Functional Programming in CLEAN
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

AEDIT Text Editor Iii Notational Conventions This Manual Uses the Following Conventions: • Computer Input and Output Appear in This Font
Quick Contents Chapter 1. Introduction and Tutorial Chapter 2. The Editor Basics Chapter 3. Editing Commands Chapter 4. AEDIT Invocation Chapter 5. Macro Commands Chapter 6. AEDIT Variables Chapter 7. Calc Command Chapter 8. Advanced AEDIT Usage Chapter 9. Configuration Commands Appendix A. AEDIT Command Summary Appendix B. AEDIT Error Messages Appendix C. Summary of AEDIT Variables Appendix D. Configuring AEDIT for Other Terminals Appendix E. ASCII Codes Index AEDIT Text Editor iii Notational Conventions This manual uses the following conventions: • Computer input and output appear in this font. • Command names appear in this font. ✏ Note Notes indicate important information. iv Contents 1 Introduction and Tutorial AEDIT Tutorial ............................................................................................... 2 Activating the Editor ................................................................................ 2 Entering, Changing, and Deleting Text .................................................... 3 Copying Text............................................................................................ 5 Using the Other Command....................................................................... 5 Exiting the Editor ..................................................................................... 6 2 The Editor Basics Keyboard ......................................................................................................... 8 AEDIT Display Format .................................................................................. -
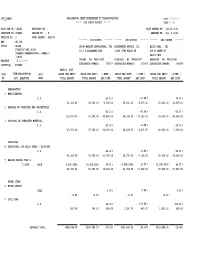
Bid Check Report * * * Time: 14:04
DOT_RGGB01 WASHINGTON STATE DEPARTMENT OF TRANSPORTATION DATE: 05/28/2013 * * * BID CHECK REPORT * * * TIME: 14:04 PS &E JOB NO : 11W101 REVISION NO : BIDS OPENED ON : Jun 26 2013 CONTRACT NO : 008498 REGION NO : 9 AWARDED ON : Jul 1 2013 VERSION NO : 2 WORK ORDER# : XL4078 ------- LOW BIDDER ------- ------- 2ND BIDDER ------- ------- 3RD BIDDER ------- HWY : SR 104 TITLE : SR104 ORION MARINE CONTRACTORS, INC. BLACKWATER MARINE, LLC QUIGG BROS., INC. KINGSTON TML SLIPS 1112 E ALEXANDER AVE 12019 76TH PLACE NE 819 W STATE ST DOLPHIN PRESERVATION - PHASE 4 98520-5934 11W101 PROJECT : NH-2013(079) TACOMA WA 984214102 KIRKLAND WA 980342437 ABERDEEN WA 985200281 COUNTY(S) : KITSAP CONTRACTOR NUMBER : 100767 CONTRACTOR NUMBER : 100874 CONTRACTOR NUMBER : 680000 ENGR'S. EST. ITEM ITEM DESCRIPTION UNIT PRICE PER UNIT/ PRICE PER UNIT/ % DIFF./ PRICE PER UNIT/ % DIFF./ PRICE PER UNIT/ % DIFF./ NO. EST. QUANTITY MEAS TOTAL AMOUNT TOTAL AMOUNT AMT.DIFF. TOTAL AMOUNT AMT.DIFF. TOTAL AMOUNT AMT.DIFF. PREPARATION 1 MOBILIZATION L.S. -25.20 % -25.48 % 40.00 % 25,000.00 18,700.00 -6,300.00 18,630.00 -6,370.00 35,000.00 10,000.00 2 REMOVAL OF STRUCTURE AND OBSTRUCTION L.S. -56.10 % -65.08 % -56.71 % 115,500.00 50,700.00 -64,800.00 40,338.00 -75,162.00 50,000.00 -65,500.00 3 DISPOSAL OF CREOSOTED MATERIAL L.S. -21.05 % -8.99 % -15.79 % 47,500.00 37,500.00 -10,000.00 43,228.35 -4,271.65 40,000.00 -7,500.00 STRUCTURE 4 STRUCTURAL LOW ALLOY STEEL - DOLPHINS L.S. -

COMMAND LINE CHEAT SHEET Presented by TOWER — the Most Powerful Git Client for Mac
COMMAND LINE CHEAT SHEET presented by TOWER — the most powerful Git client for Mac DIRECTORIES FILES SEARCH $ pwd $ rm <file> $ find <dir> -name "<file>" Display path of current working directory Delete <file> Find all files named <file> inside <dir> (use wildcards [*] to search for parts of $ cd <directory> $ rm -r <directory> filenames, e.g. "file.*") Change directory to <directory> Delete <directory> $ grep "<text>" <file> $ cd .. $ rm -f <file> Output all occurrences of <text> inside <file> (add -i for case-insensitivity) Navigate to parent directory Force-delete <file> (add -r to force- delete a directory) $ grep -rl "<text>" <dir> $ ls Search for all files containing <text> List directory contents $ mv <file-old> <file-new> inside <dir> Rename <file-old> to <file-new> $ ls -la List detailed directory contents, including $ mv <file> <directory> NETWORK hidden files Move <file> to <directory> (possibly overwriting an existing file) $ ping <host> $ mkdir <directory> Ping <host> and display status Create new directory named <directory> $ cp <file> <directory> Copy <file> to <directory> (possibly $ whois <domain> overwriting an existing file) OUTPUT Output whois information for <domain> $ cp -r <directory1> <directory2> $ curl -O <url/to/file> $ cat <file> Download (via HTTP[S] or FTP) Copy <directory1> and its contents to <file> Output the contents of <file> <directory2> (possibly overwriting files in an existing directory) $ ssh <username>@<host> $ less <file> Establish an SSH connection to <host> Output the contents of <file> using -

A New Macro-Programming Paradigm in Data Collection Sensor Networks
SpaceTime Oriented Programming: A New Macro-Programming Paradigm in Data Collection Sensor Networks Hiroshi Wada and Junichi Suzuki Department of Computer Science University of Massachusetts, Boston Program Insert This paper proposes a new programming paradigm for wireless sensor networks (WSNs). It is designed to significantly reduce the complexity of WSN programming by providing a new high- level programming abstraction to specify spatio-temporal data collections in a WSN from a global viewpoint as a whole rather than sensor nodes as individuals. Abstract SpaceTime Oriented Programming (STOP) is new macro-programming paradigm for wireless sensor networks (WSNs) in that it supports both spatial and temporal aspects of sensor data and it provides a high-level abstraction to express data collections from a global viewpoint for WSNs as a whole rather than sensor nodes as individuals. STOP treats space and time as first-class citizens and combines them as spacetime continuum. A spacetime is a three dimensional object that consists of a two special dimensions and a time playing the role of the third dimension. STOP allows application developers to program data collections to spacetime, and abstracts away the details in WSNs, such as how many nodes are deployed in a WSN, how nodes are connected with each other, and how to route data queries in a WSN. Moreover, STOP provides a uniform means to specify data collections for the past and future. Using the STOP application programming interfaces (APIs), application programs (STOP macro programs) can obtain a “snapshot” space at a given time in a given spatial resolutions (e.g., a space containing data on at least 60% of nodes in a give spacetime at 30 minutes ago.) and a discrete set of spaces that meet specified spatial and temporal resolutions. -

Humidity Definitions
ROTRONIC TECHNICAL NOTE Humidity Definitions 1 Relative humidity Table of Contents Relative humidity is the ratio of two pressures: %RH = 100 x p/ps where p is 1 Relative humidity the actual partial pressure of the water vapor present in the ambient and ps 2 Dew point / Frost the saturation pressure of water at the temperature of the ambient. point temperature Relative humidity sensors are usually calibrated at normal room temper - 3 Wet bulb ature (above freezing). Consequently, it generally accepted that this type of sensor indicates relative humidity with respect to water at all temperatures temperature (including below freezing). 4 Vapor concentration Ice produces a lower vapor pressure than liquid water. Therefore, when 5 Specific humidity ice is present, saturation occurs at a relative humidity of less than 100 %. 6 Enthalpy For instance, a humidity reading of 75 %RH at a temperature of -30°C corre - 7 Mixing ratio sponds to saturation above ice. by weight 2 Dew point / Frost point temperature The dew point temperature of moist air at the temperature T, pressure P b and mixing ratio r is the temperature to which air must be cooled in order to be saturated with respect to water (liquid). The frost point temperature of moist air at temperature T, pressure P b and mixing ratio r is the temperature to which air must be cooled in order to be saturated with respect to ice. Magnus Formula for dew point (over water): Td = (243.12 x ln (pw/611.2)) / (17.62 - ln (pw/611.2)) Frost point (over ice): Tf = (272.62 x ln (pi/611.2)) / (22.46 - -

Chapter 19 RECOVERING DIGITAL EVIDENCE from LINUX SYSTEMS
Chapter 19 RECOVERING DIGITAL EVIDENCE FROM LINUX SYSTEMS Philip Craiger Abstract As Linux-kernel-based operating systems proliferate there will be an in evitable increase in Linux systems that law enforcement agents must process in criminal investigations. The skills and expertise required to recover evidence from Microsoft-Windows-based systems do not neces sarily translate to Linux systems. This paper discusses digital forensic procedures for recovering evidence from Linux systems. In particular, it presents methods for identifying and recovering deleted files from disk and volatile memory, identifying notable and Trojan files, finding hidden files, and finding files with renamed extensions. All the procedures are accomplished using Linux command line utilities and require no special or commercial tools. Keywords: Digital evidence, Linux system forensics !• Introduction Linux systems will be increasingly encountered at crime scenes as Linux increases in popularity, particularly as the OS of choice for servers. The skills and expertise required to recover evidence from a Microsoft- Windows-based system, however, do not necessarily translate to the same tasks on a Linux system. For instance, the Microsoft NTFS, FAT, and Linux EXT2/3 file systems work differently enough that under standing one tells httle about how the other functions. In this paper we demonstrate digital forensics procedures for Linux systems using Linux command line utilities. The ability to gather evidence from a running system is particularly important as evidence in RAM may be lost if a forensics first responder does not prioritize the collection of live evidence. The forensic procedures discussed include methods for identifying and recovering deleted files from RAM and magnetic media, identifying no- 234 ADVANCES IN DIGITAL FORENSICS tables files and Trojans, and finding hidden files and renamed files (files with renamed extensions. -

Clostridium Difficile (C. Diff)
Living with C. diff Learning how to control the spread of Clostridium difficile (C. diff) This can be serious, I need to do something about this now! IMPORTANT C. diff can be a serious condition. If you or someone in your family has been diagnosed with C. diff, there are steps you can take now to avoid spreading it to your family and friends. This booklet was developed to help you understand and manage C. diff. Follow the recommendations and practice good hygiene to take care of yourself. C. diff may cause physical pain and emotional stress, but keep in mind that it can be treated. For more information on your C.diff infection, please contact your healthcare provider. i CONTENTS Learning about C. diff What is Clostridium difficile (C. diff)? ........................................................ 1 There are two types of C.diff conditions .................................................... 2 What causes a C. diff infection? ............................................................... 2 Who is most at risk to get C. diff? ............................................................ 3 How do I know if I have C. diff infection? .................................................. 3 How does C. diff spread from one person to another? ............................... 4 What if I have C. diff while I am in a healthcare facility? ............................. 5 If I get C. diff, will I always have it? ........................................................... 6 Treatment How is C. diff treated? ............................................................................. 7 Prevention How can the spread of C. diff be prevented in healthcare facilities? ............ 8 How can I prevent spreading C. diff (and other germs) to others at home? .. 9 What is good hand hygiene? .................................................................... 9 What is the proper way to wash my hands? ............................................ 10 What is the proper way to clean? ......................................................... -

System Planner
System Planner ACE3600 RTU ab 6802979C45-D Draft 2 Copyright © 2009 Motorola All Rights Reserved March 2009 DISCLAIMER NOTE The information within this document has been carefully checked and is believed to be entirely reliable. However, no responsibility is assumed for any inaccuracies. Furthermore Motorola reserves the right to make changes to any product herein to improve reliability, function, or design. Motorola does not assume any liability arising out of the application or use of any product, recommendation, or circuit described herein; neither does it convey any license under its patent or right of others. All information resident in this document is considered copyrighted. COMPUTER SOFTWARE COPYRIGHTS The Motorola products described in this Product Planner include copyrighted Motorola software stored in semiconductor memories and other media. Laws in the United States and foreign countries preserve for Motorola certain exclusive rights for copyrighted computer programs, including the exclusive right to copy or reproduce in any form the copyrighted computer program. Accordingly, any copyrighted Motorola computer programs contained in Motorola products described in this Product Planner may not be copied or reproduced in any manner without written permission from Motorola, Inc. Furthermore, the purchase of Motorola products shall not be deemed to grant either directly or by implication, estoppel, or otherwise, any license under the copyright, patents, or patent applications of Motorola, except for the normal non-exclusive, royalty free license to use that arises by operation in law of the sale of a product. TRADEMARKS MOTOROLA and the Stylized M Logo are registered in the U.S. Patent and Trademark Office. -

Powerview Command Reference
PowerView Command Reference TRACE32 Online Help TRACE32 Directory TRACE32 Index TRACE32 Documents ...................................................................................................................... PowerView User Interface ............................................................................................................ PowerView Command Reference .............................................................................................1 History ...................................................................................................................................... 12 ABORT ...................................................................................................................................... 13 ABORT Abort driver program 13 AREA ........................................................................................................................................ 14 AREA Message windows 14 AREA.CLEAR Clear area 15 AREA.CLOSE Close output file 15 AREA.Create Create or modify message area 16 AREA.Delete Delete message area 17 AREA.List Display a detailed list off all message areas 18 AREA.OPEN Open output file 20 AREA.PIPE Redirect area to stdout 21 AREA.RESet Reset areas 21 AREA.SAVE Save AREA window contents to file 21 AREA.Select Select area 22 AREA.STDERR Redirect area to stderr 23 AREA.STDOUT Redirect area to stdout 23 AREA.view Display message area in AREA window 24 AutoSTOre .............................................................................................................................. -

SQL Processing with SAS® Tip Sheet
SQL Processing with SAS® Tip Sheet This tip sheet is associated with the SAS® Certified Professional Prep Guide Advanced Programming Using SAS® 9.4. For more information, visit www.sas.com/certify Basic Queries ModifyingBasic Queries Columns PROC SQL <options>; SELECT col-name SELECT column-1 <, ...column-n> LABEL= LABEL=’column label’ FROM input-table <WHERE expression> SELECT col-name <GROUP BY col-name> FORMAT= FORMAT=format. <HAVING expression> <ORDER BY col-name> <DESC> <,...col-name>; Creating a SELECT col-name AS SQL Query Order of Execution: new column new-col-name Filtering Clause Description WHERE CALCULATED new columns new-col-name SELECT Retrieve data from a table FROM Choose and join tables Modifying Rows WHERE Filter the data GROUP BY Aggregate the data INSERT INTO table SET column-name=value HAVING Filter the aggregate data <, ...column-name=value>; ORDER BY Sort the final data Inserting rows INSERT INTO table <(column-list)> into tables VALUES (value<,...value>); INSERT INTO table <(column-list)> Managing Tables SELECT column-1<,...column-n> FROM input-table; CREATE TABLE table-name Eliminating SELECT DISTINCT CREATE TABLE (column-specification-1<, duplicate rows col-name<,...col-name> ...column-specification-n>); WHERE col-name IN DESCRIBE TABLE table-name-1 DESCRIBE TABLE (value1, value2, ...) <,...table-name-n>; WHERE col-name LIKE “_string%” DROP TABLE table-name-1 DROP TABLE WHERE col-name BETWEEN <,...table-name-n>; Filtering value AND value rows WHERE col-name IS NULL WHERE date-value Managing Views “<01JAN2019>”d WHERE time-value “<14:45:35>”t CREATE VIEW CREATE VIEW table-name AS query; WHERE datetime-value “<01JAN201914:45:35>”dt DESCRIBE VIEW view-name-1 DESCRIBE VIEW <,...view-name-n>; Remerging Summary Statistics DROP VIEW DROP VIEW view-name-1 <,...view-name-n>; SELECT col-name, summary function(argument) FROM input table; Copyright © 2019 SAS Institute Inc. -

The AWK Programming Language
The Programming ~" ·. Language PolyAWK- The Toolbox Language· Auru:o V. AHo BRIAN W.I<ERNIGHAN PETER J. WEINBERGER TheAWK4 Programming~ Language TheAWI(. Programming~ Language ALFRED V. AHo BRIAN w. KERNIGHAN PETER J. WEINBERGER AT& T Bell Laboratories Murray Hill, New Jersey A ADDISON-WESLEY•• PUBLISHING COMPANY Reading, Massachusetts • Menlo Park, California • New York Don Mills, Ontario • Wokingham, England • Amsterdam • Bonn Sydney • Singapore • Tokyo • Madrid • Bogota Santiago • San Juan This book is in the Addison-Wesley Series in Computer Science Michael A. Harrison Consulting Editor Library of Congress Cataloging-in-Publication Data Aho, Alfred V. The AWK programming language. Includes index. I. AWK (Computer program language) I. Kernighan, Brian W. II. Weinberger, Peter J. III. Title. QA76.73.A95A35 1988 005.13'3 87-17566 ISBN 0-201-07981-X This book was typeset in Times Roman and Courier by the authors, using an Autologic APS-5 phototypesetter and a DEC VAX 8550 running the 9th Edition of the UNIX~ operating system. -~- ATs.T Copyright c 1988 by Bell Telephone Laboratories, Incorporated. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopy ing, recording, or otherwise, without the prior written permission of the publisher. Printed in the United States of America. Published simultaneously in Canada. UNIX is a registered trademark of AT&T. DEFGHIJ-AL-898 PREFACE Computer users spend a lot of time doing simple, mechanical data manipula tion - changing the format of data, checking its validity, finding items with some property, adding up numbers, printing reports, and the like. -

Rexx to the Rescue!
Session: G9 Rexx to the Rescue! Damon Anderson Anixter May 21, 2008 • 9:45 a.m. – 10:45 a.m. Platform: DB2 for z/OS Rexx is a powerful tool that can be used in your daily life as an z/OS DB2 Professional. This presentation will cover setup and execution for the novice. It will include Edit macro coding examples used by DBA staff to solve everyday tasks. DB2 data access techniques will be covered as will an example of calling a stored procedure. Examples of several homemade DBA tools built with Rexx will be provided. Damon Anderson is a Senior Technical DBA and Technical Architect at Anixter Inc. He has extensive experience in DB2 and IMS, data replication, ebusiness, Disaster Recovery, REXX, ISPF Dialog Manager, and related third-party tools and technologies. He is a certified DB2 Database Administrator. He has written articles for the IDUG Solutions Journal and presented at IDUG and regional user groups. Damon can be reached at [email protected] 1 Rexx to the Rescue! 5 Key Bullet Points: • Setting up and executing your first Rexx exec • Rexx execs versus edit macros • Edit macro capabilities and examples • Using Rexx with DB2 data • Examples to clone data, compare databases, generate utilities and more. 2 Agenda: • Overview of Anixter’s business, systems environment • The Rexx “Setup Problem” Knowing about Rexx but not knowing how to start using it. • Rexx execs versus Edit macros, including coding your first “script” macro. • The setup and syntax for accessing DB2 • Discuss examples for the purpose of providing tips for your Rexx execs • A few random tips along the way.