An Executable Packer
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

LZ Based Compression Benchmark on PE Files Introduction LZ Based
LZ based compression benchmark on PE files Zsombor Paróczi Abstract: The key element in runtime compression is the compression algorithm, that is used during processing. It has to be small in enough in decompression bytecode size to fit in the final executable, yet have to provide the best compression ratio. In our work we benchmark the top LZ based compression methods on Windows PE files (both exe and dll files), and present the results including the decompres- sion overhead and the compression rates. Keywords: lz based compression, compression benchmark, PE benchmark Introduction During runtime executable compression an already compiled executable is modified in ways, that it still retains the ability to execute, yet the transformation produces smaller file size. The transformations usually exists from multiple steps, changing the structure of the executable by removing unused bytes, adding a compression layer or modifying the code in itself. During the code modifications the actual bytecode can change, or remain the same depending on the modification itself. In the world of x86 (or even x86-64) PE compression there are only a few benchmarks, since the ever growing storage capacity makes this field less important. Yet in new fields, like IOT and wearable electronics every application uses some kind of compression, Android apk-s are always compressed by a simple gzip compression. There are two mayor benchmarks for PE compression available today, the Maximum Compression benchmark collection [1] includes two PE files, one DLL and one EXE, and the Pe Compression Test [2] has four exe files. We will use the exe files during our benchmark, referred as small corpus. -

Administrator's Guide
Trend Micro Incorporated reserves the right to make changes to this document and to the product described herein without notice. Before installing and using the product, review the readme files, release notes, and/or the latest version of the applicable documentation, which are available from the Trend Micro website at: http://docs.trendmicro.com/en-us/enterprise/scanmail-for-microsoft- exchange.aspx Trend Micro, the Trend Micro t-ball logo, Apex Central, eManager, and ScanMail are trademarks or registered trademarks of Trend Micro Incorporated. All other product or company names may be trademarks or registered trademarks of their owners. Copyright © 2020. Trend Micro Incorporated. All rights reserved. Document Part No.: SMEM149028/200709 Release Date: November 2020 Protected by U.S. Patent No.: 5,951,698 This documentation introduces the main features of the product and/or provides installation instructions for a production environment. Read through the documentation before installing or using the product. Detailed information about how to use specific features within the product may be available at the Trend Micro Online Help Center and/or the Trend Micro Knowledge Base. Trend Micro always seeks to improve its documentation. If you have questions, comments, or suggestions about this or any Trend Micro document, please contact us at [email protected]. Evaluate this documentation on the following site: https://www.trendmicro.com/download/documentation/rating.asp Privacy and Personal Data Collection Disclosure Certain features available in Trend Micro products collect and send feedback regarding product usage and detection information to Trend Micro. Some of this data is considered personal in certain jurisdictions and under certain regulations. -

Automatic Classifying of Mac OS X Samples
Automatic Classifying of Mac OS X Samples Spencer Hsieh, Pin Wu and Haoping Liu Trend Micro Inc., Taiwan TREND MICRO LEGAL DISCLAIMER The information provided herein is for general information Contents and educational purposes only. It is not intended and should not be construed to constitute legal advice. The information contained herein may not be applicable to all situations and may not reflect the most current situation. Nothing contained herein should be relied on or acted 4 upon without the benefit of legal advice based on the particular facts and circumstances presented and nothing Introduction herein should be construed otherwise. Trend Micro reserves the right to modify the contents of this document at any time without prior notice. Translations of any material into other languages are intended solely as a convenience. Translation accuracy 6 is not guaranteed nor implied. If any questions arise related to the accuracy of a translation, please refer to Mac OS X Samples Dataset the original language official version of the document. Any discrepancies or differences created in the translation are not binding and have no legal effect for compliance or enforcement purposes. 10 Although Trend Micro uses reasonable efforts to include accurate and up-to-date information herein, Trend Micro makes no warranties or representations of any kind as Classification of Mach-O Files to its accuracy, currency, or completeness. You agree that access to and use of and reliance on this document and the content thereof is at your own risk. Trend Micro disclaims all warranties of any kind, express or implied. 11 Neither Trend Micro nor any party involved in creating, producing, or delivering this document shall be liable for any consequence, loss, or damage, including direct, Malware Families indirect, special, consequential, loss of business profits, or special damages, whatsoever arising out of access to, use of, or inability to use, or in connection with the use of this document, or any errors or omissions in the content 15 thereof. -

A Proposed System for Hiding Information in Portable Executable Files Based on Analyzing Import Section
IOSR Journal of Engineering (IOSRJEN) www.iosrjen.org ISSN (e): 2250-3021, ISSN (p): 2278-8719 Vol. 04, Issue 01 (January. 2014), ||V7|| PP 21-30 A Proposed System for Hiding Information In Portable Executable Files Based on Analyzing Import Section Mohammad Hussein Jawwad 1- University of Babylon- College of Information Technology- Iraq Abstract: - Information-hiding techniques have newly become very important in a many application areas. Many cover mediums have been used to hide information like image, video, voice. Use of these mediums have been extensively studied. In this paper, we propose new system for hiding information in Portable Executable files (PE files). PE is a file format for executable file used in the 32-bit and 64-bit versions of the Windows operating system. This algorithm has higher security than some traditional ones because of the combination between encryption and hiding. We first encrypt the information before hiding it to ensure high security. After that we hide the information in the import table of PE file. This hiding depends on analyzing the import table characteristics of PE files that have been built under Borland turbo assembler. The testing result shows that the result file does not make any inconsistency with anti-virus programs and the PE file still function as normal after the hiding process. Keywords: - PE File, Information Hiding, Cryptography. I. INTRODUCTION The development and wide use of computer science and informatics also, the advent of global networks (i.e. Internet) that make the access for information is possible for every one online impose the need for ways to avoid hackers and muggers from getting the important information. -

Portable Executable File Format
Chapter 11 Portable Executable File Format IN THIS CHAPTER + Understanding the structure of a PE file + Talking in terms of RVAs + Detailing the PE format + The importance of indices in the data directory + How the loader interprets a PE file MICROSOFT INTRODUCED A NEW executable file format with Windows NT. This for- mat is called the Portable Executable (PE) format because it is supposed to be portable across all 32-bit operating systems by Microsoft. The same PE format exe- cutable can be executed on any version of Windows NT, Windows 95, and Win32s. Also, the same format is used for executables for Windows NT running on proces- sors other than Intel x86, such as MIPS, Alpha, and Power PC. The 32-bit DLLs and Windows NT device drivers also follow the same PE format. It is helpful to understand the PE file format because PE files are almost identi- cal on disk and in RAM. Learning about the PE format is also helpful for under- standing many operating system concepts. For example, how operating system loader works to support dynamic linking of DLL functions, the data structures in- volved in dynamic linking such as import table, export table, and so on. The PE format is not really undocumented. The WINNT.H file has several struc- ture definitions representing the PE format. The Microsoft Developer's Network (MSDN) CD-ROMs contain several descriptions of the PE format. However, these descriptions are in bits and pieces, and are by no means complete. In this chapter, we try to give you a comprehensive picture of the PE format. -

Investigation of Malicious Portable Executable File Detection on the Network Using Supervised Learning Techniques
Investigation of Malicious Portable Executable File Detection on the Network using Supervised Learning Techniques Rushabh Vyas, Xiao Luo, Nichole McFarland, Connie Justice Department of Information and Technology, Purdue School of Engineering and Technology IUPUI, Indianapolis, IN, USA 46202 Emails: [email protected]; [email protected]; [email protected]; [email protected] Abstract—Malware continues to be a critical concern for that random forest learning technique achieved best detection everyone from home users to enterprises. Today, most devices are performance than the other three learning techniques. The connected through networks to the Internet. Therefore, malicious achieved detection rate and false alarm rate on experimental code can easily and rapidly spread. The objective of this paper is to examine how malicious portable executable (PE) files can be data set were 98.7% and 1.8% respectively. We compared detected on the network by utilizing machine learning algorithms. the performances of the four learning techniques on four The efficiency and effectiveness of the network detection rely types of PE malware - backdoors, viruses, worms and trojans. on the number of features and the learning algorithms. In this The results showed that the same learning technique show work, we examined 28 features extracted from metadata, packing, the similar performance on different types of malwares. It imported DLLs and functions of four different types of PE files for malware detection. The returned results showed that the demonstrated the features that are extracted from the files have proposed system can achieve 98.7% detection rates, 1.8% false no bias for a specific type of malware. -

Windows X32 Cross Compile Guide
Guide for cross compiling Trezarcoin for windows. By Iwens Fortis Tested on Ubuntu 16.04.2 LTS. • Start on ubuntu your terminal (search for terminal with ubuntu dash top icon left, or press windows key to open dash). • First we need to install the dependencies, for this execute the following cmd’s stated below in the terminal window. The commands to execute are in the grey textboxes. The commands will ask for a password which and u have to confirm some commands with y from yes. Tip transfer the pdf to ubuntu for easy copy and paste. • First update the apt library. sudo apt-get update • Install needed dependencies to install mxe to cross compile Trezarcoin. sudo apt-get install p7zip-full autoconf automake autopoint bash bison bzip2 cmake flex gettext git g++ gperf intltool \ libffi-dev libtool libltdl-dev libssl-dev libxml-parser-perl make openssl patch perl pkg-config python ruby scons sed unzip \ wget xz-utils libtool-bin libgdk-pixbuf2.0-dev g++-multilib libc6-dev-i386 upx -y • We need to get latest mxe from github and compile libraries needed. git clone https://github.com/mxe/mxe.git cd mxe make MXE_TARGETS="i686-w64-mingw32.static" boost make MXE_TARGETS="i686-w64-mingw32.static" qttools make MXE_TARGETS="i686-w64-mingw32.static" miniupnpc • Next we need to compile the recommended Berkeley DB our self cd ~ wget 'http://download.oracle.com/berkeley-db/db-4.8.30.NC.tar.gz' tar zxvf db-4.8.30.NC.tar.gz cd db-4.8.30.NC • Now we will create a bash script for this execute the following commands to create the bash script. -

Command-Line Guide for Linux, Mac & Windows
Command-line Guide for Linux, Mac & Windows info.nrao.edu /computing/guide/file-access-and-archiving/7zip/7z-7za-command-line-guide See also: File Archiving and Compression, Accessing and Sharing Files, Network Access, Windows Terminal Servers 7-Zip Versions 7-Zip is an Archive and File Management utility available in command-line versions for Linux/Mac, "P7Zip" (7z.exe), as well as for Windows, "7za" (7za.exe). Although its interface is deceptively simple, the command-line versions of 7ZIP are highly customizable archiving programs when used with the command parameters and switchesdescribed below. Windows users who want to use the command-line version should generate a Help Desk ticket to install the standalone 7za.exe version. To begin a session, open a terminal window. Invoke the version of 7Zip you are using by entering " 7z" for P7Zip (7z.exe), or "7za" for 7Zip for Windows (7za.exe) to start either the P7-Zip or 7za application prior to entering commands. Other than this program invocation command, all commands, parameters and switches are identical for all command-line versions. NOTE TO WINDOWS USERS: the following syntax examples begin by invoking the Linux command-line version, "7z". Please change the invocation to "7za" when applying these examples for use in 7-Zip for Windows. Command Line Syntax The general command line syntax begins by invoking the version of 7Zip you are using: "7z" for P7Zip (7z.exe) users or "7za" for 7Zip for Windows (7za.exe) users followed by the command and parameters: "command" "switches" "full_path_archive_name" "full_path_file_name" Eg; 7z a -p 7Zip_Archive Test_file.txt creates a 7z formatted archive named 7Zip_Archive that is protected with a password , then adds a file named test_file.txt to the archive. -
3. PE Portable Executable: a Look
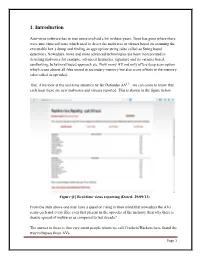
1. Introduction Anti-virus software has in true sense evolved a lot in these years. Time has gone where there were anti-virus software which used to detect the malwares or viruses based on scanning the executable hex`s dump and finding an appropriate string (also called as String based detection). Nowadays, more and more advanced technologies are been incorporated in detecting malwares for example, advanced heuristics, signature and its variants based, sandboxing, behavioral based approach etc. Now many AV not only offers deep scan option which scans almost all files stored in secondary memory but also scans offsets in the memory (also called as opcodes). But, if we look at the real-time statistics by Bit Defender AV[1] , we can come to know that each hour there are new malwares and viruses reported. This is shown in the figure below. Figure [1] Real-time virus reporting (Dated: 29/09/13) From the stats above one may have a question rising in their mind that nowadays the AVs scans each and every files even that present in the opcodes of the memory then why there is drastic spread of malwares as compared to last decade? The answer to these is that very smart people whom we call Crackers/Hackers have found the way to bypass these AVs. Page 1 They know the very detail about how the AV works and which AV have which type of detection capabilities for example if it scans based on string detection or if it scans based on sandboxing approach. We sometimes fail to remember that they (Crackers and Hackers) too have AV scanners from which they may scan their newly developed malware and viruses and can easily spread via plethora of medium, mostly the Internet. -

Qualitative and Quantitative Evaluation of Software Packers
Qualitative and Quantitative Evaluation of Software Packers Mar´ıa Bazus,´ Ricardo J. Rodr´ıguez, Jose´ Merseguer « All wrongs reversed [email protected] ¸ @RicardoJRdez ¸ www.ricardojrodriguez.es Department of Computer Science and Systems Engineering University of Zaragoza, Spain December 12, 2015 NoConName 2015 Barcelona (Spain) $whoami Ph.D. on Comp. Sci. (Univ. of Zaragoza, Spain) (2013) Assistant Professor at University of Zaragoza Performance analysis on critical, complex systems Secure Software Engineering Advance malware analysis RFID/NFC Security Not prosecuted ^¨ Speaker at NcN, HackLU, RootedCON, STIC CCN-CERT, HIP, MalCON, HITB. M. Bazus,´ R.J. Rodr´ıguez, J. Merseguer Qualitative and Quantitative Evaluation of Software Packers NcN 2015 2 / 39 Agenda 1 Introduction 2 Contributions and Related Work 3 Previous Concepts 4 Software Protection Taxonomy 5 Software Packers Under Study 6 Qualitative and Quantitative Evaluation Qualitative Evaluation Quantitative Evaluation 7 Conclusions and Future Work M. Bazus,´ R.J. Rodr´ıguez, J. Merseguer Qualitative and Quantitative Evaluation of Software Packers NcN 2015 3 / 39 Agenda 1 Introduction 2 Contributions and Related Work 3 Previous Concepts 4 Software Protection Taxonomy 5 Software Packers Under Study 6 Qualitative and Quantitative Evaluation Qualitative Evaluation Quantitative Evaluation 7 Conclusions and Future Work M. Bazus,´ R.J. Rodr´ıguez, J. Merseguer Qualitative and Quantitative Evaluation of Software Packers NcN 2015 4 / 39 RE uses: legitimate and illegitimate X Find software bugs X Get interoperability with legacy systems X Detect malicious software X Detect vulnerabilities to create/spread malware X Obtain (or avoid) software license duplication Introduction (I): Reverse Engineering WTF? To analyse a binary program with machine-code vision Types of analysis: Static analysis( + not executed, * all paths explored) Dynamic analysis( * truly executed, + but just one path explored!) M. -
![Archive and Compressed [Edit]](https://docslib.b-cdn.net/cover/8796/archive-and-compressed-edit-1288796.webp)
Archive and Compressed [Edit]
Archive and compressed [edit] Main article: List of archive formats • .?Q? – files compressed by the SQ program • 7z – 7-Zip compressed file • AAC – Advanced Audio Coding • ace – ACE compressed file • ALZ – ALZip compressed file • APK – Applications installable on Android • AT3 – Sony's UMD Data compression • .bke – BackupEarth.com Data compression • ARC • ARJ – ARJ compressed file • BA – Scifer Archive (.ba), Scifer External Archive Type • big – Special file compression format used by Electronic Arts for compressing the data for many of EA's games • BIK (.bik) – Bink Video file. A video compression system developed by RAD Game Tools • BKF (.bkf) – Microsoft backup created by NTBACKUP.EXE • bzip2 – (.bz2) • bld - Skyscraper Simulator Building • c4 – JEDMICS image files, a DOD system • cab – Microsoft Cabinet • cals – JEDMICS image files, a DOD system • cpt/sea – Compact Pro (Macintosh) • DAA – Closed-format, Windows-only compressed disk image • deb – Debian Linux install package • DMG – an Apple compressed/encrypted format • DDZ – a file which can only be used by the "daydreamer engine" created by "fever-dreamer", a program similar to RAGS, it's mainly used to make somewhat short games. • DPE – Package of AVE documents made with Aquafadas digital publishing tools. • EEA – An encrypted CAB, ostensibly for protecting email attachments • .egg – Alzip Egg Edition compressed file • EGT (.egt) – EGT Universal Document also used to create compressed cabinet files replaces .ecab • ECAB (.ECAB, .ezip) – EGT Compressed Folder used in advanced systems to compress entire system folders, replaced by EGT Universal Document • ESS (.ess) – EGT SmartSense File, detects files compressed using the EGT compression system. • GHO (.gho, .ghs) – Norton Ghost • gzip (.gz) – Compressed file • IPG (.ipg) – Format in which Apple Inc. -

Kafl: Hardware-Assisted Feedback Fuzzing for OS Kernels
kAFL: Hardware-Assisted Feedback Fuzzing for OS Kernels Sergej Schumilo1, Cornelius Aschermann1, Robert Gawlik1, Sebastian Schinzel2, Thorsten Holz1 1Ruhr-Universität Bochum, 2Münster University of Applied Sciences Motivation IJG jpeg libjpeg-turbo libpng libtiff mozjpeg PHP Mozilla Firefox Internet Explorer PCRE sqlite OpenSSL LibreOffice poppler freetype GnuTLS GnuPG PuTTY ntpd nginx bash tcpdump JavaScriptCore pdfium ffmpeg libmatroska libarchive ImageMagick BIND QEMU lcms Adobe Flash Oracle BerkeleyDB Android libstagefright iOS ImageIO FLAC audio library libsndfile less lesspipe strings file dpkg rcs systemd-resolved libyaml Info-Zip unzip libtasn1OpenBSD pfctl NetBSD bpf man mandocIDA Pro clamav libxml2glibc clang llvmnasm ctags mutt procmail fontconfig pdksh Qt wavpack OpenSSH redis lua-cmsgpack taglib privoxy perl libxmp radare2 SleuthKit fwknop X.Org exifprobe jhead capnproto Xerces-C metacam djvulibre exiv Linux btrfs Knot DNS curl wpa_supplicant Apple Safari libde265 dnsmasq libbpg lame libwmf uudecode MuPDF imlib2 libraw libbson libsass yara W3C tidy- html5 VLC FreeBSD syscons John the Ripper screen tmux mosh UPX indent openjpeg MMIX OpenMPT rxvt dhcpcd Mozilla NSS Nettle mbed TLS Linux netlink Linux ext4 Linux xfs botan expat Adobe Reader libav libical OpenBSD kernel collectd libidn MatrixSSL jasperMaraDNS w3m Xen OpenH232 irssi cmark OpenCV Malheur gstreamer Tor gdk-pixbuf audiofilezstd lz4 stb cJSON libpcre MySQL gnulib openexr libmad ettercap lrzip freetds Asterisk ytnefraptor mpg123 exempi libgmime pev v8 sed awk make