuesday and this month the company fixed around 53 vulnerabilities across various Microsoft product categories. The November security release consists of security updates for the following software: Internet Explorer Microsoft Edge Microsoft Windows Microsoft Office and Microsoft Office Services and Web Apps ASP.NET Core and .NET Core Chakra Core B. Security Issues Fixed: The Patch Tuesday updates also include two security advisories, one delivering Flash updates and the second, delivering various security-related patches to Office products. Besides these, two other security fixes is CVE-2017-11830, a vulnerability that allows attackers to bypass the Windows Device Guard security feature, and CVE-2017-11887, a vulnerability that allows attackers to bypass macro execution protection in Microsoft Excel. Refer Annexure-I, for an overview of the Security issues fixed. C. Resolution: In order to avoid any security compromise all Users are advised to update their with the latest security patches provided by Microsoft. D. References: 1. https://portal.msrc.microsoft.com/en-us/security-guidance/releasenotedetail/bae9d0d8-e497- e711-80e5-000d3a32fc99 2. https://www.bleepingcomputer.com/news/microsoft/microsoft-november-patch-tuesday-fixes-53- security-issues/ 3. https://threatpost.com/microsoft-patches-20-critical-vulnerabilities/128891/